
Welcome! This notebook will teach you about using Pandas in the Python Programming Language. By the end of this lab, you'll know how to use Pandas package to view and access data.
Estimated time needed: 15 min
The table has one row for each album and several columns
- artist: Name of the artist
- album: Name of the album
- released_year: Year the album was released
- length_min_sec: Length of the album (hours,minutes,seconds)
- genre: Genre of the album
- music_recording_sales_millions: Music recording sales (millions in USD) on [SONG://DATABASE]
- claimed_sales_millions: Album's claimed sales (millions in USD) on [SONG://DATABASE]
- date_released: Date on which the album was released
- soundtrack: Indicates if the album is the movie soundtrack (Y) or (N)
- rating_of_friends: Indicates the rating from your friends from 1 to 10
You can see the dataset here:
| Artist | Album | Released | Length | Genre | Music recording sales (millions) | Claimed sales (millions) | Released | Soundtrack | Rating (friends) |
|---|---|---|---|---|---|---|---|---|---|
| Michael Jackson | Thriller | 1982 | 00:42:19 | Pop, rock, R&B | 46 | 65 | 30-Nov-82 | 10.0 | |
| AC/DC | Back in Black | 1980 | 00:42:11 | Hard rock | 26.1 | 50 | 25-Jul-80 | 8.5 | |
| Pink Floyd | The Dark Side of the Moon | 1973 | 00:42:49 | Progressive rock | 24.2 | 45 | 01-Mar-73 | 9.5 | |
| Whitney Houston | The Bodyguard | 1992 | 00:57:44 | Soundtrack/R&B, soul, pop | 26.1 | 50 | 25-Jul-80 | Y | 7.0 |
| Meat Loaf | Bat Out of Hell | 1977 | 00:46:33 | Hard rock, progressive rock | 20.6 | 43 | 21-Oct-77 | 7.0 | |
| Eagles | Their Greatest Hits (1971-1975) | 1976 | 00:43:08 | Rock, soft rock, folk rock | 32.2 | 42 | 17-Feb-76 | 9.5 | |
| Bee Gees | Saturday Night Fever | 1977 | 1:15:54 | Disco | 20.6 | 40 | 15-Nov-77 | Y | 9.0 |
| Fleetwood Mac | Rumours | 1977 | 00:40:01 | Soft rock | 27.9 | 40 | 04-Feb-77 | 9.5 |
# Dependency needed to install file
!pip install xlrdRequirement already satisfied: xlrd in /opt/conda/envs/Python-3.7-main/lib/python3.7/site-packages (1.2.0)
# Import required library
import pandas as pdAfter the import command, we now have access to a large number of pre-built classes and functions. This assumes the library is installed; in our lab environment all the necessary libraries are installed. One way pandas allows you to work with data is a dataframe. Let's go through the process to go from a comma separated values (.csv) file to a dataframe. This variable csv_path stores the path of the .csv, that is used as an argument to the read_csv function. The result is stored in the object df, this is a common short form used for a variable referring to a Pandas dataframe.
