http://cr.openjdk.java.net/~briangoetz/valhalla/sov/02-object-model.html
セクション2:言語モデル
Brian Goetz, Dec 2019
このドキュメントは、インライン型を組み込むための言語モデルについて説明します。 インライン型のJVMモデル、およびJavaソースコードからJavaクラスファイルへの変換戦略については、別のドキュメントで説明する予定です。 (このドキュメントでは、「現在」という言葉を、この言語の今の状況、すなわちインライン型がない状態を指すものとして使います。)
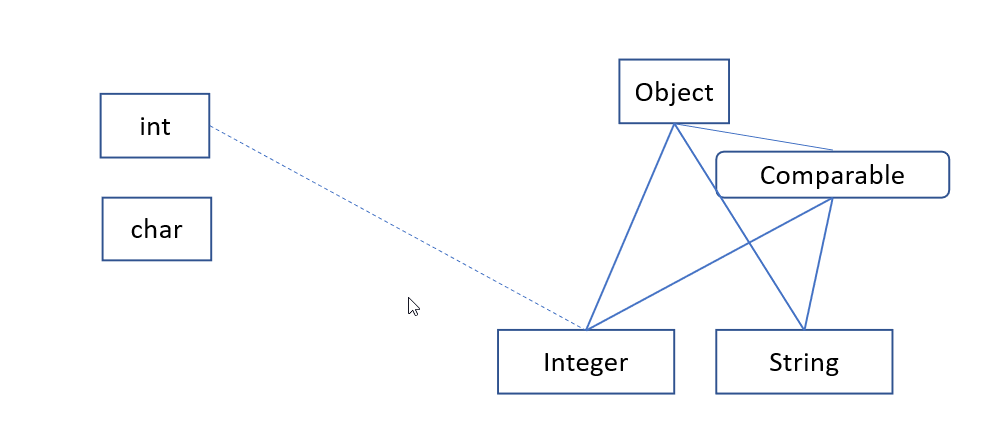
現在、型はプリミティブ型と参照型に分けられています。
8つの組み込みプリミティブ型があります(voidは型ではありません)。
参照型とは、プリミティブ型ではない型で、クラスまたはインターフェースとして宣言された型と、
配列型(String[], int[])および参照型のパラメーター化(List<String>, List<?>)などの非宣言型を含んでいます。
参照型とプリミティブ型は、考えられるほとんどすべての点で異なります。
参照型はメンバー(メソッドとフィールド)とスーパータイプ(スーパークラスとインターフェース)を持ち、すべてが(直接または間接的に)Objectを拡張します。
プリミティブ型にはメンバーがなく、型システム上の「孤島」であり、スーパータイプやサブタイプはありません。
プリミティブ型を参照型に接続するために、各プリミティブ型はラッパー型に関連付けられています(Integerはintのラッパー型です)。
ラッパー型は参照型であるため、メンバーを持つことができ、サブタイピングに参加できます。
プリミティブ型とそれに対応するラッパー型の間には、ボクシングとアンボクシングの変換があります。
すべての型は値集合を持ちます。これは、その型の変数に格納できる値の集合です。
(たとえば、intのようなプリミティブの値集合は32ビット整数の集合です。)
型Tの値集合を表すために、Vals(T) と記述することにします。
型Tが型Uのサブタイプである場合、Vals(T) ⊆ Vals(U) です。
オブジェクト はクラスのインスタンスです。 現在、すべてのオブジェクトには一意の オブジェクトアイデンティティ があります。
参照型の値集合は オブジェクト ではなく、 オブジェクトへの参照 で構成されます。
String型の変数がとりうる値は、 Stringオブジェクト自体ではなく、それらのStringオブジェクトへの参照です。
(経験豊富なJava開発者でさえ、オブジェクトを直接保存、操作、またはアクセスできないことに驚くかもしれません。
私たちはオブジェクト参照を扱うことに慣れすぎているので、違いに気付かないことさえあります。
実際、Javaオブジェクトが値渡しされるのか参照渡しされるのか、というのはよくある「落とし穴」の質問であり、答えは「どちらでもない」です。
オブジェクト参照 が値渡しされます。)
プリミティブ型の値集合は、プリミティブ値で構成されます(nullは含まれません)。
参照型の値集合は、オブジェクトインスタンスへの参照、またはnullで構成されます。
前の段落の2つの重要な事実(すべてのオブジェクトには一意のアイデンティティがあり、オブジェクトを操作する唯一の方法は参照を介すること)は両方とも、インライン型を取り込むと変わります。
次の図では、Javaプログラムの変数に格納できる値を強調表示するために、表現可能な値を赤いボックスで示します。
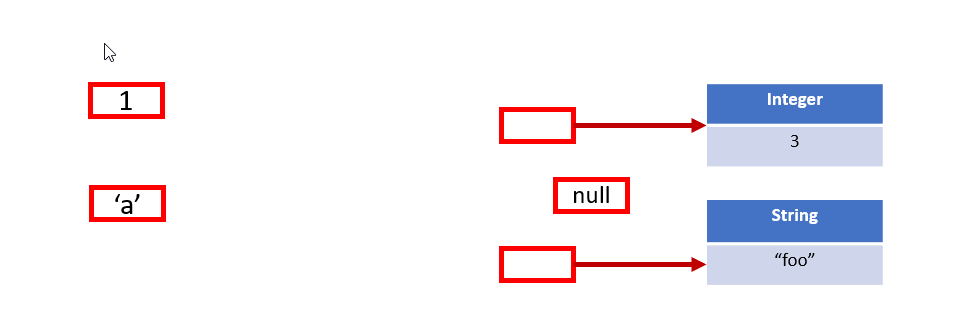
現在の世界における値の宇宙は、プリミティブ値とオブジェクトへの参照で構成されています。
現在の世界を要約すると、以下の通りです。
- 型は、プリミティブ型と参照型に分かれています。
- 参照型は、プリミティブ型ではなく、宣言されたクラス、宣言されたインターフェース、および配列型を含みます。
- プリミティブには対応するラッパー型があり、そしてそれは参照型であり、プリミティブ型とそれに対応するラッパーの間にはボクシングおよびアンボクシングの変換があります。
- プリミティブ型の値集合に
nullが含まれることはありません。 - 参照型の値集合はオブジェクトではなくオブジェクトへの 参照 で構成され、常に
nullが含まれます。 - オブジェクトにはオブジェクトアイデンティティがあります。
