An ML model for Natural Language Processing (NLP), developed in 2018 by folks at Google AI Language.
- Sentiment Analysis
- Question Answering
- Text prediction
- Text generation
- Summarization
- Polysemy resolution (Can differentiate words that have multiple meanings, like "bank")
BERT leverages:
- Large amounts of training data
- Masked Language Model
- This enforces bidirectional learning from text by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word.
- Next Sentence Prediction
- It's used to help BERT learn about relationships between sentences by predicting if a given sentence follows the previous sentence or not
- Example:
- Paul went shopping. He bought a new shirt (correct sentence pair)
- Ramona made coffee. Vanilla ice cream cones for sale (incorrect sentence pair)
- In training, 50% correct sentence pairs are mixed in with 50% random sentence pairs to help BERT increase next sentence prediction accuracy.
- Transformers
- Transformers use an attention mechanism to observe relationships between words. This concept was proposed in this paper.
- How do Transformers work?
- They work by leveraging attention, a DL model initially seen in CV
- Transformers create differential weights signaling which words in a sentence are the most critical to further process
- A transformer does this by successively processing an input through a stack of transformer layers, usually called the encoder
- If necessary, another stack of transformer layers - the decoder - can be used to predict a target output.
- BERT however, does NOT use a decoder
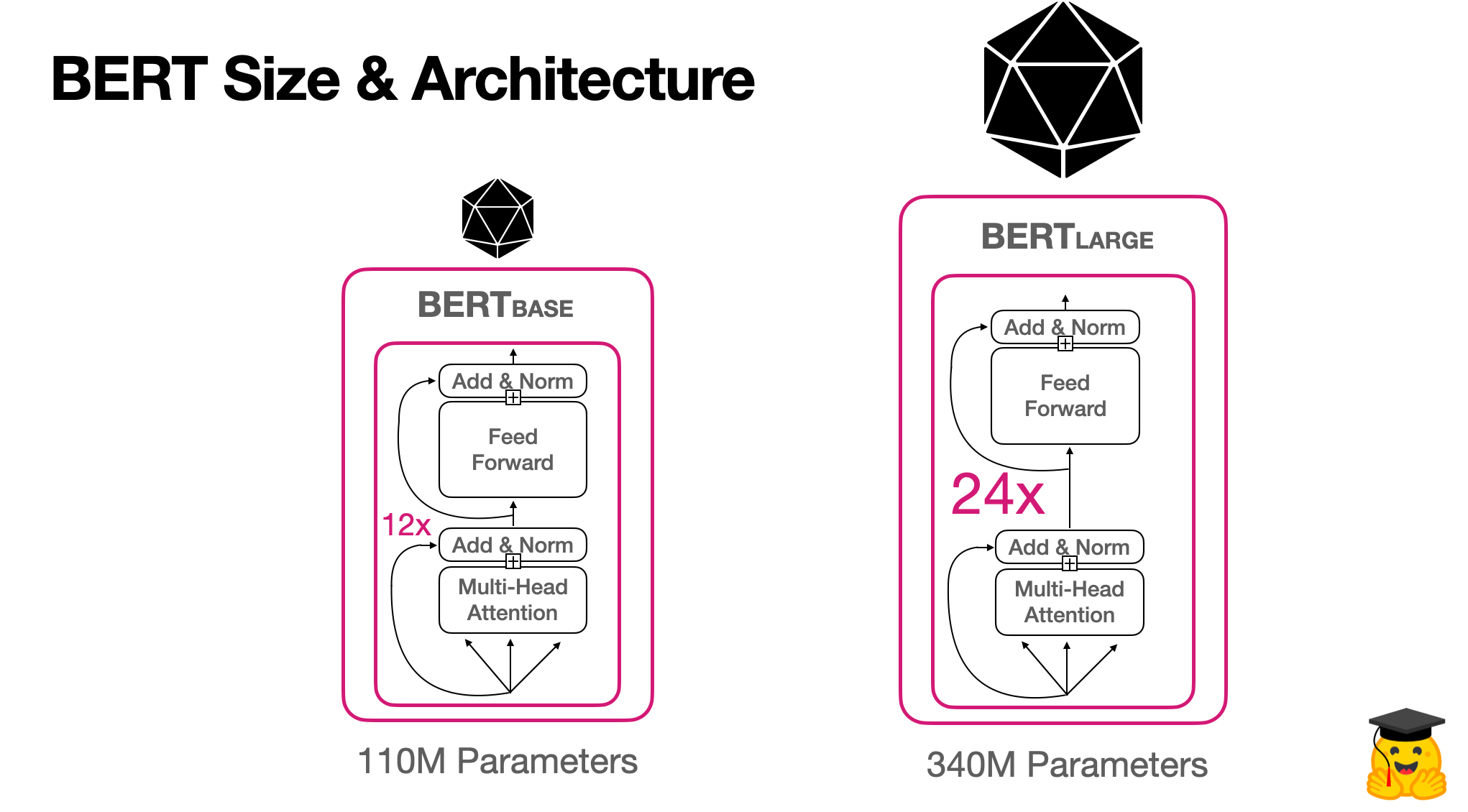
ML Architecture Glossary
| ML Architecture Parts | Definition |
|---|---|
| Parameters: | Number of learnable variables/values available for the model. |
| Transformer Layers: | Number of Transformer blocks. A transformer block transforms a sequence of word representations to a sequence of contextualized words (numbered representations). |
| Hidden Size: | Layers of mathematical functions, located between the input and output, that assign weights (to words) to produce a desired result. |
| Attention Heads: | The size of a Transformer block. |
| Processing: | Type of processing unit used to train the model. |
| Length of Training: | Time it took to train the model. |