-
-
Save leoricklin/37a4f2f53a92037a92ab231b8dbf5f53 to your computer and use it in GitHub Desktop.
- When are Artifacts Produced
- Available Data in dbt artifacts
- Parsing Artifacts from the Command Line with jq
- Parsing Artifacts from Python with pydantic
- Example Application 1: Detecting a Change in Materialization
- Example Application 2: Compute Model Centrality with networkx
- Example Application 3: Graph visualisation
This is a dbt artifacts parse in python. It enables us to deal with catalog.json, manifest.json, run-results.json and sources.json as python objects.
dbt_log_parser is a python package and CLI tool for parsing structured (JSON) data from a dbt log.
Data lineage is the foundation for a new generation of powerful, context-aware data tools and best practices. OpenLineage enables consistent collection of lineage metadata, creating a deeper understanding of how data is produced and used.
Enabling OpenLineage in dbt can capture lineage metadata for transformations running within your data warehouse.
Fortunately, dbt already collects a lot of the data required to create and emit OpenLineage events. When it runs, it creates:
- a
target/manifest.jsonfile containing information about jobs and the datasets they affect, and - a
target/run_results.jsonfile containing information about the run-cycle. These files can be used to trace lineage and job performance. - In addition, by using the
create catalogcommand, a user can instruct dbt to create atarget/catalog.jsonfile containing information about dataset schemas.
The dbt-ol wrapper supports all of the standard dbt subcommands, and is safe to use as a substitutuon (i.e., in an alias). Once the run has completed, you will see output containing the number of events sent via the OpenLineage API:
Overview
OpenLineage is an Open standard for metadata and lineage collection designed to instrument jobs as they are running. It defines a generic model of run, job, and dataset entities identified using consistent naming strategies. The core lineage model is extensible by defining specific facets to enrich those entities.
Status
OpenLineage is an LF AI & Data Foundation incubation project under active development, and we'd love your help!
Unlock the value of data assets with an end-to-end metadata management solution that includes data discovery, governance, data quality, observability, and people collaboration.
Data Discovery
Event Notification via Webhooks and Slack Integration
Add Descriptive Metadata
Role Based Access Control
Data Lineage
Data Reliability
dbt Queries
- Queries used to create the dbt models can be viewed in the dbt tab

dbt Lineage
- Lineage from dbt models can be viewed in the Lineage tab.
- For more information on how lineage is extracted from dbt take a look here

dbt Tags
- Table and column level tags can be imported from dbt
- Please refer here for adding dbt tags

dbt Owner
- Owner from dbt models can be imported and assigned to respective tables
- Please refer here for adding dbt owner

dbt Descriptions
- Descriptions from dbt manifest.json and catalog.json can be imported and assigned to respective tables and columns.
- For more information and to control how the table and column descriptions are updated from dbt please take a look here

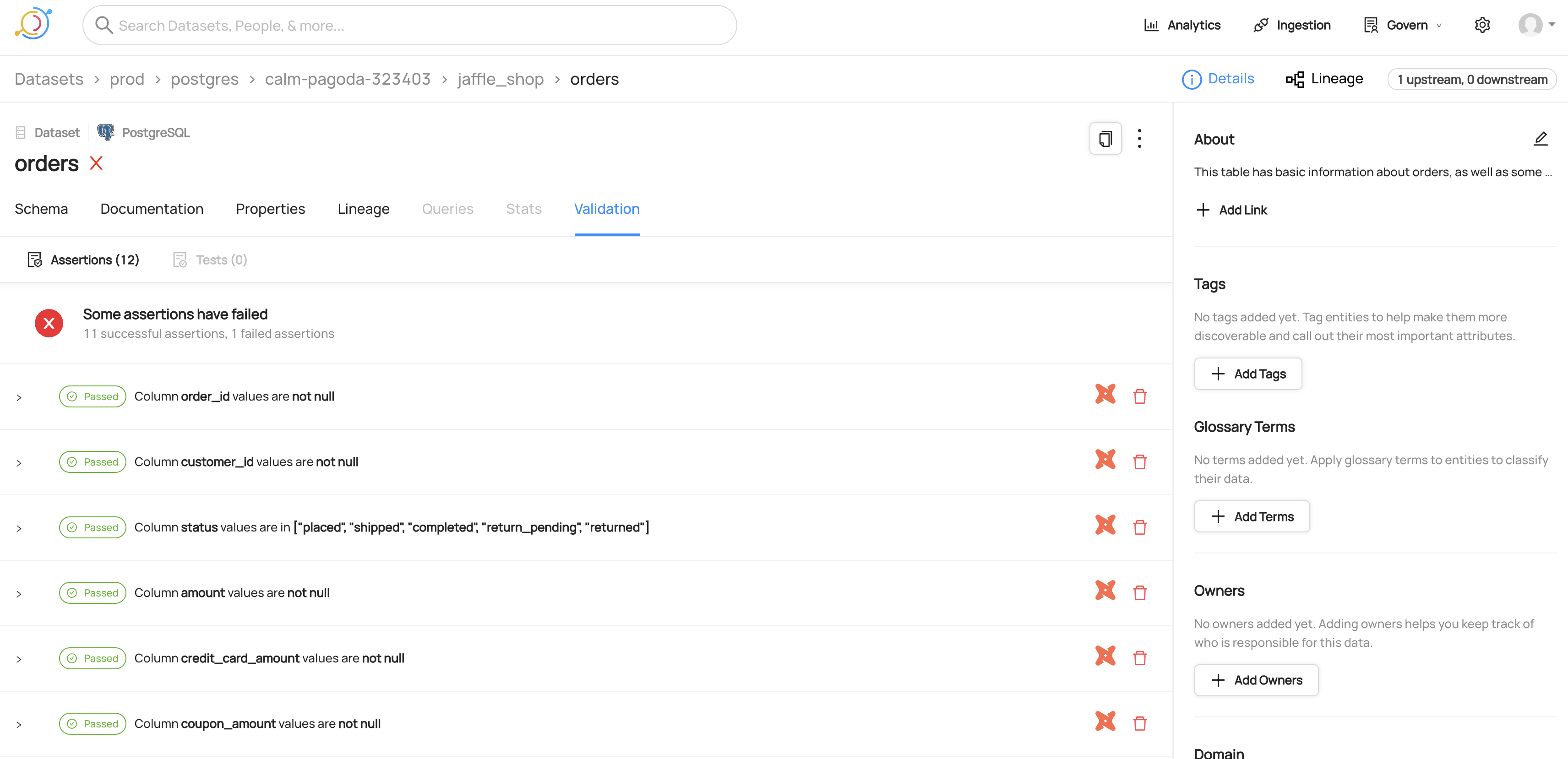
dbt Tests and Test Results
- Tests from dbt will only be imported if the run_results.json file is passed.

A unified metadata system can be transformational to how an organization uses the data based on our first-hand experience at Uber captured in the blog Uber’s Journey Toward Better Data Culture. Here are our key learnings from building the first iteration of such a system:

What is OpenMetadata?
OpenMetadata is an all-in-one platform for data discovery, data lineage, data quality, observability, governance, and team collaboration. It is one of the fastest growing open-source projects with a vibrant community and adoption by a diverse set of companies in a variety of industry verticals. Powered by a centralized metadata store based on Open Metadata Standards/APIs, supporting connectors to a wide range of data services, OpenMetadata enables end-to-end metadata management, giving you the freedom to unlock the value of your data assets.
OpenMetadata includes the following:
- Metadata Schemas - Defines core abstractions and vocabulary for metadata with schemas for Types, Entities, and Relationships between entities. This is the foundation of the Open Metadata Standard. Also supports the extensibility of entities and types with custom properties.
- Metadata Store - Stores metadata graph that connects data assets, user, and tool-generated metadata.
- Metadata APIs - For producing and consuming metadata built on schemas for User Interfaces and Integration of tools, systems, and services.
- Ingestion Framework - A pluggable framework for integrating tools and ingesting metadata to the metadata store, supporting about 55 connectors. The ingestion framework supports well know data warehouses like Google BigQuery, Snowflake, Amazon Redshift, and Apache Hive; databases like MySQL, Postgres, Oracle, and MSSQL; dashboard services like Tableau, Superset, and Metabase; messaging services like Kafka, Redpanda; and pipeline services like Airflow, Glue, Fivetran, Dagster, and many more.
- OpenMetadata User Interface - A single place for users to discover and collaborate on all data.
DataHub is an extensible metadata platform that enables data discovery, data observability and federated governance to help tame the complexity of your data ecosystem.
Important Capabilities
| Capability | Status | Notes |
|---|---|---|
| Dataset Usage | ❌ | . |
| Detect Deleted Entities | ✅ | Enabled via stateful ingestion |
| Table-Level Lineage | ✅ | Enabled by default |
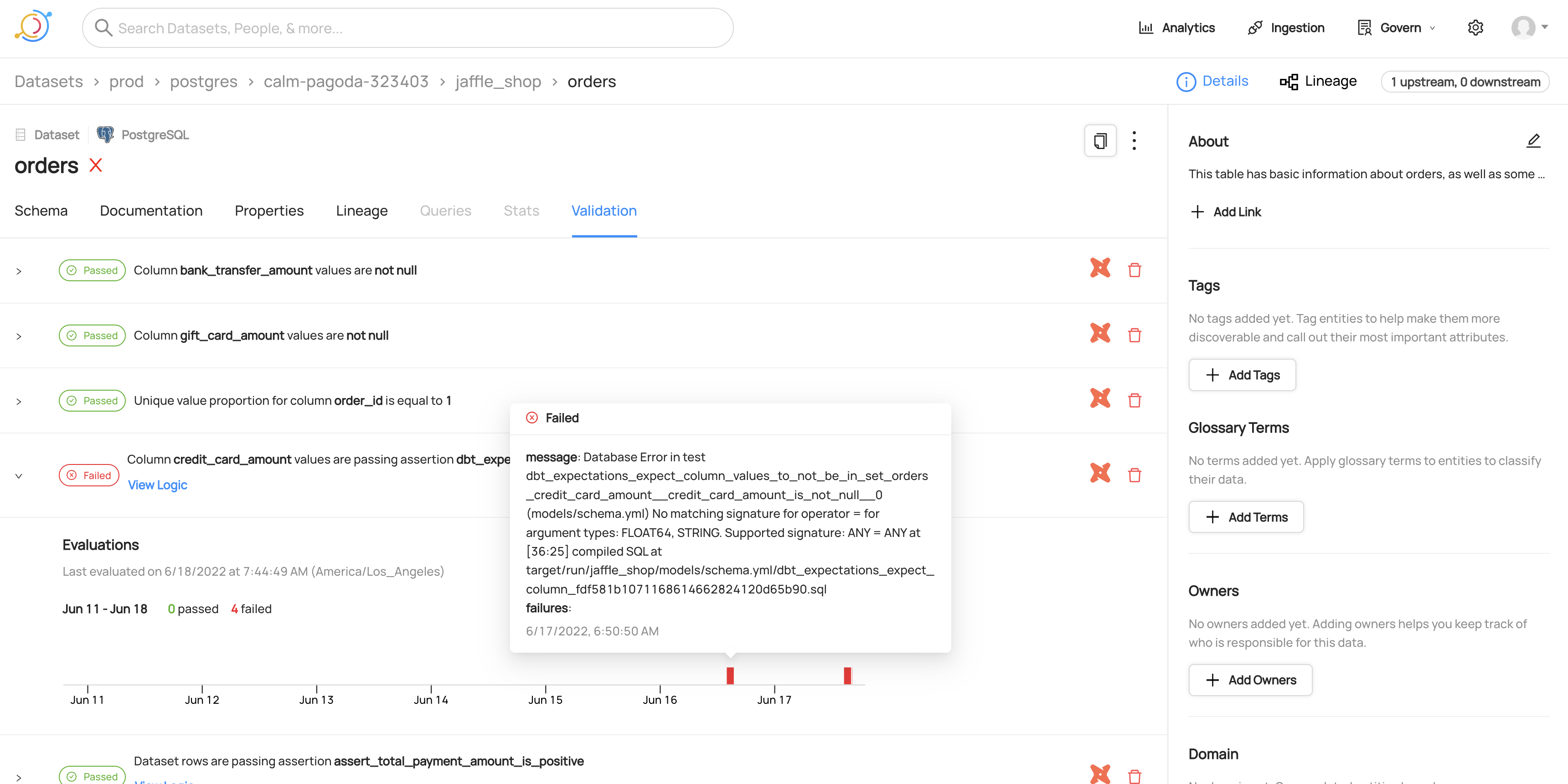
View of dbt tests for a dataset
Viewing the SQL for a dbt test
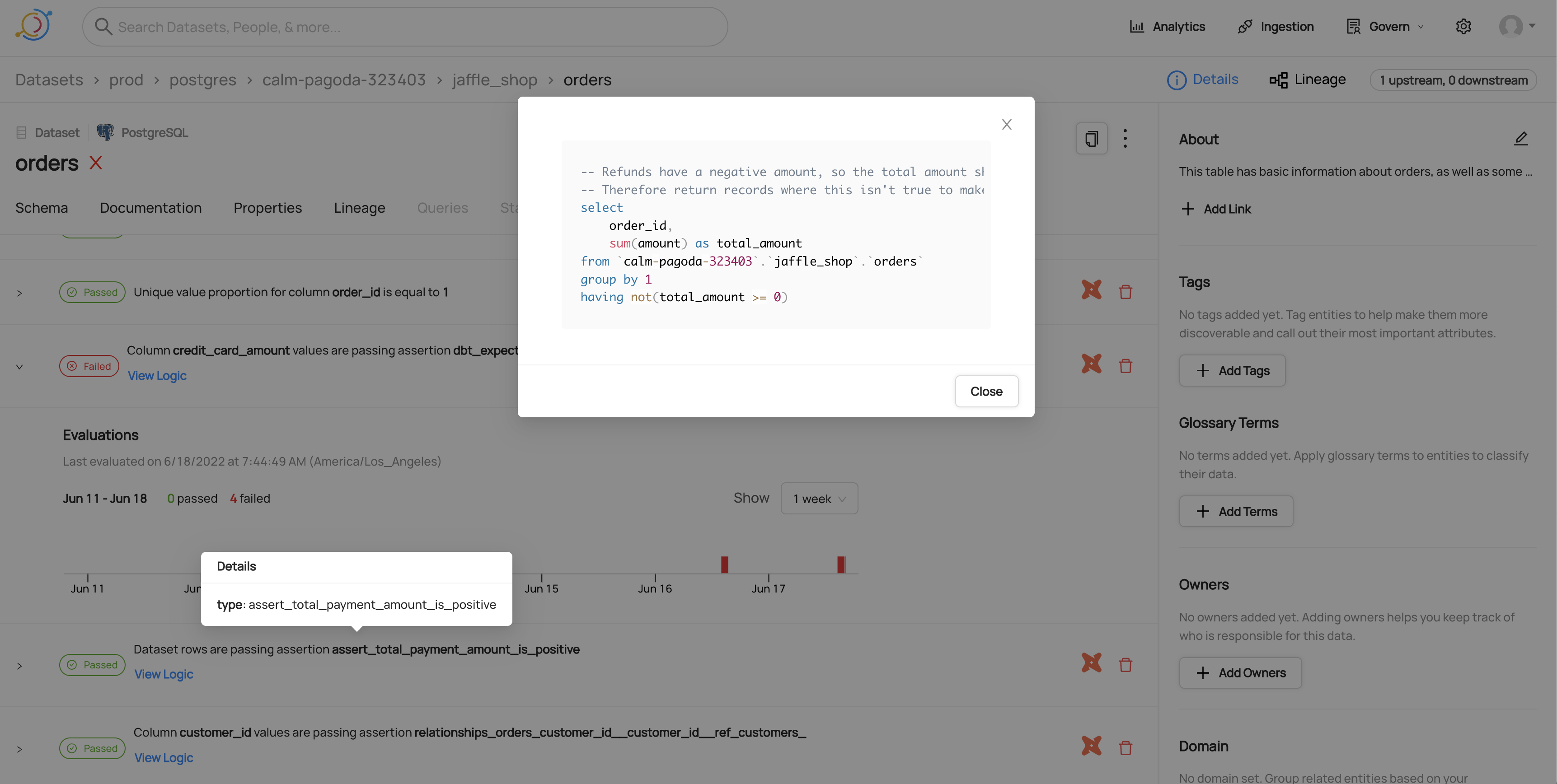
Viewing timeline for a failed dbt test
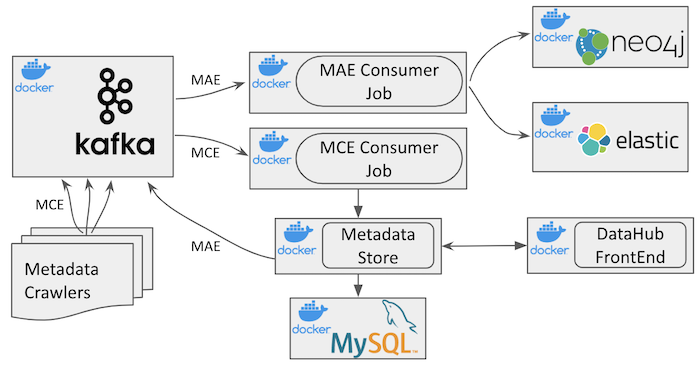
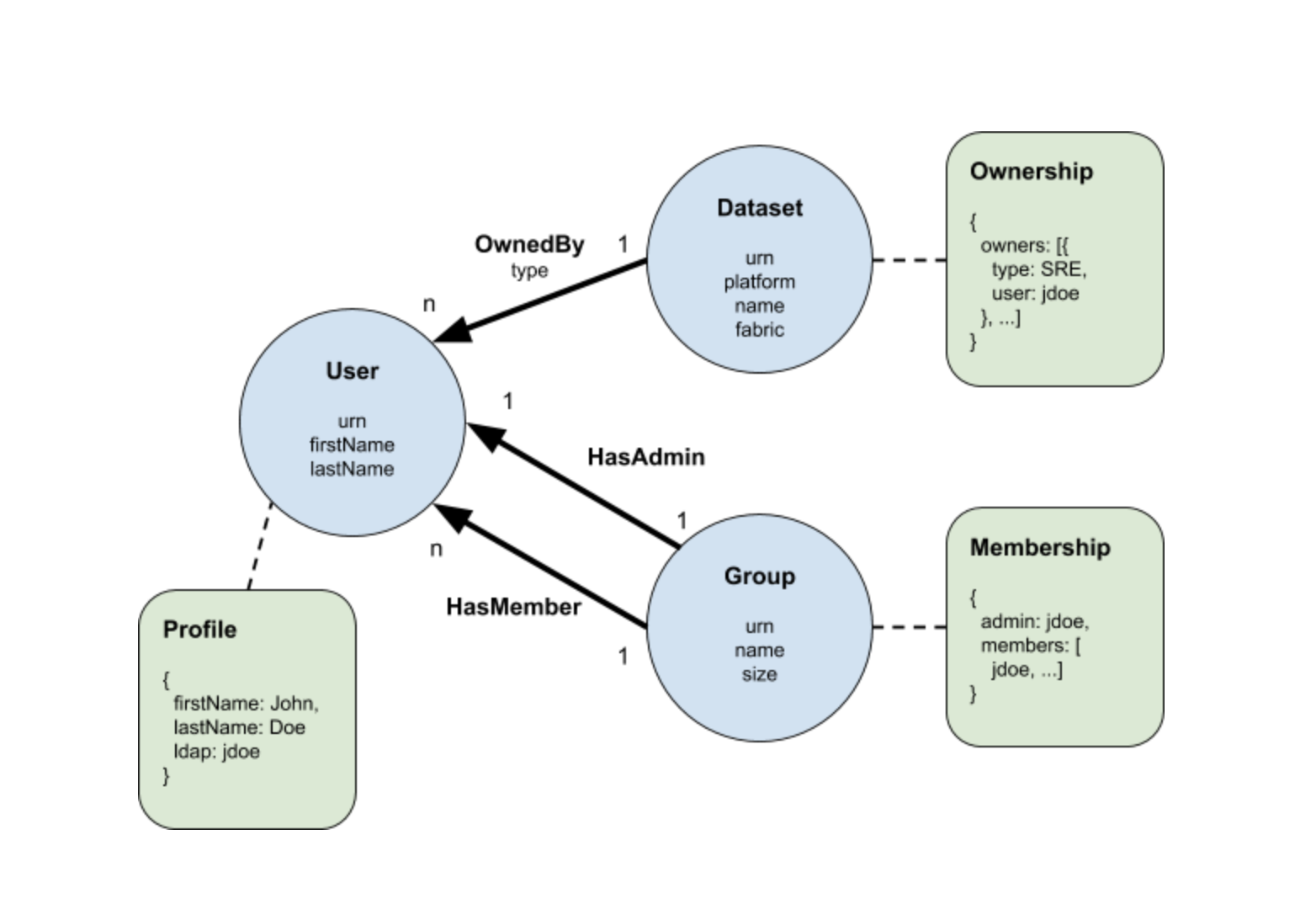
DataHub is an open-source metadata platform for the modern data stack. Read about the architectures of different metadata systems and why DataHub excels here. Also read our LinkedIn Engineering blog post, check out our Strata presentation and watch our Crunch Conference Talk. You should also visit DataHub Architecture to get a better understanding of how DataHub is implemented.


