Github repo for the Course: Stanford Machine Learning (Coursera)
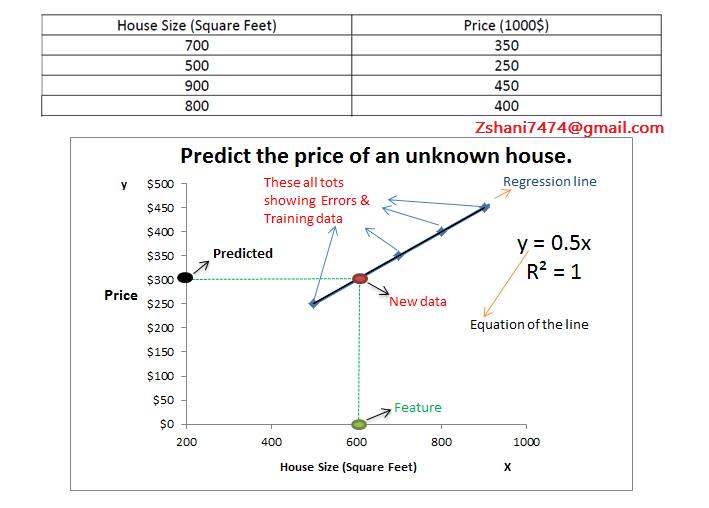
Consider the problem of predicting how well a student does in her second year of college/university, given how well she did in her first year.
Specifically, let x be equal to the number of "A" grades (including A-. A and A+ grades) that a student receives in their first year of college (freshmen year). We would like to predict the value of y, which we define as the number of "A" grades they get in their second year (sophomore year).
Here each row is one training example. Recall that in linear regression, our hypothesis is hθ(x)=θ0+θ1x, and we use m to denote the number of training examples.
| x | y |
|---|---|
| 5 | 4 |
| 3 | 4 |
| 0 | 1 |
| 4 | 3 |
For the training set given above (note that this training set may also be referenced in other questions in this quiz), what is the value of m? In the box below, please enter your answer (which should be a number between 0 and 10).
Answer:
4
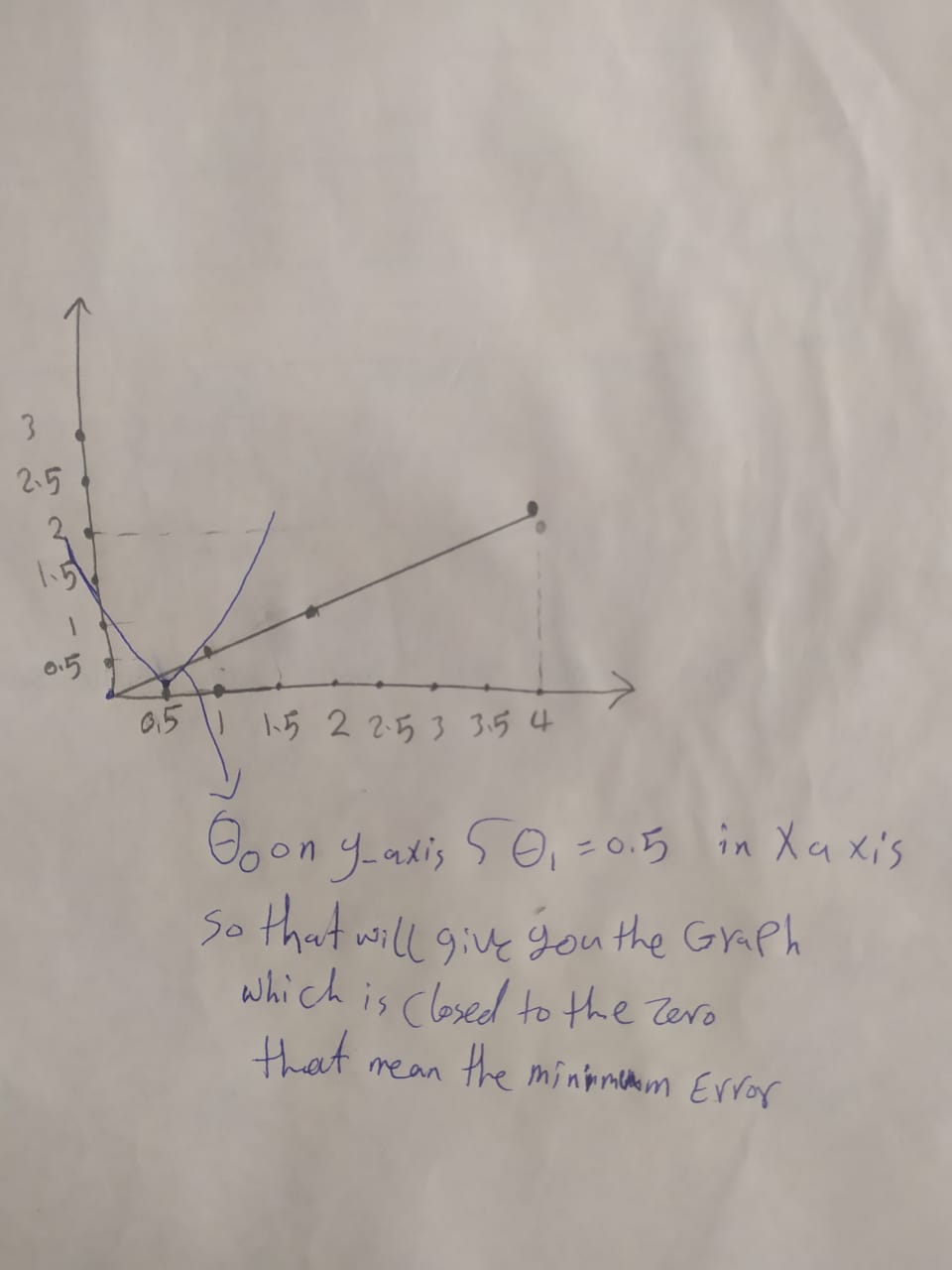
Consider the following training set of m=4 training examples:
| x | y |
|---|---|
| 1 | 0.5 |
| 2 | 1 |
| 4 | 2 |
| 0 | 0 |
Consider the linear regression model hθ(x)=θ0+θ1x. What are the values of θ0 and θ1 that you would expect to obtain upon running gradient descent on this model? (Linear regression will be able to fit this data perfectly.)
