-
Convert data type https://roboquery.com/app/convert-Microsoft_SQL_Server-to-snowflake
-
Ticket
-
Pricing
- Pricing Guide, https://www.snowflake.com/pricing/pricing-guide/
Temporary tables only exist within the session in which they were created and persist only for the remainder of the session. As such, they are not visible to other users or sessions. Once the session ends, data stored in the table is purged completely from the system and, therefore, is not recoverable, either by the user who created the table or Snowflake.
Snowflake supports creating transient tables that persist until explicitly dropped and are available to all users with the appropriate privileges. Transient tables are similar to permanent tables with the key difference that they do not have a Fail-safe period. As a result, transient tables are specifically designed for transitory data that needs to be maintained beyond each session (in contrast to temporary tables), but does not need the same level of data protection and recovery provided by permanent tables.
Introduction to Developing Applications in Snowflake — Introduction to developing applications in Snowflake.
Overview of Connectors, Drivers, and Client APIs — Information about the connectors, drivers, and client APIs that you use to develop client applications that connect to Snowflake.
- Introduction to Snowflake, https://docs.snowflake.net/manuals/user-guide-intro.html
- Connecting to Snowflake, https://docs.snowflake.net/manuals/user-guide-connecting.html
- Data Integration, https://docs.snowflake.net/manuals/user-guide/ecosystem-etl.html
- Snowflake Partner Connect
- SnowSQL (CLI Client)
- Snowflake Connector for Python
- Snowflake Connector for Spark, https://docs.snowflake.net/manuals/user-guide/spark-connector.html
- Node.js Driver
- Go Snowflake Driver
- .NET Driver
- JDBC Driver
- ODBC Driver
- Client Considerations
- Diagnosing Common Connectivity Issues
- https://docs.snowflake.net/manuals/user-guide/data-load-overview.html
- Bulk Loading Using COPY, https://docs.snowflake.net/manuals/user-guide/data-load-overview.html#bulk-loading-using-copy
- Data Loading Process, https://docs.snowflake.net/manuals/user-guide/data-load-overview.html#data-loading-process
- Tasks for Loading Data, https://docs.snowflake.net/manuals/user-guide/data-load-overview.html#tasks-for-loading-data
- Continuous Loading Using Snowpipe, https://docs.snowflake.net/manuals/user-guide/data-load-overview.html#continuous-loading-using-snowpipe
- Loading from Data Files Staged on Other Cloud Platforms, https://docs.snowflake.net/manuals/user-guide/data-load-overview.html#loading-from-data-files-staged-on-other-cloud-platforms
- https://docs.snowflake.net/manuals/user-guide/intro-summary-loading.html, Supported Character Sets (for Delimited Data Files)
- Data File Details, https://docs.snowflake.net/manuals/user-guide/intro-summary-loading.html#data-file-details
- Compression of Staged Files, https://docs.snowflake.net/manuals/user-guide/intro-summary-loading.html#compression-of-staged-files
- Encryption of Staged Files, https://docs.snowflake.net/manuals/user-guide/intro-summary-loading.html#encryption-of-staged-files
-
https://docs.snowflake.net/manuals/user-guide/data-load-considerations.html
-
Preparing Your Data Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-prepare.html
The number of data files that are processed in parallel is determined by the number and capacity of servers in a warehouse. We recommend splitting large files by line to avoid records that span chunks.
aggregate smaller files to minimize the processing overhead for each file. Split larger files into a greater number of smaller files to distribute the load among the servers in an active warehouse
split [-a suffix_length] [-b byte_count[k|m]] [-l line_count] [-p pattern] [file [name]]
If it takes longer than one minute to accumulate MBs of data in your source application, consider creating a new (potentially smaller) data file once per minute
-
Planning a Data Load, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-plan.html
-
Dedicating Separate Warehouses to Load and Query Operations, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-plan.html#dedicating-separate-warehouses-to-load-and-query-operations
-
Staging Data, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-stage.html
When staging regular data sets, we recommend partitioning the data into logical paths that include identifying details such as geographical location or other source identifiers, along with the date when the data was written. Organizing your data files by path lets you copy any fraction of the partitioned data into Snowflake with a single command.