Monitor data pipelines in minutes, in your dbt project. Elementary is built for and trusted by 3000+ analytics and data engineers.
Elementary is an open-source data observability solution for data & analytics engineers.
Monitor your dbt project and data in minutes, and be the first to know of data issues. Gain immediate visibility, detect data issues, send actionable alerts, and understand the impact and root cause.
Key features
-
Data observability report (live demo)
Generate a data observability report, host it or share with your team.
-
Data anomaly detection as dbt tests
Monitoring of data quality metrics, freshness, volume and schema changes, including anomaly detection. Elementary data monitors are configured and executed like native tests in dbt your project.
-
Models performance
Visibility of execution times, easy detection of degradation and bottlenecks.
-
dbt artifacts and run results
Uploading and modeling of dbt artifacts, run and test results to tables as part of your runs.
-
Slack alerts
Get informative notifications on data issues, schema changes, models and tests failures.
-
Data lineage
Inspect upstream and downstream dependencies to understand impact and root cause of data issues.
How it works?
For the data monitoring and dbt artifacts collection, we developed a dbt package. The monitoring configuration is configured in your dbt project, and the monitors are dbt macros and models. All the collected data is saved to an elementary schema in your DWH.
After deploying the dbt package, connect to Elementary Cloud or install the Elementary CLI to work with the UI and send Slack alerts.
To start using Elementary to monitor you tests, executions and data, you need to add our dbt package to your dbt project.
Elementary is an open-source data observability solution, built for dbt users. Setup in minutes, gain immediate visibility, detect data issues, send actionable alerts, and understand impact and root cause.

