(これは https://github.com/dotnet/coreclr/blob/master/Documentation/design-docs/GuardedDevirtualization.md の日本語訳です。対象rev.は 045f470)
ガード付き脱最適化は、.NET Core 3.0のJITの新しい最適化手法です。 このドキュメントでは、動機と初期の設計スケッチについて説明し、さらに調査が必要なさまざまな問題のハイライトを紹介します。
.NET CoreのJIT(訳注:以下、単に「JIT」と書いたときには.NET CoreのJITを指します)は、仮想呼び出しとインターフェース呼び出しに対して、限られた量の脱仮想化を実行できます。
この機能は.NET Core 2.0で追加されました。
脱仮想化をするには、JITが次の2つのいずれかを示すことができなければなりません。
それは、(newobj命令が確認できたなどの理由で)参照の正確な型を知っているか、参照の型がfinal(別名sealed)クラスとして宣言されていることを知っているか、どちらかです。
仮想呼び出しについては、メソッドがfinalとしてマークされていることをJITが証明できる場合にも、脱仮想化ができます。
しかし、ほとんどの場合、JITは正確な型や非仮想であることを判定できず、したがって、脱仮想化は失敗します。 統計によると、現時点では仮想コールサイトの約15%しか脱仮想化できません。 インターフェース呼び出しでの結果はさらに悲観的で、成功率は約5%です。
これにはさまざまな理由があります。 まず、JIT分析があまり強力ではありません。 JITは歴史的に、ある場所が参照型を なにか1つでも 保持しているかどうかしか関心を払っておらず、それが特定の参照型かどうかは見ていませんでした。 したがって、現在の型伝播は後から追加されたものなので、型がただ失われる場所も存在します。 また、JIT分析は非常に早く(型のインポート時に)行われるため、この段階でデータフロー分析を実行することはほとんどできません。 したがって、現在の脱仮想化のためには、型情報の出所と利用側がコード内でかなり接近していなければなりません。 このような欠点のいくつかについては、CoreCLR#9908に詳細な説明があります。
これらの問題を解決すればJITの脱仮想化能力を向上させることができますが、 可能な限り最善の分析をしたとしても、なお脱仮想化できないケースが数多くあります。 真に多相的なコールサイトもその一つです。他には、真に単相的なコールサイトにもかかわらず、 そのことを示すには複数の処理をまたぐ洗練された解析が必要となるものもあります。 CLRのJITや、それと同程度に動的なシステムでそのような解析を行うことは実用的ではありません。 さらに、実質的には単相的だけれども、潜在的には多相的だというコールサイトもあります。
脱仮想化が失敗する時は、代替案としてJITは ガード付き脱仮想化 を実行することができます。
その時は、JITが仮想呼び出しまたはインターフェース呼び出しの場所に if-then-else ブロックのセットを作成し、
実行時の型テスト(のようなもの)を if 文の中、つまり、「ガード」部分に挿入します。
ガード・テストが成功する場合、JITには参照の型が認識できているので、 then ブロックでその型に対応するメソッドを直接呼び出すことができます。
テストが失敗する場合、 else ブロックが実行されます。ここには元の仮想呼び出しまたはインタフェース呼び出しが含まれています。
結果としてJITは、コードサイズの増加、JIT時間の増加、呼び出しにまつわるコードパスのわずかな延長を引き換えにして、 条件付きで脱仮想化の利点を得ることができます。 型に関するJITの推測がある程度妥当である限り、この最適化はパフォーマンスを向上させることができます。
脱仮想化が効果を上げるためには、参照の型に関するJITの推測精度がかなり良くないといけないと予想する人もいるかもしれません。 いくぶん驚くべきことに、少なくとも初期調査の結果によれば、その必要はありません。
次のクラスが宣言されているとします。
class B
{
public virtual int F() { return 33; }
}
