Computation is a critical pillar for transformation and analysis of Big Data. At a very high level, there are 2 paradigms for compute, where compute refers to the actual instructions or code that executes on a compute node in a distributed machine cluster.
- Moving compute to the data
- Moving data to the compute
At the outset, the latter method seems infeasible for Big Data, given that network is a bottleneck within a set of interconnected machines. The former is very attractive as code is miniscule when compared to the data. But, moving compute to the data can only happen after all or enough of the data required for analysis is present in a storage system. A storage system becomes mandatory for this paradigm. Waiting for the accumulation of data for analysis gives rise to high latency for processing and analyzing the data, but most definitely yields better accuracies. The latter method maybe suited for certain kinds of use cases involving low-latency SLAs in Big Data. A combination of the two, a hybrid approach, is becoming popular, bringing the best of both accuracies and latency.
In the Moving compute to the data paradigm, MapReduce, is the most popular model for distributed and parallel transformation and analysis of data.
####MapReduce MapReduce is the concatenated name of 2 functions, map and reduce. These functions when executed by a framework's higher order functions in a cascading fashion can solve a majority of distributed data processing and analysis tasks parallely, at scale with simplistic fault tolerance semantics. The roots of these functions are functional programming, a programming paradigm that treats functions as first-class citizens.
Functional programming - a paradigm that uses functions as building blocks of programs is analogous to Object-Oriented Programming that uses objects to build programs. Functions should not be confused with C-like procedures, but as computational units that transform inputs to outputs, like mathematical equations. Functions are free of side-effects or pure i.e. they do not change the environment when they execute. They operate on inputs to produce outputs. The same inputs yield the same outputs regardless of order or time of execution and the state of the environment. This property is called immutability. Functional Programming languages treat functions as first-class citizens. That is,
- Functions are basic units of abstractions
- Functions can be passed as parameters
- Functions can be returned as return values A function that takes other functions as parameters or return them as return values are called higher-order functions. The differential operator from calculus is an example of an higher-order function.
The primary feature of functional programming that makes it attractive in distributed and parallel transformation of data is its immutability. It not only allows for very clean isolation of work among nodes, but also makes it easy to implement simple fault tolerance strategies. Immutability eliminates the need for co-ordination and synchronization between the different readers and writers of the data. The result remains the same as long as the same inputs are fed to the data.
Functional Programming, from my experience, has a few advantages to it,
- Immutability - This feature makes it easy for a programmer to write bug-free multi-threading code. Coding concurrency becomes simple because shared state is not encouraged, as an effect of which, co-ordination and synchronization are not required.
- Composability - Functions are highly composable. Unlike, OOP, they are not rigidly programmed to an interface. They can be written once and used anywhere without concepts like classes coming in the way. Constructs like higher-order functions aid flexibility in composition. For example, a concept like currying (keeping the arity of a function to 1) is possible because of higher-order functions.
- Less Code - The high degree of composability makes it possible to write less new code and reuse written code. Less code makes the programmer efficient, but more importantly, less code indirectly translates to lesser bugs.
- Declarative - Functional programming comes under the family of declarative programming. A program is expressed in an idiomatic fashion rather than an imperative fashion. Potentially, this can make proving correctness of a program easier and improve readability. The programmer can now focus on the logic of the application rather than the implementation specifics.
Functional Programming comes with disadvantages as well,
- The practical world is less than ideal and side-effects are a unavoidable in some situations. IO is one such situation where purity of functions comes in the way.
- The hardware on which functional programs are compiled to run are still imperative in nature. This mismatch in impedence may rise to less efficient programs. It also becomes difficult to analyze the time and space complexities of these programs.
####Map function In functional programming, the map function, as the name suggests, is a higher-order function that applies a transformation function to each and every element of a collection. The order of application of the transformation function is commutative, i.e. the order of elements on which the transformation function needs to be applied is immaterial. This commutative property makes it feasible for parallel execution of the transformation function in a map.
collection(B) <- map(f(a), collection(A))
//A : type A or set of a's
//B : type B or set of b's
//f(a) = b <- f(a) //Transformation function that maps a element of set A to set B.
//collection(X) : an "array" of elements belonging to set X depicted by x.
In a distributed setting, the same transformation function not only takes an element from set A, but also a key with the element. The result of this transformation function is again not an element of set B, rather a list of keys (can be different than the input keys) and corresponding elements from set B. The returned list can have a single tuple too. The collection is distributed across different nodes in the cluster. The structure of each element of the collection is key-value pair.
collection((keyb, b)) <- map(f(keya, a), collection((keya, a))
//a, b: Elements of set A and B respectively
//keya, keyb: keys corresponding to elements (they can be from any arbitrary set, may not be from A and B)
//list(keyb, b) <- f(keya, a) //Maps a key and element from set A to a list of keys and elements in set B.
//collection((keyx, x)) can be distributed across multiple nodes in a cluster.
MapReduce differs from functional style map and reduce by the introduction of key-value tuples instead of just values. The idea behind this is to allow for distribution of data across the nodes in a cluster. Smart use of keys can be used to load balance the data among the machines in the cluster. Traditionally, this was not a problem as all the code used to run on a single CPU. With distribution of data and computation, the borrowed concept from functional languages needed to be augmented with keys.