Test and query metrics
python -m pip install dbt-metricflow
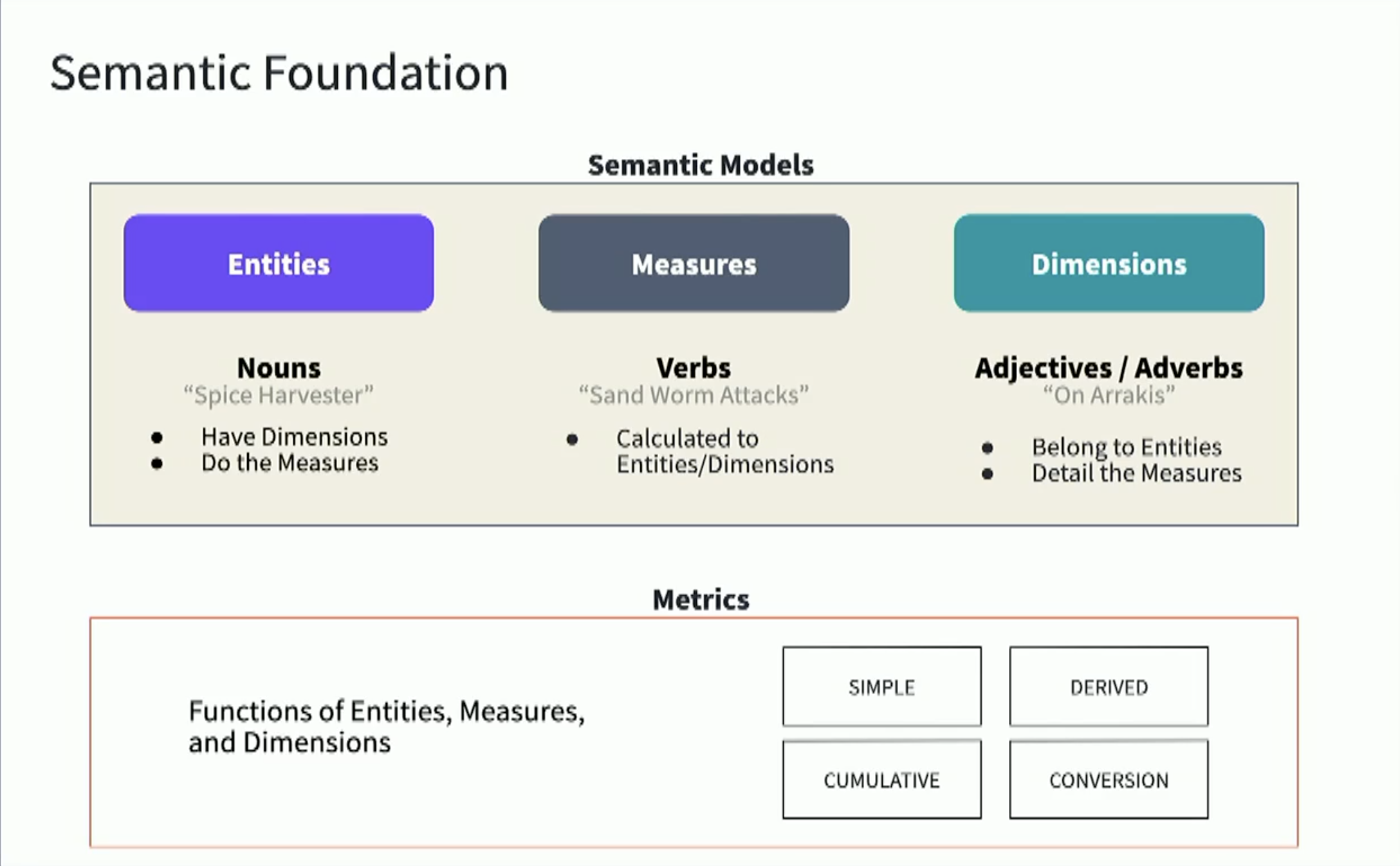
Semantic models
Semantic models are the starting points of data and correspond to models in your dbt project. You can create multiple semantic models from each model. Semantic models have metadata, like a data table, that define important information such as the table name and primary keys for the graph to be navigated correctly.
For a semantic model, there are three main pieces of metadata:
- Entities — The join keys of your semantic model (think of these as the traversal paths, or edges between semantic models).
- Dimensions — These are the ways you want to group or slice/dice your metrics.
- Measures — The aggregation functions that give you a numeric result and can be used to create your metrics.
There are two ways of defining tests in dbt:
- A
singular test(@@data test) is testing in its simplest form: If you can write a SQL query that returns failing rows, you can save that query in a.sqlfile within yourtest/directory. It's now a test, and it will be executed by thedbt testcommand. - A
generic test(@@schema test, queries which return thenumber 0to pass else fails) is a parametrized query that accepts arguments. The test query is defined in a specialtestblock (like a macro). Once defined, you can reference the generic test by name throughout your.ymlfiles—define it on models, columns, sources, snapshots, and seeds. dbt ships with four generic tests built in, and we think you should use them!