class D : B
{
public override int F() { return 44; }
}配列 B[] があり、その中に B と D のインスタンスがランダムに格納されていて、要素が B クラスである確率が p だとします。
配列の全要素に対して F を呼び出すのにかかる時間を計測し(JITはこれらの呼び出しを脱仮想化できないことに注意してください)、
その時間をpの関数としてプロットします。
結果は次のようになります。
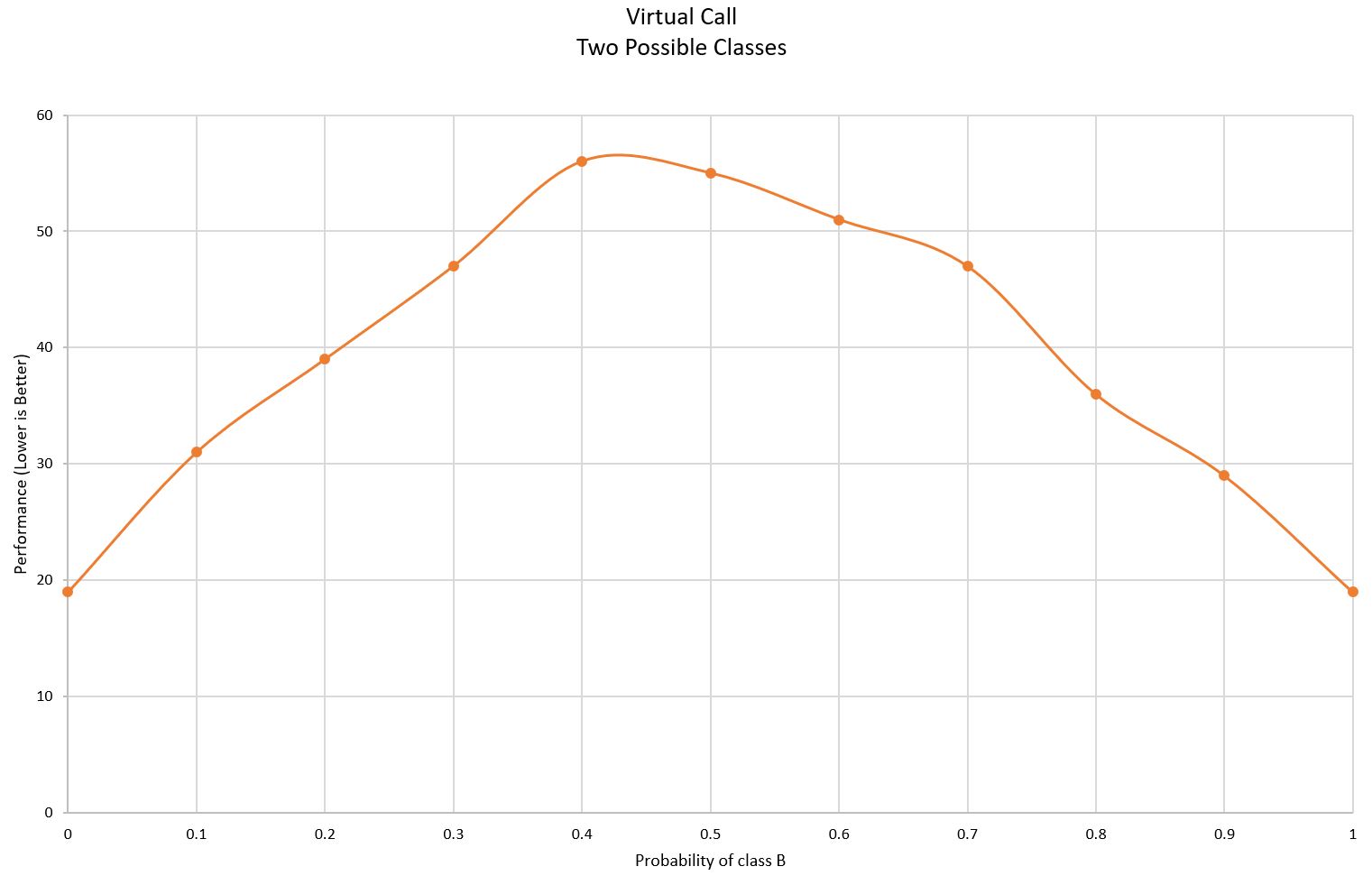
現代のハードウェアには間接分岐先予測子が含まれており、その実際の動作はこの結果からも確認できます。
配列要素の型が予測可能な( p がゼロに近いか、1に近い)場合、パフォーマンスが向上します。
要素の型が予測不能な( p が0.5に近い)場合、パフォーマンスはかなり悪くなります。
この結果から、予測が正しかった仮想呼出しには約19単位時間がかかり、ワーストケースの誤予測では約55単位時間がかかることがわかります。 ただこれには時間を計測するオーバーヘッドもいくらか乗っているので、実際のコストはもう少し低いものです。
ここで、ガード付き脱仮想化を行い、配列の要素が実際に型 B かどうかを確認するようにJITを更新したと想像してください。
そうすれば、JITは B.F を直接呼び出すことができますし、プロトタイプではJITが呼び出しをインライン化もします。
したがって、要素の型が ほぼ B の(p が1.0に近い)場合は非常に優れたパフォーマンスが得られ、
要素の型がほぼ D の(p が0.0に近い)場合、呼び出し前にチェックを実行する余分なコードが追加されるため、
おそらく最適化されていないケースよりパフォーマンスは多少悪化するはずです。
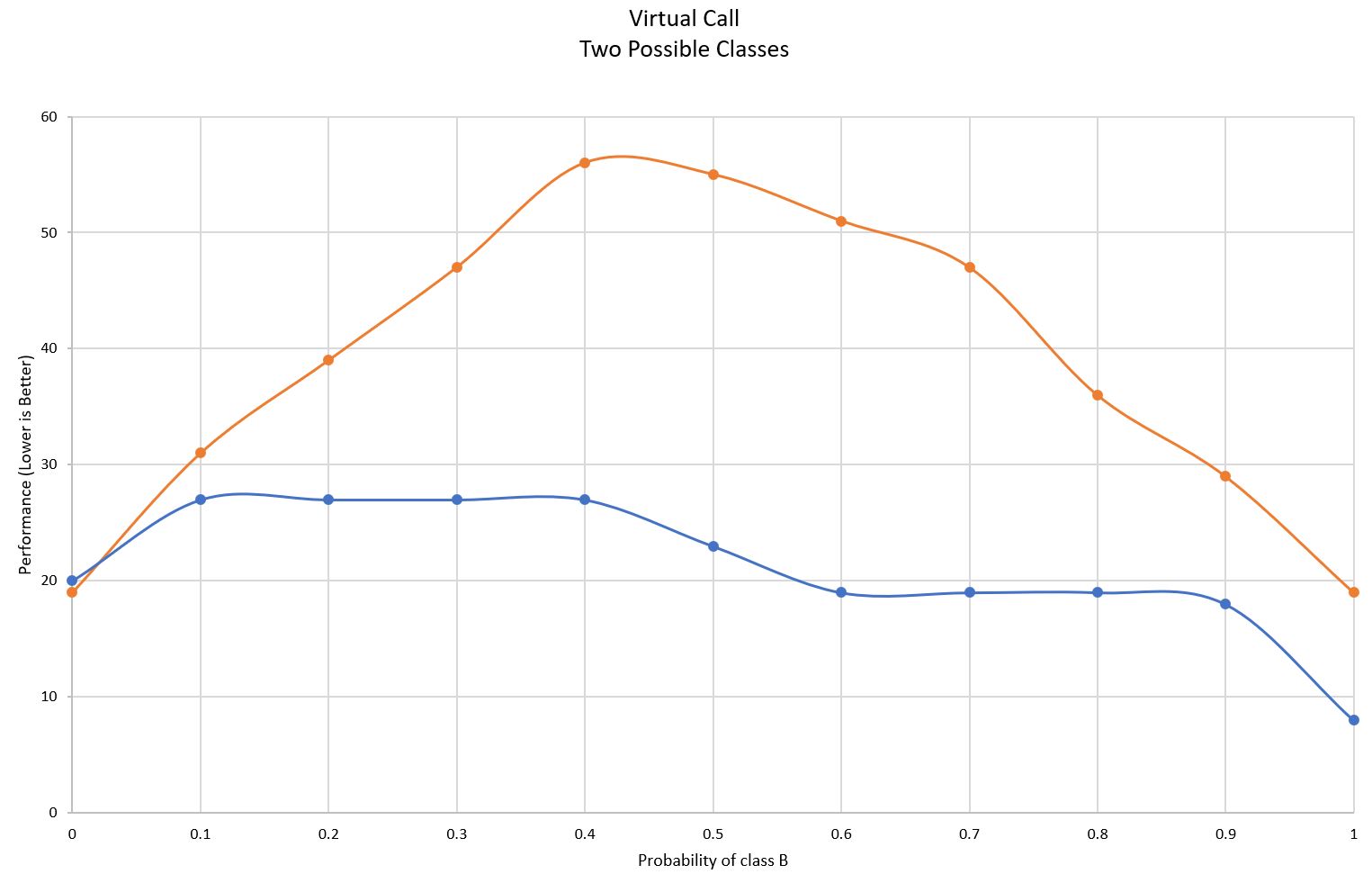
しかし、脱仮想化が行われたケース(青い線)のパフォーマンスは、 p のすべての値において最適化されていないケースと同程度かそれ以上です。
これはおそらく予想外のことで、何らかの説明が必要でしょう。
最新のハードウェアには分岐予測子も含まれていることを思い出しましょう。
p が小さいかまたは大きな値の場合、この予測子は、JITによって追加されたテストが then または else のどちらに解決されるかを正確に推測します。
p の値が小さい場合、JITの推測は間違いで、制御は elseブロックに流れることになるでしょう。
しかし、元の例とは異なり、ここでの間接呼び出しは型Dのインスタンスのみを扱うことになるため、間接分岐予測子が非常にうまく動作します。
したがって、p が小さい場合のオーバーヘッドは、ガード付き脱仮想化がなかった場合の間接呼び出しのものと同等です。
p が増加すると、分岐予測子は誤予測(訳注:pが0.5より小さい間は、分岐予測器はelseの実行パスを予測している)をし始めるので、
処理サイクルが少し増えることになります。
しかし、誤予測が起きた時は、制御フローがthenブロックに到達し、呼び出しがインライン化されます。
したがって、誤予測のコストは実行の高速化によって相殺され、コストはそれほど変動しません。
p が0.5を超えると、分岐予測器はその予測を反転してthenのケースを優先し始めます。
それまでと同じく誤予測にはコストがかかり、elseの実行パスに落ちることになりますが、そこでは引き続き正しく予測された間接呼び出しが実行されます。
そして、p が1.0に近づくにつれて、分岐予測子がほぼ正しくなるためコストが下がります。
したがって、コストは単にインライン化された呼び出しのものになります。
面白いことに、ここに示したガード付き脱仮想化のケースは、パフォーマンスのトレードオフを何も必要としていません。 JITがより可能性の高いケースを推測していたほうがもちろんよいのですが、 たとえそうでないケースを推測しても相殺されるため、パフォーマンスを犠牲にすることはありません。
とはいえこの結果だけでは、クラスが2種類の場合は特殊ケースであり、もっと複雑な場合はこうはならないだろうと疑う人もいるでしょう。 他の場合はこのあと扱います。
