-
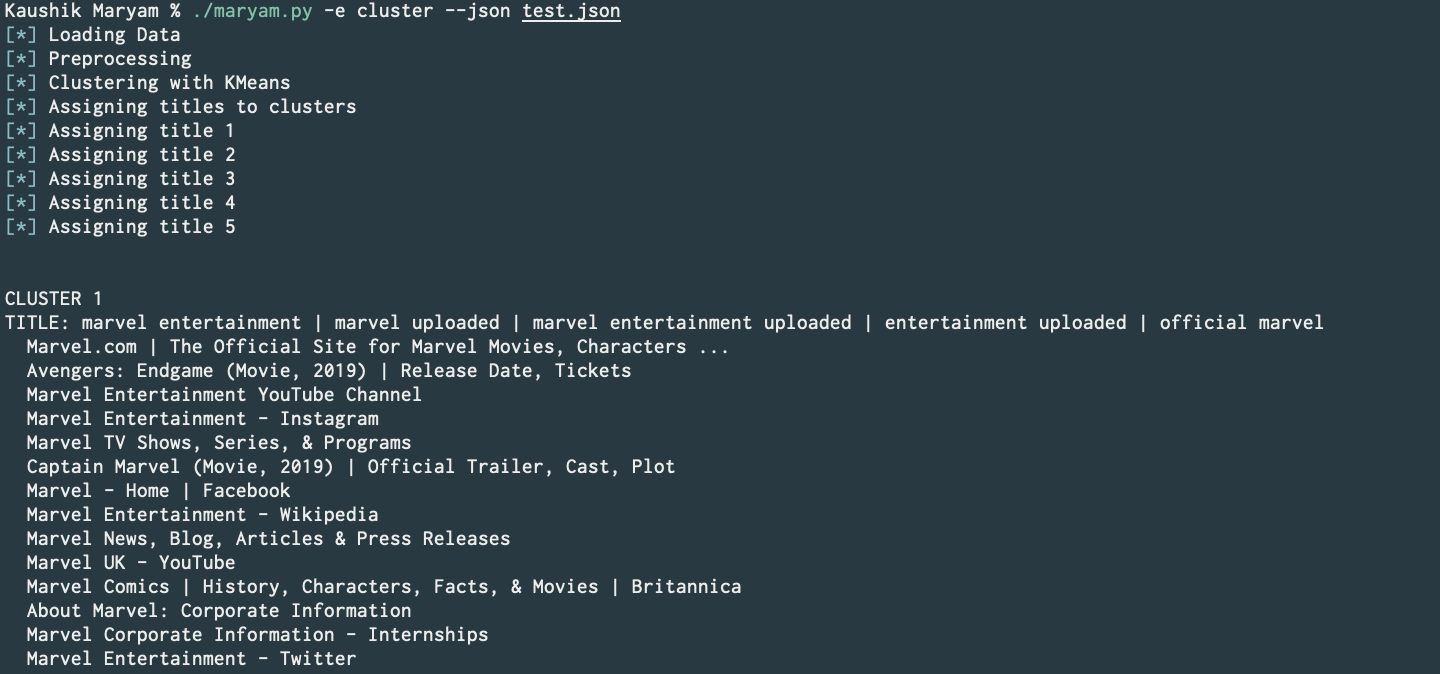
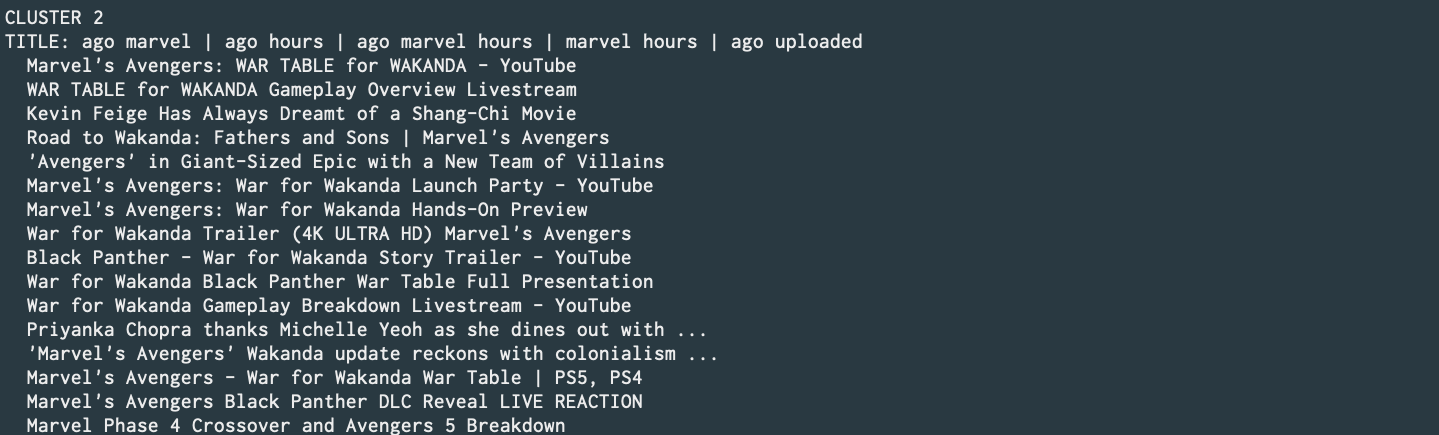
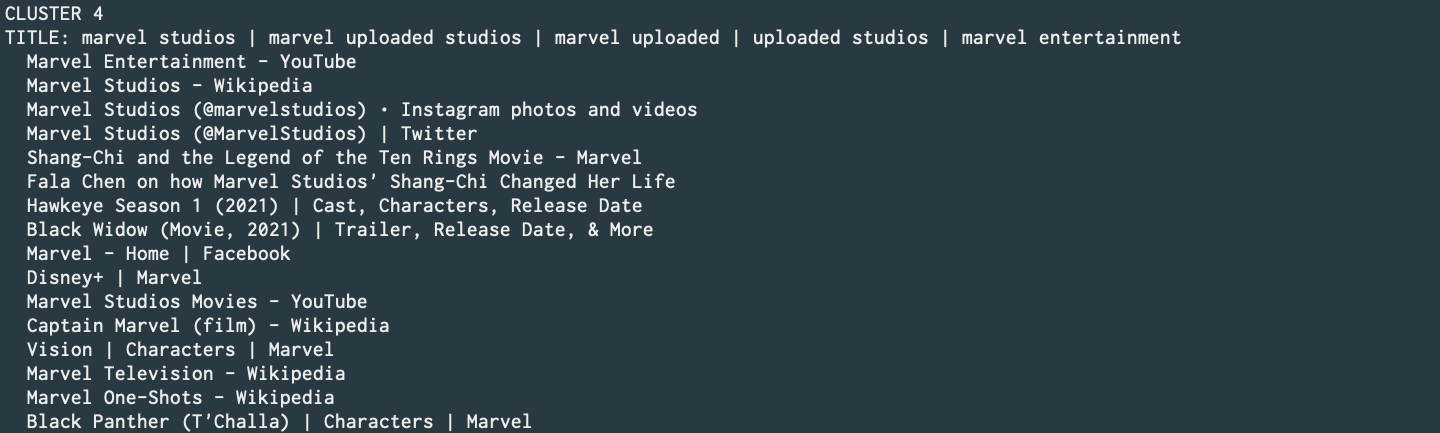
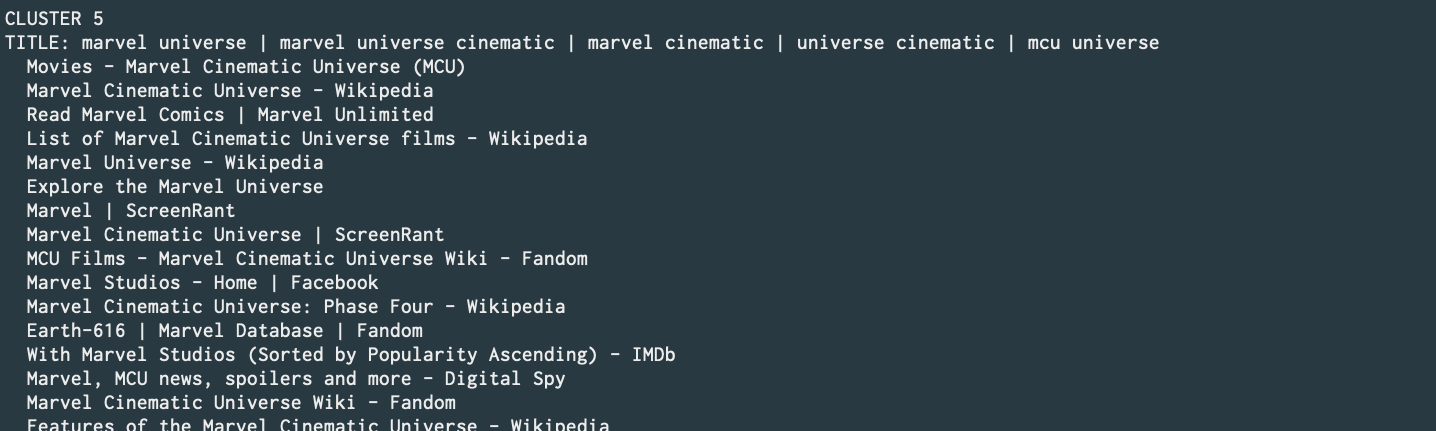
Designed and implemented a text document clustering module using KMeans and FP-growth. This shall be utilized within Iris; Maryam's metasearch engine. (Commit) (Personal repo link)
-
Generate text data using,
