这是图数据库 HugeGraph 分享的第三篇文档, 主要讲述它的读和缓存流程, 它是读写流程中另一个重心, 结合上一篇的写流程, 就对图数据库有了一个整体的读写认识, 其他的细节点(例如事务, 并发, 权限等) 可以根据需要再单独阅读了.
图的读流程主要分两块:
第一部分抽经典例子来举例, 第二部分同样以经典的API来说明, 其他图算法实现是相似的, 目前的读流程都是单点计算和查询, 所以大规模的查询效率会有受限
首先要知道, 图的读取最后落到后端本质就两类: 一类是单点查询rowkey. 另一种是通过前缀去扫表, 后者因为不具有普适性, 所以基本都是可以认为是离散的点查(尤其是OLTP场景), 但是如果这么说那图的查询似乎就太简单了, 实际不然, 图的查询反而是相当复杂的一环, 因为涉及到大量语法, 路径优化, 解析优化, 算法优化等…
但是这里先不提进阶和复杂的地方, 只说一下 HugeGraph 中核心的查询设计情况, 一个普通的查询语句, 如何被组装为一个通用的 Query 对象的. 以下是一点铺垫概念:
- Query: 基础抽象, 所有的查询都可认为是一种
query, 它又分化为几种常见的子查询, 比如点查, 条件查询, 范围查询等
- Path: 一般指特定的路径查询抽象, 比如最短路径, 全路径查询类, 两点或多点之间的路径都可归为这个范畴
- Step: 简单可理解为
Gremlin 中的每个函数算子, 比如 V(), count(), both() 都是一个查询的步骤.
- Condition: 查询条件, 常见大小等于的条件
图里面的术语比较多, 为了避免开始绕进概念, 初识就只列这4种设计, 其中 Query 作为每次查询的一个抽象代表, 贯穿始终, 每一次查询都可以认为是一个Query对象, 然后结合具体的 Gremlin 查询语句再来理解.
因为读流程里重复的查询可能会偶有发生, 虽然网络安全场景下图的缓存命中率不高, 但是其他场景, 特别是社交推荐, 缓存命中次数就相当可观了, Huge 的缓存设计思路采用的是经典的 LRU 淘汰模式, 相当于自己模拟实现了一个带定时功能的 LRU, 以及新版支持的堆外缓存(暂略)
注: LRU是每次从缓存中把最长时间没人访问的数据T掉, 和LFU最大区别在于, LRU根本判断条件是时间. 而LFU判断根本是使用次数.
先来看看普通读流程, 再看看缓存设计和使用
首先这是最常见, 通用的实现方式, 依靠于上层的 Tinkerpop-Gremlin 实现, 下层的图数据库系统只需要实现对应的图数据结构接口, 就能使用大部分 gremlin 的查询转换, 那么以最常见的查询语句为例, 它是如何做转换的呢:
// 1. 查询vid为tom的点
g.V("tom")
// 2. 查询vid为tom的点的所有出边(邻居)
g.V("tom").outE()
// 3. 查询vid为tom的点的所有出边(邻居)点中, 名字叫jin的
g.V("tom").outE().has(name, "jin")
// 4. 查询所有点里名字是jin的点, 复杂度多少O(V)?还是?
g.V().has(name, "jin")
// 5. 简单查询tom的两层邻居
g.V("tom").outE().bothV().outE()首先, 最简单的点/边id查询, 那自然是序列化为一个获得指定rowkey的查询, 在Hbase层来看, 就是一个单点 get , 然后我们基于这个出发点, 再去做一系列的扩展, 实际就可能反复与图server之间有多次RPC交互了, 比如以查询2为例:
- 我们已经知道了从
tom 出发, 查询它的出边, 那么只需要访问出边表
- 因为边的
rowkey 是由 vid构成, 我们知道了起点, 就可以构造前缀查询条件, 扫出 tom* 的边数据
然后递进到查询3, 其实就是从边中截取出出点id, 在去点表中, 多个 Get 得到对应的数据, 由此可见仍然是离散的点查, 上面都是很简单的 scan/get 例子, 下面看看第四个查询, 它就代表典型的底层图实现优化了.