準備が整いましたので、言語型システムの中でインラインクラスをどのように収容するかに取り組みましょう。 インラインクラスのモットーは、*「クラスのようにコードを書き、intのように動作する」*です。 このモットーの後半の部分は、インライン型がこれまでに説明したプリミティブ型の実行時の動作と一致しなければならないことを意味しています。 (実際、私たちはプリミティブ型をインライン型の傘下に入れたいと考えています。すでに二分割されている型システムをより多くのカテゴリに分割することは望ましくありません)。
インラインクラスはクラスのようにコードを書くため、クラスが持つことができるほとんどのものを持つことができます:フィールド、メソッド、コンストラクター、スーパーインターフェース、型変数などです。
inline class Point {
private int x;
private int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int x() { return x; }
public int y() { return y; }
}Valhallaがもたらす最初の大きな違いは、インラインクラスのインスタンス(これを インラインオブジェクト と呼びます)にアイデンティティがないことです。 これは、アイデンティティに依存した特定の操作(同期など)がインラインオブジェクトでは許可されないことを意味します。 混乱を避けるために、従来のクラスを アイデンティティクラス と呼び、それらのインスタンスを アイデンティティオブジェクト と呼びます。
インラインクラスのインスタンスはオブジェクトですが、アイデンティティはありません。
オブジェクトの ID は、とりわけ、 可変性 と レイアウトのポリモーフィズム を可能にする役割を果たします。
ID を放棄することで、インライン・クラスはこれらを放棄しなければなりません。
したがって、インライン・クラスは暗黙的に final で、そのフィールドは暗黙的に final で、そのスーパータイプには制限があります。
(それらはインターフェイスを実装したり、いくつかの抽象クラスを拡張したりすることができます。)
さらに、インラインクラス V の表現は、直接的にも間接的にも、 V 型のフィールドを含んではいけません。
(しかも、インラインクラスは clone() メソッドや finalize() メソッドをオーバーライドすることはできません。)
Valhallaでは、型をプリミティブ型と参照型に分けるのではなく、インライン型と参照型に分けています。 ここでインライン型はプリミティブを包含します。 「参照型」の意味は固定されたままです:参照型はインライン型ではないものです。 これには、宣言された ID クラス、宣言されたインターフェイス、配列型などが含まれます。 型についての図を更新して、インライン型を含むようにしてみましょう。
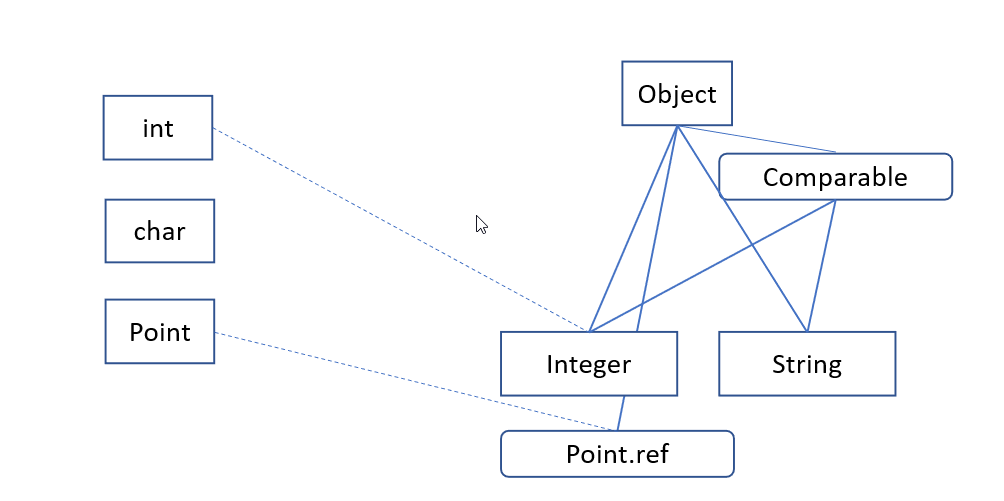
値集合がオブジェクトインスタンスへの 参照 で構成されるアイデンティティクラス(または null )とは異なり、インラインクラス型の値集合は、そのクラスの可能な インスタンス の集合です(プリミティブと同様に、インラインクラスは null不可 です)。
インラインオブジェクトは、現在のプリミティブと同様に直接表現されます。このことを値集合の図に反映しましょう。
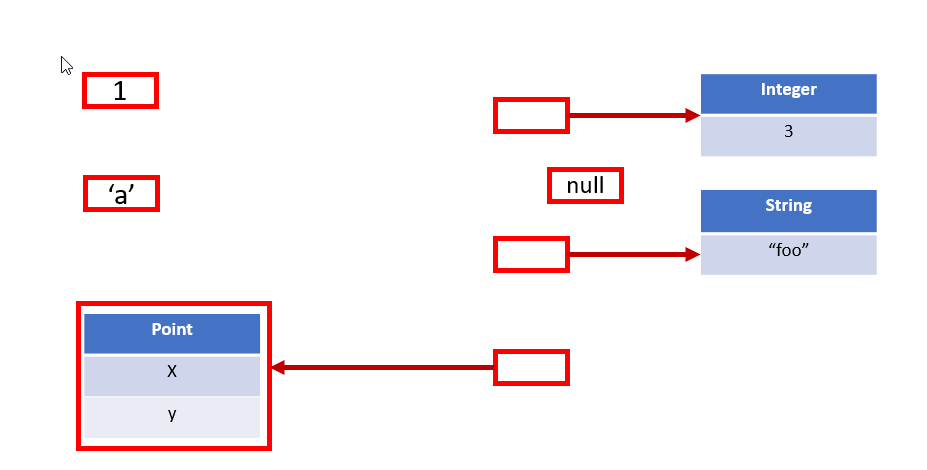
プリミティブと同様に、インラインクラスの値集合は、オブジェクト参照ではなく、そのクラスのインスタンスの集合です。
すべての型は デフォルト値 を持ちます。
プリミティブ型の場合、デフォルト値はある種のゼロ(0, 0.0, false など)です。 参照型の場合、デフォルト値はnullです。
インラインクラスの場合、デフォルト値はその型のインスタンスのうち、すべてのフィールドがそれぞれの型のデフォルト値を取るものです。
クラス型 C の場合、 C のデフォルト値を C.default と記載するでしょう。
(ジェネリックなコードでは、 T.default と記載するでしょう。型消去によるジェネリクスの場合、 T は常に参照型であるため、これは null と評価されます。
ジェネリクスが特殊化される場合は、T.default も特殊化されます。)
コンパイル時と実行時にインラインクラスとアイデンティティクラスを区別するために、 制約付きインターフェースのペアであるIdentityObjectとInlineObjectを導入します。
インラインクラスは暗黙的にInlineObjectを実装します。アイデンティティクラスは暗黙的にIdentityObjectを実装します。(両方を実装しようとするとエラーになります。)
これにより、アイデンティティに依存する操作を実行する前にオブジェクトのアイデンティティを動的にテストするコードを作成できます。
