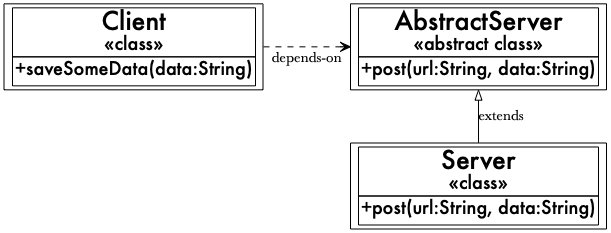
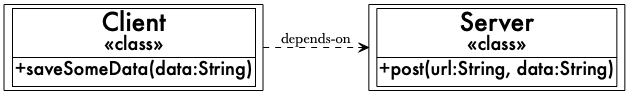依存性逆転の原則...はトレードオフだ (SOLIDはソリッドではない) https://naildrivin5.com/blog/2019/12/02/dependency-inversion-principle-is-a-tradeoff.html
2019年12月2日
元の投稿 で述べたように、私はSOLID原則が...思われるほどソリッド(堅牢)ではないことに気づいている。その投稿では、単一責任原則に私が見る問題点を概説した。 2番目の投稿 では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。 3番目の投稿 では、Liskov置換原則が間違った問題に焦点を当てすぎていて、実際には使えるデザインのガイダンスを与えていないことについて話した。 4番目 は、インターフェース分離原則が結合の問題へのアプローチとして適切ではないことについてだ。
さて、最後の原則、依存性逆転の原則に移ろう。これは、「2000年代のJavaがすべてのコードをXMLで書くことと同一視される理由の原則」とも呼べるものだ。この原則は、コードは具体ではなく抽象に依存すべきだと述べている。原則であるため、 すべて のコードが抽象に依存すべきだという含意がある。いやいや、そうあるべきではない。抽象に依存することにはコストがかかるが、この原則はそれを大いに無視している。それを見てみよう。
ここで批判を完結させて、単に「必要のない柔軟性を追加するな」と言うこともできるかもしれない。しかし、これが原則だと考えられている背景は興味深いと思う。第一原理から深く設計について考えた人から出たものではないからだ。代わりに、JavaとC++がオブジェクト指向を実装するために選択した方法のいくつかの制限に関連した防御メカニズムなのだ。
Wikipediaの記事 から引用すると:
多くの単体テストツールがモックを実現するために継承に依存しているため、クラス間の一般的なインターフェースの使用(一般性を使用するのが理にかなっているモジュール間だけでなく)がルールになった。
こうして、大規模なJavaプロジェクトになぜ依存性の注入が非常に多いのか、そして主にJavaで作業している場合になぜ依存性逆転が設計原則のように感じられるのかがわかり始める。
私は、キャリアの最初の3分の2をJavaで過ごした。私が携わった最も複雑なJavaアプリケーションは、依存性逆転の原則を大いに利用していた。すべてのクラスは、そのクラスを必要とするものがインターフェースにのみ依存できるように、別々のインターフェースと別々の実装を持たなければならなかった。すべての、単一の、クラスだ。
ReturnProcessorというクラスを作る必要がある場合、ReturnProcessorをインターフェースにし、ReturnProcessorImplというクラスで実装する。いつでもどこでも、だ。その理由は、実際には設計の純粋さとかそういったものではなかった。Javaでのモックとユニットテストに対処するためだったのだ。
仕事をするためにReturnProcessorを必要とするShipmentIntakeクラスを考えてみよう。依存性逆転などを考えずに、次のように書くかもしれない。
public class ShipmentIntake {
public processShipment (Shipment shipment ) {
ReturnProcessor returnProcessor = new ReturnProcessor ()
returnProcessor .process (shipment )
// ...
}
}このコードをテストするには、テストの一部として実際のReturnProcessorの実行を許可するか、それをモックする必要がある。依存関係をモックすることは非常に一般的で、非常に便利だ。ReturnProcessorが実際のWebサービスに多数のHTTPコールを行うとしよう。テストでそれらのHTTPコールを行いたくないので、それを避けるためにReturnProcessorをモックする。
問題は、このコードの書き方では、ReturnProcessorを簡単にモックできないことだ。Javaでは、newはオブジェクトのメソッド呼び出しではないからだ。それは特別な形式であり、モックのReturnProcessorを返すようにその動作を変更することはできない。
この制限を回避するために、ReturnProcessorを他の誰か( 依存性を注入する プロセスと呼ばれる)によってShipmentIntakeに与えることを許可する。これを行う最も簡単な方法は次のようになる。
public class ShipmentIntake {
private ReturnProcessor returnProcessor ;
public ShipmentIntake (ReturnProcessor returnProcessor ) {
this .returnProcessor = returnProcessor ;
}
public processShipment (Shipment shipment ) {
this .returnProcessor .process (shipment )
// ...