首先, 如果你直接继承 Tinkerpop 的遍历逻辑, 查询④是会扫全(点)表的, 它的逻辑是通用的一个个判断每个点是否属性包含 name , 然后再看看它是否值为 jin, 效率自然巨低, 那么你可以自己继承修改 has() 或者 hasLabel()的策略, 让它去尝试读取索引, 如果没有可以禁止此类查询, 有索引去索引表查询再返回, 这样就可以把查询效率变为 O(logV) 了.
然后大部分的 count(), avg(), 或者去重等函数(step), 都是在图server内存中进行筛选计算的, 包括filter/字符串匹配等, 整个gremlin的执行流程比较复杂, 串行和并行都可能混杂, 语法本身也会被重组排序或者优化, 但是核心都是用迭代器在依次遍历迭代. 这里就不细说, 感兴趣需要阅读 Tinkerpop 的源码部分.
K步邻居之所以在实际业务场景中使用评率很高, 有很大一部分原因是因为它是最裸的一种图查询算法, 业务就算没有学习过任何图查询算法, 因为它的广遍历特点, 也能快速从K步邻居的结果里提取到需要的信息 (简单直观).
它的实际效果是: 从某个点出发, 遍历出K步(层)内的所有关联点. 再简单一点说, 就像是从某个点出发的K次迭代循环. 举个实际的例子就像你的微信里有140个好友, 每个好友又分别有数百个好友, 通过K步邻居, 就能一次得到从你出发, 所有好友的展开关系网, 然后从中就可以进行筛选和分析, 得到想要的信息.
从官方文档中可以看到大体的访问方式, 最简单的查询某同学的3层所有朋友的写法可以是:
// Get请求,URL如下
http://ip/graphs/graphName/traversers/kneighbor?source=“1:jin”&max_depth=3
// 返回值,仅有点IDs
{
"vertices":[
"2:doge",
"1:tom",
"1:tom2",
"1:tom3",
"1:jerry",
"2:cat",
.....
]
}但是你会发现这个返回结果很有点摸不着头脑, 因为这并不是之前预期的那样----它告诉我1层(自己)有哪些朋友, 我2层(朋友的朋友)是哪些, 而是一股脑把所有名字都输出给了我, 并且没有点对应的边的信息. 这都是后续可以改进的地方~
通过之前性能测试就已经发现, 当深度变大(>3层)的时候, K步邻居的查询速度会明显变长, 甚至于出错无法得到结果. 那么分析的核心自然就是找到它的耗时点, 然后分析瓶颈到底在什么地方, 是HugeServer , 还是后端存储?
通过对比JanusGraph和Tinkerpop的实现方式, 对K步邻居性能上的关注点集中在以下几个地方:
- 通过gremlin查询K步邻居和使用kneighbor查询本质区别, gremlin查询主要瓶颈是在?
- 通过kneighbor查询的时候, 每一层是通过上一层缓存的点一次性去查下一层(1次RPC), 还是说每个点依次迭代(N次RPC ).
然后带着这些问题, 再结合源码去验证和进一步思考.
首先, 所有的定制图算法在结构上都是属于Traverser 的. 包括最短路径, 全路径, PageRank, 三角计数等等... 而在Huge中这个结构也挺清晰, 分为以下几个核心步骤:
- 构造API
- 编写Traverser算法 (核心)
- 针对后端定制 (可选)
就以Kneighbor为例, 首先在hugegraph-api 模块中, 它会有一个KneighborAPI , 然后提供网络I/O的REST接口, 解析通过HTTP请求发送的Kneighbor参数, 调用kneighbor算法, 最后序列化返回结果, 这个过程简化的K步邻居的整个逻辑:
-
给定两个Set集合, 一个记录每层遍历的点(latest), 一个记录整个过程遍历的点(all).
-
从第一层开始, 依次遍历
当前层
的所有点 + 之前层的点.
- 首先获得当前点的所有边(方向可指定)
- 遍历每一条边, 然后获得边指向的另一个顶点
- 判断指向的点是否记录过, 没有就加进去.
-
依次循环, 直到遍历数达到上限, 或遍历完成.
过程可以理解为: 用两个Set替代了传统队列的BFS遍历, 只不过目前的Set集合只进不出, 只是能自动去重. 所以在多层迭代遍历的时候效率较低, 因为每次遍历不仅要遍历当前层所有点, 还有遍历之前已经遍历过的所有点 (虽然有跳过逻辑)
整个遍历过程:
- 算法复杂度接近: O(n) + O(n+n^2^) +.... O(n+n^2^+....n^k^) ≈ O(n^k^) (K代表遍历层数, 当然因为图缓存的关系, 所以低层数并不会很慢.)