./maryam.py -e google -q 'Marvel' -l 10 --api --format > test.json -
Pass it to cluster module with,
./maryam.py -e cluster --json test.json
-
-
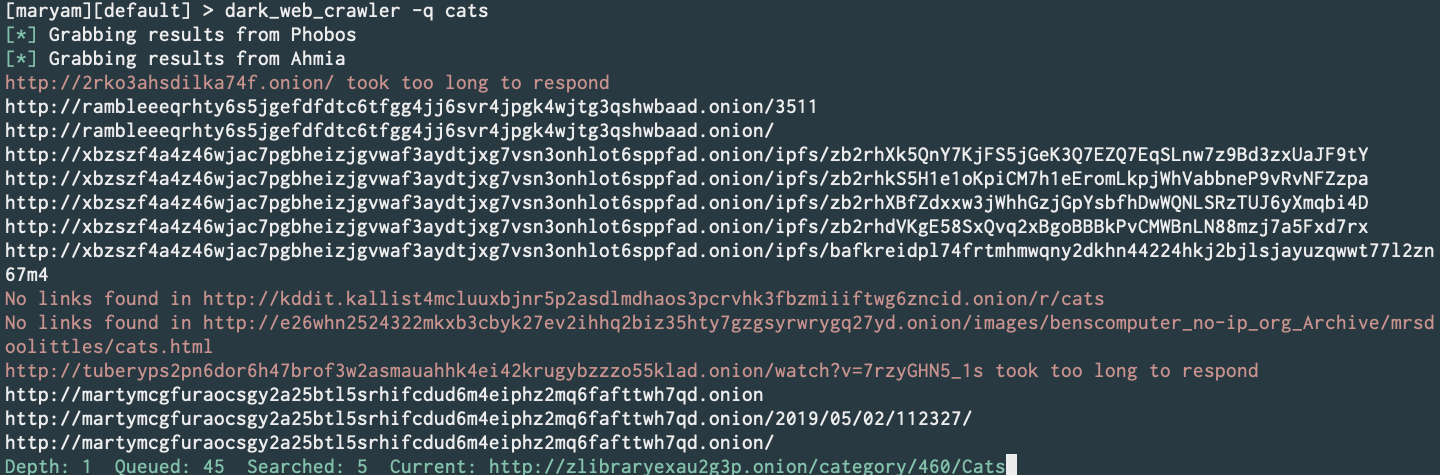
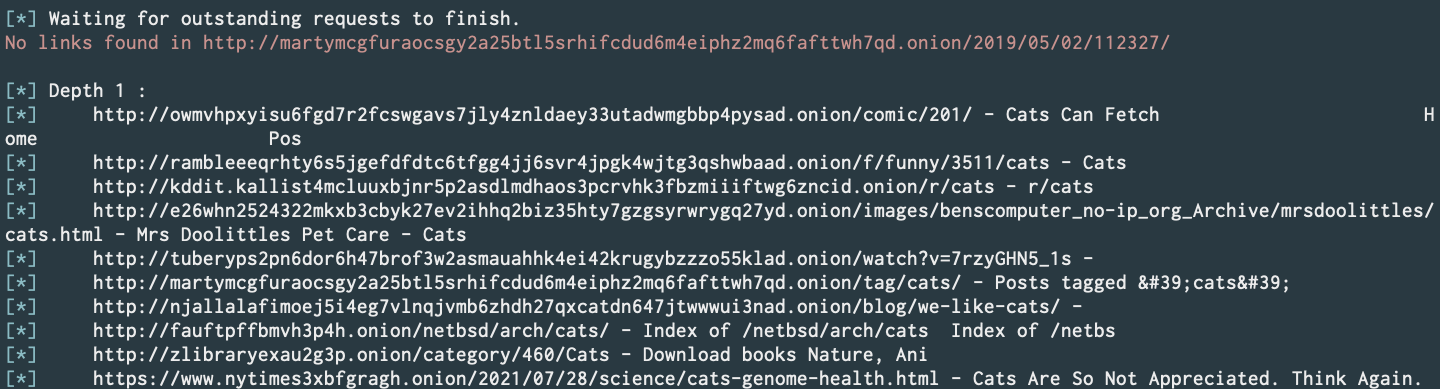
Designed and implemented a smart dark web crawler module, with a custom TFIDF text retriever class using cosine similarity to rank best pages to