# Read data from CSV file
csv_path = 'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/Chapter%204/Datasets/TopSellingAlbums.csv'
df = pd.read_csv(csv_path)We can use the method head() to examine the first five rows of a dataframe:
# Print first five rows of the dataframe
df.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | Album | Released | Length | Genre | Music Recording Sales (millions) | Claimed Sales (millions) | Released.1 | Soundtrack | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Jackson | Thriller | 1982 | 0:42:19 | pop, rock, R&B | 46.0 | 65 | 30-Nov-82 | NaN | 10.0 |
| 1 | AC/DC | Back in Black | 1980 | 0:42:11 | hard rock | 26.1 | 50 | 25-Jul-80 | NaN | 9.5 |
| 2 | Pink Floyd | The Dark Side of the Moon | 1973 | 0:42:49 | progressive rock | 24.2 | 45 | 01-Mar-73 | NaN | 9.0 |
| 3 | Whitney Houston | The Bodyguard | 1992 | 0:57:44 | R&B, soul, pop | 27.4 | 44 | 17-Nov-92 | Y | 8.5 |
| 4 | Meat Loaf | Bat Out of Hell | 1977 | 0:46:33 | hard rock, progressive rock | 20.6 | 43 | 21-Oct-77 | NaN | 8.0 |
We use the path of the excel file and the function read_excel. The result is a data frame as before:
# Read data from Excel File and print the first five rows
xlsx_path = 'https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/PY0101EN/Chapter%204/Datasets/TopSellingAlbums.xlsx'
df = pd.read_excel(xlsx_path)
df.head().dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | Album | Released | Length | Genre | Music Recording Sales (millions) | Claimed Sales (millions) | Released.1 | Soundtrack | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Jackson | Thriller | 1982 | 00:42:19 | pop, rock, R&B | 46.0 | 65 | 1982-11-30 | NaN | 10.0 |
| 1 | AC/DC | Back in Black | 1980 | 00:42:11 | hard rock | 26.1 | 50 | 1980-07-25 | NaN | 9.5 |
| 2 | Pink Floyd | The Dark Side of the Moon | 1973 | 00:42:49 | progressive rock | 24.2 | 45 | 1973-03-01 | NaN | 9.0 |
| 3 | Whitney Houston | The Bodyguard | 1992 | 00:57:44 | R&B, soul, pop | 27.4 | 44 | 1992-11-17 | Y | 8.5 |
| 4 | Meat Loaf | Bat Out of Hell | 1977 | 00:46:33 | hard rock, progressive rock | 20.6 | 43 | 1977-10-21 | NaN | 8.0 |
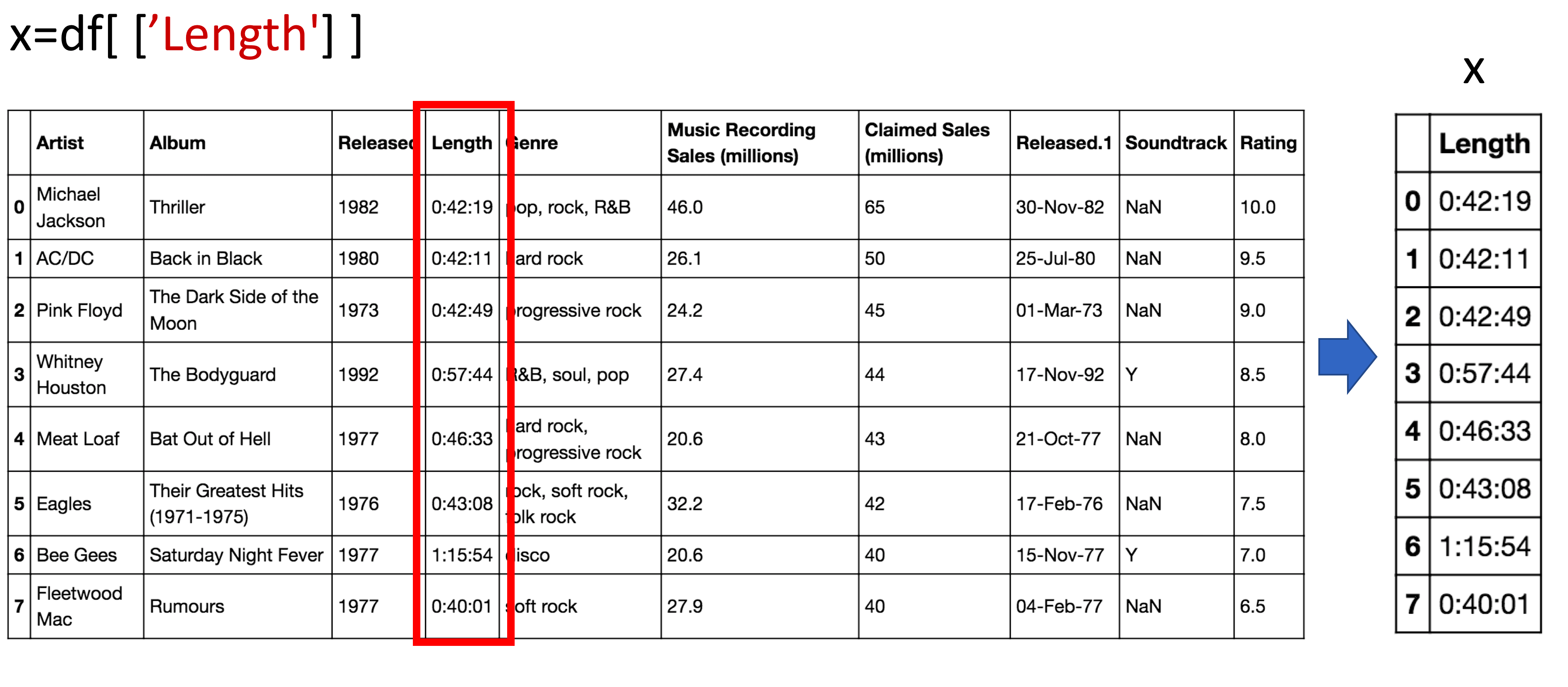
We can access the column Length and assign it a new dataframe x:
# Access to the column Length
x = df[['Length']]
x.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Length | |
|---|---|
| 0 | 00:42:19 |
| 1 | 00:42:11 |
| 2 | 00:42:49 |
| 3 | 00:57:44 |
| 4 | 00:46:33 |