if (x instanceof IdentityObject)) {
synchronized(x) { ... }
}同様に、可変型(およびジェネリック型の境界)での同一性の要求を静的に反映しています。
static void runWithLock(IdentityObject lock, Runnable r) {
synchronized (lock) {
r.run();
}
}現在の世界では、プリミティブ型ごとに == が定義されており、参照型では、2つの値が == となるのは、両方がnullであるか、同じオブジェクトへの参照である場合です。
現在、すべての参照はアイデンティティを持つオブジェクトを指しているため、オブジェクトアイデンティティを使用して「同じオブジェクト」を定義できます。
コンポジションを用いて == をインラインオブジェクトに拡張できます。
2つのインラインオブジェクトが == となるのは、2つが同じ型で、それぞれのフィールドについて、全てのペアがフィールドの静的型の == に従って等しい場合です
( float および double を除きます。これらは、 Float::equals および Double::equals のセマンティクスに従って比較されます)。
この定義では、2つのインラインオブジェクトが 置換可能 、すなわち違いが識別できない場合にのみ等値であると言います。
インターフェース I を実装する任意のクラス X (インラインまたはアイデンティティ)の場合、 X の配列に対して次のサブタイプ関係が保持されます。
X[] <: I[] <: Object[]
現在、いくつかの操作はオブジェクトアイデンティティの観点から定義されています。 これらの一部は、すべてのオブジェクトインスタンスを対象とするように適切に拡張できます。 残りの操作は部分的になります。 これらには以下が含まれます。
- 等値性。
Object上で==を全域化します。 つまり、現在において意味がある場合、新しい定義はその意味と一致します。 (次のセクションで説明するように、インラインオブジェクト への参照 に関連する追加の作業がいくつかあります。) - System::identityHashCode。
identityHashCodeの主な用途は、IdentityHashMapなどのデータ構造の実装です。 等値性を全域化するのと同じ方法でidentityHashCodeを全域化できます - すべてのフィールドのハッシュからインライン・オブジェクトのハッシュを導出します。 - 同期。 これは部分的な操作になります。 同期が実行時に失敗することを静的に検出できる場合(インラインクラスで
synchronizedメソッドを宣言するなど)、コンパイルエラーを発行できます。 そうでない場合、インラインインスタンスをロックしようとすると、実行時にIllegalMonitorStateExceptionとなります。これが正当化できるのは、対象オブジェクトのロックプロトコルを明確に理解していないのにそれをロックするというのは本質的に不注意によるものだからです。任意のObjectまたはインターフェースインスタンスをロックするというのは、まさにそういうことなのです。 - Object::wait および Object::notify。 同期と同じです。
- 弱い参照。 これについてはどちらにすることもできます。
Objectの弱参照を作成することを部分化もできますが、これは厄介な結果になります:弱参照はほとんど役に立たなくなります。なぜなら、何らかの弱いデータ構造を維持したいすべてのクラスは、アイデンティティオブジェクトとインラインオブジェクトの別々のパスに分岐する必要が出てくるためです (これはidentityHashCodeの部分化に似ています)。一方、単純な動作(インラインオブジェクトを保持する弱参照は決して消去されないなど)を選択すると、初めは存在していた、弱参照を使用する目的となるGCフレンドリーな振る舞いの一部が失われます。この件はさらなる分析が必要です。
これまでのところ、「プログラム可能なプリミティブ」に非常によく似たインライン型を構築してきました。 しかし、プリミティブの最大の欠点は、静的にも動的にも、プリミティブとオブジェクトの間ではっきり分かれている点です。 「プログラム可能な」部分は、インライン型がメンバーとスーパータイプを持つことができるという点で、いくつかのギャップを狭めます。 しかし、このギャップをさらに狭くしたいと思います。
現在の世界では、 ボクシング変換を介してプリミティブ型から参照型に変換しています。 これは、より多くの多態的なコードを書くことができるので便利です。
サブタイプまたはボクシングを介して、任意の値を Object で表すことができます。