- 时间复杂度: S(2n), 来自
set 的存储消耗
并且当前只是一股脑把所有点去重获得了, 并不知道实际用途... 所以如果要用它替代目前gremlin自己实现的K步邻居, 还有比较多需要改动的地方,
上面是说的核心的逻辑, 如果还是不太确定, 可以看看具体的源码, 其中degree指单个顶点最大可遍历边数目 (也就是个单点limit)
public Set<Id> kneighbor(Id sourceV, Directions dir,
String label, int depth, long degree, long limit) {
checkParams(sourceV,dir....);
// Q1:如果不传,则查所有边是在哪实现的... ("" or null)
Id labelId = this.getEdgeLabelId(label);
// 初始化两个的Set, 添加初始顶点
Set<Id> latest = newSet(sourceV);
Set<Id> all = newSet(sourceV);
// 按每层遍历
while (depth-- > 0) {
long remaining = limit == NO_LIMIT ? NO_LIMIT : limit - all.size();
// 每次更新latest集合加入相邻顶点(核心)
latest = adjacentVertices(latest, dir, labelId, all, degree, remaining);
all.addAll(latest);
if (limit != NO_LIMIT && all.size() >= limit) break; //遍历点数超过上限则跳出
}
return all;
}
private Set<Id> adjacentVertices(Set<Id> vertices, Directions dir,Id label,
Set<Id> excluded, long degree, long limit) {
if (limit == 0) return ImmutableSet.of();
Set<Id> neighbors = newSet();
// 依次遍历latest顶点 (比如在第二层, 则遍历第一层的所有点+起点)
for (Id source : vertices) {
// 拿到从这个点出发的所有边,,时间复杂度至少O(n)?
Iterator<Edge> edges = edgesOfVertex(source, dir,label, degree);
while (edges.hasNext()) {
HugeEdge e = (HugeEdge) edges.next();
// 获得每条边指向的顶点ID
Id target = e.id().otherVertexId();
// 跳过or添加这个点
if (excluded != null && excluded.contains(target)) continue;
neighbors.add(target);
if (limit != NO_LIMIT && neighbors.size() >= limit) return neighbors;
}
}
return neighbors;
}
Iterator<Edge> edgesOfVertex(Id source, Directions dir, Id label, long limit) {
Id[] labels = {};
if (label != null) labels = new Id[]{label}; //Q2:为何下面不直接传label
//通过"fromV + 方向 + 边label"查询边, 这里确定是一个ConditionQuery (查的细节在后面.)
Query query = GraphTransaction.constructEdgesQuery(source, dir, labels);
if (limit != NO_LIMIT) query.limit(limit);
return this.graph.edges(query);
}然后你会发现这里有一个核心操作被封装了, 就是如何获取某个点的所有边呢? 类似v.outE(), 可以看看如下的源码, 以及在 Hbase 中对应的构造查询条件:
//关键查询后端在于此,后续具体分不同后端操作,这里以Hbase/Binary序列化为例
@Override
public Iterator<BackendEntry> query(Query query) {
if (!(query instanceof ConditionQuery)) {
return super.query(query); //非条件查询,writeQueryEdgePrefixCondition
}
QueryList queries = new QueryList(this.graph(), query,
q -> super.query(q));
for (ConditionQuery cq: ConditionQueryFlatten.flatten(
(ConditionQuery) query)) {
Query q = this.optimizeQuery(cq);
/*
* NOTE: There are two possibilities for this query:
* 1.sysprop-query, which would not be empty.
* 2.index-query result(ids after optimization), which may be empty.
