# Enable emulation for cross-platform images
sudo apt-get install -y binfmt-support qemu-user-static
# Enable cross-build commands in docker
docker buildx create --use
Lyle Franklin ljfranklin
ljfranklin
/ build-glibc-alpine-arm64.md
Last active
April 4, 2024 10:24
Steps to build glibc for alpine ARM64
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # Start ethernet | |
| usb start | |
| # U-Boot Parameters | |
| setenv initrd_high "0xffffffff" | |
| setenv fdt_high "0xffffffff" | |
| # Mac address configuration | |
| setenv macaddr "00:1e:06:61:7a:39" |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| DEBUG='embedded,' \ | |
| DEBUG+='netdevice,' \ | |
| DEBUG+='netdev_settings,' \ | |
| DEBUG+='image,' \ | |
| DEBUG+='dhcp,' \ | |
| DEBUG+='efi_acpi,' \ | |
| DEBUG+='efi_autoboot,' \ | |
| DEBUG+='efi_block,' \ | |
| DEBUG+='efi_bofm,' \ | |
| DEBUG+='efi_debug,' \ |
Install snapserver/snapclient.
Create /etc/systemd/system/snapfifo.service with contents:
[Unit]
Description=Pipes line-in to /tmp/snapfifo pipe
After=snapserver.service
[Service]
- Download OS: http://www.orangepi.org/downloadresources/orangepizero/2017-05-05/orangepizero_e7c74a532b47c34968b5098.html
- Extract once:
unrar x Raspbian_server_For_zero_H2+_V0_1.rar - Extract again:
unxz < Raspbian_server_For_zero_H2+_V0_1.img.xz > Raspbian_server_For_zero_H2+_V0_1.img - Copy OS onto SD card:
sudo dd^Cs=4M if=Raspbian_server_For_zero_H2+_V0_1.img of=/dev/sda conv=fsync- Ensure disk is unmounted
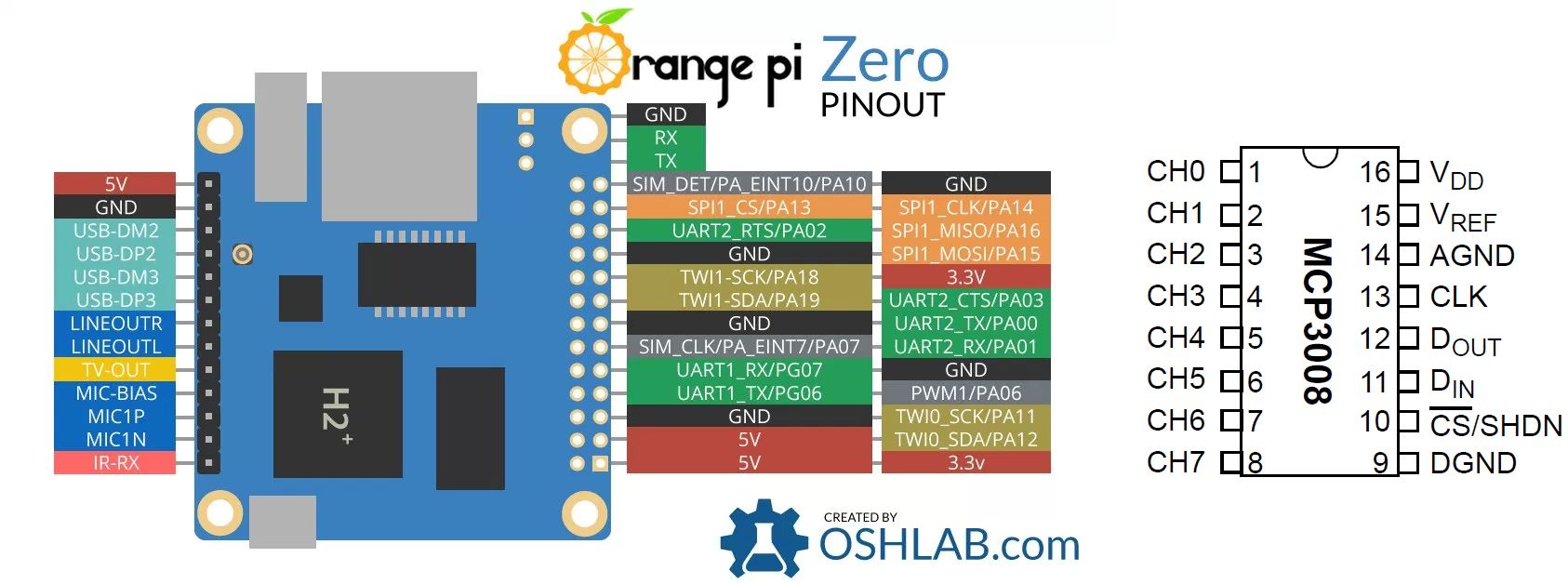
- Pinout: https://forum.armbian.com/uploads/monthly_2017_03/orangepizeromcp3008.jpg.7cffc0474b56f40ef1d64f39a57ea5c2.jpg
- Connect USB-to-TTL cable
- Note: TX should connect to RX on board, RX to TX on board, ground connected but 5v and 3.3V are unconnected
- Connect over TTL:
sudo screen /dev/ttyUSB0 115200 - Power on board
ljfranklin
/ k8s-pi.md
Created
January 7, 2019 00:42

{kind=link}
(Gopher image by Ashley McNamara)
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Instance control/7eb695e4-cfb6-47ab-bbe2-8d77cd299e18 | |
| Exit Code 1 | |
| Stdout Running smoke tests... | |
| Running binaries smoke/isolation_segments/isolation_segments.test | |
| smoke/logging/logging.test | |
| smoke/runtime/runtime.test | |
| [1544651752] CF-Isolation-Segment-Smoke-Tests - 4 specs - 4 nodes | |
| ------------------------------ | |
| [2018-12-12 21:55:52.75 (UTC)]> cf api https://api.sys.pale-talon.gcp.releng.cf-app.com |
ljfranklin
/ arch-install.md
Last active
November 16, 2021 18:38
Bootstrapping an Arch Linux installation
- Download arch ISO from https://www.archlinux.org/download/
- Copy the ISO to the USB drive:
- From a Linux machine:
# replace sdX with usb drive listed by `fdisk -l`,
ljfranklin
/ add_key
Last active
December 18, 2017 00:10
Script for OSX and Linux to add an SSH key and eject the disk
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #!/usr/bin/env bash | |
| set -e | |
| HOURS=$1 | |
| green='\033[32m' | |
| yellow='\033[33m' | |
| nc='\033[0m' |
ljfranklin
/ mysql_docker_sadness.md
Last active
August 2, 2017 22:57
Repro steps: MySQL service won't start in docker unless I touch all its files...
Docker version affected:
- ERROR: Docker version 17.06.0-ce on OSX host
- ERROR: Concourse CI container (Linux based executing with runC)
- OK: Docker version 17.06.0-ce on Ubuntu 16.04 host
Dockerfile:
FROM debian:jessie
NewerOlder