しかし、ボクシングにはいくつかの重大な欠点があります。
ボックス型は、特注の手作りクラスであり、プリミティブ型への言語的接続は限られています - これは、インラインクラスに確実に対応しません。
さらに悪いことに、結果のボックスには「偶発的な」オブジェクトアイデンティティがあり、多くのVM最適化の妨げになります。
「ボクシングは遅い」という信念は、この偶然のアイデンティティに由来するものです。
私たちがやりたいのは、実行時のアドホックで軽量な方法でインライン型の世界を参照型の世界に接続することです。
インラインクラスの値集合はオブジェクトインスタンスで構成されますが、アイデンティティクラスの値集合はオブジェクトインスタンス への参照 で構成されます。 この表現の違いは、現在の世界のプリミティブとオブジェクトの違いの主な原因の1つです。
インラインクラスを型システムの残りの部分に接続し、インターフェースを実装して Object を拡張できるようにします。
しかし、インターフェース I 、 I を実装するアイデンティティクラス C 、および I を実装するインラインクラス V があるとします。
I の値集合は I ですか? 明らかに、 C と V の両方の値集合を含める必要がありますが、これらの集合は構造的にまったく異なります。
一方にはオブジェクトが含まれ、もう一方にはオブジェクトへの参照が含まれます。 これは、橋渡しする必要があるオブジェクトとプリミティブの分断です。
現在の世界は、これを不器用にボクシングで埋めています。 より均一で軽量な方法で橋渡しをしたいと考えています。
インターフェース(および Object )は参照型です。つまり、値集合はオブジェクト参照で構成されている必要があります。
それが、Valhallaの次の大きな違いにつながります。
すなわち、アイデンティティオブジェクトを操作できるのは参照を介してのみですが、インラインオブジェクトでは、直接またはオブジェクト参照を介して、 どちらの方法でも 操作および保存できます。
Valhallaの値の宇宙は、プリミティブ値、インラインオブジェクト、およびアイデンティティオブジェクトとインラインオブジェクトの両方への参照で構成されています。
Valhallaでは、 インライン拡大変換 を介してインラインから参照型に変換します。 これはボクシングと似ていますが、大きな違いがあります:
変換の結果は(ボックスのように)アイデンティティオブジェクトではなく、 インラインオブジェクトへの参照 です。
(結果の Object で Object::getClass を呼び出すと、ボックス型ではなく、元のインラインオブジェクトのクラスが報告されます。)
これにより、VMの最適化能力を損なうことなく、インライン型と参照型の間で必要な相互運用が可能になります。
インライン拡大変換は、ボクシングのパフォーマンスの欠点をほとんど伴わずに、ボクシングの望ましいセマンティクスを提供します。
演算子 ref v は、 v がインラインオブジェクトの場合は v への参照として定義し、 v が既にオブジェクト参照である場合は v 自体として定義すると便利です。 そうすれば、 ref はすべての表現可能な値の全域で定義され、常に参照を返します。 (逆の演算子 unref は部分的であり、インラインオブジェクトへの参照にのみ適用され、2つは 射影と埋め込みのペア を形成します。)
インライン拡大変換は、インライン型からそれが実装する任意のインターフェースおよび Object に存在し、 ref 演算子の適用として定義されています。
これにより、 I の値集合に関する質問に答えることができます。
これには、 C のすべてのインスタンスへの参照と、 V のすべてのインスタンスへの参照が含まれます。
インターフェース(および
Object)の値集合は、値nullに加えて、アイデンティティまたはインラインオブジェクトのいずれかであるオブジェクトへの参照で構成されます。 インターフェースまたはObjectインスタンスでアイデンティティに依存する操作を実行すると、実行時に失敗する場合があります。
この時点で、読者は単に用語のトリックを演じただけ、含意のある用語「ボクシング」をまだ含意のない用語「インライン拡大」に置き換えただけではないかと疑問に思うかもしれません。 実施したのが単に名前の変更だけなのであれば、それは確かにトリックになります。 インライン拡大が単に名前変更されたボクシングではない理由は、Valhalla JVMでは、インライン拡大および縮小変換が、対応するボクシングおよびアンボクシング変換よりもはるかに軽いためです。 ボクシングの問題は、アドホック(訳注:プリミティブという限られた型のみに定義されていること)であり、コストがかかることです。 私たちはこれらの両方の懸念に対処しようとしています。