*/
if (q == null) {
queries.add(this.indexQuery(cq));
} else if (!q.empty()) {
queries.add(q);
}
}
return !queries.empty() ? queries.fetch() : Collections.emptyIterator();
}
//上面的query()方法,到Hbase前的查询条件如下(可以看到总共有5种方式)
@Override
public Iterator<BackendEntry> query(Session session, Query query) {
if (query.limit() == 0 && query.limit() != Query.NO_LIMIT) return ImmutableList.<BackendEntry>of().iterator();
// Query all (扫表)
if (query.empty()) return newEntryIterator(this.queryAll(session, query), query);
// Query by prefix (前缀查询, 查"某点的所有出边"属于这种,比如"1:jin"的出边 )
if (query instanceof IdPrefixQuery) {
IdPrefixQuery pq = (IdPrefixQuery) query;
return newEntryIterator(this.queryByPrefix(session, pq), query);
}
// Query by range (数值范围查询)
if (query instanceof IdRangeQuery) {
IdRangeQuery rq = (IdRangeQuery) query;
return newEntryIterator(this.queryByRange(session, rq), query);
}
// Query by id (非条件查询)
if (query.conditions().isEmpty()) {
assert !query.ids().isEmpty();
RowIterator rowIterator = null;
if (query.ids().size() == 1) {
Id id = query.ids().iterator().next();
rowIterator = this.queryById(session, id);
} else {
rowIterator = this.queryByIds(session, query.ids());
}
return newEntryIterator(rowIterator, query);
}
// Query by condition (or condition + id)
ConditionQuery cq = (ConditionQuery) query;
return newEntryIterator(this.queryByCond(session, cq), query);
}
// 条件查询到Hbase使用的是scan by rowkey查询
public RowIterator scan(String table, byte[] startRow,
boolean inclusiveStart, byte[] prefix) {
// Hbase-client的scan, 这里filter就是序列化后的通过id去前缀匹配rowkey
Scan scan = new Scan().withStartRow(startRow, inclusiveStart).setFilter(new PrefixFilter(prefix));
return this.scan(table, scan);
}所以可以确定这里只需要一次RPC, 就能从Hbase中读取到一批数据, 不过这里starRow是在哪设置的什么来着....
至于改进和展望就可以单独看k步邻居的改进分析, 不单独细说了.
当然, LRU也是一个大的分类, 可以结合一些其他的条件综合实现, 从而获得更好的缓存命中率, 比如相同时间删除数据大小更大的, 以及"使用时间+次数" 的LRU-K. , 或者是FIFO+LRU 的双队列实现, 详情可以参考一下LRU多种实现的对比 .
在Huge里有一个单独的cache 包, 里面有1个Cache 接口 + 3个封装 + 1个RamCache实现. 三个封装分别是:
- CachedSchemaTransaction (缓存图的Schema信息)
- CachedGraphTransaction (缓存图的点边数据)
- CacheManager (缓存管理器)
那么这样看整个设计就很清晰了: (估计)
- "接口+实现"负责实现缓存本身
- 点/边数据通过缓存管理器调用CachedGraphTransaction的方法进行缓存
- Schema数据通过缓存管理器调用CachedSchemaTransaction缓存.
