I've put in place an Elasticsearch cheat-sheet for those preparing an Elastic certification.
Question
answer
_____ is a way to tell Elasticsearch how to configure an index when it is created.
Index Template
A business analyzes sales and consumer use data using Amazon Elasticsearch Service (Amazon ES). Travel is being made by members of the company's globally distributed sales staff. They must sign in to Kibana using their corporate credentials saved in Active Directory. The organization has used Active Directory Federation Services (AD FS) to provide cloud service authentication. Which solution will satisfy these criteria? A company uses Amazon Elasticsearch Service (Amazon ES) to store and analyze its website clickstream data. The company ingests 1 TB of data daily using Amazon Kinesis Data Firehose and stores one day’s worth of data in an Amazon ES cluster. The company has very slow query performance on the Amazon ES index and occasionally sees errors from Kinesis Data Firehose when attempting to write to the index. The Amazon ES cluster has 10 nodes running a single index and 3 dedicated master nodes. Each data node has 1.5 TB of Amazon EBS storage attached and the cluster is configured with 1,000 shards. Occasionally, JVMMemoryPressure errors are found in the cluster logs. Which solution will improve the performance of Amazon ES?
Decrease the number of Amazon ES shards for the index.
A data analyst is designing a solution to interactively query datasets with SQL using a JDBC connection. Users will join data stored in Amazon S3 in Apache ORC format with data stored in Amazon Elasticsearch Service (Amazon ES) and Amazon Aurora MySQL. Which solution will provide the MOST up-to-date results?
Query all the datasets in place with Apache Spark SQL running on an AWS Glue developer endpoint.
A Machine Learning Specialist is building a smart web crawler that will analyze tweets using sentiment analysis. She wants to index the scraped tweet and its sentiment as metadata into an Amazon Elasticsearch cluster for quick data search. Which service will help the Specialist create the application?
Amazon Comprehend
A media analytics company consumes a stream of social media posts. The posts are sent to an Amazon Kinesis data stream partitioned on user_id. An AWS Lambda function retrieves the records and validates the content before loading the posts into an Amazon Elasticsearch cluster. The validation process needs to receive the posts for a given user in the order they were received. A data analyst has noticed that, during peak hours, the social media platform posts take more than an hour to appear in the Elasticsearch cluster. What should the data analyst do reduce this latency?
Increase the number of shards in the stream
A metrics shipper built on the Libbeat framework. It originated from Topbeat (which has now been deprecated) and is primarily used for collecting metrics prior to their enrichment within Logstash for further processing within Elasticsearch & Kibana.
Metricbeat
Amazon Elasticsearch Service (Amazon ES) is used by a business to store and analyze website clickstream data. Daily, the organization uses Amazon Kinesis Data Firehose to collect 1 TB of data and stores one day's worth of data in an Amazon ES cluster. The organization has a very sluggish query performance on the Amazon ES index and sometimes encounters issues when trying to publish to the index using Kinesis Data Firehose. The Amazon ES cluster is comprised of ten nodes that each execute a single index and three dedicated master nodes. Each data node is set with 1.5 TB of Amazon EBS storage, and the cluster contains 1,000 shards. Occasionally, cluster logs include JVMMemoryPressure problems. Which option will optimize Amazon ES's performance?
Decrease the number of Amazon ES shards for the index
By default, elasticsearch node is a master node.
TRUE
By default, X-PACK is installed with the elasticsearch 7 version?
Yes Can we create a custom analyzer in elasticsearch?
Yes
Can we use wildcard-based search in Elasticsearch?
Yes
Each instance of Elasticsearch is called a ______________.
Node
Elasticsearch 7. x and later have a limit of ________ shards per node?
1000
How does Elasticsearch scale the volume of data?
By using Sharding
How much percentage should be Heap size of Elasticsearch node.
50% of RAM
In Elasticsearch, what do provide you with the ability to group and perform calculations and statistics (such as sums and averages) on your data by using a simple search query?
Aggregations
Indices in Elasticsearch < 7.0.0 were created with _______ shards?
5
Is it possible to change field mappings in Elasticsearch?
FALSE
Is there any way to search wrong words so Elasticsearch can give us related words to our search?
Fuzzy Match
Name a free and open platform for single-purpose data shippers. They send data from hundreds or thousands of machines and systems to Logstash or Elasticsearch.
Beats
Name the simple syntax for filtering Elasticsearch data using a free text search or a field-based search? Type the acronym.
KQL
Programming language used in Elasticsearch?
Java
Select all the built-in analyzers in Elasticsearch?
Simple
The Elasticsearch default communication port is
9300/tcp
We can back up an Elasticsearch cluster by simply copying the data directories of all of its nodes?
FALSE
We can not add data in elasticsearch without defining mapping.