インライン・クラスはインタフェースを実装することができます。任意のクラスを拡張することはできませんが、抽象クラスの限られたカテゴリを拡張することができます。つまり、フィールドを持たず、本体が空である引数なしコンストラクタを持ち、それ以外のコンストラクタを持たず、インスタンス初期化子はなく、同期メソッドを持たず、そのスーパークラスがすべて同じ条件を満たしているクラスです(Object と Number はそのようなクラスの例です)。
与えられたインラインクラスのオブジェクトへの 参照 の集合に null を加えて記述できると便利なことがよくあります。
インライン型 V が与えられたとき、値の集合が次のように与えられる参照型 R が欲しいと思います。
ValSet(R) = {null} ∪ {ref v : v ∈ ValSet(V)}
このような型 R を V の 参照射影 と呼びます(参照型は、それ自身の参照射影です)。
参照射影は、現在の世界ではラッパークラスが果たす役割を担っています。しかし、すべてのインラインクラスに手書きのアドホックなラッパーを持たせたくはありません。
インラインクラスから参照射影を機械的に導出し、それを参照するための統一された方法を持ちたいのです。
そうすれば、インラインクラスとその参照射影を対応付けたメンタルディクショナリを維持する必要はありません。
任意の型 T に対して、T.ref は T の参照射影を表します。
インライン・クラスの場合、参照射影と値射影の両方を自動的に作成します。
インラインクラス V の場合、V.ref は V の参照射影(V のインスタンスへの参照の集合に null を加えたもの)を記述する型であり、V.val は V の値射影(V のインスタンスの集合)を参照します。
そして(後で述べるような特別な申し立てがない場合は) V は V.val のエイリアスです。
(この参照射影は、V.val のみをサブタイプとして許可するシールされた抽象クラスです。)
つまり、抽象クラス C を拡張したインラインクラス V の場合、以下のようになります。
sealed abstract class V.ref
extends C
permits V.val { }
inline class V.val extends V.ref { }そして、V は V.val のエイリアスになります。
(この種のエイリアスは新しいものではありません。Stringはjava.lang.Stringのエイリアスです。)
V.valからV.refへのインライン・ワイドニング変換が自動的に行われます(したがって、V から V.ref への変換も行われます)。
さらに、V.ref から V.val へ(したがって、V.refからVへ)のインラインナローイング変換を定義します。
それは unref演算子を適用するもので、nullに対してはNullPointerExceptionをスローします。
この一対の変換によって、インラインクラスは、歴史的にラッパー型とプリミティブがそうであったように、参照射影と同じ関係を持ちます。 ボクシング変換(オートボクシング、条件式の型付け、オーバーロードの選択)の観点から定義されている既存のルールは、インラインの拡大と縮小の変換を組み込むために、簡単に拡張することができます。 その結果、既存の言語ルールと、これらの変換に関するユーザーの直感は、新しい世界でも変更されることなく前進することができます - しかし、ボックス化の実行時間コストはありません。 なぜなら、現在のボクシングのように、インラインの拡大は偶然のアイデンティティを持つ新しいオブジェクトの生成を強制するものではないからです。
参照型 R はすでにそれ自身の参照射影であるためのすべての要件を満たしているので、
参照型 R については、 R.ref を R 自身のエイリアスにします。
これで、すべての型 T が T.ref と呼ばれる参照射影を持つことが保証されました。
インラインクラス V は、2つの型(V.ref と V.val 、それに型エイリアス V)を生成します。
そして同じく、2つのクラスミラーも生成されます。
しかし、参照射影は抽象クラスなので、どのインスタンスもそれが参照射影のインスタンスであることを報告することはありません。
V の値への非null参照は、V.valのインスタンスであることを報告します。
歴史的には、クラスがインターフェースを実装することはいくつかのことを意味していました。
- 適合性。 クラスには、メンバーとして、インターフェースのすべてのメンバーがあります。
- 推移性。 このクラスのサブクラスもインターフェースを実装します。
