!SLIDE
"Follow your nose"
— Roy T. Fielding
!SLIDE
"build scalable, flexible implementations that do not simply run on the Web, but that actually exist in the Web"
— Mike Admundsen
!SLIDE
@jamiemhodge
ITMEDIA, University of Copenhagen Faculty of Humanities
Mixed Media
!SLIDE

!SLIDE

!SLIDE

!SLIDE

!SLIDE
- The Web
- Richardson Maturity Model
- REST & Hypermedia
- Affordances
- Design
!SLIDE
"WWW is fundamentally a distributed hypermedia application"
— Richard Taylor
"...client and server applications are built, modified, and maintained independently"
— Mike Admundsen
!SLIDE
user agent-representation-server software
!SLIDE
- GET /{service}/{document}
- Read-only
- No headers
- Mirror files pass-by-object
- Links and embedded content
!SLIDE
- DELETE /{service}/{document}
- Read/Write
- Headers (metadata)
- MIME Types pass-by-value
- Parameterized queries and operations
!SLIDE
"This ability to support not only navigational links (HTML anchor tags) and in-place rendering of related content (e.g. the IMG tag) but also parameterized queries and write operations helped HTML become the lingua franca of the Web"
— Mike Admundsen
!SLIDE
- MIME Type = Media Type = Content Type
- Content negotiation
AcceptandContent-Type
- Representations of resources
- Extensible
!SLIDE
- A client-server contract
- How data is transferred
- How application flow control is communicated
!SLIDE
"The development of the Web follows the introduction of hypermedia links as a method of not only navigating between documents but also through the use of hypermedia controls that support sending parameterized queries and write instructions to remote servers"
— Mike Admundsen
!SLIDE
"Roy’s REST codifies (to some extent reverse-engineeres) the Web into a set of constraints."
— Subbu Allamaraju Protocols vs Styles
!SLIDE
- Client-server
- Stateless
- Cacheable
- Layered system
- Code on Demand
- Uniform Interface
!SLIDE
- Identification of resources
- Manipulation of those resources through these representations
- Self-descriptive messages (MIME)
- Hypermedia as the engine of application state
!SLIDE
!SLIDE
- SOAP, XML, RPC, POX
- Single URI
http://{service}/{method}
method(arguments)
!SLIDE
- URI Tunnelling
- Many URIs, Single verb
http://{service}/{resource}/{method}?{arguments}
Resource.method(arguments)
!SLIDE
- CRUD
- Many URIs (templates), many verbs, status codes
DELETE http://{service}/{resource}
Resource.destroy #=> true
!SLIDE
"What's important is that GET has constraints on its meaning, and when there are constraints you can optimize around them: conditional GET, partial GET, reliability, cachability, and so on. This is the value of the uniform interface."
"The downside is that when you add HTTP methods you limit the universe of clients that can understand the semantics of your service. Beyond a certain point it's better to describe the specifics of an operation with hypermedia."
— Leonard Richardson
!SLIDE
"I am getting frustrated by the number of people calling any HTTP-based interface a REST API....
What needs to be done to make the REST architectural style clear on the notion that hypertext is a constraint? In other words, if the engine of application state (and hence the API) is not being driven by hypertext, then it cannot be RESTful and cannot be a REST API. Period. Is there some broken manual somewhere that needs to be fixed?"
— Roy T. Fielding
!SLIDE
"Instead, S3 gives you these key, and some rules you need to know to turn those names into URIs. Where are these rules? You have to read the S3 documentation. You'd never see this kind of document on the web, unless it was part of a scavenger hunt."
"Putting aside the fact that it's annoying to not just have those URIs where you can use them, this design creates a coupling between the client and this particular web service. You've got to write custom client code that you can't reuse.
And Amazon doesn't get anything out of not providing URIs. In fact, they've kind of painted themselves into a corner, because their clients are coupled not to the contents of XML documents which Amazon can change easily, but to the contents of the human-readable documents that describe how to make these URIs."
— Leonard Richardson
!SLIDE
- CRUD + Hypermedia
- Single URI entry point, many verbs, status code, links and controls
GET http://{service}
resource = Resource.new
resource.associations
resource.methods
!SLIDE
"A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API). From that point on, all application state transitions must be driven by client selection of server-provided choices that are present in the received representations or implied by the user’s manipulation of those representations."
— Roy T. Fielding
!SLIDE
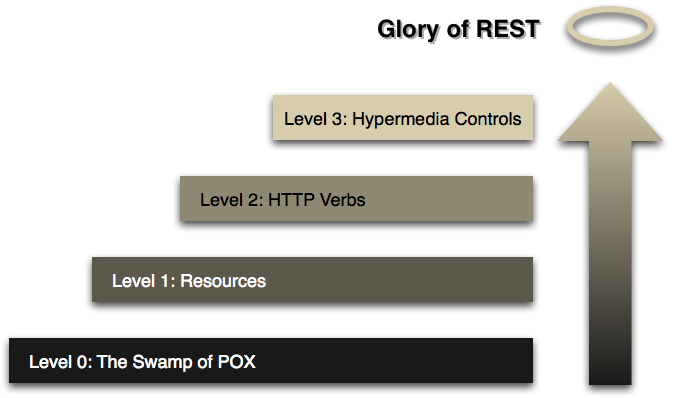
"Level 1 tackles the question of handling complexity by using divide and conquer, breaking a large service endpoint down into multiple resources. Level 2 introduces a standard set of verbs so that we handle similar situations in the same way, removing unnecessary variation. Level 3 introduces discoverability, providing a way of making a protocol more self-documenting."
— Martin Fowler citing Ian Robinson
!SLIDE
"So here's the lesson of HTML. Connections between resources are a form of data, and they should be described in the documents with the rest of the data. Let your clients focus on looking at that document and making decisions about what to do next. Not on internalizing your particular rules about where on the web you put your data."
"When information about the capabilities of resources is described with hypermedia, the developer doesn't have to do that work. The just have to simulate a person sitting at their web browser, looking at the web page and deciding what link to click and how to fill out the forms. This is still a difficult task, in fact it's the most difficult part of the task, but it's less difficult than simulating the person and also simulating part of the web browser."
— Leonard Richardson
!SLIDE
!SLIDE
!SLIDE
- Updated API? Break clients
- Moved API? Break clients and documentation
- Modified or extended process flow? Break clients and corrupt data