crawl per Snowball Sampling iteration. (Commit) (Note: explicit results not shown unless searched for)
In progress:
Results after reaching target depth:
-
Implemented various search modules over diverse sources, namely,
-
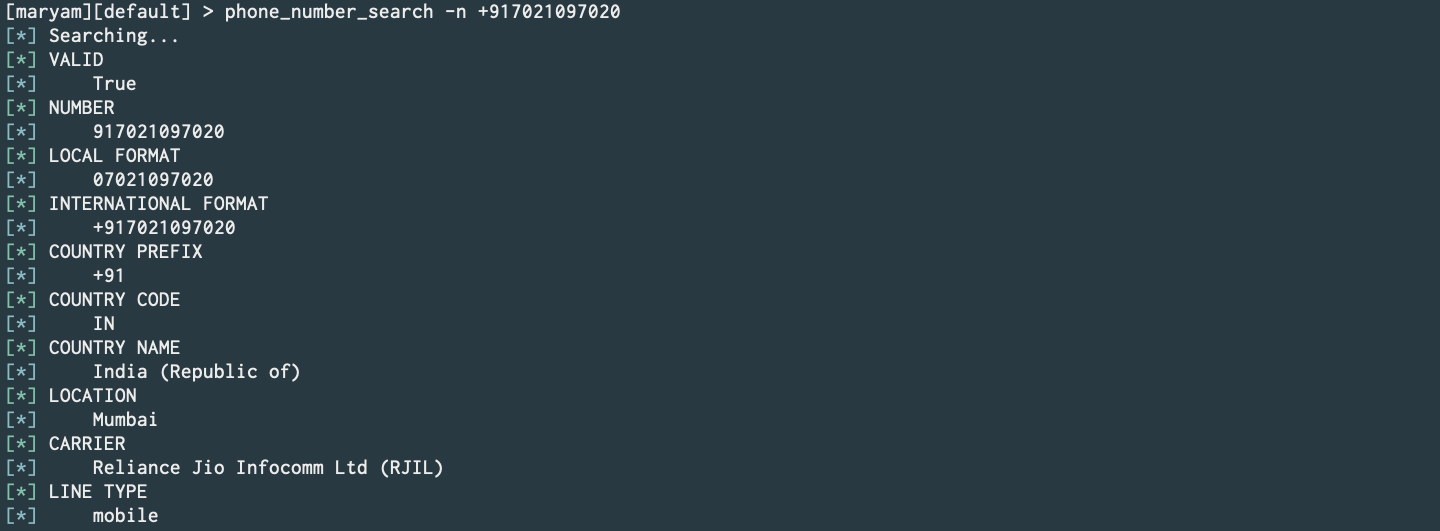
Phone Number Search using NumVerify (PR).
-
Dictionary module using Google Dictionary (PR).
-