先に進む前に、現在のCLRの仮想呼び出しはC++よりも少し高くつくことを指摘しておきます。 それは、CLRは2段階のメソッドテーブルを使用しているからです。 つまり、間接呼び出しのシーケンスは次のようなものです。
000095 mov rax, qword ptr [rcx] ; fetch method table
000098 mov rax, qword ptr [rax+72] ; fetch proper chunk
00009C call qword ptr [rax+32]B:F():int:this ; call indirectこれは依存読み込みが3連鎖しているので、ベストケースであっても少なくとも最良のキャッシュレイテンシーの3倍(それに加えて間接予測のオーバーヘッド)が必要になります。
そのため、CLRの仮想呼び出しのコストは高くなります。 チャンク化されたメソッドテーブルの設計は、パフォーマンスを犠牲にしてスペースを節約する(チャンクは異なるクラスで共用できます)ために採用されました。 このため、ガード付きの脱仮想化が、予想されるよりも広い範囲のクラスにわたって効果を発揮することは明らかです。
そして完全を期すため、上で測定されたガード付き if-then-else のシーケンス全体は次のとおりです。
00007A mov rcx, gword ptr [rsi+8*rcx+16] ; fetch array element
00007F mov rax, 0x7FFC9CFB4A90 ; B's method table
000089 cmp qword ptr [rcx], rax ; method table test
00008C jne SHORT G_M30756_IG06 ; jump if class is not B
00008E mov eax, 33 ; inlined B.F
000093 jmp SHORT G_M30756_IG07
G_M30756_IG06:
000095 mov rax, qword ptr [rcx] ; fetch method table
000098 mov rax, qword ptr [rax+72] ; fetch proper chunk
00009C call qword ptr [rax+32]B:F():int:this ; call indirect
G_M30756_IG07:(cmpに隠されている)メソッドテーブルの冗長な読み込みがありますが、
これはプロトタイプに対してもう少し追加作業をすれば排除できる可能性があることを指摘しておきます。
そのため、特にpの値が小さい場合、ガード付き脱仮想化の性能は上記の値よりもさらに良くなる余地があります。
さて、上で尋ねた質問に戻りましょう。2つのクラスのケースに何か特殊な要因があるせいで、ガード付き脱仮想化が特に魅力的になったのでしょうか? 続きを読みましょう。
3番目のクラスを混ぜこんで、上記の測定を繰り返してみます。その場合、結果に影響を及ぼす確率は2つになります。
1つは確率pで、これは要素の型がBクラスである確率です。もう1つは確率p1で、これは要素の型がDクラスである確率です。
そしてそれ以外であれば 3番目のEクラスとなります。
グラフを3次元描画しなくてすむように、まずp1のさまざまな値に対する結果を単純平均して、性能をpの関数として描画します。
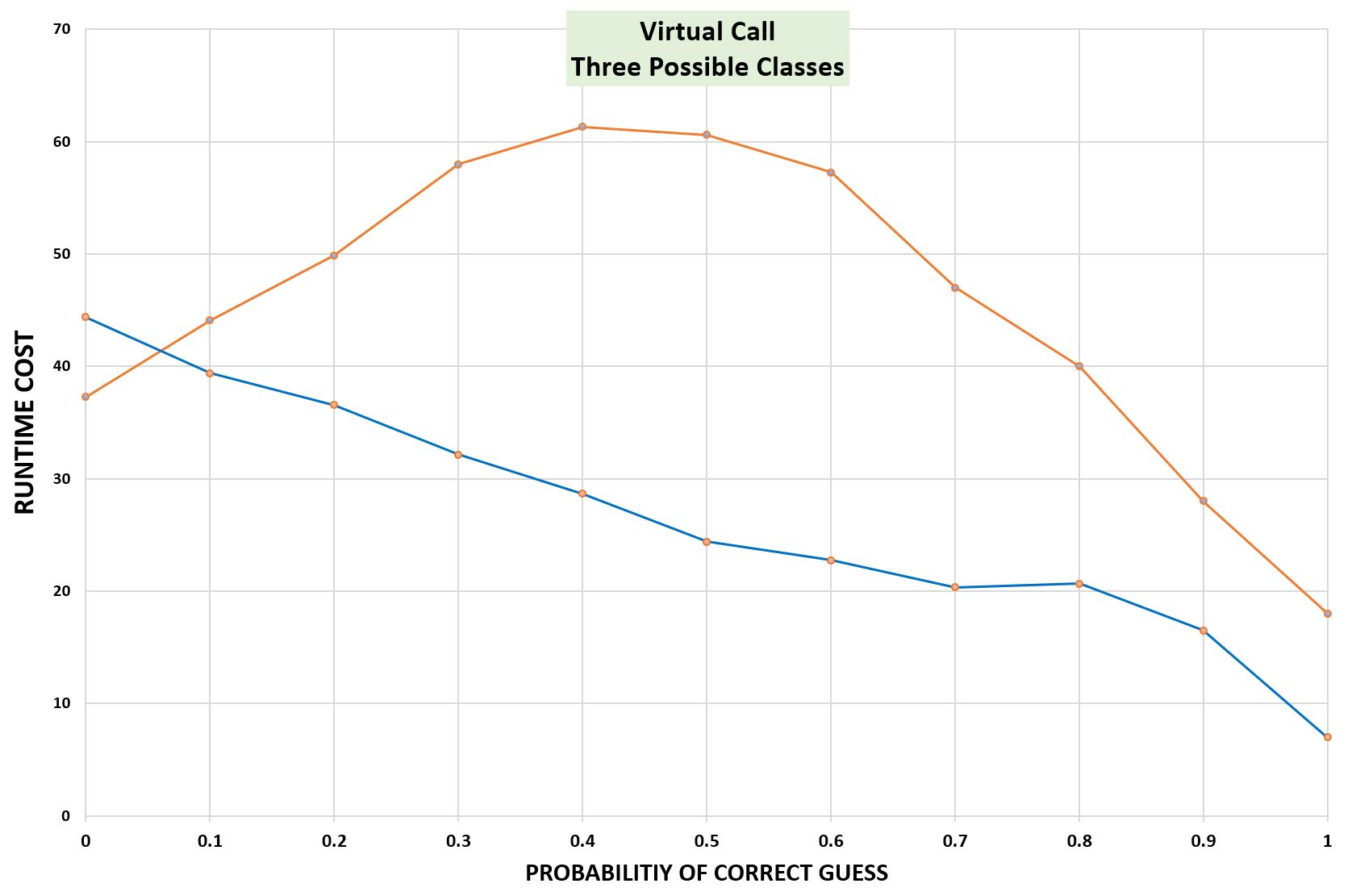
(pが1.0に近い)右側は前のグラフとよく似ています。
右側では3番目のクラスのインスタンスが比較的少ないので、これは驚くことではありません。
しかし、中央と左側は前のグラフと異なり、より高価です。
最適化されていないケース(オレンジ色)に関しては、違いは間接分岐予測子の性能に直接起因します。
pが小さい場合でも、取り得る分岐先が(平均すれば)2つあるので、間接分岐にはある程度の誤予測が含まれます。
最適化されたケースでは、ガード付き脱仮想化はJITの推測が完全に間違っている場合に最適化しない場合よりもパフォーマンスが悪くなることがわかります。
JITが導入した分岐は予測可能であるため、ペナルティはそれほど悪くありません。
しかし、pの値がごく小さい間でさえ、ガード付き脱仮想化の方が勝ち始めます。
p1を平均したのは何かを隠すためではないのかと疑う人もいるかもしれません。