-
θ0=0.5,θ1=0
-
θ0=0.5,θ1=0.5
-
θ0=1,θ1=0.5
-
θ0=0,θ1=0.5
-
θ0=1,θ1=1
Answer:
θ0=0,θ1=0.5
As J(θ0,θ1)=0, y = hθ(x) = θ0 + θ1x. Using any two values in the table, solve for θ0, θ1.
If you don't know how to do this, please see the following video: Solving system of linear equations
Suppose we set θ0=−1,θ1=0.5. What is hθ(4)?
Answer:
Setting x = 4, we have hθ(x)=θ0+θ1x = -1 + (0.5)(4) = 1
Let f be some function so that
f(θ0,θ1) outputs a number. For this problem,
f is some arbitrary/unknown smooth function (not necessarily the
cost function of linear regression, so f may have local optima).
Suppose we use gradient descent to try to minimize f(θ0,θ1) as a function of θ0 and θ1. Which of the
following statements are true? (Check all that apply.)
-
Even if the learning rate α is very large, every iteration of gradient descent will decrease the value of f(θ0,θ1).
-
If the learning rate is too small, then gradient descent may take a very long time to converge.
-
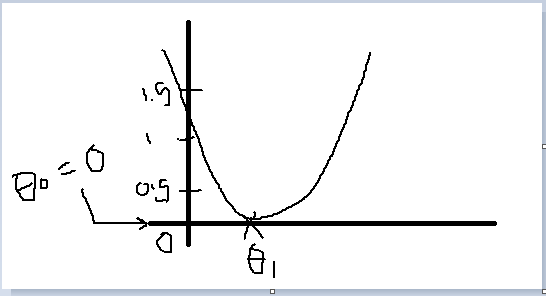
If θ0 and θ1 are initialized at a local minimum, then one iteration will not change their values.
-
If θ0 and θ1 are initialized so that θ0=θ1, then by symmetry (because we do simultaneous updates to the two parameters), after one iteration of gradient descent, we will still have θ0=θ1.
