|
#!/usr/bin/env python3 |
|
# Check Twitch.tv live streams |
|
# Written by Yu-Jie Lin |
|
# WTFPL Version 2, see COPYING |
|
|
|
import argparse |
|
import json |
|
import os |
|
import re |
|
import sys |
|
import time |
|
from datetime import datetime |
|
from textwrap import fill |
|
from urllib import request |
|
from urllib.parse import quote_plus |
|
|
|
import pytz |
|
from dateutil.parser import parse |
|
from dateutil.tz import tzlocal |
|
|
|
__description__ = 'Check Twitch.tv live streams' |
|
|
|
# Twitch API GET /streams http://git.io/Z2ZRqQ |
|
API_BASE = 'https://api.twitch.tv/kraken/streams' |
|
|
|
INDENT_SIZE = 4 |
|
INDENT = ' ' * INDENT_SIZE |
|
FMT = ( |
|
'\033[1;32m{name:{lens[name]}}\033[0m ' |
|
'\033[1;31m{viewers_str:>{lens[viewers_str]}}\033[0m ' |
|
'\033[1;33m{up_time_since:>{lens[up_time_since]}}\033[0m{PAD_C1} ' |
|
'{up_time}\n' |
|
|
|
'{url:{lens[url]}}{PAD_url} ' |
|
'\033[1;34m{game}\033[0m\n' |
|
|
|
'\n' |
|
|
|
'{wrapped_status}\n' |
|
) |
|
FMT_ONE = ( |
|
'http://{url_one}/\033[1;32m{name_one:{lens[name]}}\033[0m ' |
|
'\033[1;31m{viewers_str:>{lens[viewers_str]}}\033[0m ' |
|
'\033[1;33m{up_time_since:>{lens[up_time_since]}}\033[0m ' |
|
'{status_one}' |
|
) |
|
FMT_TIME = '{h:d}h {m:2d}m {s:2d}s' |
|
FMT_TIME_ONE = '{h:d}:{m:02d}:{s:02d}' |
|
RE_WHITESPACES = re.compile(r'\s{2,}') |
|
|
|
|
|
def relative_time(d, FMT='{h:2d}h {m:2d}m {s:2d}s'): |
|
|
|
t = abs(d.seconds if hasattr(d, 'seconds') else int(d)) |
|
s = t % 60 |
|
m = t // 60 % 60 |
|
h = t // 3600 + (d.days if hasattr(d, 'days') else 0) * 24 |
|
|
|
return FMT.format(**locals()) |
|
|
|
|
|
def extract_stream(stream): |
|
|
|
channel = stream['channel'] |
|
|
|
stream['name'] = channel['display_name'] |
|
stream['status'] = channel['status'].strip() |
|
stream['url'] = channel['url'] |
|
stream['viewers_str'] = '{:,}'.format(stream['viewers']) |
|
|
|
return stream['name'], stream |
|
|
|
|
|
def main(): |
|
|
|
parser = argparse.ArgumentParser(description=__description__) |
|
parser.add_argument('-m', '--monitor', default=0, type=int, metavar='MON', |
|
help=('monitoring mode, run constantly ' |
|
'(Default %(default)s)')) |
|
parser.add_argument('-1', '--one', action='store_true', |
|
help='one stream per line') |
|
parser.add_argument('-g', '--game', action='store_true', |
|
help=('search by game, CHANNEL arguments would be ' |
|
'treated as name of game')) |
|
parser.add_argument('-l', '--limit', default=25, type=int, |
