-
-
Save jkbradley/ab8ae22a8282b2c8ce33 to your computer and use it in GitHub Desktop.
| /* | |
| This example uses Scala. Please see the MLlib documentation for a Java example. | |
| Try running this code in the Spark shell. It may produce different topics each time (since LDA includes some randomization), but it should give topics similar to those listed above. | |
| This example is paired with a blog post on LDA in Spark: http://databricks.com/blog | |
| Spark: http://spark.apache.org/ | |
| */ | |
| import scala.collection.mutable | |
| import org.apache.spark.mllib.clustering.LDA | |
| import org.apache.spark.mllib.linalg.{Vector, Vectors} | |
| import org.apache.spark.rdd.RDD | |
| // Load documents from text files, 1 document per file | |
| val corpus: RDD[String] = sc.wholeTextFiles("docs/*.md").map(_._2) | |
| // Split each document into a sequence of terms (words) | |
| val tokenized: RDD[Seq[String]] = | |
| corpus.map(_.toLowerCase.split("\\s")).map(_.filter(_.length > 3).filter(_.forall(java.lang.Character.isLetter))) | |
| // Choose the vocabulary. | |
| // termCounts: Sorted list of (term, termCount) pairs | |
| val termCounts: Array[(String, Long)] = | |
| tokenized.flatMap(_.map(_ -> 1L)).reduceByKey(_ + _).collect().sortBy(-_._2) | |
| // vocabArray: Chosen vocab (removing common terms) | |
| val numStopwords = 20 | |
| val vocabArray: Array[String] = | |
| termCounts.takeRight(termCounts.size - numStopwords).map(_._1) | |
| // vocab: Map term -> term index | |
| val vocab: Map[String, Int] = vocabArray.zipWithIndex.toMap | |
| // Convert documents into term count vectors | |
| val documents: RDD[(Long, Vector)] = | |
| tokenized.zipWithIndex.map { case (tokens, id) => | |
| val counts = new mutable.HashMap[Int, Double]() | |
| tokens.foreach { term => | |
| if (vocab.contains(term)) { | |
| val idx = vocab(term) | |
| counts(idx) = counts.getOrElse(idx, 0.0) + 1.0 | |
| } | |
| } | |
| (id, Vectors.sparse(vocab.size, counts.toSeq)) | |
| } | |
| // Set LDA parameters | |
| val numTopics = 10 | |
| val lda = new LDA().setK(numTopics).setMaxIterations(10) | |
| val ldaModel = lda.run(documents) | |
| val avgLogLikelihood = ldaModel.logLikelihood / documents.count() | |
| // Print topics, showing top-weighted 10 terms for each topic. | |
| val topicIndices = ldaModel.describeTopics(maxTermsPerTopic = 10) | |
| topicIndices.foreach { case (terms, termWeights) => | |
| println("TOPIC:") | |
| terms.zip(termWeights).foreach { case (term, weight) => | |
| println(s"${vocabArray(term.toInt)}\t$weight") | |
| } | |
| println() | |
| } |
tokenized[1] is an RDD of tokenized documents so converting them into term count vectors is indeed a distributed operation (i.e. "done in map reduce").
[1] https://gist.github.com/jkbradley/ab8ae22a8282b2c8ce33#file-lda_sparkdocs-L19
Hi, Is there a way to generate terms/weight for each topic like in the screenshot:
https://databricks.com/wp-content/uploads/2015/03/Spark-docs.png
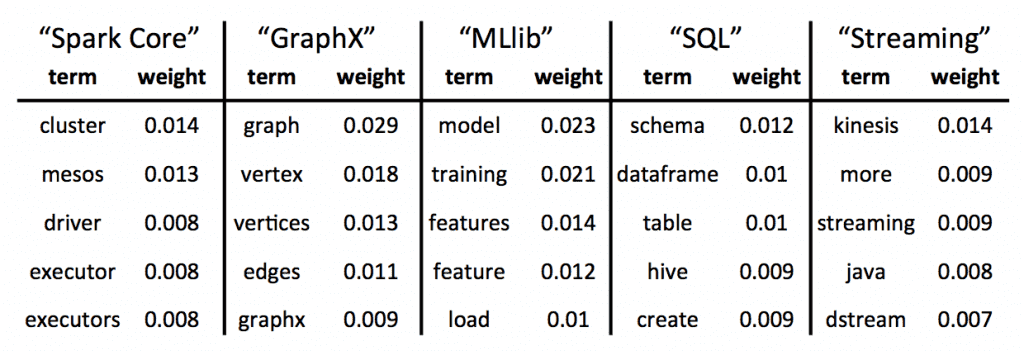{kind=link}
the code will raise "org.apache.spark.SparkException: Task not serializable".I fix it this way and i use spark 1.4.