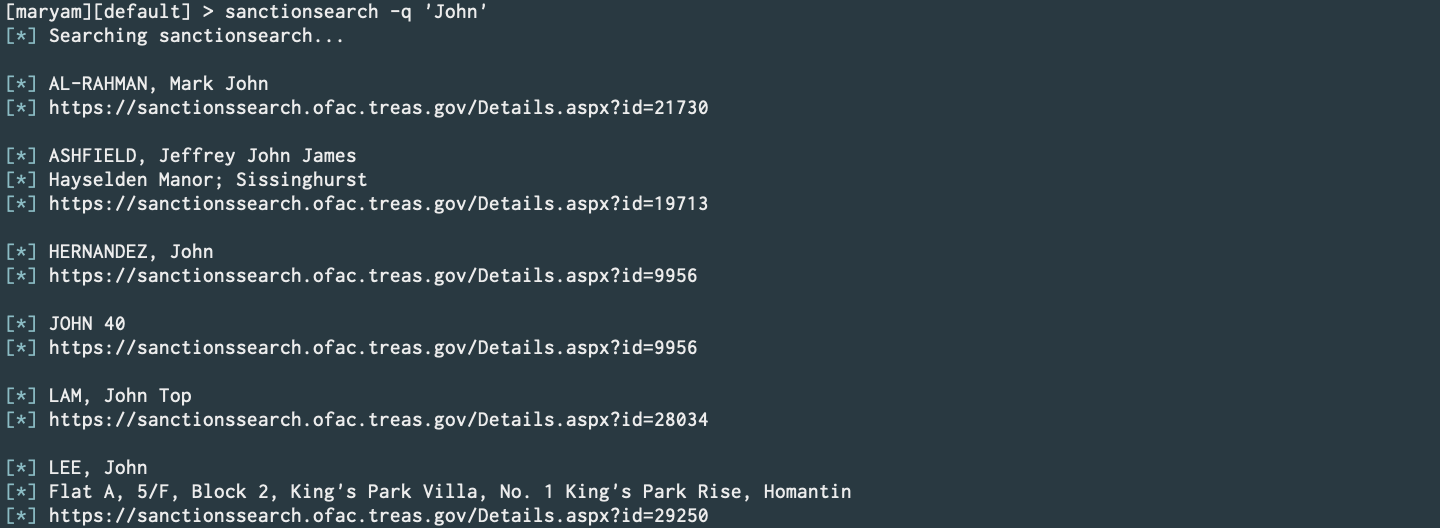
SanctionSearch (PR)
-
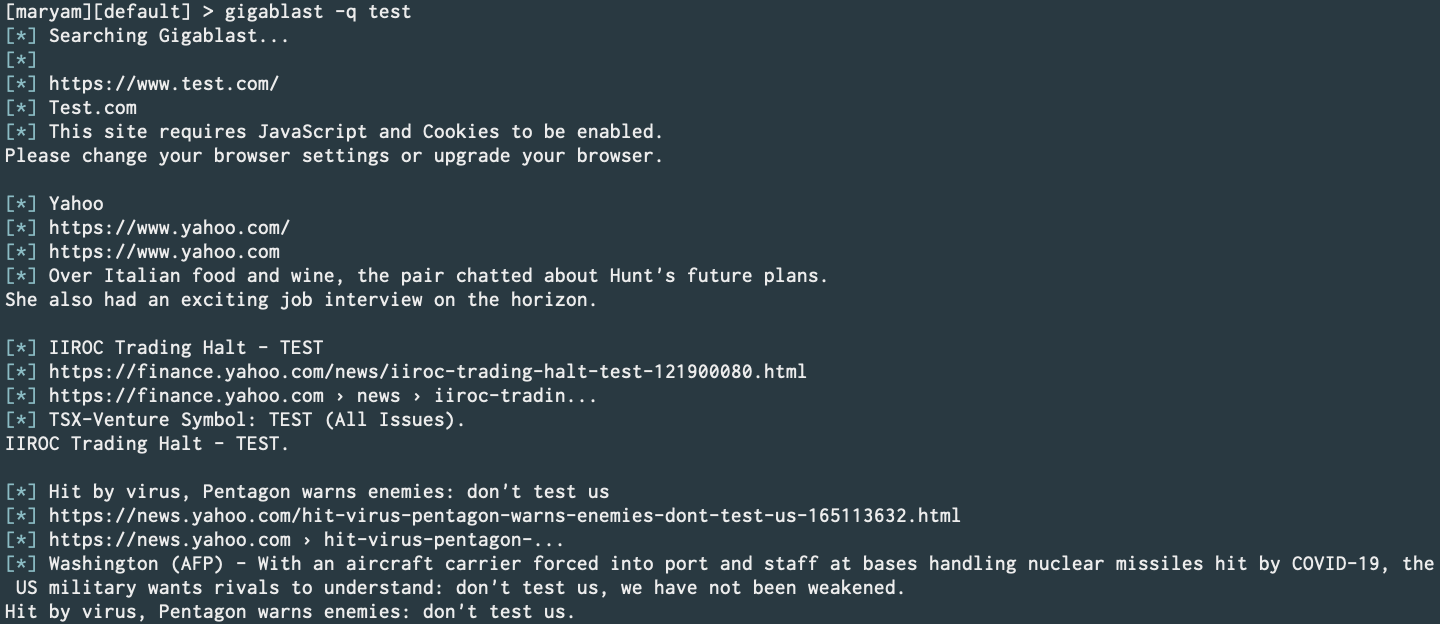
Gigablast (PR)
-
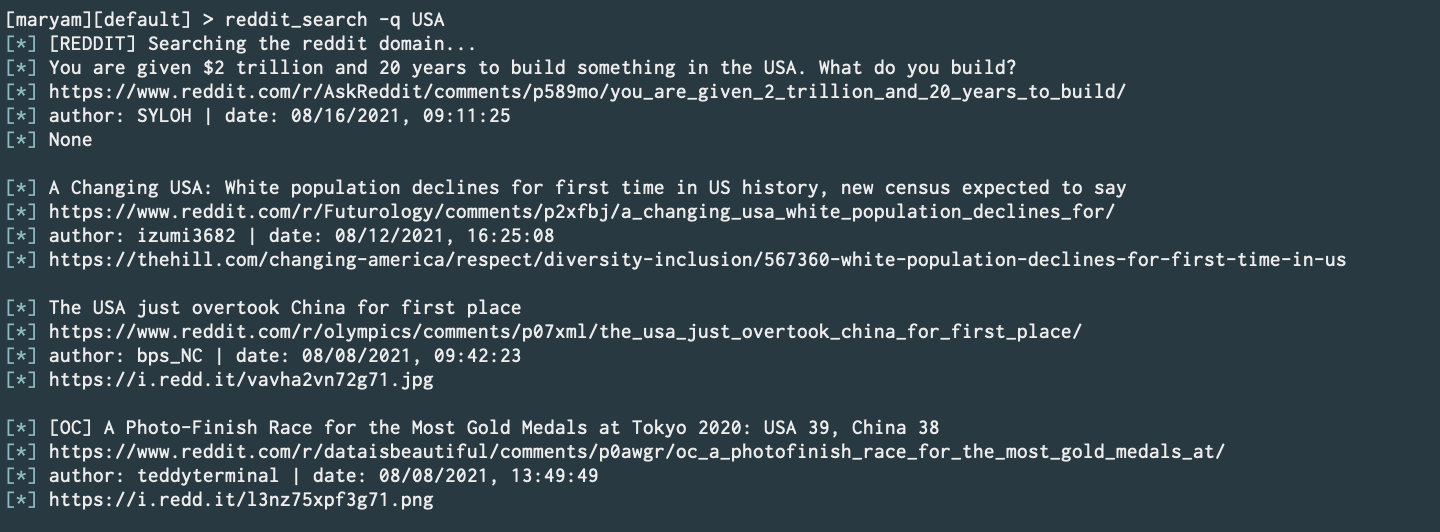
Reddit Search (without official API or scraping) (Commit).
-
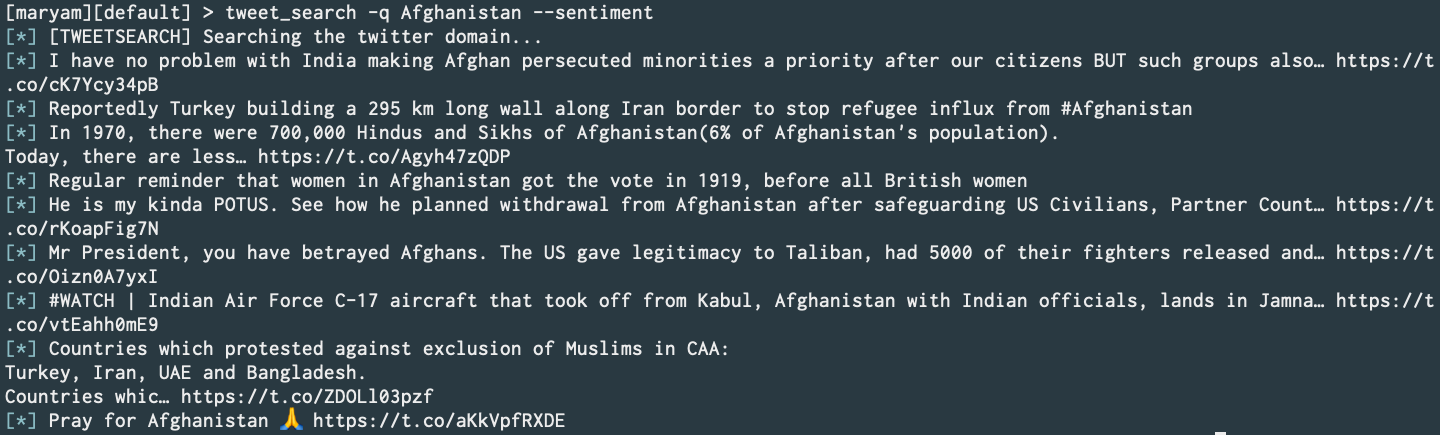
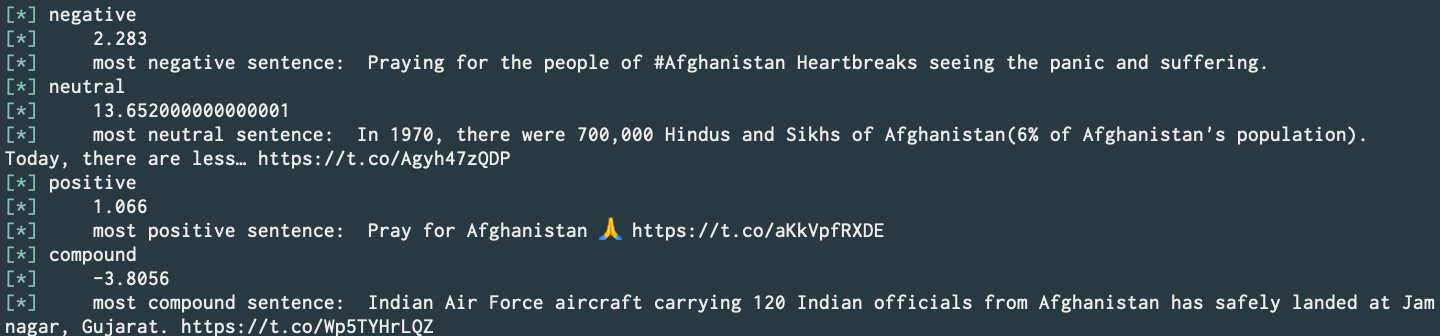
Twitter Tweet Search (without official API or scraping) w/ Sentiment Analysis (Commit).