|
help='maximum number of streams (Default: %(default)s)') |
|
parser.add_argument('-o', '--offset', default=0, type=int, |
|
help='offset of first stream (Default: %(default)s)') |
|
parser.add_argument('-s', '--sort', |
|
help='sorting key (Default: None; viewers if --game') |
|
parser.add_argument('-r', '--reverse', default='default', |
|
choices=('default', 'true', 'false'), |
|
help=('sort in reverse order ' |
|
'(Default: false; true if --game)')) |
|
parser.add_argument('channels', metavar='CHANNEL', nargs='+', |
|
help='channel ID or URL, or game if --game is used') |
|
args = parser.parse_args() |
|
|
|
if args.game: |
|
URL = API_BASE + '?game=' + quote_plus(' '.join(args.channels)) |
|
if args.sort is None: |
|
args.sort = 'viewers' |
|
else: |
|
m = map(lambda ch: ch.rsplit('/', 1)[-1].lower(), args.channels) |
|
URL = API_BASE + '?channel=' + ','.join(m) |
|
URL += '&limit=%d&offset=%d' % (args.limit, args.offset) |
|
|
|
args.reverse = (args.game if args.reverse == 'default' else |
|
args.reverse == 'true') |
|
|
|
if not args.monitor: |
|
streams = get_live_streams(args, URL) |
|
if not streams: |
|
return os.EX_UNAVAILABLE |
|
show_streams(args, streams) |
|
else: |
|
try: |
|
monitor(args, URL) |
|
except KeyboardInterrupt: |
|
print() |
|
|
|
return os.EX_OK |
|
|
|
|
|
def monitor(args, URL): |
|
|
|
old_streams = {} |
|
k_old_streams = set(old_streams.keys()) |
|
|
|
while True: |
|
t = time.asctime(time.localtime()) |
|
streams = get_live_streams(args, URL) |
|
k_streams = set(streams.keys()) |
|
|
|
new_streams = {k: streams[k] for k in k_streams - k_old_streams} |
|
off_streams = {k: old_streams[k] for k in k_old_streams - k_streams} |
|
upd_streams = { |
|
key: streams[key] |
|
for key in k_streams & k_old_streams |
|
if streams[key]['status'] != old_streams[key]['status'] or |
|
streams[key]['game'] != old_streams[key]['game'] |
|
} |
|
|
|
TPL_MSG = '\033[1;%%dm=== %%s at %s ===\033[0m' % t |
|
monitor_list_streams(args, new_streams, TPL_MSG % (32, 'Online')) |
|
monitor_list_streams(args, off_streams, TPL_MSG % (31, 'Offline')) |
|
monitor_list_streams(args, upd_streams, TPL_MSG % (33, 'Updated')) |
|
print() |
|
|
|
old_streams = streams |
|
k_old_streams = k_streams |
|
|
|
msg = ('\033[2K\033[1A\033[2K\033[1G' |
|
'%s: %d lives\n' |
|
'%s: next check in %s') |
|
c = time.time() + args.monitor |
|
n = time.asctime(time.localtime(c)) |
|
lives = len(streams) |
|
while time.time() <= c: |