LDA().setK(numTopics).setMaxIterations(10).run(documents)
So I seem to have an implementation issue of getting all the same topics. I have the issue on both my custom data as well as the 20 News Groups.
I import the data with:
val corpus: RDD[String] = sc.wholeTextFiles("C:/Users/dreyco676/Desktop/20_newsgroups/*/*").map(_._2)
The rest is exactly the same code as is the Gist. But I get:
TOPIC:
more 0.005217208636956542
than 0.004616388745415586
people 0.00450498752399804
other 0.004428023897931391
only 0.004397520854580642
university 0.004218285799152583
been 0.004195655057724472
know 0.004189353242600861
think 0.003948569283092488
does 0.003593475763653907
TOPIC:
more 0.004918280931884248
people 0.004560412694857893
other 0.004457584588270678
university 0.004421378022668589
than 0.004346075920988981
only 0.0042215242074262
know 0.004195765754451906
been 0.004143742511468107
think 0.0038718360648051374
does 0.003634062257801975
TOPIC:
people 0.004955981677196874
more 0.004781698245412742
than 0.004512705569270228
been 0.004476402436726267
other 0.004328697216637016
only 0.0043268994713863565
know 0.004306598622875322
university 0.0042831795204390875
think 0.00417745067584956
does 0.003559752569608692
etc..
I don't get neither, I have the issue. Any clues upon that?
Hi, I get same kind of results as the one shown by @dreyco676.
any idea how to fix?
Hello, how can we estimate:
2- How many workers I need and how large is the memory on each of them?
1- How many stages the LDA will take to finish?
2- How long gonna be the processing knowing the number of workers and knowing that we have enough memory on each node.
Thanks
from here - https://databricks.com/blog/2015/09/22/large-scale-topic-modeling-improvements-to-lda-on-spark.html
Make sure to run for enough iterations. Early iterations may return useless (e.g. extremely similar) topics, but running for more iterations dramatically improves the results. We have noticed this is especially true for EM
Hi,
I was having the same issue of getting the same results with @dreyco676. When I increased the iterations to 20; more different terms came up. Thanks @dzianis-shender!
I am having difficulty in interpreting an error after this command:
val avgLogLikelihood = ldaModel.logLikelihood / documents.count()
Since I've compiled each command one after the other, I was able to detect the error. The error message I'm getting is that logLikelihood is not a member of org.apache.spark.mllib.clustering.LDAModel.
How can I fix this? Thank you!
AJ
Hey @boolean85, the reason is that for some reason the value of ldaModel is of type LDAModel but the instance is of type DistributedLDAModel, so just cast it before getting the value
val avgLogLikelihood = ldaModel.asInstanceOf[DistributedLDAModel].logLikelihood / documents.count()
Any one able to get the results as expected by @vsingh58
how can I get consistent topic distributions? I know LDA uses randomness in training, but if I use setSeed shouldn't the topics and calculated topic distributions always be the same on each run?
val ldaParams: LDA = new LDA().setK(10).setMaxIterations(60).setSeed(10L)
val distributedLDAModel: DistributedLDAModel = ldaParams.run(corpusInfo.docTermVectors).asInstanceOf[DistributedLDAModel]
val topicDistributions: Map[Long,Vector] = distributedLDAModel.topicDistributions.collect.toMap //produces different results on each runHello,
I am training a LDA model on wikipedia articles(4 million docs, ~14GB data). I am running a scala script on one machine with ~98GB memory. I run the scala code in spark shell with following params:
$SPARK_HOME/bin/spark-shell --executor-memory 2G --driver-memory 25G --total-executor-cores 10 --conf spark.driver.maxResultSize=50g
I have scala code very similar to the above. No matter what driver memory, executor memory or maxResultSize memory I keep, I get OutOfMemory error or maxResultSize exceeded error
Could you please help me figure out the right settings?