-
ActiveSearchResults (PR)
-
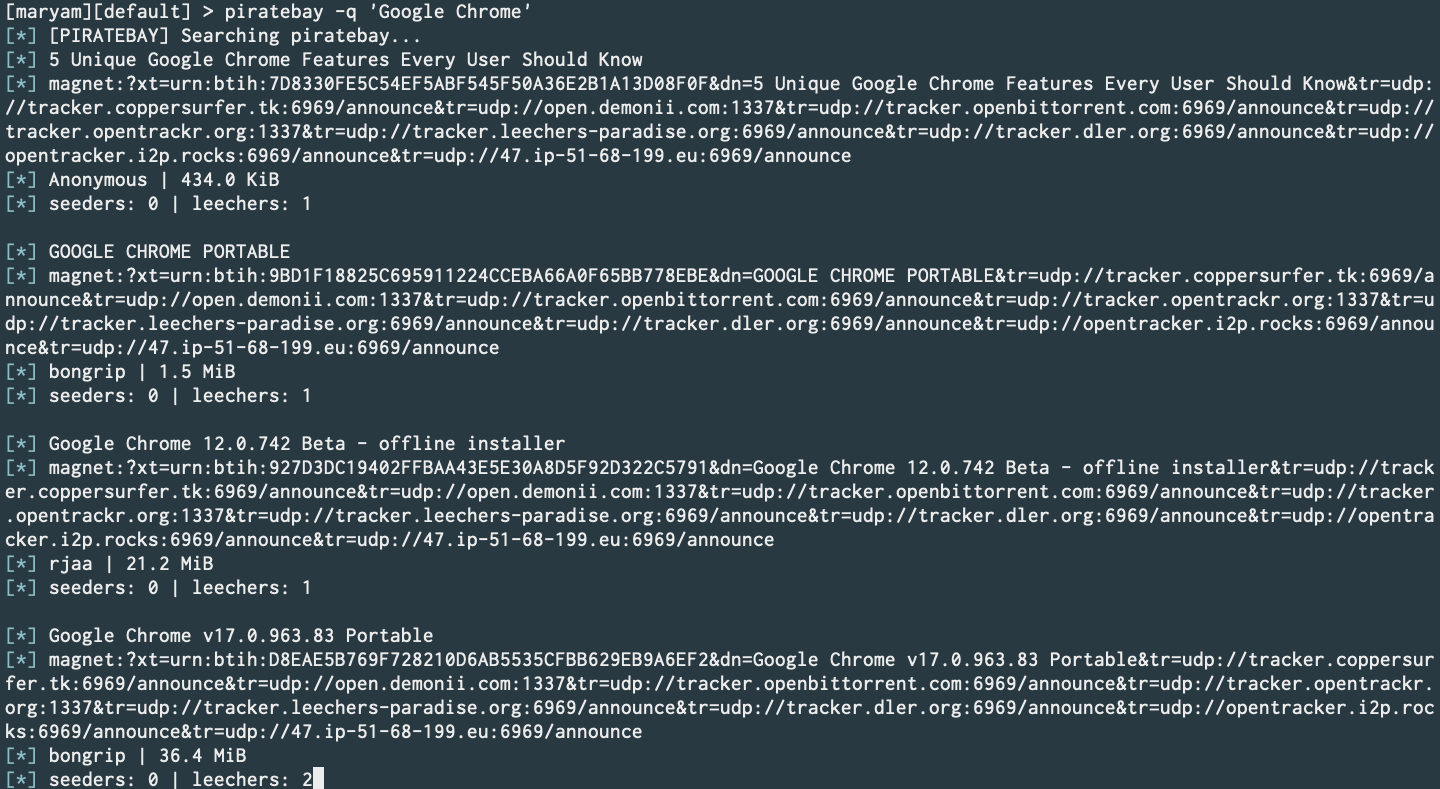
PirateBay (PR) (Later updated to use undocumented backend API)
-
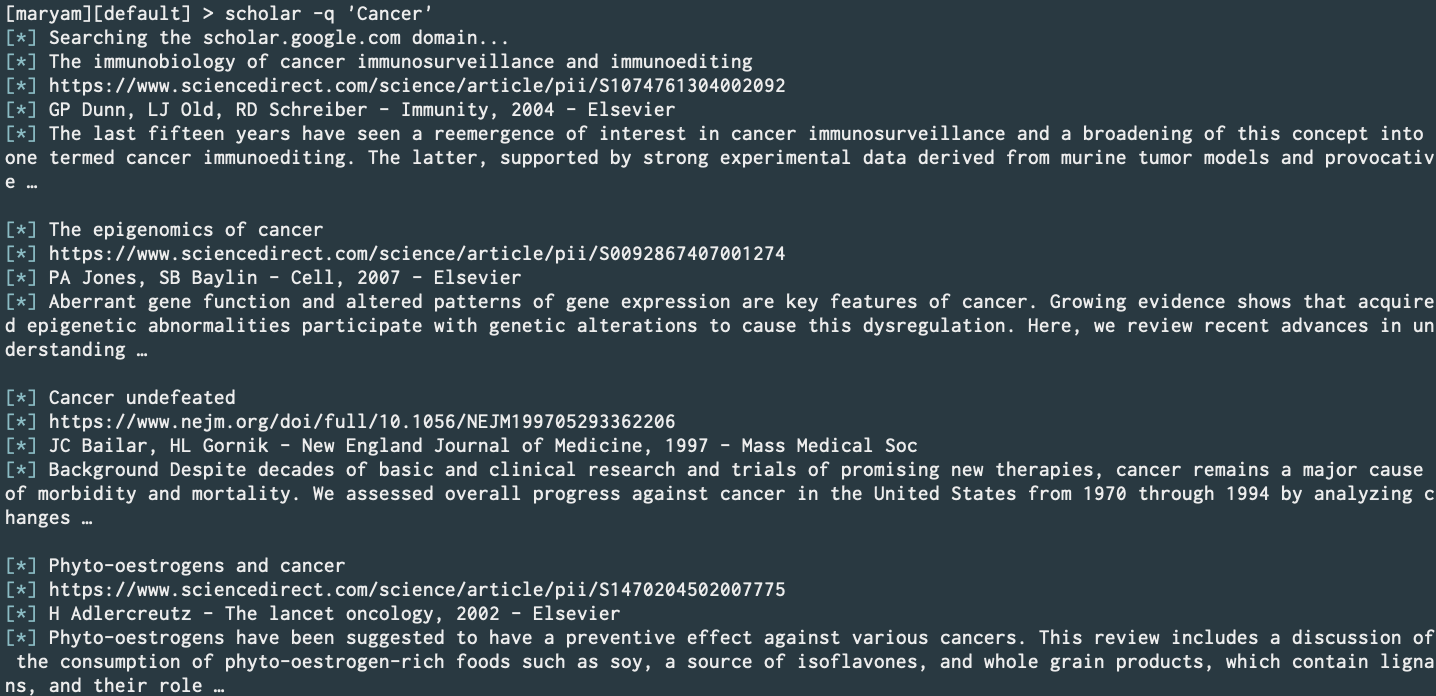
Google Scholar (PR)
-
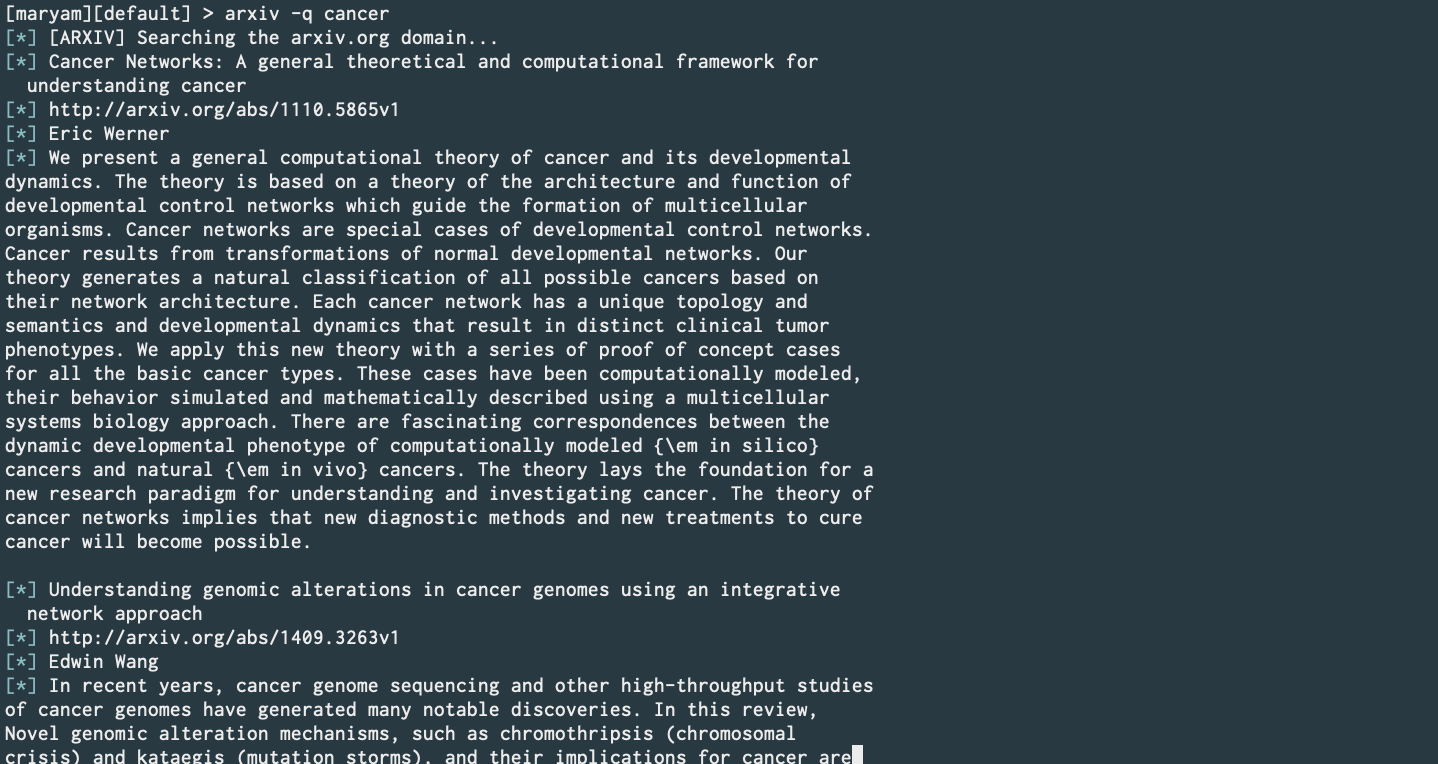
ArXiv (PR)
-
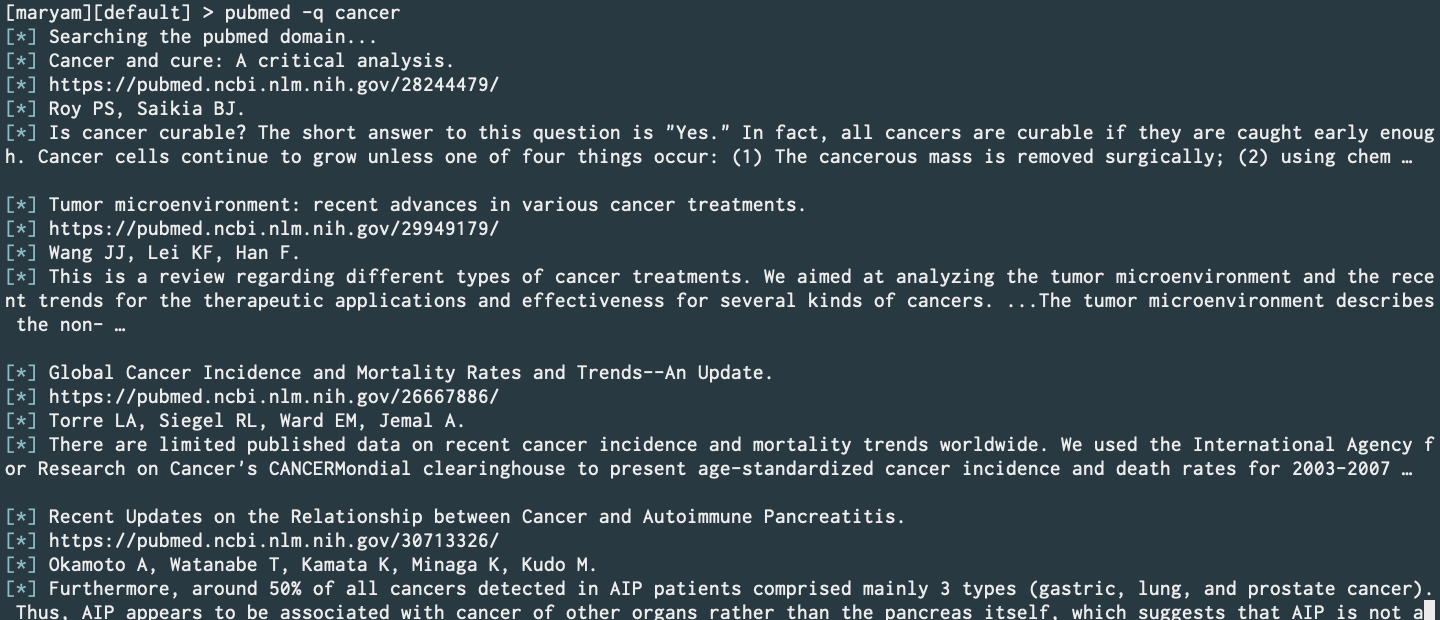
PubMed (PR)
-
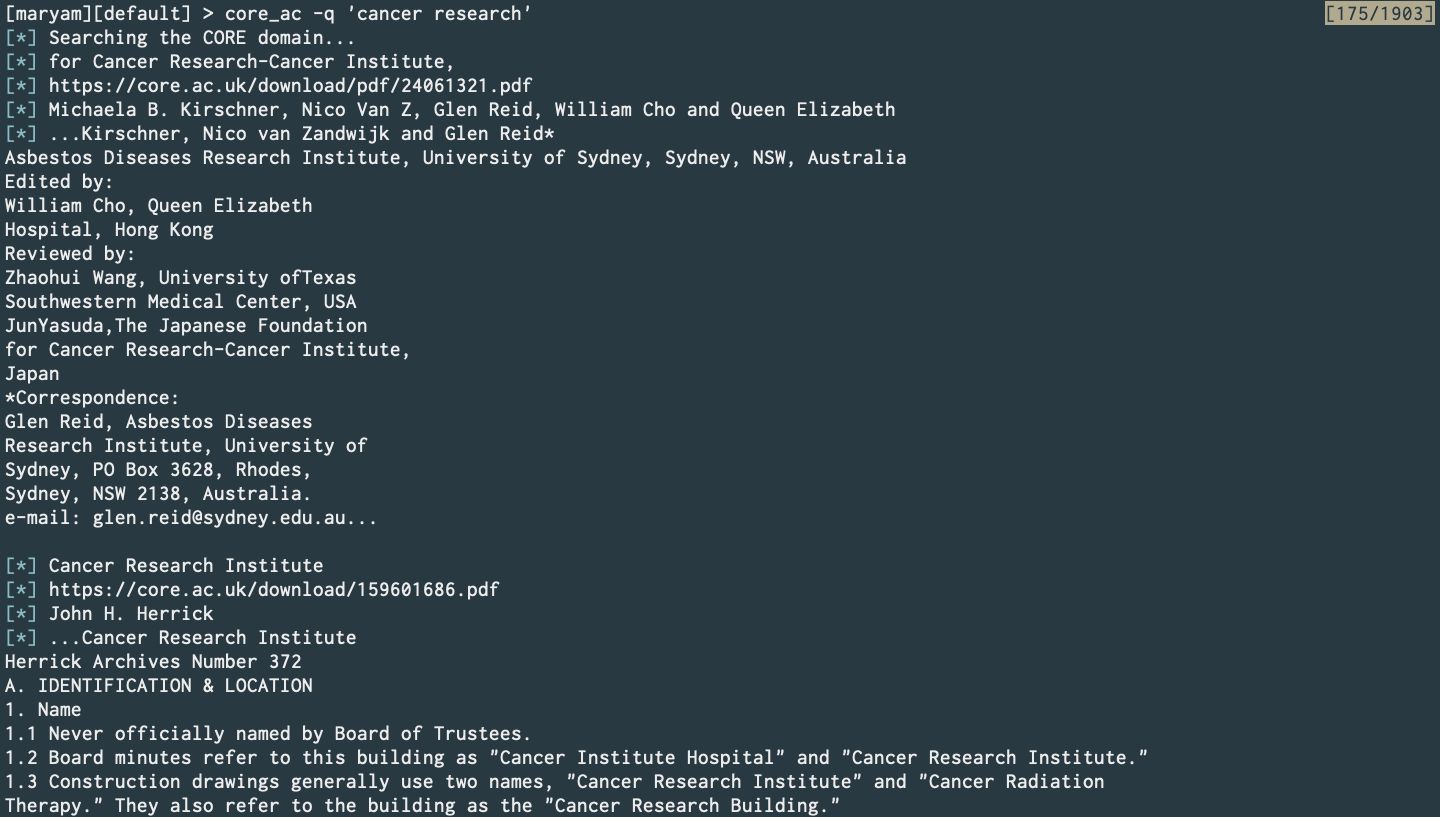
Core.ac.uk Search (PR)
-
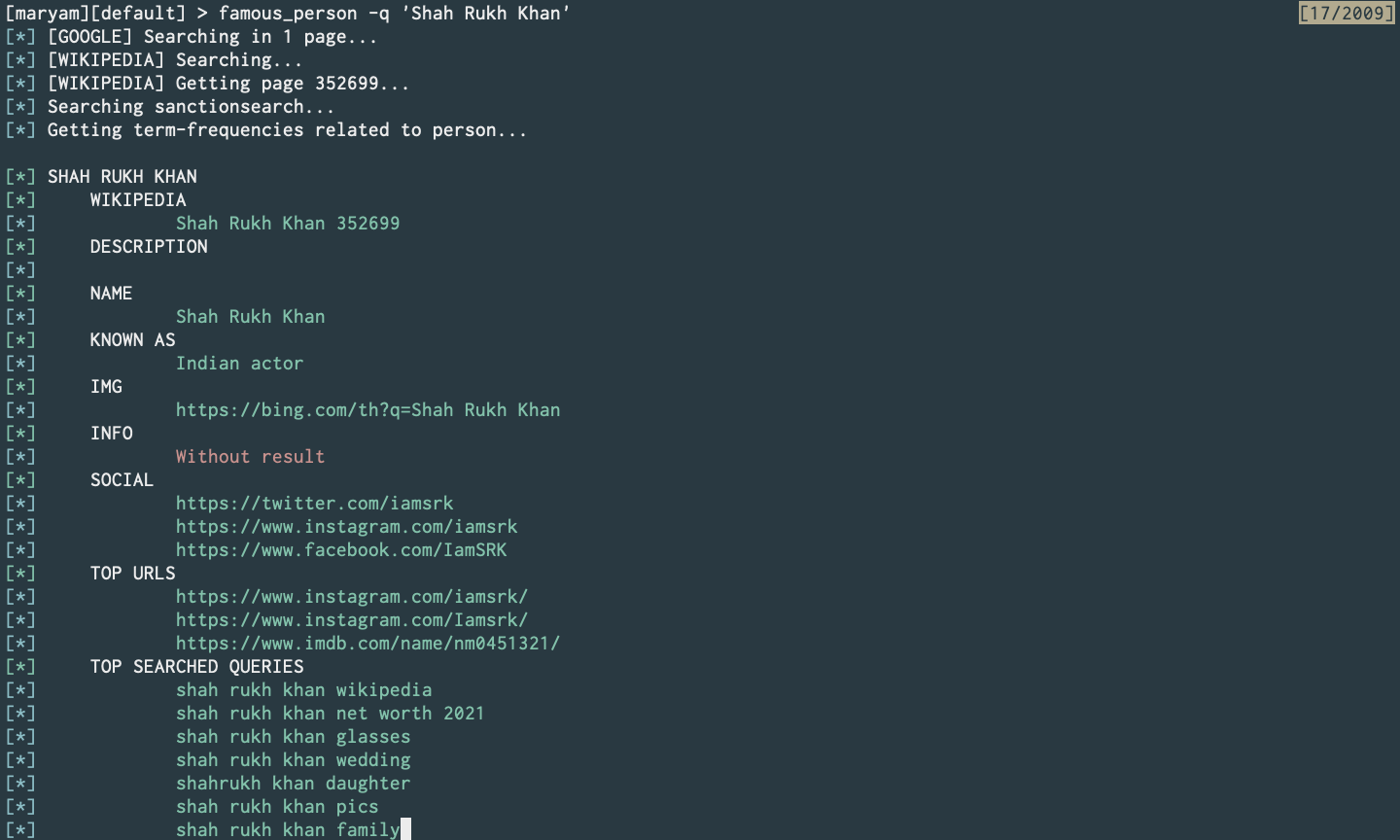