Apply a tag (or list of tags) to a resource.
These tags can be used as part of the resource selection syntax, when running the following commands:
- dbt run --select tag:my_tag
- dbt seed --select tag:my_tag
- dbt snapshot --select tag:my_tag
- dbt test --select tag:my_tag (indirectly runs all tests associated with the models that are tagged)
-
Use tags to run parts of your project
Apply tags in your dbt_project.yml as a single value or a string:
#dbt_project.yml
models:
jaffle_shop:
+tags: "contains_pii"
staging:
+tags:
- "hourly"
marts:
+tags:
- "hourly"
- "published"
metrics:
+tags:
- "daily"
- "published"
- You can also apply tags to individual resources using a config block:
#models/staging/stg_payments.sql
{{ config(
tags=["finance"]
) }}
select ...
- Then, run part of your project like so:
# Run all models tagged "daily"
$ dbt run --select tag:daily
# Run all models tagged "daily", except those that are tagged hourly
$ dbt run --select tag:daily --exclude tag:hourly
The meta config can also be defined:
under the models config block in dbt_project.yml
in a config() Jinja macro within a model's SQL file
-
Designate a model owner
Additionally, indicate the maturity of a model using a model_maturity: key.
#models/schema.yml
version: 2
models:
- name: users
meta:
owner: "@alice"
model_maturity: in dev
- Override one meta attribute for a single model
#models/my_model.sql
{{ config(meta = {
'single_key': 'override'
}) }}
select 1 as id
from dbt.cli.main import dbtRunner, dbtRunnerResult
# initialize
dbt = dbtRunner()
# create CLI args as a list of strings
cli_args = ["run", "--select", "tag:my_tag"]
# run the command
res: dbtRunnerResult = dbt.invoke(cli_args)
# inspect the results
for r in res.result:
print(f"{r.node.name}: {r.status}")
The env_var function can be used to incorporate Environment Variables from the system into your dbt project. This env_var function can be used in your profiles.yml file, the dbt_project.yml file, the sources.yml file, your schema.yml files, and in model .sql files. Essentially env_var is available anywhere dbt processes jinja code.
The graph context variable contains information about the nodes in your dbt project. Models, sources, tests, and snapshots are all examples of nodes in dbt projects.
The run_query macro provides a convenient way to run queries and fetch their results. It is a wrapper around the statement block, which is more flexible, but also more complicated to use.
statements are sql queries that hit the database and return results to your Jinja context. Here’s an example of a statement which gets all of the states from a users table.
{% ... %}for Statements{{ ... }}for Expressions to print to the template output{# ... #}for Comments not included in the template output
{% set iterated = false %}
{% set seq = ['a', 'b', 'c'] %}
{% for item in seq %}
{{ item }}
{% set iterated = true %}
{% endfor %}
{% if not iterated %} did not iterate {% endif %}
Variables can be modified by filters. Filters are separated from the variable by a pipe symbol (|) and may have optional arguments in parentheses. Multiple filters can be chained. The output of one filter is applied to the next.
For example, {{ name|striptags|title }} will remove all HTML Tags from variable name and title-case the output (title(striptags(name))).
Filters that accept arguments have parentheses around the arguments, just like a function call. For example: {{ listx|join(', ') }} will join a list with commas (str.join(', ', listx)).
The List of Builtin Filters below describes all the builtin filters.
IF
{% if kenny.sick %}
Kenny is sick.
{% elif kenny.dead %}
You killed Kenny! You bastard!!!
{% else %}
Kenny looks okay --- so far
{% endif %}
Assignments
Inside code blocks, you can also assign values to variables. Assignments at top level (outside of blocks, macros or loops) are exported from the template like top level macros and can be imported by other templates.
Assignments use the set tag and can have multiple targets:
{% set navigation = [('index.html', 'Index'), ('about.html', 'About')] %}
{% set key, value = call_something() %}
Block Assignments
Starting with Jinja 2.8, it’s possible to also use block assignments to capture the contents of a block into a variable name. This can be useful in some situations as an alternative for macros. In that case, instead of using an equals sign and a value, you just write the variable name and then everything until {% endset %} is captured.
Example:
{% set navigation %}
<li><a href="/">Index</a>
<li><a href="/downloads">Downloads</a>
{% endset %}
The navigation variable then contains the navigation HTML source.
Starting with Jinja 2.10, the block assignment supports filters.
Example:
{% set reply | wordwrap %}
You wrote:
{{ message }}
{% endset %}
- Union together your sources in one model
{% set countries = ['au', 'us'] %}
{% for country in countries %}
select
*,
'{{ country }}' as country
from {{ source(country, 'orders') }}
{% if not loop.last -%} union all {%- endif %}
{% endfor %}
{% set countries = ['au', 'us'] %}
{% set shopify_order_sources = [] %}
{% for country in countries %}
{% do shopify_order_sources.append(source('shopify_' ~ country, 'orders') %}
{% endfor %}
{{ dbt_utils.union_relations(shopify_order_sources) }}
{{ union_shopify_sources(countries=['au', 'us'], table_name = 'orders') }}
{% macro get_sources(source_prefix, table_name) %}
{% set sources = [] %}
{% if execute %}
{% for node_name, node in graph.nodes.items() %}
{% if node.resource_type == 'source' and node.name == table_name and node.source_name.startswith(source_prefix) %}
{% set new_source = source(node.source_name, node.name) %}
{% do sources.append(new_source) %}
{% endif %}
{% endfor %}
{% do return(sources) %}
{% endif %}
{% endmacro %}
- List
{# Initialise myList with some values #}
{% set myList = [1,5,3,4,2] %}
{%- set size = myList|length() -%}
{%- set ret -%}
use idx {{size-1}}: {{ myList[size-1] }}
use last: {{ myList|last() }}
{% endset %}
{# add 5 to myList #}
{% do myList.append(6) %}
{# remove the second item from the list #}
{% set temp = myList.pop(1) %}
{# find the index of the number 2 in myList #}
{% set myIndex = myList.index(2) %}
{# pop the number two from myList #}
{% set temp = myList.pop(myIndex) %}
{# output the list and index of 1 #}
{{ "values in my list:"}}
{{ myList }}
{% set indexOne = myList.index(1) %}
{{ "</br> index of the number one:" }}
{{ indexOne }}
Output:
values in my list: [1,3,4,5]
index of the number one: 0
- Tuple
{# Creating a list of URL adresses with captions #}
{# Create an empty list for storing my URLs #}
{% set myUrls = [] %}
{# append some URLs to myList #}
{% append ("index.html", "Landing page") to myUrls %}
{% append ("cart.html", "Cart") to myUrls %}
{# Output the second value of the second tuple in my list #}
{{ myUrls[1][1] }}
Output: Cart
- DIctionary
{# initialise the dictionary #}
{% set customer = ({"Name":"Peter","Surname": "Smith"}) %}
{# Output the value stored by the key Name #}
{{ customer["Name"] }}
Output: Peter
- template
{{ myList }}
{{ myList[0] }}
{{ myList.pop() }}
{{ myList|join(':') }}
- values
myList : [1,5,3,4,2]
- output
[1,·5,·3,·4,·2]
1
2
1:5:3:4
-
send_anonymous_usage_stats
We want to build the best version of dbt possible, and a crucial part of that is understanding how users work with dbt. To this end, we've added some simple event tracking to dbt (using Snowplow). We do not track credentials, model contents or model names (we consider these private, and frankly none of our business).
Usage statistics are fired when dbt is invoked and when models are run. These events contain basic platform information (OS + python version). You can see all the event definitions in tracking.py.
By default this is turned on – you can opt out of event tracking at any time by adding the following to your profiles.yml file:
config:
send_anonymous_usage_stats: False
Authentication Methods
-
OAuth via gcloud
-
Oauth Token-Based
-
Refresh token
refresh_token: [token] client_id: [client id] client_secret: [client secret] token_uri: [redirect URI] <optional_config>: <value>refer to Google Auth Library: Node.js Client
"token_uri": "https://accounts.google.com/o/oauth2/token"
-
-
Service Account File
-
Service Account JSON
Produced by: Any command that parses your project. This includes all commands except deps, clean, debug, init
This single file manifest.json contains a full representation of your dbt project's resources (models, tests, macros, etc), including all node configurations and resource properties. Even if you're only running some models or tests, all resources will appear in the manifest (unless they are disabled) with most of their properties. (A few node properties, such as compiled_sql, only appear for executed nodes.)
Produced by: build compile docs generate run seed snapshot test run-operation
This file contains information about a completed invocation of dbt, including timing and status info for each node (model, test, etc) that was executed. In aggregate, many run_results.json can be combined to calculate average model runtime, test failure rates, the number of record changes captured by snapshots, etc.
Produced by: docs generate
This file catalog.json contains information from your data warehouse about the tables and views produced and defined by the resources in your project. Today, dbt uses this file to populate metadata, such as column types and table statistics, in the docs site.
4.2.Guides-How to
What are the techniques, analyses, reporting frameworks + human working relationships that we employ at dbt Labs, and how are those going for us? This living and ever-growing collection of writing shares all.
Short, actionable guides on data workflows that you can use and replicate in your own organization.
Follow our internal data team members as they take a data project from a request to production.
We love these SQL functions so much that we thought we should write them a letter professing how they’ve made our lives better. These letters are a great way to learn how to get the most out of these functions.
Get the play-by-play of our internal data team members’ typical day, and learn some life hacks along the way.
- What is analytics engineering?
- Why does it exist?
-
A love letter to ETL tools
-
The case for the ELT workflow
-
Modular data modeling technique
-
Data testing
-
Data cataloging
-
Version control with Git
-
Business intelligence reporting
-
Data science
-
Operational analytics
-
Exploratory analysis
-
Writing analytics job descriptions
-
Data org structure examples
-
Centralized vs decentralized data teams
-
Hiring an analytics engineer
-
When to hire a data engineer?
-
Adam Stone's Career Story
-
Tom Nagengast's Career Story
-
dbt jobs board
-
Model Naming
-
Model configuration
-
Testing
-
Naming and field conventions
-
CTEs
-
SQL style guide
-
YAML style guide
-
Jinja style guide