}
}これにより、モック化された動作を持つ実際のReturnProcessorのサブクラスを作成でき、それをテストで使用できる。例えば:
ReturnProcessor mockReturnProcessor =
createMock (ReturnProcessor .class ) // or whatever
ShipmentIntake shipmentIntake =
new ShipmentIntake (mockReturnProcessor )ただし、これでは問題は完全には解決しない。Javaでは、クラスがサブクラスを持つことができない、または特定のメソッドがオーバーライドできないことを示すことができる。そのようにされている場合、テスト用のサブクラスを作成することはできない。
それ を回避するために、ShipmentIntakeが依存するインターフェースを作成し、実際のReturnProcessorがそれを実装するようにする。モックのReturnProcessorはもはやサブクラスである必要はない。インターフェースを実装すればよいのだ。
それ は次のようになる。
public interface ReturnProcessor {
public void process (Shipment shipment )
}
public class ReturnProcessorImpl implements ReturnProcessor {
public void process (Shipment shipment ) {
// ...
}
}
public class ShipmentIntake {
private ReturnProcessor returnProcessor ;
public ShipmentIntake (ReturnProcessor returnProcessor ) {
this .returnProcessor = returnProcessor ;
}
// ...
}私たちは今、「依存性を逆転」させた。なぜなら、ShipmentIntakeはもはや具体的な実装に依存せず、代わりに一般的なインターフェースに依存し、そのインターフェースの任意の実装を提供できるからだ。
問題は、これは本当にユニットテストの問題に対処するためにのみ必要だったが、結局はこれを どこでも やらなければならなくなり、最終的にはこれが単に「良いオブジェクト指向設計」だと決めつけてしまうことだ。元々解決しようとしていた問題ではないにもかかわらず、だ。
もちろん、このパターンはまた、これらすべての依存関係を結びつける新しいコードが必要になるという問題も生み出す。どこかで、ShipmentIntakeに使用するReturnProcessorの実装を知っているものが必要だ。昔は、これは巨大なXMLファイルだったが、最近では、ソースコードにアノテーションを追加して、それを実現できる。
しかし、オープン/クローズド原則の投稿で議論したように、この追加された柔軟性は無料ではない。コストがかかる。それは、システム全体を理解しにくくすることだ。なぜなら、ShipmentIntakeのソースコードを見ても、実行時にどのオブジェクトが使用されるかがわからなくなるからだ。実装を入れ替える 必要 がなければ、これは何の利点もない不要な柔軟性だ。
覚えておいてほしいのは、これを導入したのは、コードを「より良く」するためではなく、Javaでのテストの方法に関する問題を解決するためだということだ。Rubyを使用していれば、元の問題は発生しなかっただろう。Rubyでの元のShipmentIntakeは次のようになる。
class ShipmentIntake
def process_shipment ( shipment )
return_processor = ReturnProcessor . new
return_processor . process ( shipment )
# ...
end
end newはオブジェクト(つまり、クラスでもあるReturnProcessorオブジェクト)に対して呼び出されるメソッドであり、Rubyは任意のメソッドの動作を動的に変更できるため、依存関係を逆転させる必要なく(Rubyにはインターフェースがないことを念頭に置いて)、テスト中にReturnProcessor.newがモックオブジェクトを返すように簡単に設定できる。
一部の開発者はこれを好まないが、繰り返しになるが、これはトレードオフだ。依存関係を逆転させてそれらを注入可能にすると、新しい問題が生じる。つまり、クラスは単純化されるかもしれないが、システムはより複雑になるのだ。これは本当のトレードオフだ!