!SLIDE
"Reprogramming participants on the Web may be possible when there are only a few parties involved, but it does not scale up to the thousands and millions of participants that interact on the Web today"
— Mike Admundsen
!SLIDE
"How can a server successfully export its private objects in a way that clients can see and use them?"
!SLIDE
Object-Server-Representation-Client-Object
- Binds
- internal objects to public API
- client to server
- Brittle, inflexible, poor encapsulation
- Server-centric
!SLIDE
- Shared schema
- URI construction
- Payload decoration
- Narrow media types
!SLIDE
"All of those points are rather small compared to my overall complaint that it isn’t appropriate to define a “REST” binding to a specific data model’s limitations. The whole point of REST is to avoid coupling between the client applications and whatever implementation might be behind the abstract interface provided by the server. REST accomplishes that by eliminating the need to think in terms of resource types or specialized interfaces. Instead, the representations tell the application how and what it can do next. Any resource can potentially be viewed as a document or as a folder, depending on how one might want to look at the information. The trick is to define how such resources are related to one another in an implementation-independent manner that can be provided as the interface to any back-end, not just a back-end that corresponds to one data model."
— Roy T. Fielding
!SLIDE
"How can a server and client share a common understanding of the payloads passed between them?"
!SLIDE
"A technique for describing data in a way that is not bound to any internal type, programming language, web framework, or operating system"
— Mike Admundsen
!SLIDE
- Raw data
- Metadata about the data
- Metadata about the state of the application
!SLIDE
- labels
- hierarchies
- relationships
!SLIDE
- current state
- possible (content-sensitive)
- transitions: navigate
- actions: filter, search, add, edit, delete, etc.
!SLIDE
"It's the availability of application metadata in the message that turns an ordinary media type into a hypermedia type"
"The essence of programming the Web is designing hypermedia-rich messages that can be understood and passed between parties on the network... The Web encourages the use of coarse-grained messages that include metadata that describes not only the data being passed but also the state of the application at the time of the request. The set of hypermedia elements that can be used to communicate application state changes... is the same regardless of the data format used to transfer the message"
— Mike Admundsen
!SLIDE
"A Hypermedia Type is a media type that contains native hyperlinking elements that can be used to control application flow"
— Mike Admundsen
!SLIDE
"When I say hypertext, I mean the simultaneous presentation of information and controls such that the information becomes the affordance through which the user (or automaton) obtains choices and selects actions. Hypermedia is just an expansion on what text means to include temporal anchors within a media stream; most researchers have dropped the distinction.
Hypertext does not need to be HTML on a browser. Machines can follow links when they understand the data format and relationship types."
— Roy T. Fielding
!SLIDE
"The media type identifies a specification that defines how a representation is to be processed. That is out-of-band information (all communication is dependent on some prior knowledge). What you are missing is that each representation contains the specific instructions for interfacing with a given service, provided in-band. The media type is a generic processing model that every agent can learn if there aren’t too many of them (hence the need for standards). The representation is specific to the application being performed by the agent. Each representation therefore provides the transitions that are available at that point in the application... important to me is that the same design reflects good human-Web design, and thus we can design the protocols to support both machine and human-driven applications by following the same architectural style."
— Roy T. Fielding
!SLIDE
- Links
- Embedded/External
- Templated
- Idempotent/Non-idempotent
- Controls
- Read
Accept,Accept-Language - Update
<form enctype=''>Content-Type - Method
<form method=''> - Link annotations
<a rel='edit'>
- Read
!SLIDE
- Base Format
- State Transfer (from client to server)
- Domain Style
- Application Flow
!SLIDE
- XML
- JSON
- HTML !!
!SLIDE
No native support for links or control elements
!SLIDE
Native support for links <a> and control elements <form> <input> <textarea> <select> etc.
!SLIDE
Client to Server representation transfer
!SLIDE
- Read-only
- Predefined e.g. ATOM
<feed><entry> - Ad-Hoc e.g. inline
form
!SLIDE
"Think of it in terms of the Web. How many Web browsers are aware of the distinction between an online-banking resource and a Wiki resource? None of them. They don’t need to be aware of the resource types. What they need to be aware of is the potential state transitions — the links and forms — and what semantics/actions are implied by traversing those links. A browser represents them as distinct UI controls so that a user can see potential transitions and anticipate the effect of chosen actions. A spider can follow them to the extent that the relationships are known to be safe. Typed relations, specific media types, and action-specific elements provide the guidance needed for automated agents."
— Roy T. Fielding"
!SLIDE
"... the process of selecting element and attribute names, deciding where hierarchies should exist... translating the problem domain into message form"
"focuses on the information that needs to be shared, stored, computed, etc. [i.e. resource lifecycles]"
— Mike Admundsen
!SLIDE
- Specific
<customer></> - General
<item></> - Agnostic
<article class='item'>
!SLIDE
"more than just including links and forms in responses. Application flows require identifications for the various possible options for changing the state of the application"
— Mike Admundsen