- サブタイピング。 クラス型は、インターフェース型のサブタイプです。
インラインクラスをサポートするために、この最後の箇条書きであるサブタイピングを少しだけ洗練させる必要があります。 インライン・クラスの 参照射影 は、インターフェース・タイプのサブタイプであると言います。 (アイデンティティクラス型はそれ自身の参照射影なので、この宣言はすべてのクラスに適用されます。) 同様に、インラインクラスが抽象クラスを拡張している場合、参照射影は抽象クラスのサブタイプであることを意味します。
Object には、すべてのクラス、インライン、およびアイデンティティのルート型としての役割があるため、インターフェースと多くの特性を共有しています。
既に述べたように、すべてのインライン型から Object へのインライン拡大変換があります。
ただし、 Object は具象クラスであるため、残念ながら、コンストラクターを介して Object 直接インスタンス化することは可能です。
インターフェースは継承されるため、 Object は InlineObject も IdentityObject も実装できません。
ですが、 new Object() によるインスタンス化の結果はアイデンティティ型のインスタンスである必要があります(他の理由で Object をインスタンス化するポイントがないため)。
この罠からはいずり出るには、手の込んだ動きが必要です。
まずは IdentityObject を返す静的ファクトリー Object::newIdentity を作成し、
それから、さまざまなツール(コンパイラー警告やJITのマジックなど)を使って、既存のソースおよびバイナリーでの new Object() の使用をそちらに移行しようとすることから始めましょう。
そして最終的には、直接インスタンス化するための Object コンストラクターを( protected にしてしまうことで)「廃止」するのです。
インラインオブジェクトの == 拡張は完了していません。
インラインオブジェクト自体に対しては定義しましたが、参照型で、値集合の中にインラインオブジェクトへの参照を持つ可能性のあるものについてはまだ定義していません。
これについて、2つのオブジェクト参照が等しいとは、両方ともnullであるか、同じアイデンティティオブジェクトへの参照であるか、または == が成立する2つのインラインオブジェクトへの参照である場合とします。
これにより、 == の 代入可能性 のセマンティクスがすべての値に拡張されます。
すなわち、2つの値は、 NaN が持つ従来の動作を除いて、どのような方法でも区別できない場合にのみ == です。
これにより、 == について、次の有用な不変式( NaN の従来の動作を除くすべてで成り立つ)が得られます。
==は反射的、すなわちすべてのvに対してv == vです。- 2つのインライン値が参照に拡大されるとき、元の値が
==だった場合にのみ、結果も==となります。 - 2つの参照がインラインオブジェクトに縮小されるとき、元の参照が
==だった場合にのみ、結果も==となります。
Object::equals の基本実装は、 == に委任します。
Object::equals を明示的にオーバーライドしないインラインクラスでは、それがデフォルトです。
(同様に、 Object::hashCode の基本実装は System::identityHashCode に委任します。これもデフォルトです。)
参照射影の定義は意味があり、参照型との関係についての既存の直観と一致していますが、これらの型が非常に重要である 理由 をまだ十分に動機付けていません。
インライン型を使用できない場合は次のようにいくつかあります。
- 無効値。 Nullはインライン型の値ではなく、すべての参照型の値ですが、「V型のnull値を許可する値」という概念を表現したい場合もあります。
- 非平坦化。 インライン値はオブジェクトと配列に規則正しくフラット化されます。 通常、これは私たちが望むものです。 ただし、場合によっては、メモリー使用率をより細かく制御する必要がある場合があります。たとえば、「幅の広い」インラインクラス(多くのフィールドを持つクラス)があり、それらの疎な配列が必要な場合などです - 平坦化された値の配列よりも、参照の配列の方がメモリーを効率的に使える場合があります。
- 再帰表現。 インラインクラスは、表現について自分自身に再帰的に依存することはできません。 通常、これは重大な制限ではありませんが、参照型でこれをシミュレートしたい場合もあります(たとえば、「次の」フィールドを持つ