- CacheManger类似一个守护进程, 每隔一段时间去观察/更新一下缓存状态
先看缓存本身的实现, 再看如何调用. 在Huge里, 定义了一个Cache 接口, 确定之后缓存实现所需的方法 (如下图) :
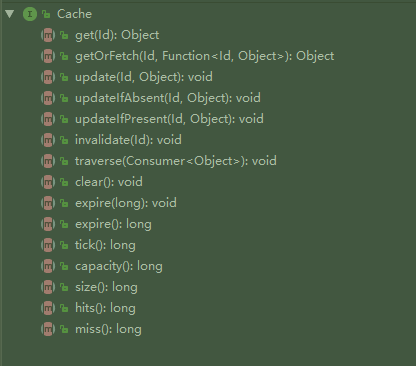
可以看到核心就是缓存的CURD操作, 以及设置一些核心参数(缓存大小, 过期时间), 然后接着看看唯一的实现类RamCache的设计吧: (先看看概览图)
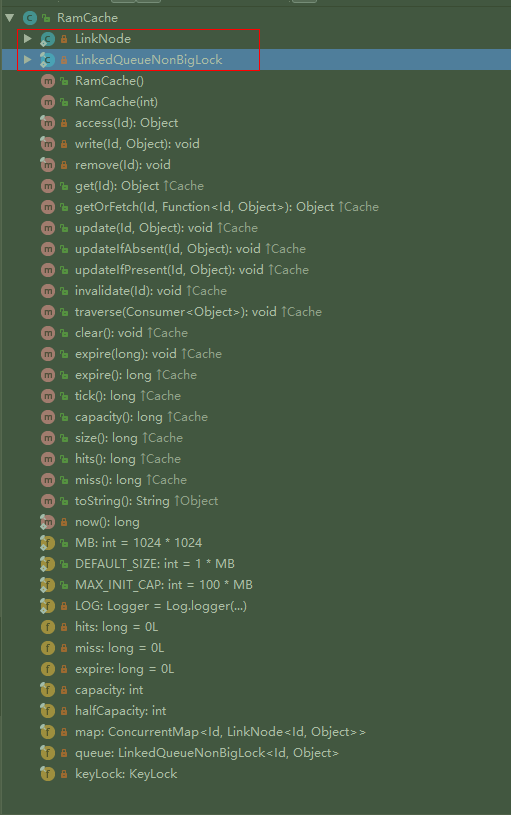
- 初始化一个map, 一个队列: (核心结构)
- map是 <100MB (
100*1024*1024个)的ConcurrentHashMap<Id, LinkNode<Id, Object>>
- 队列是自己实现的的双向链队列 (名为
LinkedQueueNonBigLock<Id, Object>, 其中每个节点(LinkNode)都带有当前时间戳)
- 缓存的本质某个对象的Id和对象本身. 但是要注意的是, 这里Id除了常见的点/边Id, 还有比如某次查询对应的
QueryId ,这样重复的查询, 就无需去缓存中多次查找每个点边, 而是一次把整个Query 对象都取出来.
- 通过包装的两个类来间接调用缓存的增删改查方法, 通过守护进程定时清理过期缓存.
先看看缓存最核心读写实现 (修改本质是覆盖写, 删除就是出队, 不单独说了~) :
以下是精简后的核心过程.
private final void write(Id id, Object value) {
final Lock lock = this.keyLock.lock(id);
try { // 如果超过缓存个数限制,移除队头或清空map (capacity默认1024*1024个)
while (map.size() >= capacity) {
// 1.先从队列移出最长时间未访问元素
// 注意: 如果其他线程正在做出队操作或队列可能为空, 那么可能就会返回null(出队失败)
LinkNode<Id, Object> removed = queue.dequeue();
if (removed == null) {
// 如果与此同时有其他添加操作,map就会先被清空,然后跳出循环 (Q:why clear map?)
map.clear();
break;
}
// 2.然后从map里移出刚才的元素
map.remove(removed.key());
}
// 3.旧元素出队(如果存在)
LinkNode<Id, Object> node = map.get(id);
if (node != null) queue.remove(node);
// 4.新元素入队,然后放入map
map.put(id, queue.enqueue(id, value));
} finally {lock.unlock();}
}这里其他过程都很清晰, 就是如果其他线程同一时间写入, 则导致出栈元素为空时, 为何要清空整个map. 这里还不太理解... 待确定
private final Object access(Id id) {
// map中元素 < 缓存上限一半, 则直接返回元素值, 不移动队列
if (map.size() <= this.halfCapacity) {
LinkNode<Id, Object> node = map.get(id);
if (node == null) return null;
return node.value();
}
final Lock lock = this.keyLock.lock(id);
try {
LinkNode<Id, Object> node = map.get(id);
if (node == null) return null;
// 如果map中元素 > 缓存上限数一半, 则需要更新队列,读取的元素重新入队
if (map.size() > halfCapacity) {
// 把元素从中间移至尾部 (元素可能被其他线程通过出队调用移除)
if (queue.remove(node) == null) return null;
queue.enqueue(node);
}
return node.value();
} finally {lock.unlock();}
}这里跟标准的LRU的区别就在于设置了一个halfCapacity . 原本LRU每次读取都会在链表里移动这个元素到队尾, 而链表的查询效率是很低的. 如图所示:
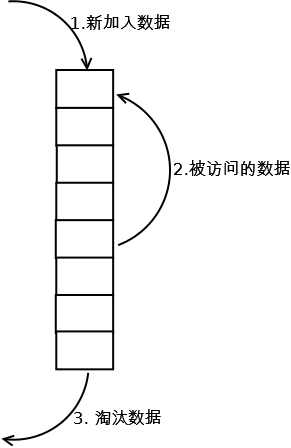
可能这里为了减少移动次数, 就设定当缓存还算充裕(多于一半)的时候, 退化为FIFO... 不去重新移动和计算队列, 也不加锁, 这样读取效率理论上会提高许多, 它的主要缺点是? 待确定
之前接口里其实有一个方法名比较奇怪, 名为tick() (Tick-Tok) , 我想了想, 翻译为标记(过期元素数)....可能比较合适?