!SLIDE
- None
- Intrinsic
<update><link rel='update'>
- Applied
<div id='' class=''><a rel=''><input name=''>
!SLIDE
- Closed: control element
- Open: relation values, applied consistently to specific elements and attributes
- Publish
<meta name='profile' content='/profile'>- relation values
- meaning
- purpose
- relation values
!SLIDE
"To some extent, people get REST wrong because I failed to include enough detail on media type design within my dissertation. That’s because I ran out of time, not because I thought it was any less important than the other aspects of REST....
However, I think most people just make the mistake that it should be simple to design simple things. In reality, the effort required to design something is inversely proportional to the simplicity of the result. As architectural styles go, REST is very simple.
REST is software design on the scale of decades: every detail is intended to promote software longevity and independent evolution. Many of the constraints are directly opposed to short-term efficiency. Unfortunately, people are fairly good at short-term design, and usually awful at long-term design. Most don’t think they need to design past the current release. There are more than a few software methodologies that portray any long-term thinking as wrong-headed, ivory tower design (which it can be if it isn’t motivated by real requirements)."
— Roy T. Fielding
!SLIDE
"I don't think we have enough examples yet to be really sure that the restful approach is the right way to integrate systems, I do think it's a very attractive approach and the one that I would recommend in most situations."
— Martin Fowler