The data warehouse contains source data from different source systems, via different extraction methodologies (i.e. Fivetran, Stich and Postgres pipeline). This page describes the different data sources and the way we extract this data via data pipelines.
Data Customers expect Data Teams to provide data they can trust to make their important decisions. And Data Teams need to be confident in the quality of data they deliver. But this is a hard problem to solve: the Enterprise Data Platform is complex and involves multiple stages of data processing and transformation, with tens to hundreds of developers and end-users actively changing and querying data 24 hours a day. The Trusted Data Framework (TDF) supports these quality and trust needs by defining a standard framework for data testing and monitoring across data processing stages, accessible by technical teams and business teams. Implemented as a stand-alone module separate from existing data processing technology, the TDF fulfills the need for an independent data monitoring solution.
- Enable everyone to contribute to trusted data, not just analysts and engineers
- Enable data validations from top to bottom and across all stages of data processing
- Validate data from source system data pipelines
- Validate data transforms into dimensional models
- Validate critical company data
- Deployable independently from central data processing technology
- Key Terms
This page documents the CI jobs used by the data team in Merge Requests in both the Data Tests and Analytics projects.
The Enterprise Dimensional Model (EDM) is GitLab's centralized data model, designed to enable and support the highest levels of accuracy and quality for reporting and analytics. The data model follows the Kimball technique, including a Bus Matrix and Entity Relationship Diagram. Dimensional Modeling is the third step of our overarching Data Development Approach (after Requirements definition and UI Wireframing) and this overall approach enables us to repeatedly produce high-quality data solutions. The EDM is housed in our Snowflake Enterprise Data Warehouse and is generated using dbt.
In order to make it easy for anyone to send data from Snowflake to other applications in the GitLab tech stack we have partnered with the Enterprise Applications Integration Engineering team to create this data integration framework, which we are calling Data Pump.
It is the Data team's collective responsibility to promote, respect, and improve our Python Style Guide since not all the things can be caught up by the tools we are using. This deliberate attention makes a difference and does a lot to ensure high-quality code. The main motivation to have comprehensive and useful Python guidelines is to ensure a high standard of code quality is maintained in our work. As we use this guideline as a support in that daily work, which is always changing, this guide is likewise always subject to iteration. In the long run this guide will help us to have a world-class code quality we should be proud of. All the changes are driven by our values.
Snowplow is an open source, event analytics platform. There is a business entity that runs SaaS for Snowplow and they also maintain the code for the open source product. The general architecture overview of snowplow is on GitHub and has more detail on the basics of how it works and how it is set up.
In June of 2019, we switched sending Snowplow events from a third party to sending them to infrastructure managed by GitLab, documented on this page. From the perspective of the data team, not much changed from the third party implementation. Events are sent through the collector and enricher and dumped to S3.
This guide establishes our standards for SQL and are enforced by the SQLFluff linter and by code review. The target code changes that this stile guide apply to are those made using dbt.
If you are not on the Data Team or you are developing SQL outside of dbt, keep in mind that the linting tools may be more difficult to apply, but you are welcome to follow the guidance given within this guide.
-
Usage
-
SQLFluff
- Changes from the default configuration
-
General Guidance
-
Best Practices
-
Commenting
-
Naming Conventions
-
Reference Conventions
-
Common Table Expressions (CTEs)
-
Data Types
-
Functions
-
What and why
-
Running dbt
- Configuration
- Venv Workflow
- Using dbt
- Docker Workflow
- Using dbt
- Command line cheat sheet
- model selection
dbt run --models modelname- will only run modelnamedbt run --models +modelname- will run modelname and all parentsdbt run --models modelname+- will run modelname and all childrendbt run --models +modelname+- will run modelname, and all parents and childrendbt run --models @modelname- will run modelname, all parents, all children, AND all parents of all childrendbt run --exclude modelname- will run all models except modelname
- model selection
- Configuration for contributing to dbt project
-
Style and Usage Guide
- Model Structure
- General
- Seeds
- Tags
- Trusted Data Framework
- Snapshots
- Testing Downstream Impact
-
Upgrading dbt
-
The Data Quality Program
-
Types Of Data Quality Problems
-
Data Quality System Components
- Operational Process
- Fixing Data Quality Problems
- Product Data Quality Scorecard
- Quick Links
-
Additional Resources
-
Guides and Books
- SaaS Tools
- Custom
- BambooHR
- Postgres Pipeline
-
Transformation Data Quality
-
-
Data Pipeline Health Dashboard
-
Product Usage Metrics Coverage Dashboard
-
dbt style guide
-
sql style guide
-
PR template.
This guide was created to introduce DBT to our team. The main objective is to provide clear and consistent instructions and standards, to make it easier for users to get started, and to avoid some of the issues we encountered before. Some practices are based on articles from the DBT community and Gitlab Data Team. The relevant links are provided within the guide.
這個 Guide 是先前 team 內決定要嘗試導入 DBT 時,順帶為了解決組織遇到的問題所訂出的使用規範,主要目的是希望透過清楚統一的說明和規則,讓後續使用者容易上手,也讓 DE 的日子好過一點(苦笑 部分結構是參考 DBT 社群及 Gitlab Data Team 的文章,在 Guide 裡面可以找到相關連結
- generate_source
$ dbt run-operation generate_source --args '{"schema_name": "jaffle_shop", "database_name": "raw", "table_names":["table_1", "table_2"]}'
-
generate_base_model
-
generate_model_yaml
It will generate non-unique d41d8cd98f00b204e9800998ecf8427e for NULL value.
dbt-expectations is an extension package for dbt, inspired by the Great Expectations package for Python. The intent is to allow dbt users to deploy GE-like tests in their data warehouse directly from dbt, vs having to add another integration with their data warehouse.
dbt-profiler implements dbt macros for profiling database relations and creating doc blocks and table schemas (schema.yml) containing said profiles. A calculated profile contains the following measures for each column in a relation:
column_name: Name of the columndata_type: Data type of the columnnot_null_proportion^: Proportion of column values that are notNULL(e.g.,0.62means that 62% of the values are populated while 38% areNULL)distinct_proportion^: Proportion of unique column values (e.g.,1means that 100% of the values are unique)distinct_count^: Count of unique column valuesis_unique^: True if all column values are uniquemin*^: Minimum column valuemax*^: Maximum column valueavg**^: Average column valuestd_dev_population**^: Population standard deviationstd_dev_sample**^: Sample standard deviationprofiled_at: Profile calculation date and time
This dbt package helps to create simple data models from the outputs of dbt sources freshness and dbt tests. That is, this package will help you to
- Access and report on the output from
dbt source freshness(sources.json,manifest.json) - Access and report on the output from
dbt tests(run_results.json,manifest.json)
Prerequisites
- This package is compatible with dbt 1.0.0 and later
- This packages uses Snowflake as the backend for reporting (contributions to support other backend engines are welcomed)
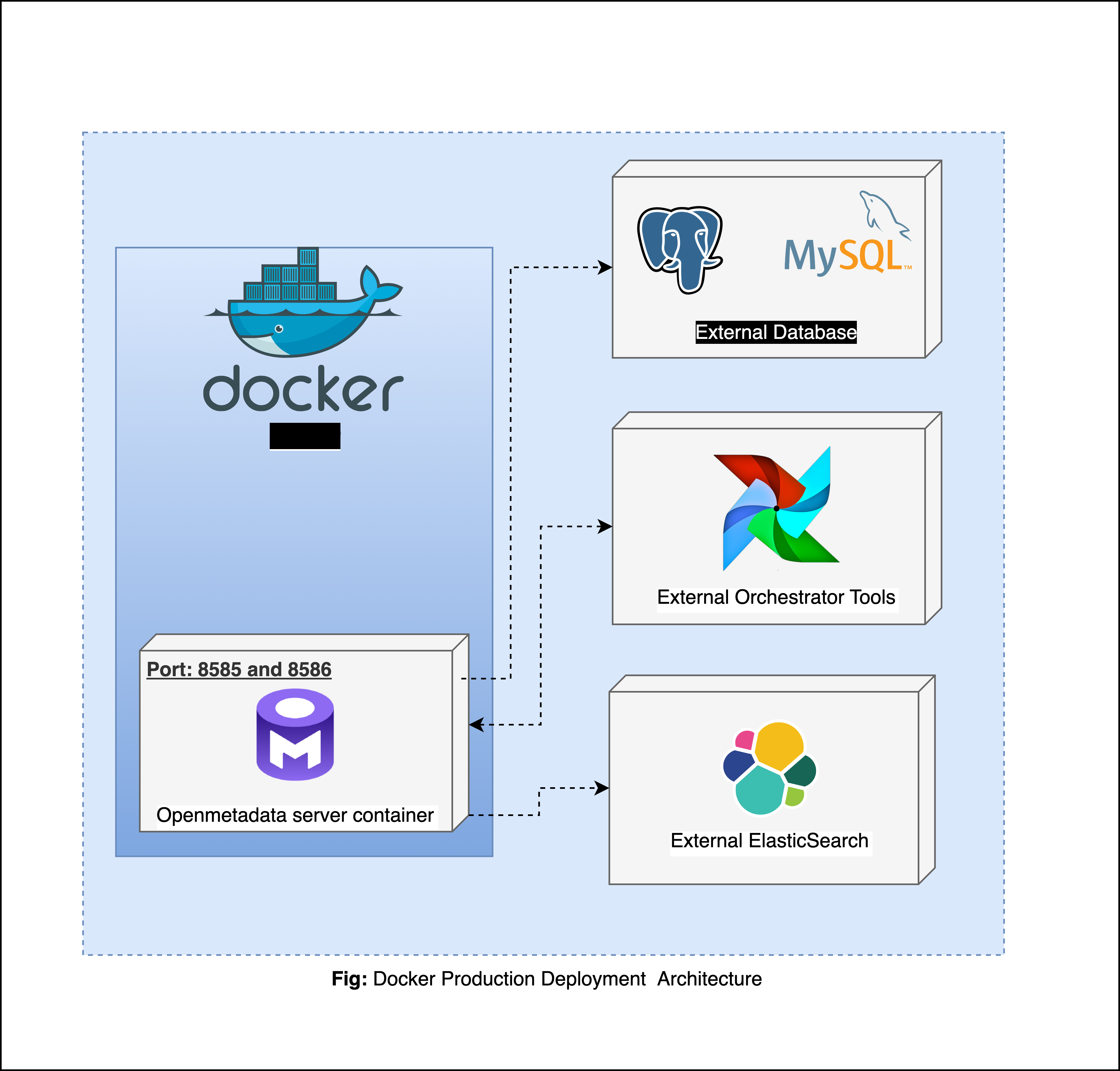
Architecture Overview
- Bonus - it provides a ready-to-go Power BI dashboard built on top the dbt models created by the package to showcase all features
A package for dbt which enables standardization of data sets. You can use it to build a feature store in your data warehouse, without using external libraries like Spark's mllib or Python's scikit-learn.
Currently they have been tested in Snowflake, Redshift , BigQuery, SQL Server and PostgreSQL 13.2. The test case expectations have been built using scikit-learn (see *.py in integration_tests/data/sql), so you can expect behavioural parity with it.
location: models/customers.sql
location: tests/unit/tests.sql
This dbt package is part of Elementary, the dbt-native data observability solution for data and analytics engineers. Set up in minutes, gain immediate visibility, detect data issues, send actionable alerts, and understand impact and root cause. Available as self-hosted or Cloud service with premium features.
In order to deploy your documentation site, you’ll need to
- create a netlify account
- run dbt docs generate from within your dbt folder
- drag the “target” folder from dbt into netlify where it says to “drag and drop your site folder here”
- this will create a manual site and viola you are done!
- Add seed files for your expected input and output to your dbt project
- In your models, ref the static data
- Add an “equality” test to check that the expected input matches the expected output
- Run your test with --target ci
- Parameterize the equality test to accept an environment argument.
- At small data volumes, your best bet is a simple
mergeinto a clustered table. - As data volume scales, switch to dynamic
insert_overwrite. You don’t have to think about it too hard. - Once you know exactly how your incremental runs should be working—always reprocessing the past three days, for instance, with solid alerting if a dbt run fails a few days in a row—put on your data engineering hat, define some static partitions, and profit.
Have you had a look at operations? This is pretty much what they’re designed to do.
| Series | Snowflake | Databricks | dbt Lab |
|---|---|---|---|
| A | 201208, 5M | 201309, 14M | 202004, 12.9M |
| B | 201410, 26M | 201406, 33M | 202011, 29.5M |
| C | 201506, 79M | 201612, 60M | 202106, 150M |
| D | 201709, 105M | 201708, 140M | 202202, 222M |
| . | - | - | - |
| G | 202002, 479M | 202102, 1B | - |
| H | IPO:202009, 3.4B | 202108, 1.6B | - |
20211208 dbt Core v1.0 is here: 200+ contributors, 5,000 commits, 100x faster parsing speed, EN, ★★★
With this version, users will benefit from:
- Improved performance to ensure quick development cycles in dbt projects of all sizes
- Increased stability, so you can feel confident building projects and tooling on top of dbt.
- Opinionated workflows, such as the dbt build command for multi-resource runs
- Intuitive interfaces making it easier to configure projects and deployments
- Easier upgrades to newer versions, so you’re always getting the latest & greatest that dbt has to offer