次のグラフは、平均値に加えて、最小値と最大値を図示しています。また、2クラスの時の結果(破線)も示しています。
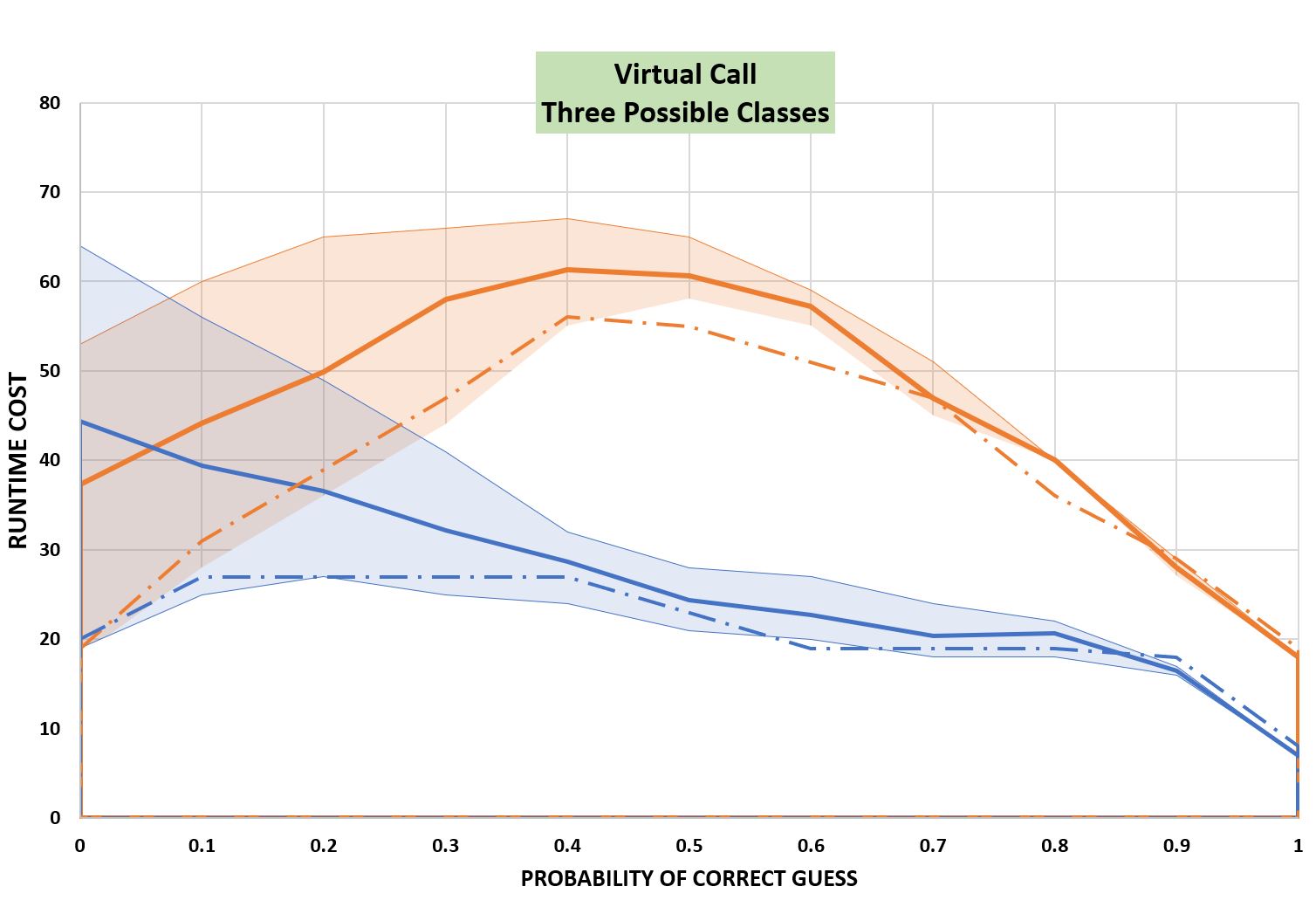
最小値はクラスが2つの場合と非常によく似ています。これは、p1が0または1に近い場合です。
そして、それは理にかなっています。なぜなら、3つのクラスが存在する可能性があるにもかかわらず、実際には2つのクラスしか存在しないならば、
2つのクラスしか存在し得ない場合と同様の結果が得られるはずです。
そして、上で述べたように、pが十分に大きいなら、DとEがどの程度混合しているかは問題にならないので、曲線はやはりクラスが2つの場合に収束します。
つまり、Bの優位性が勝つのです。
pの値が小さい場合、コールサイトにおける実際のクラスはDとEがある程度混在したものになります。
詳細は次のとおりです(このグラフでは、x軸の上段がp1で、下段がpを表しています)。
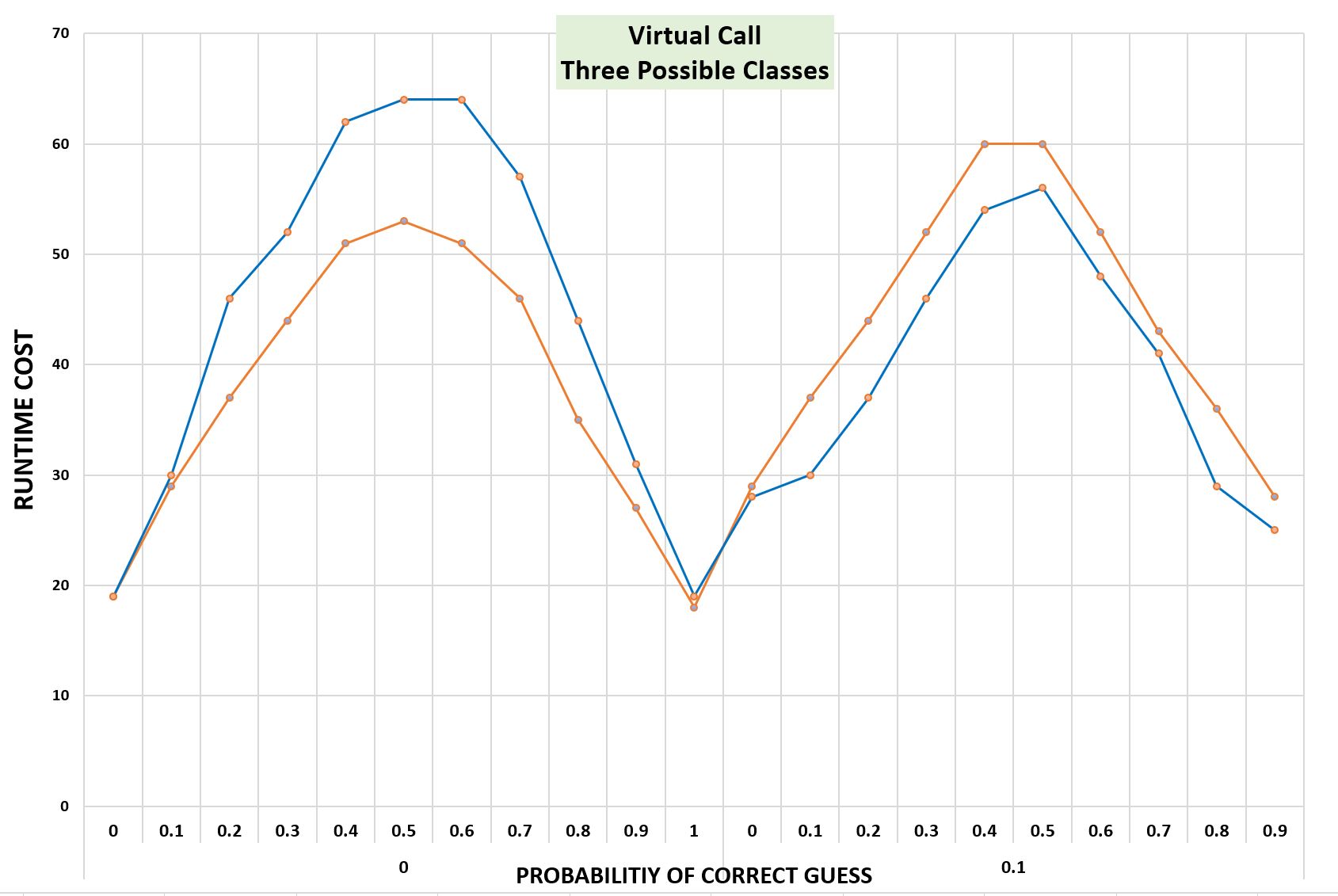
両方において性能が最悪になるケースは、DとEの割合が50% - 50%で予測できず、Bが存在しない場合です。
Bを10%だけ混ぜると、他の2つのクラスがどういう分布であっても、ガード付き脱仮想化のパフォーマンスの方が良くなります。
最悪のケース(JITがまったく現れないクラスを推測し、他のクラスが均等に分配されている場合)のオーバーヘッドは約20%です
そのため、JITがクラスの存在確率について信頼できる推測(たとえば、最低でも10%の確率で正しい推測)をすることができるなら、 仮想呼び出しをガード付き脱仮想化することでパフォーマンス上の利点が生じる可能性が非常に高いと言えます。
もっと多くのシナリオで検証する必要はありますが、これらの初期結果は確かに有望です。
上の結果から考えると、2つの候補が同程度に存在し得る場合は、JITはそれぞれについてテストする必要があるのではないかと推測する人もいるでしょう。 確かにその可能性もありますし、間接呼び出しのプロファイリングをするC++コンパイラでは、複数のテストが良い考えとみなされることもあります。 とはいえ、コードサイズは増加しますし、別の分岐が増えるという問題もあります。
これについては追加調査をしたいと思います。
CLRのインターフェース呼び出しは仮想スタブディスパッチ(訳注:リンク先は日本語訳)を介して実装されています。 呼び出しは間接化セルを通して行われますが、間接化セルは最初、検索スタブ(Lookup Stub)を指しています。 初回の呼び出しで、インターフェースの対象がオブジェクトのメソッドテーブルから識別され、 検索スタブはガード付き脱仮想化ととてもよく似た方法でその特定のメソッドテーブルをチェックするディスパッチスタブに置き換えられます (訳注:初回のインターフェース呼び出しで解決されたメソッドはディスパッチスタブ内にキャッシュされ、次回以降はインスタンスのメソッドテーブルをチェックして、キャッシュされたメソッドと一致するかを確認する)。
メソッドテーブルのチェックに失敗した場合はカウンターがインクリメントされ、 カウンターがしきい値に達するとディスパッチスタブは解決スタブ(Resolve Stub)に置き換えられます。 解決スタブは、プロセス全体で共有されるハッシュテーブルから正しいターゲットを検索するものです。
インターフェースのコールサイトが単相の場合、仮想スタブディスパッチのメカニズムは(ディスパッチスタブを用いて)次のコードシーケンスを実行します(次に示すのはx64の場合です)。
; JIT-produced code
;
; set up R11 with interface target info
mov R11, ... ; additional VSD info for call
mov RCX, ... ; dispatch target object
cmp [rcx], rcx ; null check (unnecessary)
call [addr] ; call indirect through indir cell
; dispatch stub
cmp [RCX], targetMT ; check for right method table