在LinkNode 的结构里, 每个节点初始化的时候都会携带一个当前时间戳, 它就是在tick() 函数中被用来计算过期时间的, 然后它又是CacheManager 初始化的时候调用的, 借助Timer对象后台执行, 达到定时检查缓存是否过期, 以及移除过期对象的效果 :
public long tick() {
long expireTime = this.expire; //默认过期时间
int expireItems = 0; //过期元素个数
long current = now();
if (expireTime <= 0) return 0L;
for (LinkNode<Id, Object> node : map.values()) {
if (current - node.time() > expireTime) {
remove(node.key()); //删除缓存元素
expireItems++;
}
}
return expireItems;
}
// CacheManager的核心定时执行方法
private TimerTask scheduleTimer(float period) {
TimerTask task = new TimerTask() {
@Override
public void run() {
for (Entry<String, Cache> entry : caches().entrySet()) tick(entry.getKey(), entry.getValue());
}
private void tick(String name, Cache cache) {
long start = System.currentTimeMillis();
long items = cache.tick(); //调用上面的tick清理过期元素
long cost = System.currentTimeMillis() - start;
LOG.debug("Cache '{}' expiration tick cost {}ms", name, cost);
}
};
// 30s定时执行一次
timer.schedule(task, 0, (long) (period * 1000.0));
return task;
}至于双向链队的结构, 除了加了一个自己封装的KeyLock 锁对象, 其他暂时没看到有什么特殊设计, 就不单独讲数据结构了.. 有兴趣可以参考源码1,源码2
上面已经把Hugegraph中的缓存设计和实现大体说完了, 这里再举个具体的例子, 比如之前说的K步邻居查询, 或者某条gremlin查询后, 在Huge里是如何缓存的? 当然这里其实只是一个函数调用了.
以K步邻居核心过程, 查某个点的所有边为例, 最后会调用queryEdgesFromBackend() , 这种操作都是属于GraphTransaction ,而这些都在CachedGraphTransaction 中进行了重写, 例如下面就同时展示了读写缓存在图里的使用方式:
@Override
protected Iterator<HugeEdge> queryEdgesFromBackend(Query query) {
// 通过page查询的边不存入缓存.直接使用父类
if (query.empty() || query.paging()) return super.queryEdgesFromBackend(query);
Id id = new QueryId(query);
List<HugeEdge> edges = (List<HugeEdge>) this.edgesCache.get(id); //先从缓存里查,存在则返回
if (edges == null) {
// 迭代器不方便直接缓存,转为集合缓存.
edges = ImmutableList.copyOf(super.queryEdgesFromBackend(query));
if (edges.size() <= MAX_CACHE_EDGES_PER_QUERY) {
this.edgesCache.update(id, edges); //缓存这次查询的所有边.标记为一个QueryId
}
}
return edges.iterator();
}至于Schema的缓存读写, 大体也是类似的, 细节稍有不同, 就不重复说了, 它的命中率和使用次数最高, 基本等于常驻内存
总体来说, Hugegraph里的缓存设计是实现了传统的LRU的淘汰策略, 并做了一些小改进, 然后缓存过期通过原生的Timer 定时检查并剔除的, 那么我们之前的假想, 如果想通过内存(空间)换时间. 就等于是给了一个非常大的HashMap ,而Java在处理一个如此大的HashMap对象的时候, JVM在内存管理应该会变得很难处理, 也容易出现问题.. (待确认)
所以如果想在Huge里比如用很大(100G+)内存来做缓存, 可能还是用redis/memcache 这样的分布式缓存, 或者存储自身的缓存要好的多, 图本身则可以用来缓存更结构化的数据, 例如:
- 图的Schema信息. (缓存命中率极高, 频繁)
- 图的Query/Path/Traverser信息. (比如上面的例子, 但是不缓存实际大量的点边数据)
- 子图信息 (...如果之后支持子图相关算法, 包括社群发现, Pagerank迭代的时候复用?)
未完待续, 此文应该补充更细粒度的通用 gremlin 读解析, 拆借为第四篇
- Gremlin 官方文档
- HugeGraph-Server-API 相关源码
- 缓存读流程