| 5 | 00:43:08 |
| 6 | 01:15:54 |
| 7 | 00:40:01 |
The process is shown in the figure:
You can also get a column as a series. You can think of a Pandas series as a 1-D dataframe. Just use one bracket:
# Get the column as a series
x = df['Length']
x0 00:42:19
1 00:42:11
2 00:42:49
3 00:57:44
4 00:46:33
5 00:43:08
6 01:15:54
7 00:40:01
Name: Length, dtype: object
You can also get a column as a dataframe. For example, we can assign the column Artist:
# Get the column as a dataframe
x = type(df[['Artist']])
x = df[['Artist']]
x.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | |
|---|---|
| 0 | Michael Jackson |
| 1 | AC/DC |
| 2 | Pink Floyd |
| 3 | Whitney Houston |
| 4 | Meat Loaf |
| 5 | Eagles |
| 6 | Bee Gees |
| 7 | Fleetwood Mac |
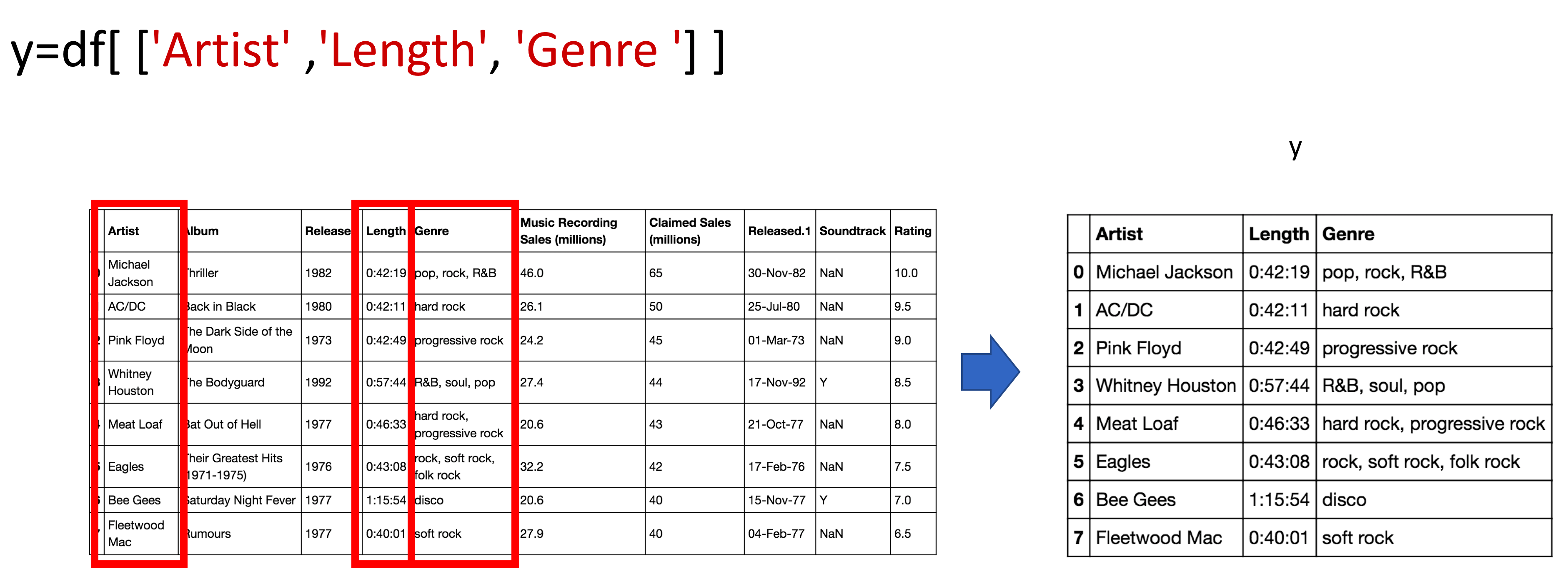
You can do the same thing for multiple columns; we just put the dataframe name, in this case, df, and the name of the multiple column headers enclosed in double brackets. The result is a new dataframe comprised of the specified columns:
# Access to multiple columns
y = df[['Artist','Length','Genre']]
y.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | Length | Genre | |
|---|---|---|---|
| 0 | Michael Jackson | 00:42:19 | pop, rock, R&B |
| 1 | AC/DC | 00:42:11 | hard rock |
| 2 | Pink Floyd | 00:42:49 | progressive rock |
| 3 | Whitney Houston | 00:57:44 | R&B, soul, pop |
| 4 | Meat Loaf | 00:46:33 | hard rock, progressive rock |
| 5 | Eagles | 00:43:08 | rock, soft rock, folk rock |
| 6 | Bee Gees | 01:15:54 | disco |
| 7 | Fleetwood Mac | 00:40:01 | soft rock |
The process is shown in the figure:
One way to access unique elements is the iloc method, where you can access the 1st row and the 1st column as follows:
# Access the value on the first row and the first column
df.iloc[0, 0]'Michael Jackson'
You can access the 2nd row and the 1st column as follows:
# Access the value on the second row and the first column
df.iloc[0:2,1:3].dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Album | Released | |
|---|---|---|
| 0 | Thriller | 1982 |
| 1 | Back in Black | 1980 |
You can access the 1st row and the 3rd column as follows:
# Access the value on the first row and the third column
df.iloc[0,2]1982
You can access the column using the name as well, the following are the same as above:
# Access the column using the name
df.loc[0, 'Artist']'Michael Jackson'
# Access the column using the name
df.loc[1, 'Artist']'AC/DC'
# Access the column using the name
df.loc[0, 'Released']1982
# Access the column using the name
df.loc[1, 'Released']1980