Answers:
| True or False | Statement | Explanation |
|---|---|---|
| True | If the learning rate is too small, then gradient descent may take a very long time to converge. | If the learning rate is small, gradient descent ends up taking an extremely small step on each iteration, and therefor can take a long time to converge |
| True | If θ0 and θ1 are initialized at a local minimum, then one iteration will not change their values. | At a local minimum, the derivative (gradient) is zero, so gradient descent will not change the parameters. |
| False | Even if the learning rate α is very large, every iteration of gradient descent will decrease the value of f(θ0,θ1). | If the learning rate is too large, one step of gradient descent can actually vastly "overshoot" and actually increase the value of f(θ0,θ1). |
| False | If θ0 and θ1 are initialized so that θ0=θ1, then by symmetry (because we do simultaneous updates to the two parameters), after one iteration of gradient descent, we will still have θ0=θ1. | The updates to θ0 and θ1 are different (even though we're doing simulaneous updates), so there's no particular reason to update them to be same after one iteration of gradient descent. |
Other Options:
| True or False | Statement | Explanation |
|---|---|---|
| True | If the first few iterations of gradient descent cause f(θ0,θ1) to increase rather than decrease, then the most likely cause is that we have set the learning rate to too large a value | if alpha were small enough, then gradient descent should always successfully take a tiny small downhill and decrease f(θ0,θ1) at least a little bit. If gradient descent instead increases the objective value, that means alpha is too large (or you have a bug in your code!). |
| False | No matter how θ0 and θ1 are initialized, so long as learning rate is sufficiently small, we can safely expect gradient descent to converge to the same solution | This is not true, depending on the initial condition, gradient descent may end up at different local optima. |
| False | Setting the learning rate to be very small is not harmful, and can only speed up the convergence of gradient descent. | If the learning rate is small, gradient descent ends up taking an extremely small step on each iteration, so this would actually slow down (rather than speed up) the convergence of the algorithm. |
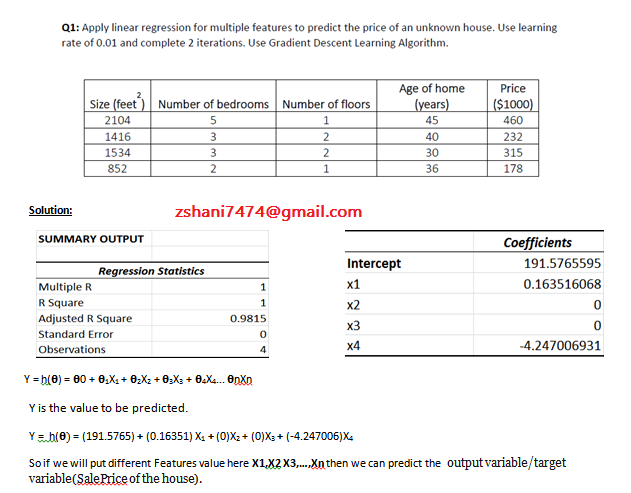
Suppose that for some linear regression problem (say, predicting housing prices as in the lecture), we have some training set, and for our training set we managed to find some θ0, θ1 such that J(θ0,θ1)=0.
Which of the statements below must then be true? (Check all that apply.)
-
For this to be true, we must have y(i)=0 for every value of i=1,2,…,m.
-
Gradient descent is likely to get stuck at a local minimum and fail to find the global minimum.
-
For this to be true, we must have θ0=0 and θ1=0 so that hθ(x)=0
-
Our training set can be fit perfectly by a straight line, i.e., all of our training examples lie perfectly on some straight line.
Answers:
| True or False | Statement | Explanation |
|---|---|---|
| False | For this to be true, we must have y(i)=0 for every value of i=1,2,…,m. | So long as all of our training examples lie on a straight line, we will be able to find θ0 and θ1) so that J(θ0,θ1)=0. It is not necessary that y(i) for all our examples. |
| False | Gradient descent is likely to get stuck at a local minimum and fail to find the global minimum. | none |
| False | For this to be true, we must have θ0=0 and θ1=0 so that hθ(x)=0 | If J(θ0,θ1)=0 that means the line defined by the equation "y = θ0 + θ1x" perfectly fits all of our data. There's no particular reason to expect that the values of θ0 and θ1 that achieve this are both 0 (unless y(i)=0 for all of our training examples). |
| True | Our training set can be fit perfectly by a straight line, i.e., all of our training examples lie perfectly on some straight line. | None |
Other Options:
| True or False | Statement | Explanation |
|---|---|---|
| False | We can perfectly predict the value of y even for new examples that we have not yet seen. (e.g., we can perfectly predict prices of even new houses that we have not yet seen.) | None |
| False | This is not possible: By the definition of J(θ0,θ1), it is not possible for there to exist θ0 and θ1 so that J(θ0,θ1)=0 | None |
| True | For these values of θ0 and θ1 that satisfy J(θ0,θ1)=0, we have that hθ(x(i))=y(i) for every training example (x(i),y(i)) | None |








A good description of machine learning for student assessment. I think that it may be even more useful to include information about writing an essay. Very useful information for adapting the learning process. In my class, for example, few people knew how to write essays and used the site https://gradesfixer.com/free-essay-examples/literature/ where I could find texts on different topics to solve problems in my studies. A site with a large database of free examples of essays on literature. I hope that it will be possible to expand this database and make many additions, which relate to personal indicators of subjects with links to errors.