By default, compactions in Accumulo are driven by a configurable compaction ratio using the following algorithm.
- If LF * CR < SUM then compact this set of files. LF is the largest file in the set. CR is the compaction ratio. SUM is the size of all files in the set.
- Remove largest file from set.
- If set is empty, then compact no files.
- Go to 1.
While working on compaculation in service of #564 and trying to figure out a sensible way to support parallel compactions, I came up with a modified file selection algorithm that finds the largest set of small files to compact. See this code in Compaculation for the algorithm.
The motivation for this new algorithm were sets of files like with sizes like [101M,102M,103M,104M,4M,3M,3M,3M,3M].
There is a huge disparity in sizes between the files. Accumulo's current algorithm would compact all files in a single compaction. The large files may take a lot of time to compact, while the small files could compact very quickly. This long compaction has two disadvantages, first a lot more small files could arrive while the long compaction is running. Second for scans, we always want less files therefore quickly reducing the number of files is advantageous for scans.
The new algorithm would first compact [4M,3M,3M,3M,3M] and then compact [101M,102M,103M,104M,16M] where the 16M file is the result of the first compaction. This algorithm does a little more work, but it reduces the number of files
more quickly. Although it may do more work, its still logarithmic because every set is chosen using the compaction ratio. As a proof of this consider a key that starts off in a 1M file. With a compaction ratio of 3, this key would only be rewritten into a file of at least 3M. After that, the key would only be rewritten into files of at least 9M, 27M, etc. Since the requirements for rewrite are exponential, the amount of rewriting is logarithmic.
The new algorithm works really well in the case when a tablet can have multiple concurrent compactions, with the caveat that when a compaction is running all files larger than those being compacted should not be considered. See file count parity for an explanation.
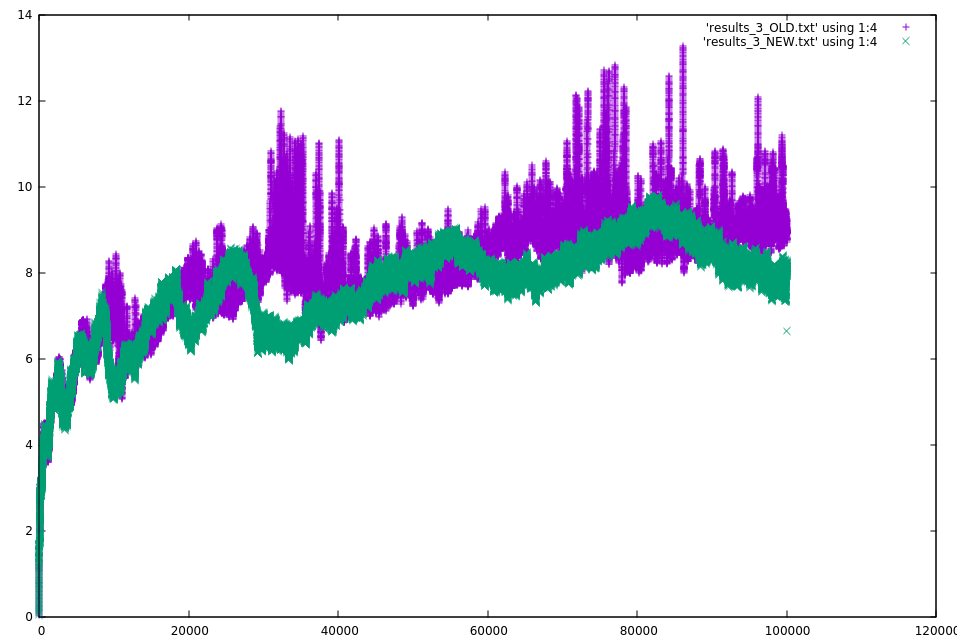
To test the new algorithm, Compaculation commit c44017c was used. This simulated 100,000 ticks, 100 tablets, and 5M files added to 4 random tablets each tick. The average number of files per tablet are plotted below for compaction ratio of 3. Green is the new algorithm (with concurrent compactions per tablet) and purple is the old algorithm (w/o concurrent compactions).