You can perform slicing using both the index and the name of the column:
# Slicing the dataframe
df.iloc[0:2, 0:3].dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | Album | Released | |
|---|---|---|---|
| 0 | Michael Jackson | Thriller | 1982 |
| 1 | AC/DC | Back in Black | 1980 |
# Slicing the dataframe using name
df.loc[0:2, 'Artist':'Released'].dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Artist | Album | Released | |
|---|---|---|---|
| 0 | Michael Jackson | Thriller | 1982 |
| 1 | AC/DC | Back in Black | 1980 |
| 2 | Pink Floyd | The Dark Side of the Moon | 1973 |
Use a variable q to store the column Rating as a dataframe
# Write your code below and press Shift+Enter to execute
q = df[['Rating']]
q.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Rating | |
|---|---|
| 0 | 10.0 |
| 1 | 9.5 |
| 2 | 9.0 |
| 3 | 8.5 |
| 4 | 8.0 |
| 5 | 7.5 |
| 6 | 7.0 |
| 7 | 6.5 |
Double-click here for the solution.
Assign the variable q to the dataframe that is made up of the column Released and Artist:
# Write your code below and press Shift+Enter to execute
q = df[['Rating','Artist']]
q.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Rating | Artist | |
|---|---|---|
| 0 | 10.0 | Michael Jackson |
| 1 | 9.5 | AC/DC |
| 2 | 9.0 | Pink Floyd |
| 3 | 8.5 | Whitney Houston |
| 4 | 8.0 | Meat Loaf |
| 5 | 7.5 | Eagles |
| 6 | 7.0 | Bee Gees |
| 7 | 6.5 | Fleetwood Mac |
Double-click here for the solution.
Access the 2nd row and the 3rd column of df:
# Write your code below and press Shift+Enter to execute
df.iloc[1,2]1980
Double-click here for the solution.
Congratulations, you have completed your first lesson and hands-on lab in Python. However, there is one more thing you need to do. The Data Science community encourages sharing work. The best way to share and showcase your work is to share it on GitHub. By sharing your notebook on GitHub you are not only building your reputation with fellow data scientists, but you can also show it off when applying for a job. Even though this was your first piece of work, it is never too early to start building good habits. So, please read and follow this article to learn how to share your work.
Joseph Santarcangelo is a Data Scientist at IBM, and holds a PhD in Electrical Engineering. His research focused on using Machine Learning, Signal Processing, and Computer Vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.
Other contributors: Mavis Zhou
Copyright © 2018 IBM Developer Skills Network. This notebook and its source code are released under the terms of the MIT License.