ReturnProcessorのRuby版は、シンプルなAPIを持っている。引数なしで作成でき、shipmentを受け取る単一のメソッドがある。もしそのコラボレーター(ReturnProcessorなど)を注入できるようにすると、次のように、リターンプロセッサーへの依存を公開するため、そのAPIはより複雑になる。
class ShipmentIntake
def initialize ( return_processor = ReturnProcessor . new )
@return_processor = return_processor
end
def process_shipment ( shipment )
@return_processor . process ( shipment )
# ...
end
end 大したことではないと思うかもしれないが、これは実際には重要だ。ShipmentIntakeが出荷を処理することだけに関するデザインから、「リターンプロセッサーで出荷を処理する」ことに関するデザインに変わったのだ。ShipmentIntakeのクライアントは、リターンプロセッサーについて知る必要があるだろうか?
ShipmentIntakeが何に使用されるかを知らずにその質問に答えるのは難しい。異なる状況で異なるリターンプロセッサーを使用する必要がある場合は、はい、ReturnProcessorを注入できるようにすべきだ。しかし、この柔軟性が必要ない場合はどうだろう?
もしその柔軟性が必要 ない のであれば、それを追加することを良いこととは見なしがたい。クラスのAPIを必要以上に大きくしてしまったのだ。そして、オープン/クローズド原則の投稿で議論したように、不必要な柔軟性を持つクラスは、実行時に正確にどのオブジェクトが使用されたかを追跡しなければならないため、システム全体の理解を難しくする。
では、いつクラスを抽象に依存するように設計 すべき だろうか? テストの問題を除けば(Javaでは、依存関係を注入するためのパブリックAPIを作成することなく、実際には別の方法で解決できる)、特定のオブジェクトの作成が複雑な場合、依存関係を外部化することは有用に思える。
これまでの例では、コンストラクタに何も渡さずにオブジェクトを作成していた。しかし、オブジェクトを構築するために情報が必要な場合はどうだろう? 例えば、ReturnProcessorがHTTPコールを行う場合、URLや認証情報など、それを行う方法に関するかなりの情報が必要になるかもしれない。
ShipmentIntakeがReturnProcessorのインスタンスを作成する責任を持つ場合、問題が発生するかもしれない。ShipmentIntakeはReturnProcessorを作成するためのすべての設定値を知っている必要があるか、それ自体も その コンストラクタのどこかから設定を与えられる必要があり、そうするとあちこちに設定が渡されることになる。
1つの解決策は、すべてのクラスにグローバルな設定オブジェクトを提供し、必要なときに必要なものを取り出すことだ。
public class ShipmentIntake {
public ShipmentIntake (GlobalConfig config ) {
this .returnProcessor = new ReturnProcessor (
config .returnPartner .getUrl (),
config .returnPartner .getUsername (),
config .returnPartner .getPassword ()
);
}
}これは、カプセル化を維持する。ShipmentIntakeのユーザーは、完全に機能するオブジェクトを取得するためにnew ShipmentIntake(config)を呼び出すだけでよく、それを作成するためにShipmentIntakeがどのように実装されているかを知る必要はない。しかし、すべてのクラスがどこでもすべての設定にアクセスできるため、不快な結合が生じる。これにより、おそらくそうあるべきではないのに、2つのクラスが同じ設定オプションに依存する状況が生まれ、システムが不必要に変更しにくくなる可能性がある。アプリケーションの設定は必ずしも凝集性が高くないので、それをあちこちに増殖させないようにするのは理にかなっている。
依存性逆転の原則に従えば、どのクラスも依存関係をインスタンス化する必要はない。代わりに、どこか別の場所からそれらの依存関係が提供される。その別の場所とはどこだろう?