jne DISPATCH-FAIL ; bail to resolve stub if check fails (uses R11 info)
jmp targetCode ; else "tail call" the right method一見したところでは、仮想スタブディスパッチにガード付き脱仮想化を追加しても、単相的なコールサイトではそれほどメリットがないようにも思えます。 ただし、ガード付き脱仮想化のテストは間接セルを使用せず、R11レジスターの設定も不要なので、最適化によってnullチェックを無くせるかもしれません。 そうなればインライン化のドアを開くことができます。その時は、呼び出しコストは平均でもやや低くなり、場合によっては大幅に低くなるはずです。
(なお、CoreCLR#1422によれば、どのような場合でもnullチェックを最適化することができるはずです。)
ガードテストが失敗した場合は、1つのメソッドテーブルが除外されます。 コールサイトが2つのクラスを交互に使用している場合でも、ディスパッチセルはうまく機能します。 そのため、ガード付き脱仮想化と仮想スタブディスパッチの組み合わせは、2クラスのテストでうまく機能し、 3つ以上のクラスが混在している場合にのみ欠点となることが期待されます。
ガードテストが常に失敗する場合は、仮想テーブルをフェッチする先行コストがありますが、 それは、スタブ内のその後のフェッチと、実行しないと予測された方の分岐によって、かなりうまく償却されるはずです。 そのため、JITの予測が常に間違っている2クラスのケースのコストは少し高くなる程度だと予想されます。
下のグラフは測定結果を示しています。 仮想スタブディスパッチの状態が残ることで過度の影響を受けないようにするために、pの値ごとに新しいコールサイトを使用します。 オレンジ色の実線は現在のコストです。 オレンジ色の破線は、同じpの値を持つ仮想呼び出しに対応するコストです。 青い実線は、事前にガードテストをするコストです。 すでに述べたように、JITが常に間違ったクラスを推測しているときには若干の性能低下がありますが、 推測が正しい確率が比較的小さいうちに損益分岐点(図示していません)に達します。
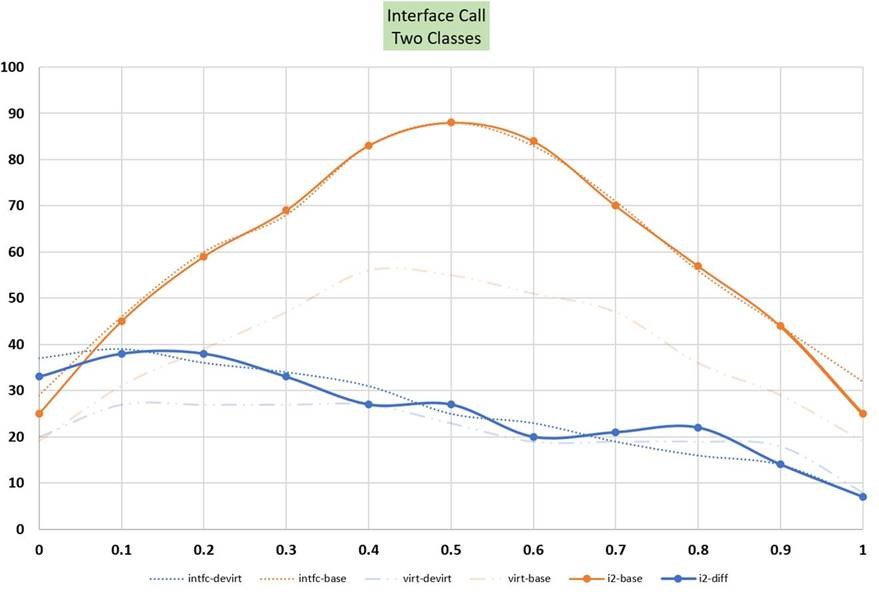
仮想呼び出しと同様に、インターフェース呼び出しでも2クラスのケースは特別なのではと強く疑っているかもしれませんね。そう思うのはもっともです。
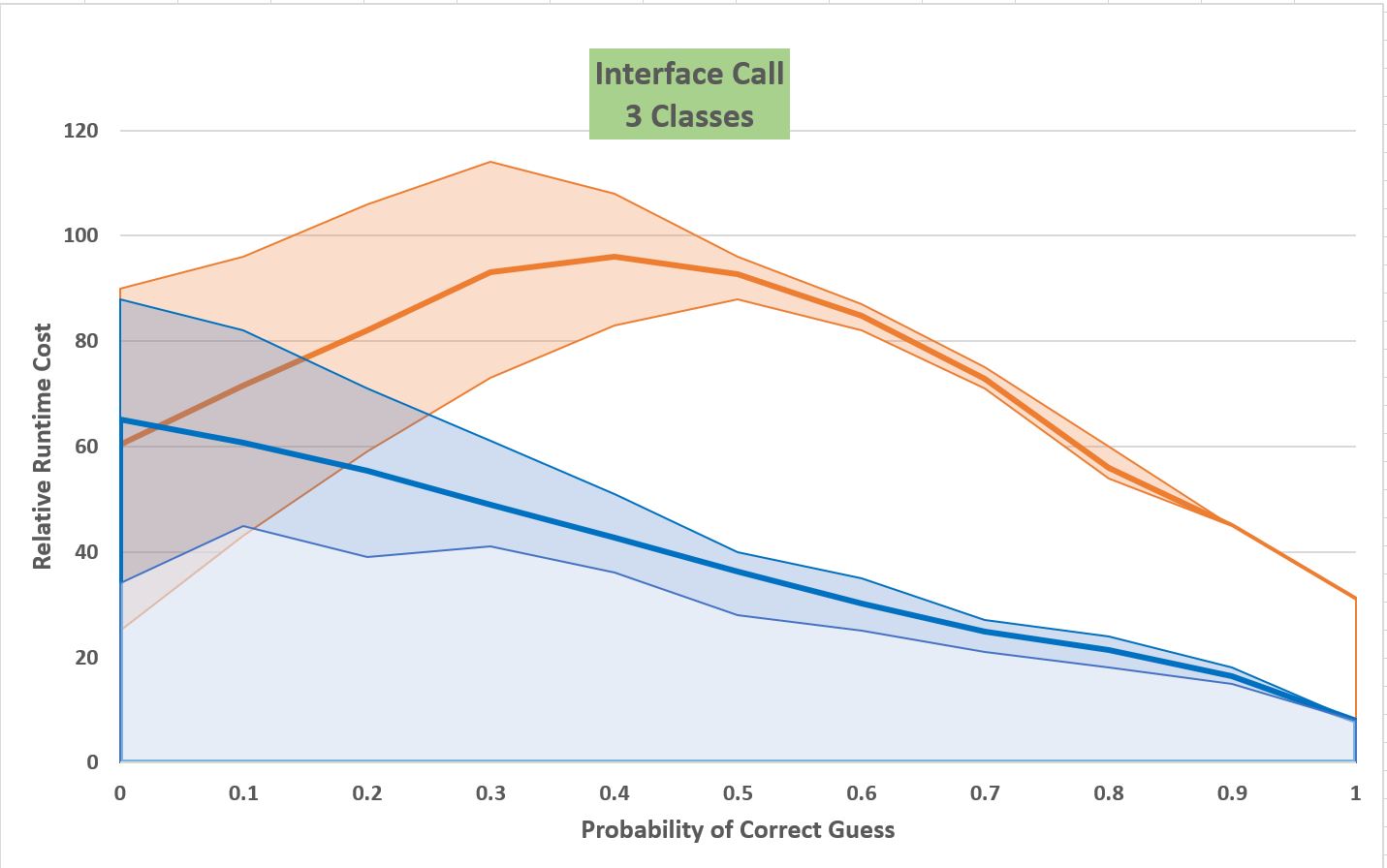
仮想呼び出しでもやったように3番目のクラスを混在させると、次に示すように、インターフェース呼び出しのパフォーマンス構成にも同様の変化が見られます。 しかし、仮想呼び出しの場合と同様に、JITの推測が効果を出すためには、さほど良くなくても問題ありません。 推測が10%程度正しければ、平均的には性能が良くなりますし、30%程度正しい推測であれば、常に性能の勝負に勝てます。
本記事のここまでの議論は仮想呼び出しの文脈でしたが、この手法は一般的なものなので、間接呼び出しにも適用できます。 その時は、ガードテストは型というより特定の関数かどうかだけをテストするかもしれません。
Delegate.Invokeは、最終的に間接呼び出しへと変化できる特殊なメソッドです。
この呼び出しのターゲット候補について、JITに推測させることも不可能ではありません。
その時に適切なターゲットを選択するには、間接呼び出しについてある種のプロファイリングが必要になります。
間接呼び出しはcalliオペコードでも発生します。
そこでターゲットを選択するには、おそらくデリゲートと同様に特殊なプロファイリングが必要でしょう。
性能について楽観的に見ることを前提にしても、ガード付き脱仮想化にはコードサイズの増加とJIT時間の増加というコストもかかることを覚えておくことが重要です。 メソッドに以前は存在しなかった制御フローを導入するので、ローカルコード生成に二次的な影響があるかもしれません。
ガード付き脱仮想化を積極的に実行する単純な実装では、PMI(訳注:JITのユーティリティツール)による測定でコードサイズ全体が約5%増加します。 JIT時間の増加は測定されていませんが、同程度のはずです。 アセンブリによっては、コードサイズが最大12%増加するものもあります。