####Reduce Function In functional programming, reduce or fold, is a higher-order function that summarizes over a collection of items. The summarization is done by an combiner function (not to be confused with combiners in Hadoop) that is passed to the reduce.
x <- reduce(f(intemediateX, b), collection(B))
//f(intermediateX, b) : is the combiner function. It takes and intermediate value of the result x.
//and an element from the collection to return a new intermediate value of x. If addition over the collection needs to be done, the intermediateX can start with a value 0.
//collection(B) : Collection over which summarization needs to take place
//x : The reduced/summarized value.
In the MapReduce distributed version of the same function, the reduce takes a collection of key-value pairs and reduces over them. However, there is one difference about the collection of key-value pairs it acts upon. The collection contains values for a single key.
(key,x) -> reduce(f(intermediateX, b), key, collection(B for key))
//collecton(B for key): This collection contains values corresponding to a single key.
####Common Form
Most languages on which MapReduce frameworks were built did not support functional concepts. This needed bringing down the order of the map and reduce functions and making them handle the transformation and combiner functions respectively. In the literature, MapReduce functions are often written as,
list(keyb, b) <- Map(keya, a)
x <- Reduce(key, Iterator<B for key>)
####MapReduce Frameworks
Reduce acts only on values of a particular key. This asks for an intermediate glue layer that acts on the Map's output keys, groups them, sorts them and then invokes the reduce function. This layer is the Shuffle and Sort layer. A MapReduce framework like Hadoop takes care of shuffling and sorting. The reduce cannot start without the completion of all maps.
In all frameworks that support MapReduce, the map functions are called on each record, on a split of the input data. Maps on different splits of the data can execute in parallel. Maximum parallelism in the system is achieved by the map functions and it is recommended to push most of the computation to the map (if possible) to exploit this parallelism.
A partitioning function is used to distribute the data to the appropriate reducers. If R is the number of reducers, a default partitioner could be something like hash(key) mod R. Most frameworks allow for custom partitioners, so that, an user of the system who is well aware of the data distribution can easily load-balance the system against swamping reducers with data.
For a person from a SQL background, a MapReduce job is equivalent to a SQL query like,
SELECT key, AGGREGATE(value) FROM dataset
GROUP BY key,
ORDER BY key
####Fault Tolerance
MapReduce programs provide simplistic semantics for failure handling via immutability. A Map failure is handled by re-executing the map on the input split. A Reduce failure is handled by re-executing a reduce on all the Map outputs. The Map outputs are generally persisted on disk to allow for re-execution of the Reduce step. A node failure is handled by rescheduling the task (Map or Reduce) on some other node. Most of the data stores that support MapReduce provide replication of data splits making rescheduling possible.
Cloning of tasks is very easy because of immutability of maps and reduces. It finds its applicability in mitigating staggler tasks. If a staggler is detected by the framework, it can clone the same task on some other node and use the results from the task the finishes the fastest.
####Limitations
- MapReduce programs are batch-oriented. This may not be feasible for certain kinds of applications that rely on low-latency.
- MapReduce's immutability is not suited for in-place transformations. The output must be a new data file and can create storage pressures.
- MapReduce is not suited for iterative kind of algorithms. Though iteration is possible by cascading MapReduce jobs, the startup costs associated with job initiation may not be make it an attractive option. Also, the data size increases 2X if iteration takes place over the same data.
Below is a diagram from the seminal MapReduce presentation on the system organization of a MapReduce framework.
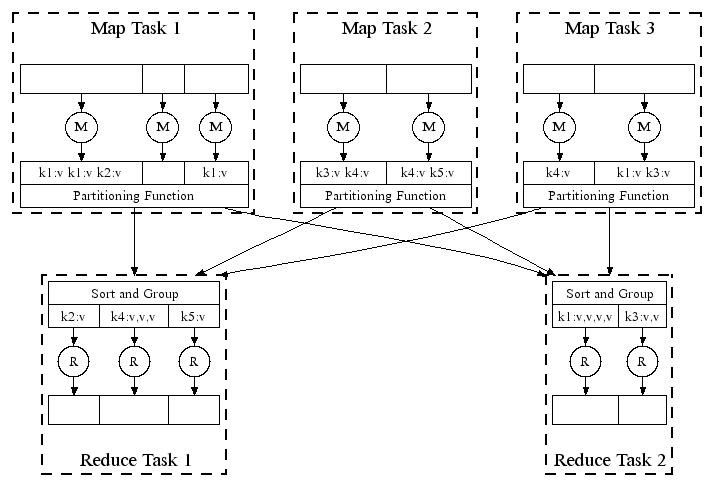
The simplicity of distributed programming using MapReduce, makes it attractive for developers without any background in Distributed Systems, to implement programs that can run on a large number of machines. The programs are guaranteed massive parallelism in the cluster of machines. MapReduce programs are agnostic to the number of machines in a cluster. Programs can be written once and deployed at any scale be it 1-machine or a 1000-machine cluster.