Nodeクラス)。 - 型消去によるジェネリクス。 既存の型消去ジェネリクスは、型パラメーターが参照型であることを前提としています - アイデンティティ依存の操作や、null値などが許可されます。特殊化されたジェネリクスが使えるようになって、インライン型と型消去ジェネリクスの相互運用ができるようになるまで、型パラメーターには参照型を使用したいのです。
- 妥当なゼロがない場合。 インライン型のデフォルト値は、すべてのフィールドがデフォルト値をとる値です。 一部の型では、この値は妥当です(
Pointのデフォルト値として(0, 0)は妥当です)が、場合によっては(Rationalなど)、この値は無意味か、または危険ですらあります。 そういった場合は、初期化されていない値を表すためにnullを使用できるように、参照型を使用したいこともあります。
これらすべての状況で、インライン型の代わりに参照型を使用できます。
ただし、 Object などの広い参照型を使用すると、多くの損失が発生します - 型安全性が失われ、クライアントはインラインの世界に戻るためにコードに未チェックのキャストを挿入する必要があります。
インライン型に参照射影を使用すれば、インラインの拡大と縮小の変換によって、値集合が特定のインラインクラスの値集合と密接に結び付けられた参照型があり、明示的な変換を使用せずにそのインラインクラスに自由に変換できます – これにより、私たちが望む型の安全性と利便性が救われます。
例として、特殊なインスタンス化をサポートするために Map インターフェースを移行する問題を考えてください。
Map::get メソッドは、要求されたキーがマップに存在しない場合は null を返しますが、 Map の V パラメーターがインライン型の場合、 null は値集合のメンバーではありません。
get() メソッドを以下のように宣言すれば、これを捕捉できます。
public V.ref get(K key);これは、 Map::get の戻り値の型が V への参照か、または null 参照のどちらかになるという概念を捉えています。
これまでに説明した手法は新しいコードには十分ですが、準備しておきたい移行シナリオがいくつかあります。
値ベースのクラスがすでにいくつも存在していて、それらはインラインクラスへのスムーズな移行を可能にするために設計された一連の制限を満たしています。
そのような例の1つに java.util.Optional があります。これは、Java 8にインラインクラスがあったとしたならインラインクラスとして宣言できたはずです。
Optional をインラインクラスに移行して、インラインクラスの実行時の利点を活用したいと思います。
( java.util.time パッケージのクラスも同様の状況にあります。)
既存のクライアントには、変数の型、メソッドのパラメーターまたは戻り値の型、型パラメーターなどで、 Optional 型が多数使用されています。
これらのクライアントはすべて、 Optional が参照型であると想定しており、参照型はnull可能です。
したがって、 Optional を直接インライン型に移行することはできません。
次善策は、 Optional を何らかのインライン・クラスの参照射影として定義することです。
これは、Optional を抽象クラスに移行し、ただ一つのインラインクラス(値射影 Optional.val)だけ許可するようにシールされるように手配することを意味します。
この移行後、 Optional の インスタンス はアイデンティティクラスではなくインラインクラスになりますが、既存のコードは引き続き、参照を介して Optional 値を格納したり渡したりします。
それらを直接表現することが実際に違いを生むのは、それらがヒープに出会う場所、つまりフィールドと配列要素です。
そしてそこでは、 Optional のそれら特定の用途を Optional.val に自由にかつ段階的に移行できます。
インラインの拡大と縮小の変換によって、フィールドまたは配列を Optional から Optional.val に変更するのは、ソース互換の変更になります。
既存のAPIは、参照射影である Optional を引き続き使用する可能性が高いでしょう。
このトリックを達成するために、Optional のインライン・クラスを宣言して参照射影 Optional.ref と値射影 Optional.val を生成したいのですが、エイリアス Optional を逆にして値射影ではなく参照射影を参照するようにしたいのです。
これは、宣言を修正して ref-defaultインライン・クラス であることを示すことで実現できます。
ref-default inline class Optional<T> {
// current implementation of Optional