Our PR template (view markdown file in GitHub) is composed of 6 sections:
- Description & motivation
- To-do before merge (optional)
- Screenshots
- Validation of models
- Changes to existing models
- Checklist

We’ve just cut a first release candidate of dbt Core v0.21 (Louis Kahn), which includes some long-sought-after additions:
- A dbt build command for multi-resource runs (watch Staging!)
- Defining configs in all the places you’d expect
- Handling for column schema changes in incremental models
20210602 How Airbnb Standardized Metric Computation at Scale | by Amit Pahwa | The Airbnb Tech Blog | Medium



Since we last wrote about dbt, we've used it in a few projects and like what we've seen. For example, we like that dbt makes the transformation part of ELT pipelines more accessible to consumers of the data as opposed to just the data engineers building the pipelines. It does this while encouraging good engineering practices such as versioning, automated testing and deployment. SQL continues to be the lingua franca of the data world (including databases, warehouses, query engines, data lakes and analytical platforms) and most of these systems support it to some extent. This allows dbt to be used against these systems for transformations by just building adaptors. The number of native connectors has grown to include Snowflake, BigQuery, Redshift and Postgres, as has the range of community plugins. We see tools like dbt helping data platforms become more "self service" capable.
Airflow is an essential part of our software stack. Data pipelines and machine learning models at Snowflake are driven by Snowhouse (our own instance of Snowflake, which is a SaaS-based platform), dbt, and Airflow for modeling and transformation. Airflow is also used for the orchestration and scheduling of tasks
20210308 Build a DataOps platform to break silos between engineers and analysts | AWS Big Data Blog, EN
In this post, we discuss and build a data platform that fosters effective collaboration between engineers and analysts. We show you how to enable data analysts to transform data in Amazon Redshift by using software engineering practices—DataOps. We demonstrate how analytics transformations, defined as data build tool (dbt) models, can be submitted as part of a CI/CD pipeline, and then be scheduled and orchestrated by Apache Airflow.


20210228 How to set up a dbt data-ops workflow, using dbt cloud and Snowflake · Start Data Engineering
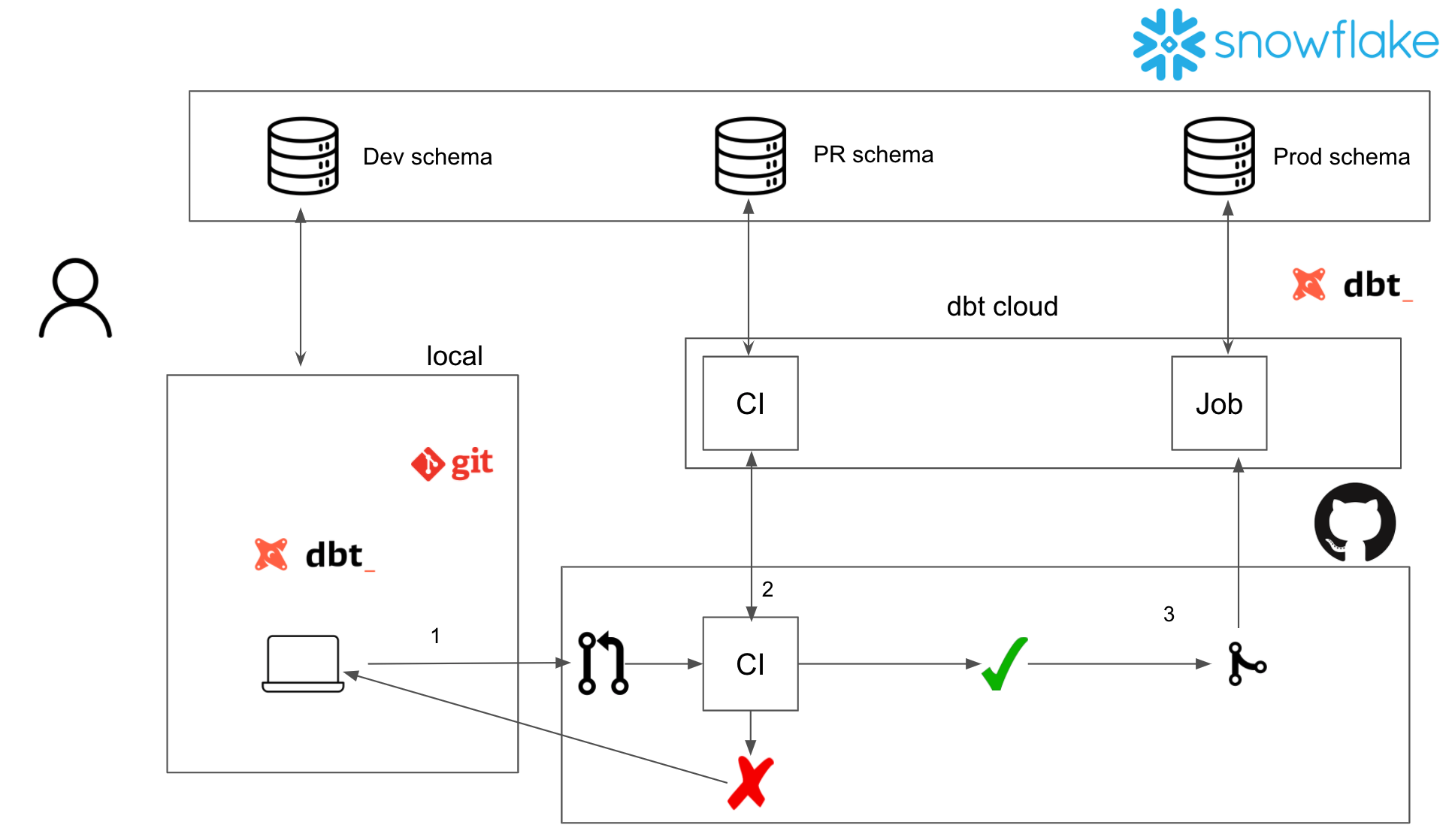