FALSE
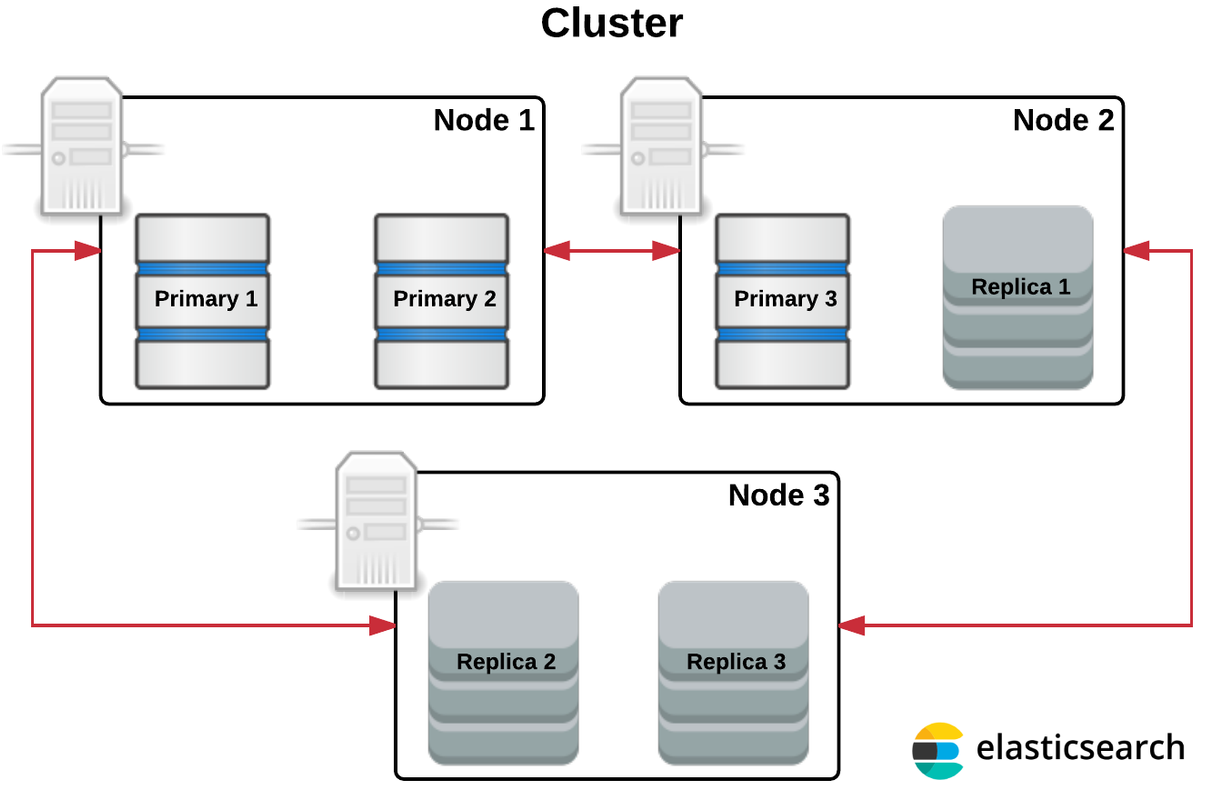
What is the cluster in Elasticsearch?
It is a set of collection of one or more than one nodes or servers
What is the default port number to access elasticsearch?
9200
What is the file format in Elasticsearch?
JSON
What is the syntax to retrieve a document by ID in Elasticsearch?
GET < index_name >/< id >
What refers to a single running instance of Elasticsearch?
Nodes
Which file is used to configure Elasticsearch?
config/Elasticsearch.yml
Which of the following are Advantages of elasticsearch?
All of the above
Which parameter is used to define master in Elasticsearch.yml?
node.master
How many consecutive heartbeats of communication must be lost between the master and the witness host for the witness host to be deemed to have failed?
5
What is Beats?
A collection of data shippers that send data to Elasticsearch or Logstash
A host is declared what when they are not receiving network heartbeats?
Isolated
Select the Beats Family type (Select all applicable answers)?
PacketBeat
Name a free and open platform for single-purpose data shippers. They send data from hundreds or thousands of machines and systems to Logstash or Elasticsearch.
Beats
What is Logstash?
An event processing pipeline
Which is not an advertised feature of Logstash ?
firewall policy adjustment recommendation
A network package analyser used to capture network traffic and can be used to extract useful fields of information from network transactions before shipping them to one or more destinations, including Logstash.
Packetbeat
A metrics shipper built on the Libbeat framework. It originated from Topbeat (which has now been deprecated) and is primarily used for collecting metrics prior to their enrichment within Logstash for further processing within Elasticsearch & Kibana.
Metricbeat
What is the default port number of Kibana?
5601
What is the default port number to access Kibana?
What is Kibana?