ただし、ガード付き脱仮想化は、全メソッドの約15%に対してしか適用されません。 つまり、仮想呼び出しを使用したメソッド1つに対する相対的なサイズの増加は、おそらく平均で33%近くになるはずです。
現在のプロトタイプには非効率な部分がいくらかあるでしょうし、それらを修正すればコードサイズへの影響を減らせるかもしれません。 上で説明した、追加のメソッドテーブルフェッチの他にも、重複した呼び出しには同じ引数のセットが使われるので、引数の評価コストをもっとうまく償却できる可能性があります。 また、戻り値の処理には、特に暗黙の参照渡し構造体(訳注:読み取り専用構造体か?)の場合にいくつか複雑な部分があるので、同じように効率化できるかもしれません。
ですが、すべての仮想呼び出しを盲目的にガード付き脱仮想化で最適化するのは、おそらく正しいアプローチではありません。 もっと選択的な方法が必要なのはほぼ確実です。
とはいえ、これまではコードが拡張されるような最適化をやや盲目的に行ってきました。 この最適化をティア1(最優先グループ)だけに制限することで、サイズ増大のリスクを抑えることができます。 また、PMIは、常にインライン化されるメソッドにおける変更の影響を過大計測することがあるので、現実的なシナリオでのサイズに対する影響を過大評価する可能性があります。 そのため、複数の実際のシナリオでサイズの増加を確認するべきです。
私なら多分、まずループのクローン生成(訳注:ループ最適化の一手法)を先例として選び、サイズへの影響を検討するでしょう。
上記のデータを採取し、関連する課題をよりよく理解するために、プロトタイプを実装しました。 それは現在このブランチにあります:GuardedDevirtFoundations
このプロトタイプは、いくつかの仮想およびインターフェース呼び出しに対してガード付き脱仮想化を導入することができます。 直接呼び出されるメソッドのインライン化をサポートします。 予測するクラスとしてJITが「最もよく知っている型」を使用します。 また、あるインターフェースを実装するクラスをランタイムに問い合わせできることも期待されています。
ほとんどの場合、脱仮想化はJITのとても早期であるインポート中に行われます。 これにより、脱仮想化された呼び出しを後でインライン化できるようになりますし、 インライン展開先にある呼び出しサイトを脱仮想化するために、 インライン化された引数から型情報を利用して、インライン展開先に引き渡したりすることもできるようになります。
ガード付き脱仮想化の対象にも同じ性質を持たせたいと思います。 そのため、概念的には、変換は同じ時点で行われるべきです。 ただし、インポーターの中で新しい制御フローを導入することはできません(質問オペレーションを使う可能性については今のところ無視します)。 そのため、実際の変換はインポーターが実行されてからインライナーが実行されるまでの間のどこかに延期する必要があります。
呼び出し先の属性についてランタイムに問い合わせるにはインポーターの状態の重要な部分がいくつか必要なので、この延期は少々問題です。 そのため、変換を延期する場合は、これらの問い合わせに必要なデータを何らかの方法で取得しておいて、後で使用できるようにする必要があります。 現在のプロトタイプはこのためにインライン化候補の情報を使用(濫用?)します。 この一環として、少なくとも最初は、脱仮想化サイトと推測されるすべてをインライン化候補として扱うことを要求します。 これには、呼び出しを最上位の(ステートメント)式にして、戻り値のプレースホルダーが導入されるという副作用があります。
現在JITではすでに似たような変換が行われています。それはCoreRTに必要な "fat calli"変換です。
この変換は、適切なタイミング(インポーターより後でインライナーより前)で実行され、
正しい種類のif-then-else制御フロー構造を導入します。
よって、検討すべきはガード付き脱仮想化も処理できるようにこれを一般化することです。
プロトタイプでは、初回のインポーターによる impDevirtualizeCall 呼び出しの中で脱仮想化候補が認識されます。