どこかでオブジェクトの作成方法と、どのオブジェクトをどの他のオブジェクトに渡すかを知っている必要がある。このオブジェクトの 配線 は設定の一形態であり、2000年代のJavaでは、XMLファイルで行われていた。今日では、アノテーションを使って暗黙的に行われているが、ScalaやGoなどの言語では、次のようにコードで行われる。
// Somehwere deep and dark that is allowed to have a bunch of
// coupling so that most objects don't have to
GlobalContext globalContext = new GlobalContext ();
globalContext .loadDefaultsFromEnvironment ();
globalContext .put (
"ReturnProcessor" ,
new ReturnProcessor (
globalContext .get ("returnPartner.url" ),
globalContext .get ("returnPartner.username" ),
globalContext .get ("returnPartner.password" )
)
globalContext .put (
"ShipmentIntake" ,
new ShipmentIntake (globalContext .get ("ReturnProcessor" )
)このGlobalContextには、システムが必要とする すべて のオブジェクトのインスタンスがあり、それらはすべて設定されて準備ができている。これは基本的にSpring Frameworkの仕組みだ(ただし、すべての配線を設定するのはそれほど厄介ではない)。
このように構築されたアプリケーションには利点が ある 。日々のコードは、オブジェクトのメソッドを呼び出すだけで構成され、オブジェクトの設定や作成に手を加える必要はほとんどない。しかし、このようなシステムのデバッグは楽ではない。アプリケーションの「配線」部分は非常に複雑になる可能性があり、それを正しく行うのは必ずしも簡単ではない。
複雑なアプリケーションでは、コードのかなりの部分がこの配線になることがあり、それが正しいことを確認するために、書き込み自体の統合テストが必要になる。アプリケーションが暗黙的に配線されている場合(現代のSpringアプリケーションのように、配線を行う実際のコードや設定がない場合)、実行時に実際にどのオブジェクトが使用されているかを把握するのは非常に難しい。
Ruby on Railsアプリケーションでは、この設定の問題をいくつかの方法で解決している。
一般的なパターンは、クラスが初期化時に設定される明示的な設定オブジェクトを公開することだ。この設定は、そのクラスのインスタンスを作成するたびに使用されるため、すべてのコードは単にReturnProcessor.newと書くことができ、ReturnProcessor内であらかじめ設定された設定がクラスの設定に使用される。
Railsでは、config/initialzersのファイルはアプリの起動時に実行されるので、次のようなことを行うかもしれない。
# config/initializers/return_processor.rb
ReturnProcessor . configure do |config |
config . url = ENV [ "RETURN_PARTNER_URL" ]
config . user = ENV [ "RETURN_PARTNER_USERNAME" ]
config . pass = ENV [ "RETURN_PARTNER_PASSWORD" ]
end オブジェクトのコンストラクタであるべきものの設定オブジェクトを外部化するのは奇妙に思えるかもしれないが、これは問題に対する良い解決策だ。アプリケーションコードはすべて、必要なときに必要なオブジェクトを作成でき、オブジェクトが重要な設定を必要とする場合は、それが他の場所で処理される。 実際の オブジェクトを事前に作成する強い必要性はない。
もう1つのパターンは、次のように、イニシャライザで単一のグローバルなオブジェクトインスタンスを作成することだ。
# config/initializers/return_processor.rb
RETURN_PROCESSOR = ReturnProcessor . new (
ENV [ "RETURN_PARTNER_URL" ] ,
ENV [ "RETURN_PARTNER_USERNAME" ] ,
ENV [ "RETURN_PARTNER_PASSWORD" ] そして、クラスはReturnProcessorが必要な場合、事前に設定されたグローバルインスタンスRETURN_PROCESSORを使用することを知っている。
最後の2つは嫌な感じがするかもしれないが、問題が本当に存在するのか、それとも単に純粋性に関連しているだけなのか、正直に自問してみよう。はい、グローバル変数は問題になる可能性があるが、アプリケーションに作成が難しいオブジェクトが少ししかない場合、これはあちこちに依存性注入を設定するよりも良い解決策ではないだろうか?
重要なのは、これはトレードオフだということだ。常に依存関係を逆転させ、常に依存性注入を使用することを示す「原則」は、すべての状況に対して常に正しいアドバイスではない。コードの振る舞いを非常に明示的にし、何が何を使っているかを直接見ることの方が価値がある場合、抽象化された依存性注入は問題になるだろう。一方、システム全体の理解度を犠牲にしてでも、すべてのクラスの設計に一貫性を持たせたい場合は、それでもよい。
トレードオフを理解し、SOLID原則にこだわらずに、自分のニーズと価値観に基づいて選択すること!
単に「抽象に依存する」だけでは、全体像を見ていないことになる。設計作業をしているのではなく、アプリケーションやチームの成功にとって重要なトレードオフを見逃すことになる。
私にとって、必要なものを構築し、必要になったときに柔軟性を追加するのが、必要になるかもしれないからというだけで柔軟性を追加するよりも常に良い。そして、テスト可能であるためにクラスを柔軟にする必要があるなら...素晴らしい! ただそう言ってほしい!
私のアドバイス: 必要であれば依存関係を注入し、なぜそうするのかについて正直であること。そうでなければ、必要のない柔軟性を追加しないこと。