|
print(msg % (t, lives, n, relative_time(c - time.time())), end='') |
|
sys.stdout.flush() |
|
time.sleep(1) |
|
print('\033[2K\033[1A\033[2K\033[1G', end='') |
|
|
|
|
|
def monitor_list_streams(args, streams, msg): |
|
|
|
if not streams: |
|
return |
|
|
|
print(msg, end='\n' if args.one else '\n\n') |
|
show_streams(args, streams) |
|
|
|
|
|
def get_live_streams(args, URL): |
|
|
|
with request.urlopen(URL) as f: |
|
data = json.loads(f.read().decode('utf8')) |
|
streams = data['streams'] |
|
streams = filter(lambda stream: 'url' in stream['channel'], streams) |
|
streams = dict(map(extract_stream, streams)) |
|
|
|
for stream in streams.values(): |
|
if not args.one: |
|
stream['wrapped_status'] = fill( |
|
text=stream['status'], |
|
width=72, |
|
initial_indent=INDENT, |
|
subsequent_indent=INDENT, |
|
) |
|
else: |
|
stream['name_one'] = stream['name'].replace(' ', '_') |
|
stream['status_one'] = RE_WHITESPACES.sub(' ', stream['status']) |
|
|
|
up_time = parse(stream['created_at']) |
|
up_time = up_time.astimezone(tzlocal()) |
|
d = datetime.utcnow().replace(tzinfo=pytz.utc) - up_time |
|
d = relative_time(d, FMT=FMT_TIME_ONE if args.one else FMT_TIME) |
|
|
|
stream['up_time'] = up_time |
|
stream['up_time_since'] = d |
|
|
|
return streams |
|
|
|
|
|
def show_streams(args, streams): |
|
|
|
get_len = lambda key: max(len(s[key]) for s in streams.values()) |
|
keys = ('viewers_str', 'name', 'url', 'up_time_since') |
|
lens = dict((key, get_len(key)) for key in keys) |
|
if not args.one: |
|
lens['C1'] = lens['name'] + 2 + lens['viewers_str'] + 2 |
|
lens['C1'] += lens['up_time_since'] |
|
lens['LEFT_COLUMN'] = max(lens['url'], lens['C1']) |
|
|
|
streams = list(streams.values()) |
|
if args.sort: |
|
streams.sort(key=lambda stream: stream[args.sort], reverse=args.reverse) |
|
|
|
for stream in streams: |
|
if args.one: |
|
print(FMT_ONE.format( |
|
lens=lens, |
|
url_one=stream['url'].split('/')[2].replace('www.', ''), |
|
**stream |
|
)) |
|
else: |
|
PAD_C1 = ' ' * (lens['LEFT_COLUMN'] - lens['C1']) |
|
PAD_url = ' ' * (lens['LEFT_COLUMN'] - lens['url']) |
|
print(FMT.format(lens=lens, PAD_C1=PAD_C1, PAD_url=PAD_url, **stream)) |
|
|
|
|
|
if __name__ == '__main__': |
|
sys.exit(main()) |
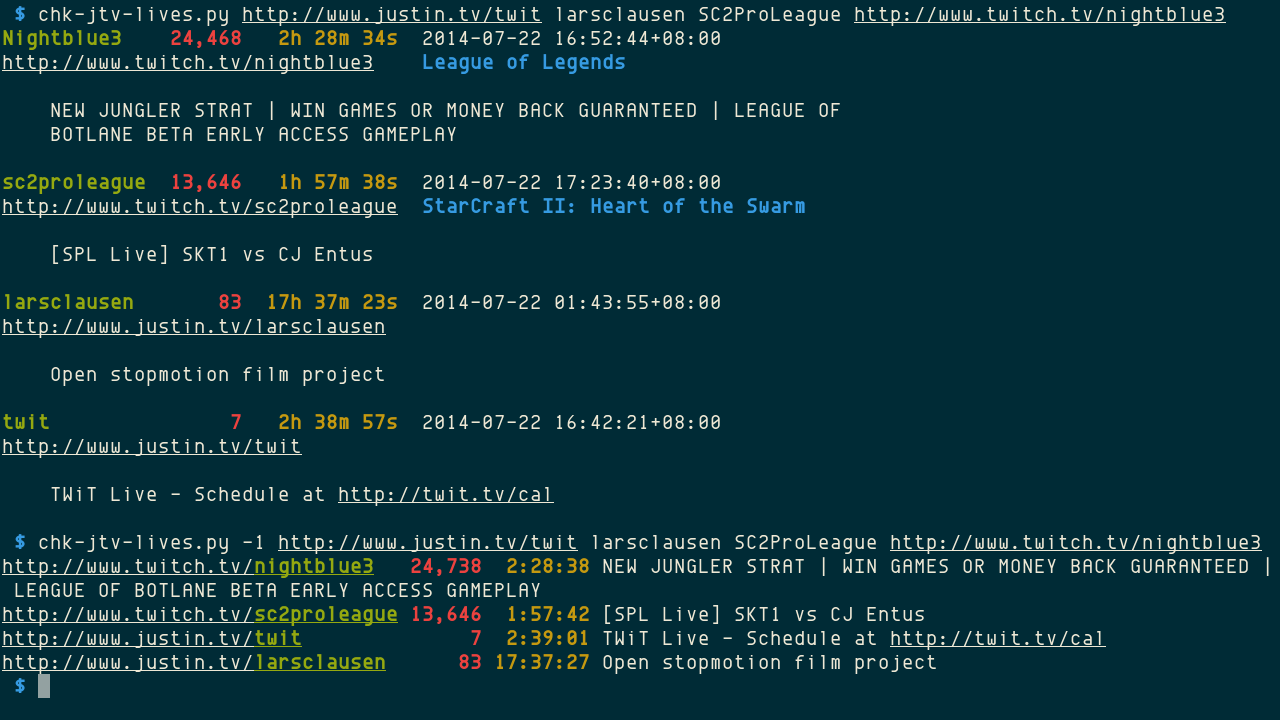
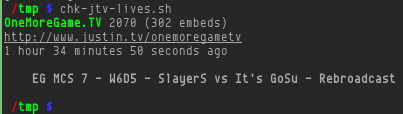




{kind=link}
{kind=link}
{kind=link}
Sorry, you'll have to find someone to do it. Please do share a link if you get a solution.