脱仮想化をできない理由が正確性が足りないというだけである場合、その呼び出しはガード付き仮想化解除の候補としてマークされます。
直接呼び出しを生成するために、プロトタイプは、呼び出しのthen側に渡されたthisを更新して、正確に予測された型を持つようにします。
それからimpDevirtualizeCallを再度呼び出します。型が正確にわかっているので今度は成功するはずです。
ここで再利用している利点は、脱仮想化の特殊ケースのうちいくつかは処理される可能性が高くなることです。
プロトタイプは現在、すべての仮想呼び出しとインターフェース呼び出しを潜在的なインライン候補として設定します。 未解決問題の1つは、直接呼び出しを導入するためだけにガード付き脱仮想化を行う価値があるかどうかです。 他の選択肢として、直接呼び出されるメソッドも潜在的にインライン化可能だと主張することもできました。 呼び出しのオーバーヘッドは、インライン候補にも適していそうな小さなメソッドのほうがはるかに問題になるという考え方もあります。
インライン候補の情報は、仮想サイトで呼び出された見かけのメソッドに基づいています。 これが基本のメソッドで、そこに仮想スロットを導入します。 そのため、何らかのクラスを推測的にチェックし、その推測したクラスが覆された場合は、インライン情報を何らかの方法で更新する必要があります。 最善の方法はまだ明らかになっていません。
候補とされた呼び出しはインライン候補として処理されるため、JITはインポート時にその呼び出しを最上位の式に引き上げ(それは問題ありません)、 元のツリーで呼び出しが占めていた場所に戻り値のプレースホルダーを導入します (おかしなことに、値を返さない呼び出しに対しても戻り値のプレースホルダーが導入されることがありますが、それは修正します)。 プレースホルダーは呼び出しの時点で値を参照します。
呼び出しとプレースホルダーの間には一対一の関係が必要なので、1つの呼び出しを2つの呼び出しに分割した時は、構造をそのままにしておくことはできません。 そのため、プロトタイプは戻り値を新しいローカル変数に保存してから、そのローカル変数を参照するようにプレースホルダーを更新する必要があります。 場合によっては、戻り値の実際の型がまだ決まっていない場合があるため、これには注意が必要です。
JITの初期段階(JIT全体の中ではそう言って過言ではないでしょう)で戻り値を処理するのはかなり面倒です。 ABIの詳細はかなり早くから漏れ出ていて、しかも漏れ方はやや不均一です。 そのことは、構造体を返すメソッドに対して主に影響を与えます。なぜなら、異なるABIはまったく異なる規則を持つからです。 そしてIR(中間表現)はそれらの規則を反映するように変換されますが、そのタイミングは、インライン化されない呼び出し、インライン化される可能性があったものの最終的にはインライン化されなかったインライン化呼び出し、インライン化された呼び出し、そのそれぞれについて異なります。 特に、構造体が十分小さいため(1レジスターまたは複数レジスターを使った)値として返す場合は、慎重な処理が必要です。
現在、プロトタイプはそのような構造体を値で返すメソッドをスキップします。
fgUpdateInlineReturnExpressionPlaceHolderにあるロジックの中には、呼び出しの戻り値に正しく型を付けるために取り込むべきものもあります。
そうすれば、一時変数にも正しく型を付けることができるようになります。
あるいは、"fat calli"の場合に行われるインポート時の変換をいくつか利用することもできたかもしれません。
それより大きな構造体の場合は、戻り値は新しい一時変数に直接書き込まれるようにするのがいいでしょう。 そうすれば、どこからの戻り値であっても一時変数にコピーするということをしなくてすむので、レベル1の構造体コピーを回避できるでしょう。 ただしそのようにすると、戻り値の構造体を事前にゼロ初期化しないといけなくなるかもしれません。それが発生するのは一箇所だけにするべきです。
さらに注意深く検討しなければならないいくつかの問題を以下に述べます。
- テストするクラスを推測する最良のメカニズムは?
- ティア0のコードを計測する?
- 引数の型を調べる?