Famous Person Search (Commit)
-
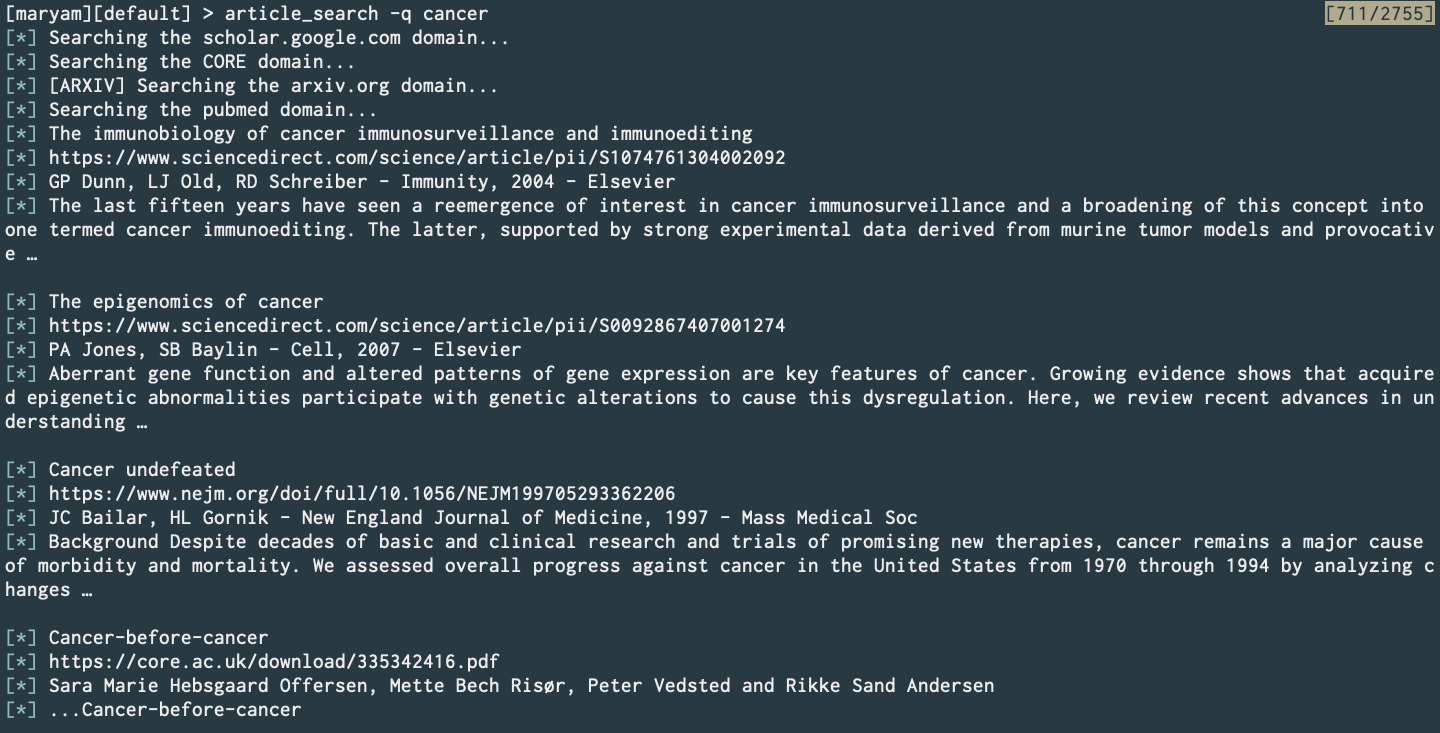
Article Search (Commit)
-
-
And standalone utility classes, namely,
-
Discovered startup lag due to heavy imports such as matplotlib and implemented optimization with cleanup resulting in significant reduction in startup time. (Commit 1, Commit 2)
-
Restructured and cleaned up Maryam's file tree in order to make it suitable for packaging and distribution. (PR (closed but later rechecked and commited manually by mentor saeeddhqan))
-
Packaged and deployed Maryam to PyPi. (link)
-
Fixed critical bug affecting OSX on Python3.8 and 3.9. (Issue)
-
Made numerous bug fixes, all of which can be accessed from the list of my commits.




- Implement frontend for Web API.
- A way to test module utils (at least engines) without module_api or module_run.
- Iris is key. The ultimate goal of Maryam is to improve Iris to the extent at which it can smartly leverage collaboratively, the capabilities of all modules and present its output intuitively.
- This requires us to classify an input query into the module that (we think) can handle it best.
- Output could be formatted as accordion of most suitable module outputs.