-
Loading Data, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-load.html
-
Options for Selecting Staged Data Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-load.html#options-for-selecting-staged-data-files
-
Executing Parallel COPY Statements That Reference the Same Data Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-load.html#executing-parallel-copy-statements-that-reference-the-same-data-files
This prevents parallel COPY statements from loading the same files into the table, avoiding data duplication
-
Loading Older Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-load.html#loading-older-files
-
Removing JSON “null” Values, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-load.html#removing-json-null-values
-
Managing Regular Data Loads, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-manage.html
-
Partitioning Staged Data Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-manage.html#partitioning-staged-data-files
-
Loading Staged Data, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-manage.html#loading-staged-data
-
Removing Loaded Data Files, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-manage.html#removing-loaded-data-files
-
Troubleshooting Bulk Data Loads, https://docs.snowflake.net/manuals/user-guide/data-load-considerations-ts.html
-
https://docs.snowflake.net/manuals/user-guide/data-load-prepare.html
-
Supported Data Types, https://docs.snowflake.net/manuals/user-guide/data-load-prepare.html#supported-data-types
-
Data File Compression, https://docs.snowflake.net/manuals/user-guide/data-load-prepare.html#data-file-compression
-
Supported File Formats, https://docs.snowflake.net/manuals/user-guide/data-load-prepare.html#supported-file-formats
- Leading Spaces,
- Semi-structured File Formats
- Named File Formats
- Overriding Default File Format Options
-
Supported Copy Options, https://docs.snowflake.net/manuals/user-guide/data-load-prepare.html#supported-copy-options
-
Bulk Loading from a Local File System (fig-1), https://docs.snowflake.net/manuals/user-guide/data-load-local-file-system.html
-
Choosing a Stage for Local Files, https://docs.snowflake.net/manuals/user-guide/data-load-local-file-system-create-stage.html
-
Staging Data Files from a Local File System, https://docs.snowflake.net/manuals/user-guide/data-load-local-file-system-stage.html
-
Copying Data from an Internal Stage, https://docs.snowflake.net/manuals/user-guide/data-load-local-file-system-copy.html
- https://docs.snowflake.net/manuals/user-guide/querying-metadata.html
- Metadata Columns
- Query Limitations
- Query Examples
- https://docs.snowflake.net/manuals/user-guide/data-load-transform.html
- Usage Notes
- Transforming CSV Data
- Transforming Semi-structured Data
-
https://docs.snowflake.net/manuals/user-guide/data-unload-snowflake.html
-
Unloading the Data
copy into @mystage/unload/ from mytable file_format = (format_name = 'my_csv_unload_format' compression = none);
get @mystage/unload/data_0_0_0.csv.gz file:///data/unload;
-
Managing Unloaded Data Files
** Managing Security in Snowflake
- Access Control in Snowflake
- Overview of Access Control
- Access Control Considerations
- Access Control Privileges, https://docs.snowflake.net/manuals/user-guide/security-access-control-privileges.html
- Table Privileges
** General Reference
*** Transactions
https://docs.snowflake.net/manuals/sql-reference/transactions.html
- Scope of a Snowflake Transaction
- Isolation Level
- Resource Locking
- Transaction Commands and Functions
- Aborting Transactions
*** Information Schema
https://docs.snowflake.net/manuals/sql-reference/info-schema.html
- List of Views
- FILE_FORMATS, https://docs.snowflake.net/manuals/sql-reference/info-schema/file_formats.html
- PIPES, https://docs.snowflake.net/manuals/sql-reference/info-schema/pipes.html
- STAGES, https://docs.snowflake.net/manuals/sql-reference/info-schema/stages.html
- TABLES, https://docs.snowflake.net/manuals/sql-reference/info-schema/tables.html
- List of Table Functions
- Entity Relationship Diagram (ERD) for Views
https://docs.snowflake.net/manuals/sql-reference/sql-all.html
-
SHOW TABLES, https://docs.snowflake.net/manuals/sql-reference/sql/show-tables.html
-
LIST, https://docs.snowflake.net/manuals/sql-reference/sql/list.html
-
GRANT TO ROLE, https://docs.snowflake.net/manuals/sql-reference/sql/grant-privilege.html
-
GRANT ROLE, https://docs.snowflake.net/manuals/sql-reference/sql/grant-role.html
-
CTEsm WITH, https://docs.snowflake.net/manuals/sql-reference/constructs/with.html
[
WITH
<cte_name1> [ ( <cte_column_list> ) ] AS ( SELECT ... )
[ , <cte_name2> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
[ , <cte_nameN> [ ( <cte_column_list> ) ] AS ( SELECT ... ) ]
]
SELECT ...