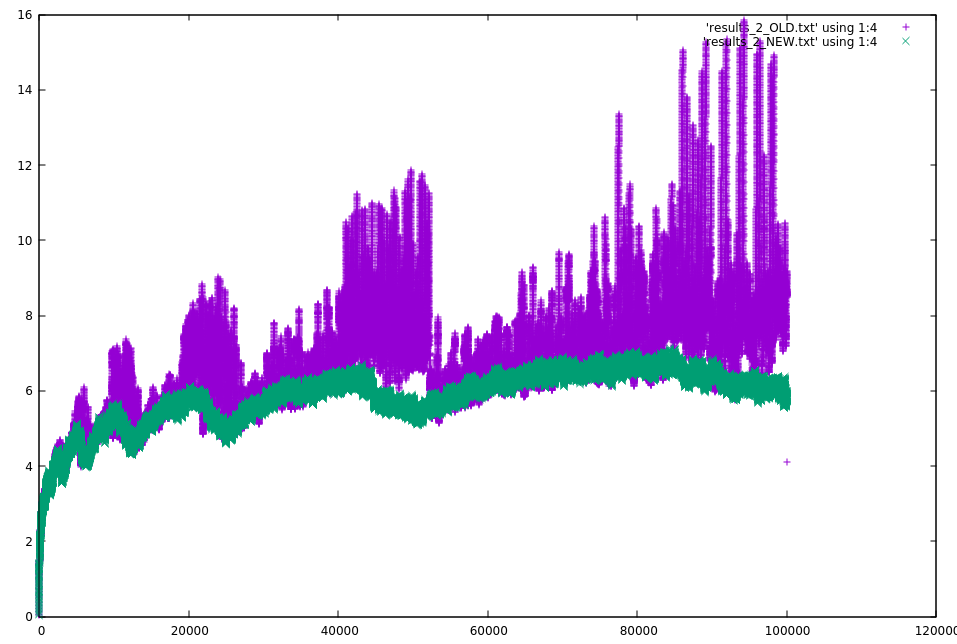
Below is a plot for a compaction ratio of 2.
Below is a plot for a compaction ratio of 1.5.
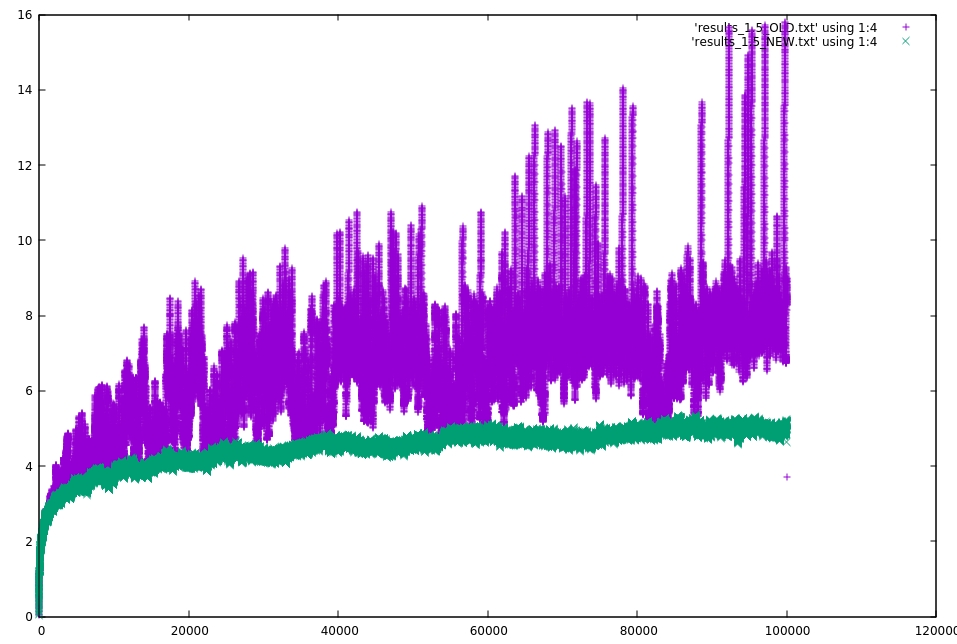
The results are much better, assuming the simulation is somewhat correct. Need to determine how much of the improvement is from parallelism vs the new algorithm. The new algorithm did rewrite more data. For a compaction ratio of 3, it rewrote 22% more data. For 2 it rewrote 13% more data. For 1.5 it rewrote 25% more data.
When running the new algorithm it could schedule multiple concurrent compactions per tablet. There were 4 executors, one for compactions < 10M, one for < 100M, one for < 500M, and one for everything else.
This new approach may have the advantage of maintaining a smaller set of files for a system that is constantly adding files. This is done with logarithmic cost and once the system settles (files stop being added) it will compact down to the same number of files per tablet as the old approach.