- 判別済みのクラスについてランタイムに問い合わせる?
- ランタイムのキャッシュ(仮想スタブディスパッチ)から情報を取り出す?
- ティア1の計測を追加してデータを収集し、ティア2を最適化する?
- クラスの範囲に対してテストする効率的な方法は? 現在JITはある正確な型に対するテストをしています。
しかし、実際に気にしているのはどのメソッドが呼び出されるのかです。
であるなら、
D1 ... DNという範囲の型があり、すべてが特定のメソッドを呼び出すような場合に、その型すべてをテストする方法はあるでしょうか? - それとも、メソッドルックアップの後にメソッドをテストするべきでしょうか? (メソッドテーブルはチャンク配置されているので、おそらくトレードオフが悪くなるでしょう。また、あるメソッドは時間がたつにつれて複数のアドレスを持つこともあるので、扱いにくくもなります。) そうすれば、多くの型が1つのチャンクを共有することもあるので、より広い範囲のクラスで脱仮想化ができるようになる(利点)かもしれませんが、正確な型の知識を失うことになるでしょう(欠点)。 これらのトレードオフがどう影響するのかはまだ明らかになっていません。
- ガード付き脱仮想化と仮想スタブディスパッチを連携させる? インターフェース呼び出しに関しては、JITが出力するコードで仮想スタブディスパッチの第一段階をある意味インライン化しています。
- JITの推測が良くないとわかったときに、ガードを失効させたり修正したりするべきか?
- 通常の脱仮想化を改善して、ガード付き脱仮想化の必要性を下げる
- Pre-JIT(事前ネイティブコンパイル)されたコードでもガード付き脱仮想化を有効にするべきか?事前ネイティブコンパイルされたコードでは、対象のメソッドテーブルはJIT時定数ではなく、都度検索しないといけません。
- プロトタイプでは、ガード付き脱仮想化と遅延された脱仮想化が競合することがあります。 コールサイトの脱仮想化ができず、クラスXを推測するガード付き脱仮想化に拡大したとします。 未解決の仮想呼び出しは、遅延された脱仮想化によって最適化できる可能性がありますし、そうすれば実際のクラスが見つかるかもしれません。 その場合、ガード付き脱仮想化は必要ありません。しかし、現在の実装ではそれを元に戻すことはできません。
- ガード付き脱仮想化は、併せてインライン化までできないのであれば、おそらくあまりやりたくないことです。 しかし、呼び出しをインライン化できるかどうかを判断するには、いくつかの評価手順が必要ですし、 その中には、ガードを追加した 後 に行われるものもあります。繰り返しますが、この拡大は元に戻すことができません。
- そのため、ガード付き脱仮想化がインライン化できなかった場合や遅延された脱仮想化を適用する場合にも備えるために、元に戻す機能を構築する必要があるはずです。
- 潜在的な仮想呼び出しのためのメソッドテーブルの再取得を回避する(コードサイズを減らし、全体的なパフォーマンスの向上を図ることができるはず)
- 引数の準備をどの程度効率的に共有しているかを調べる(コードサイズとJIT時間への影響を減らす可能性に期待して)
- 戻り値を完全に一般的に扱う
- ILのオフセット
- 未解決の呼び出しに、NULLチェックが必要ないというフラグを立てる
- インライン化候補を適切に選定する
- インポーターから間接変換フェーズに情報を渡すための方法として、
InlineCandidateInfoのリファクタリングが正しいかどうかを決定する
- 複数の呼び出しを1回のテストでカバーできるかどうか。 直接呼び出されたメソッドのインライン化を介して後続の呼び出しが導入される場合については、そのパスに沿った正確な型がわかっているので、現在の実装でも起こることがあります。 しかし、同じオブジェクトへの仮想メソッドの連続呼び出しの場合については、いずれ1回だけのテストにできるといいなと考えています。
- 複数の型についてテストする必要があるかどうか。 テストによって「最も可能性の高い」ケースを取り除いた上で、次に最も可能性が高いケースの条件付き確率が高い場合は、そちらもテストする価値があります。 C++コンパイラはそんな風に最大3つの候補をテストしたはずですが……そうするとコードが大きく拡大することになります。