Thanks!
Hi I have my data stored in a Sql Table. I scrapped a newpaper data and stored it ina sql table.
I am importing a column from of contents which contains the news article(content) and docID as
dataframe_mysql.registerTempTable("HT")
val data = sqlContext.sql("Select content,id from HT limit 2").toDF("text","docId").cache
data: org.apache.spark.sql.DataFrame = [text: string, docId: int]
data.show(1)
+--------------------+-------+
| text | docId |
+--------------------+-------+
|The Panama Papers...| 1 |
+--------------------+--------+
Can someplease help me how can modify this as a standard inout for this algorithm
I have found the solution myself.
I just mapped the data and got the input in standard form .
val corpus = data.map{x:Row => x.getAsString}
corpus: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[83] at map at :52.
Now I don't want to print the the final output . I want to save it in a dataFrame. So that I can store it as a table in Hive.
val topicIndices = ldaModel.describeTopics(maxTermsPerTopic = 5)
topicIndices.foreach { case (terms, termWeights) =>
println("TOPIC:")
terms.zip(termWeights).foreach { case (term, weight) =>
println(s"${vocabArray(term.toInt)}\t$weight")
}
println()
}
topicIndices: Array[(Array[Int], Array[Double])] = Array((Array(0, 2, 3, 1, 4),Array(0.00350628017263507, 0.0034694474589591524, 0.003438757757561852, 0.003436255047934638, 0.003163149677097968)), (Array(0, 3, 2, 1, 4),Array(0.0036033828372688545, 0.003475759951074189, 0.0034649895837134807, 0.003435509739061473, 0.0031197044381247384)), (Array(0, 2, 1, 3, 4),Array(0.0035777177552655955, 0.0035349785708481277, 0.003533272120787881, 0.003387443930605837, 0.003293978337255521)), (Array(0, 1, 2, 3, 4),Array(0.003582087659862847, 0.003542792277259787, 0.0034411804067727104, 0.003396808386547253, 0.0032547793346400836)), (Array(0, 3, 2, 1, 4),Array(0.003564513879334988, 0.0034774762675255965, 0.0034378278250957604, 0.0033565986686143186, 0.0030693802853424055)), (Array(0, 2, 3, 1, 4),Array(0...TOPIC:
would 0.00350628017263507
what 0.0034694474589591524
people 0.003438757757561852
india 0.003436255047934638
your 0.003163149677097968
Please help me to tweak this code to save this data rather than printing it on screen
Hi,
I'd like to train a LDA model to data from Twitter, I compiled this code until step
val lda = new LDA().setK(numTopics).setMaxIterations(10)
I get this error
error: reference to LDA is ambiguous;
it is imported twice in the same scope by import org.apache.spark.ml.clustering.LDA and import org.apache.spark.mllib.clustering.LDA
val lda = new LDA().setK(numTopics).setMaxIterations(10)
Could someone please help me ? I use spark 2.0.0
Thanks !
Hi,
it seems that you all figured out how to deal with the Problem of similar (in my case even same) Topics. Maybe someone can help me, too?
My corpus exists of Tupel2<Long, Vector> where the Vector is a denseVector made of an Array with doubles.
Then I just tried the following:
LDAModel ldaModel = new LDA().setK(3).setMaxIterations(100).run(corpus);
final scala.Tuple2<int[],double[]>[] topics = ldaModel.describeTopics(v_AnzahlTerme);
List result2 = new java.util.ArrayList<>();
for (scala.Tuple2<int[],double[]> tmp : topics) {
for (int i=0; i<3;i++)
{
for (int j=0; j<tmp._1().length;j++)
{
result2.add(RowFactory.create(i, tmp._1()[j], tmp._2()[j]));
}
}
}
return sc.parallelize(result2);
Are there any obvious Errors?
Thank you for any help!
Anja
@colinmolter
val corpus: RDD[String] = sc.wholeTextFiles("docs/*.md").map(_._2) get the topic words are same,
should change it toval corpus = sc.textFile("docs/*.md")
Hi,
May I know how to change the word to some short phrase, such as public holiday, banking holiday and their weights accordingly. Shall we consider using n-gram.
Regards
Sprint
Thanks,
Shouldn't the step with the title 'Convert documents into term count vectors' be done in map reduce as well?