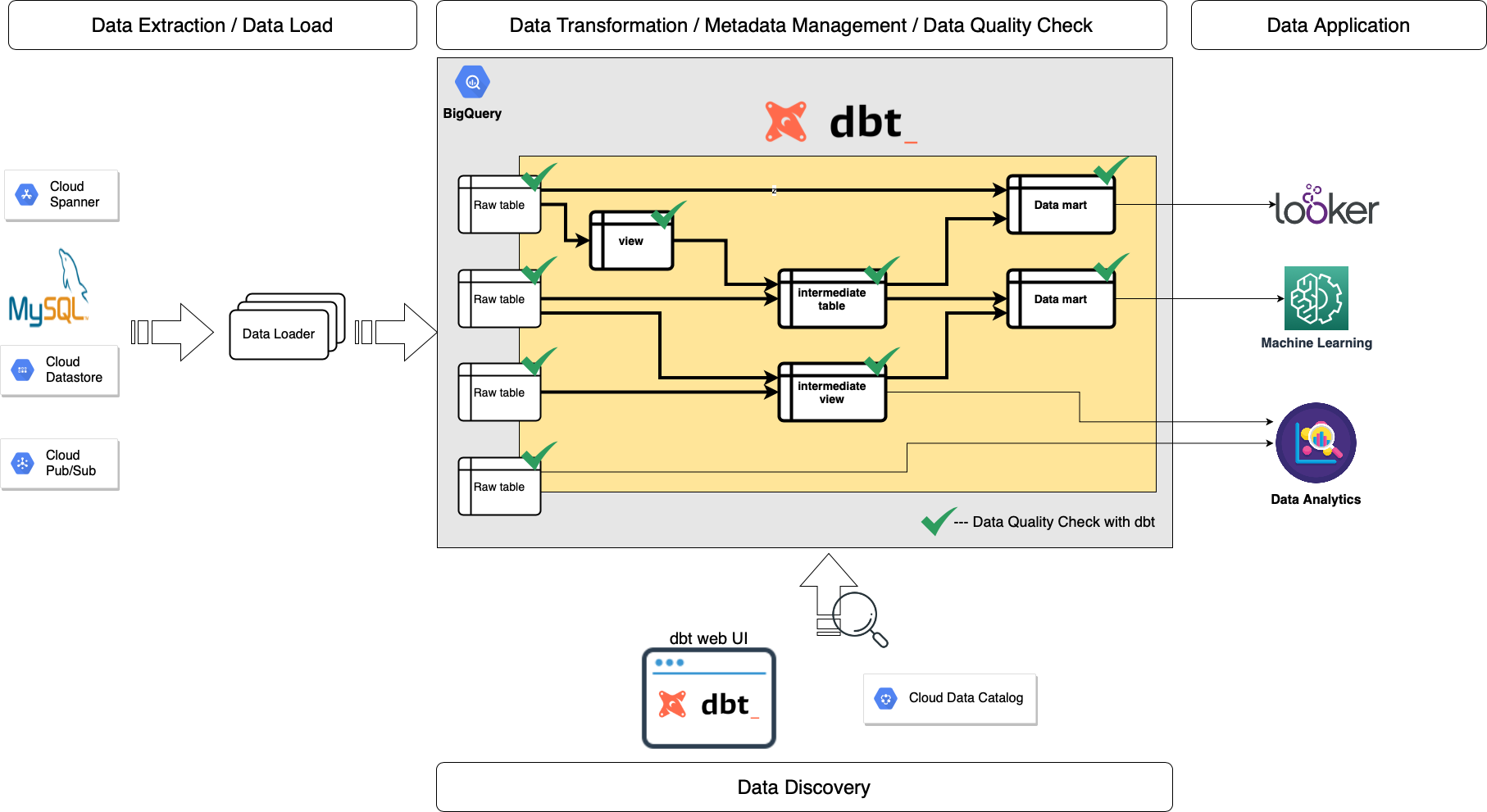
dbt also enables us to:
- 'model BigQuery tables and views' only by SQL files with dbt models,
- 'test data quality' of BigQuery tables and views by YAML files with dbt tests,
- 'check data freshness' of BigQuery tables and views by YAML with dbt source snapshot-freshness ,
- 'document metadata' of BigQuery tables and views with YAML and markdown dbt docs,
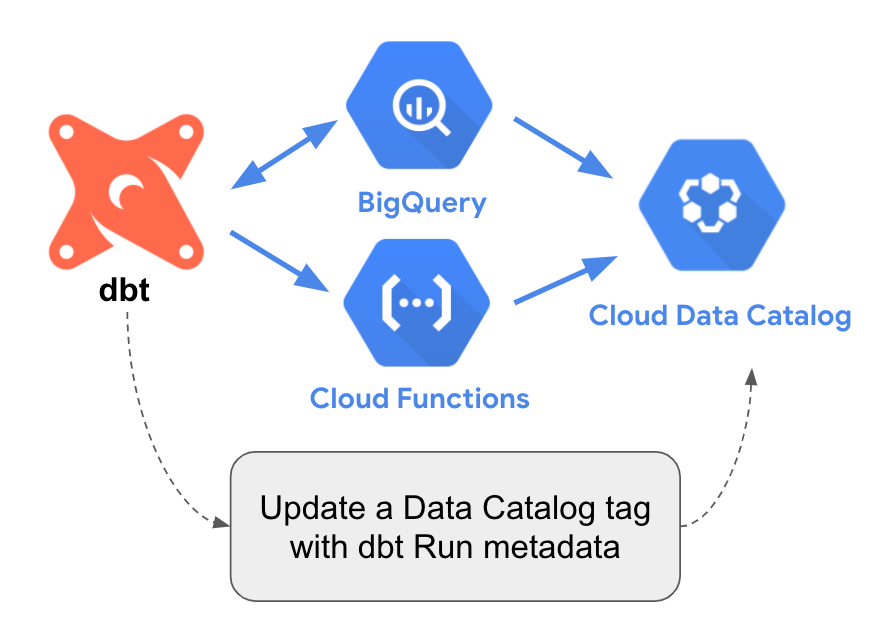
- 'search and discover' BigQuery tables and views with the dbt web UI and Cloud Data Catalog,
- 'visualize dependencies' of tables and views on the dbt web UI,
- use community packages to leverage dbt with dbt hub,
- 'make incremental snapshots' of BigQuery tables with dbt snapshots,
- 'share BigQuery queries' with dbt analyses, and
- 'manage metadata of data consumers' with dbt exposure.
As I described a little bit about the model selection syntax, we are able to select desired dbt models and sources with tags.
- First, we created custom tags to specify running environments that are only_prod, only_dev and WIP.
- Second, we have custom tags to schedule dbt models and tests.
-
- Tests
-
- Version control
-
- DAGs and dbt docs
-
- Environment management
-
- Ease of adoption and use
-
- The community
Check out our GitHub repo, where you can find our dbt style guide, sql style guide, and PR template.
20201005 Automating deployment of Amazon Redshift ETL jobs with AWS CodeBuild, AWS Batch, and DBT | AWS Big Data Blog, EN

20200409 Practical tips to get the best out of Data Build Tool (dbt) — Part 3 | by Stefano Solimito | Unboxing Photobox | Medium, EN
- How to orchestrate data pipelines and dbt models
- Document and serve
20200402 Practical tips to get the best out of Data Build Tool (dbt) — Part 2 | by Stefano Solimito | Unboxing Photobox | Medium
- get the best out of your dbt_project.yml file.
- dbt makes you rethink some aspects of traditional data warehousing.
- dbt Macros usage.
- wrap dbt.
20200327 Practical tips to get the best out of Data Build Tool (dbt) — Part 1 | by Stefano Solimito | Unboxing Photobox | Medium, EN, ★★★
-
One data platform, how many dbt projects?
Fig-0: Graphical representation of the different dbt projects organisation approaches.
The table below summarises the pros and cons of the listed approaches.

- dbt Models organisation.
If it's just running SQL I don't think much beyond templating/macros which is like either a stored procedure or dynamic SQL.
The main benefits are in workflow.
- Built in testing of code
- Implicit lineage DAG and being able to run full model, just the node, everything preceding the node, every dependent table after the node, or both
- Online data catalog and lineage, can easily search both objects and code
- Reusable macros
- Typically integrated with code repo (you can do this in any model but they try to enforce it)
If you are trying to build a scalable process of developing code dbt seems to check the boxes and you can implement in CI/CD. If you have 20 people developing code against a database it's going to get messy fast. If it's just writing SQL, SQL is SQL whether you put it in dbt or not, but running the DAG different ways and dbt will help your development, testing, and maintenance.
A dbt project can have many different ‘modules’, and a number of these are highlighted below:
- Models
- Tests
- Macros
- Analysis
- Docs
- Logs
- Target Directories (e.g. dev)
- dbt is a compiler and a runner
- dbt ships with a package manager
- a programming environment for your database

- Analytics is collaborative
- Version Control
- Quality Assurance
- Documentation
- Modularity
- Analytic code is an asset
- Environments
- Service level guarantees
- Design for maintainability
- Analytics workflows require automated tools
temp