- All Functions, https://docs.snowflake.net/manuals/sql-reference/functions-all.html
- COALESCE: Returns the first non-NULL expression among its arguments, or NULL if all its arguments are NULL.
- GET_DDL, https://docs.snowflake.net/manuals/sql-reference/functions/get_ddl.html
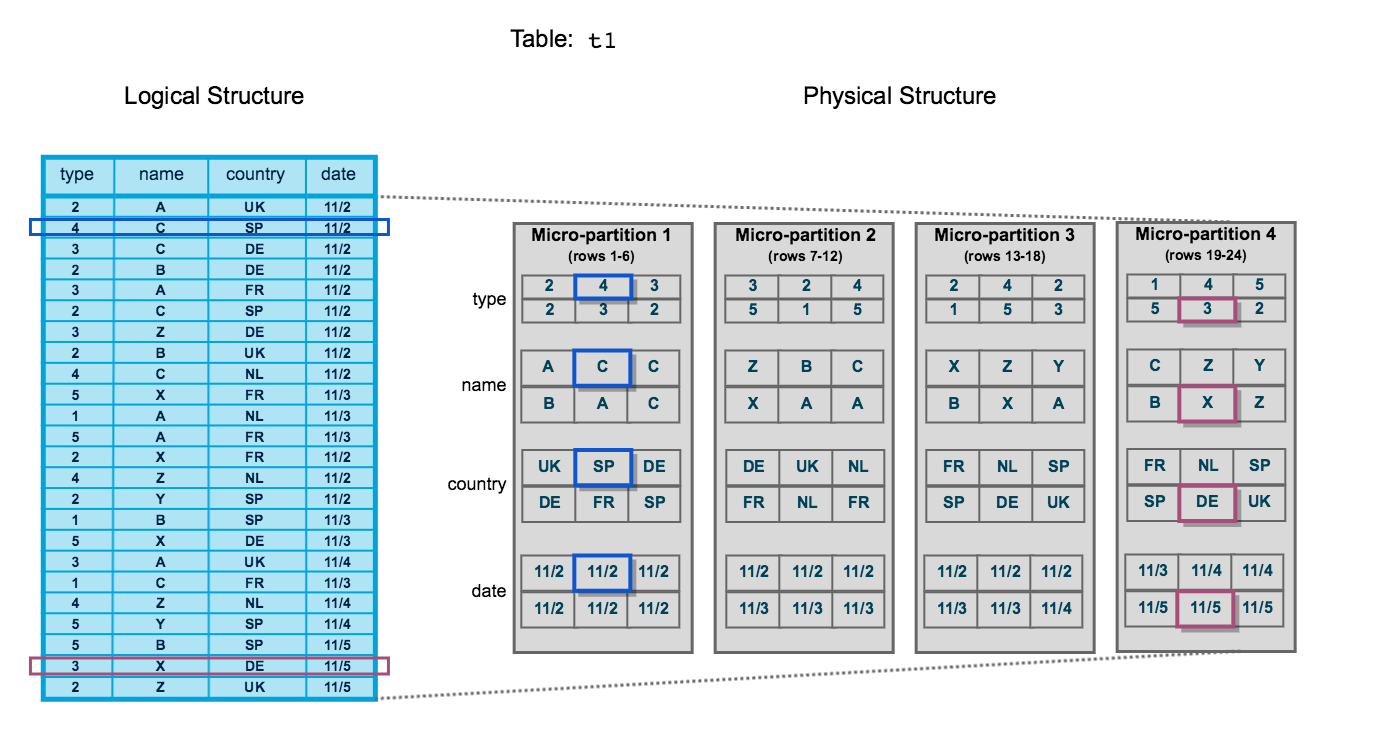
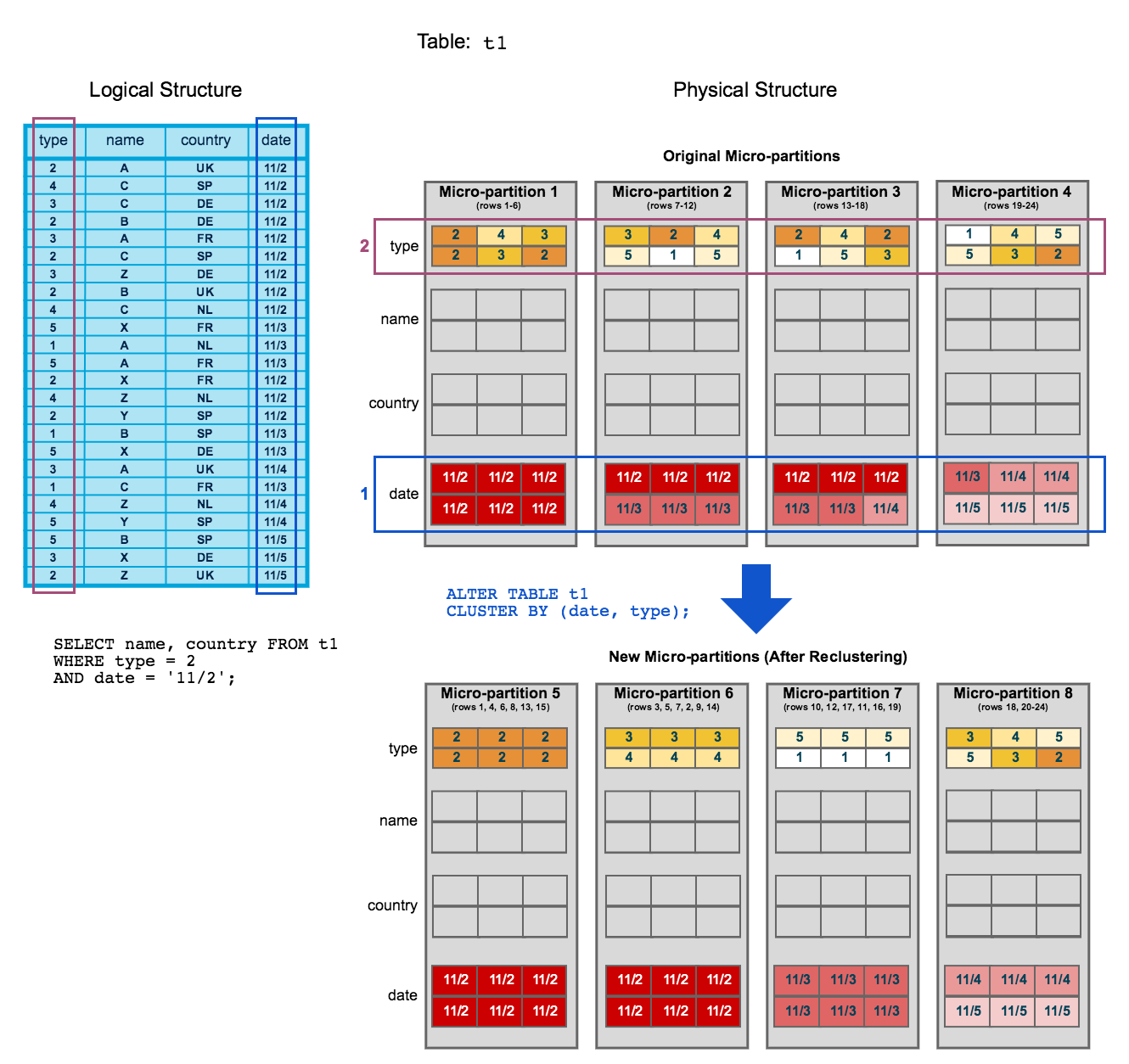
- SYSTEM$CLUSTERING_INFORMATION, https://docs.snowflake.net/manuals/sql-reference/functions/system_clustering_information.html
"partition_depth_histogram" : {
"08192" : 1606, // there are 1606 partitions with 8192 keys inside this partition "16384" : 24698 // there are 24698 partitions with 16384 keys inside this partition } The quick way to assess the actual clustering is via the “average depth”… in a well-clustered table this is often <= 10.
Good example will be: "average_depth" : 21.8698, "partition_depth_histogram" : { "00000" : 0, "00001" : 13849, // there are 13849 partitions with 1 keys inside this partition ...
-
Overview of Stored Procedures, https://docs.snowflake.net/manuals/sql-reference/stored-procedures-overview.html
-
View Predicate Pushdown & Parametric View, https://support.snowflake.net/s/question/0D50Z00007jREDpSAO/view-predicate-pushdown-parametric-view
When you query a view like the one you defined above, predicates get pushed down to the individual tables, and in addition only necessary columns (ones referenced by the query) are retrieved. So the view is never fully materialized.