
The following gist is intended to Data Engineers. It focuses on Spark and Scala for Machine Learning.
If we want to handle batch and real-time data processing, this gist is definitely worth checking.
We'll learn how to install and use Spark and Scala on a Linux system.
We'll learn latest Spark 2.0 methods and updates to the MLlib library working with Spark SQL and Dataframes.
Please fork it if you find it relevant.
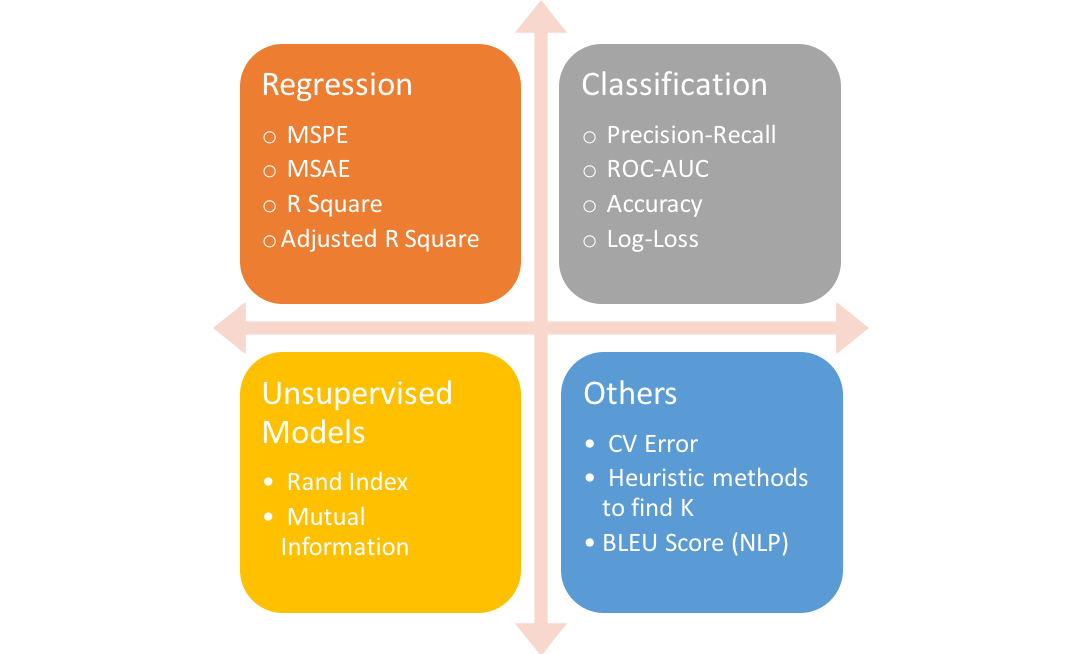
This gist is structured into 2 parts:
. Scala is a general purpose programming language.
. Scala was designed by Martin Odersky (Ecole Polytechnique Fédérale de Lausanne).
. Scala source code is intended to be compiled to Java bytecode to run on a Java Virtual Machine (JVM).
. Java librairies can be used directly in Scala.
. Spark is one of the most powerful Big Data tools.
. Spark runs programs up to 100x faster than Hadoop's MapReduce.
. Spark can use data stored in Cassandra, Amazon S3, Hadoop'sHDFS, etc.
. MapReduce requires files to be stored in HDFS, Spark does not.
. Spark performs 100x faster than Mapreduce because it writes jobs in-memory. Mapreduce writes job on disk.
. MapReduce (Hadoop) writes most data to disk after each Map and Reduce operation.
. Spark keeps most of the data in memory after each transformation.
. At the core of Spark there are Resilient Distributed Datasets also known as RDDs.
. An RDD has 4 main features:
- Distributed collection of data
- Fault-tolerant
- Parallel operations which are partitioned
- An RDD can use many data sources
. RDDs are immutable, cacheable and lazily evaluated.
. There are 2 types of RDD operations:
- Transformations: recipes to follow
- Actions: performs recipe's instructions and returns a result
Environment options for Scala and Spark
- Text editors, such as
Sublime TextandAtom - IDEs (Integrated Development Environments), such as
IntelliJandEclipse - Notebooks, such as
Jupyter,ZeppelinandDatabricks
I've uploaded a .zip file ** which contains useful slides related to MachineLearning, Spark and Scala.
https://bit.ly/2zkcrP7
- Isaac Arnault - Introducing Machine Learning using Spark-Scala - Related tags: #EC2 #TLS #AWSCLI #Linux
** © Perian Data