An analytics and visualization platform
A business analyzes sales and consumer use data using Amazon Elasticsearch Service (Amazon ES). Travel is being made by members of the company's globally distributed sales staff. They must sign in to Kibana using their corporate credentials saved in Active Directory. The organization has used Active Directory Federation Services (AD FS) to provide cloud service authentication. Which solution will satisfy these criteria?
Enable Amazon Cognito authentication for Kibana on Amazon ES.
What is the Default Port for Kibana is
5601
A metrics shipper built on the Libbeat framework. It originated from Topbeat (which has now been deprecated) and is primarily used for collecting metrics prior to their enrichment within Logstash for further processing within Elasticsearch & Kibana.
Metricbeat
When diagnosing Cisco DNA Center system level issues, which of the following statements is true regarding the Kibana and Grafana visualizations tools?
Kibana is used to view service logs, but Grafana is used to view server metrics.
Select the purpose of Sharding?
To easier fit large indices onto nodes
Able to store more Documents
You need to choose a sharding pattern for sql data warehouse that offers the highest query performance for large tables. Which choice offers the best solutions?
Hash
Sharding is a way to divide indices into smaller pieces?
TRUE
Which sharding overcomes the connection limitation by enabling client browsers to download more resources in parallel?
Domain
Which of the following is true about sharding?
We cannot change a shard key directly/automatically once it is set up
Which of the following is true about sharding?
We cannot change a shard key directly/automatically once it is set up
What is the argument required to disable dynamic mapping?
dynamic= False
What is the default number of primary shards for an Index?
1
The replica will allocate on the same node as the primary shards.
FALSE
What is the Primary Shard?
A shard that has been replicated
What is X-Pack?
A collection of features such as security, monitoring, alerting, reporting, etc
By default, X-PACK is installed with the elasticsearch 7 version?
Yes
What is the full form of E in ELK Stack?
Elasticsearch
Which component is not part of ELK Stack?
Compass
Select all the tools under Elastic Stack.
Beats
elasticsearch
Logstash
Kibana
X-PACK
It is possible to change field mappings in Elastic search.
FALSE
Which one is valid SQL for an Index?
CREATE INDEX ID;
What is an index?
A structure that enables you to locate rows in a table quickly, using an indexed value
In _______________ index instead of storing all the columns for a record together, each column is stored separately with all other rows in an index.
Column store
If an index is _________________ the metadata and statistics continue to exists.
Disabling
Which of the following are allowable data types for an index?
String, Integer, Real, and Enumerated
___________ is way to tell Elasticsearch how to configure an index when it is created.
Index Template
What is the command to check the indices?
GET /_cat/indices
__________ is a secondary name used to refer to one or more existing indices.
Index Alias
What is the cluster in Elasticsearch?
It is a set of collection of one or more than one nodes or servers
In Language Analyzer, what does provide many language-specific analyzers like English or French?
Elasticsearch
Select all the states of Shards
Started
Initializing
By default alias is defined for a document
FALSE
What is command used to reindex?
/_reindex
Command to check the indices?
GET /_cat/indices
Select the types of mapping in Elasticsearch:
Static Mapping
Dynamic Mapping
What is the work of WhiteSpace Analyzer?
Splits text tokens
… this way Elasticsearch will not add any value if data type is not defined
dynamic:Strict
Select all the built-in analyzers in Elasticsearch?
Simple
The value will be allowed only if the value has data type is called as a
Strict Dynamic
We change mapping if there is already some data in it
FALSE
Which argument is used to run Elasticsearch in the background?
"-d"
What is the command to set a password for Elasticsearch authentication?
Elasticsearch-setup-passwords interactive
Which parameter is used to define the tag for a node?
node.attr
You can use a ….. Search to filter and analyze log data stored on clusters in different data clusters?
Cross cluster
Which utility is used to generate a self-signed certificate for the Elasticsearch cluster?
Elasticsearch-certutil
Which state means the cluster is in healthy state?
Green
How does Elasticsearch ensure high availability
By using replication
What characterized term-level queries?
Term level queries match exact values and are not analyzed
Which argument is used to define pagination for the query search?
Size
What characterizes full-text queries?
Full-text queries are analyzed using the analyzed defined for the Searched filed
… Helps in the collection of data from the query used in the search
Aggregations
… is a noop analyzer that returns the entire input string as a single token
Keyword
Aggregations can be performed for string on the only keyword
TRUE
… works on the output produced by other aggregations transforming the values already computed by them
Pipeline
… provide you with the ability to group and perform calculations
Aggregations
Which aggregation helps in calculating matrices from fields of aggregated document values?
Metric
… helps in the collection of data from the query used in the search
Aggregations
… creates buckets of documents
Bucket
What is the command used to get mappings?
GET //_mapping
Which data type we can use to do aggregations, sorting, or filtering on exact values?
Keyword
Text Analysis is performed by an
Analyzer
… is a single piece of an Elasticsearch index
Shard
… allows us to define a type for index
Mapping