}ref-default修飾子が持つ唯一の効果は、装飾されていない型名が指し示すのは、2つの射影のうちどちらかを決定することです。
このような移行から生じる可能性のある非互換モードが1つあります - クライアントが getClass() の結果と Optioinal.class を比較する場合です。
移行前は、 Optional インスタンスは Optional.class クラスを持っています。
Optional が抽象クラスに移行されると、 Optional インスタンスは 自分自身が値射影 Optional.val のインスタンスであると報告するでしょう。
M.classの使用を取り巻くこの非互換性は、ここで概説する移行アプローチの主要な互換性コストです。これは、getClass()の結果とインターフェースや抽象クラスのクラスリテラルとを==で比較するときにコンパイル警告を発行することで多少緩和できます。実行時に失敗することがわかっているためです。
インライン型にプリミティブの抽象化という役割を割り当てましたが、実際にプリミティブをインライン型に包含できるようにするために、さらに作業が必要です。
ラッパー型である Integer とその仲間たちを、Optional の移行と同じ手法を用いて、シールされた抽象クラスに移行することから始めます。
これらのインターフェイスは、プリミティブの参照射影になります。
これを行うには、まず、プリミティブラッパーのアイデンティティへの依存性をユーザーから解放しなければなりません。
これを行うには、パブリックなコンストラクタを非推奨にして(実際には削除するのではなくプライベートになります)、移行期間中はInteger のインスタンスを「永久にロックされた」状態にします(ここでのアプローチについては JEP 169 を参照してください)。
この動きは、プリミティブラッパーのアイデンティティに依存するコードを壊すリスクがあります。代入可能性を持った
==の定義を考えれば、==による比較はほぼ問題になりませんが、ラッパーをロックするコードは実行時に失敗するでしょう。
その後、プリミティブ型をインラインクラスとして明示的に宣言できます。
inline class int { /* implementation */ }自己参照については明らかに多少の調整を行う必要がありますし、レガシーラッパーの名前をプリミティブに合わせるために、さらにいくつかの修正を加えましたが、今や、 int にスーパーインターフェースとインスタンスメソッドを追加するのも自由ですし、通常はクラスのように扱うことができます。
参照射影 int.ref は Integer のエイリアスになっていて、 Integer.val は int のエイリアスになっています。
2つの型の関係は、移行された値ベースのクラスの場合と同じです。
プリミティブが真のインライン型である場合でも、配列の間には引き続き以下のサブタイピング関係があります。
int[] <: Integer[] <: Object[]
次に、int と Integer の間で定義された2組の変換を調整しなければなりません。
既存のボクシング変換と、新たなインライン縮小・拡大変換です。
しかし、便利なことに、ラッパークラスの偶発的なアイデンティティ(非推奨です)を除き、これらは同じセマンティクスを持つように定義しています。
ボクシングは、ランタイムが規則正しい最適化によって除去することがより単純になりますが、その一方で、変換や、オーバーロード選択や、推論にまつわるすべての既存ルールは維持されます。
同様に、オーバーロード選択でのボクシングの役割を一般化して、インラインの拡大と縮小を代わりに使用できるため、この移行ではオーバーロード選択の決定方法は変更されません。
ジェネリクスは現在、単一の参照に型消去されます。
いずれはジェネリクスがその表現を特殊化できるようにして、 ArrayList<Point> のようなジェネリック型も Point[] がもたらす平坦化と密度の利点を得ることができるようにしたいと思っています。
これには追加の時間がかかり、移行互換性の問題がさらに発生します。
ArrayList を特殊化可能な型に移行しても、既存のクラスファイルは 型消去による ArrayList への参照が多く残されたままでしょうから、これらは引き続き動作する必要があります。
将来の機能として、特殊化されたジェネリクスの余地を残そうとしています。
現在の型消去されたジェネリクスは、参照型でのみ機能し続ける可能性があります。
List<int> や Optional<Point> などの特殊化された型については、将来的に自然な表記法を予約したいと考えています。
これを行うには、型消去されたジェネリクスでは、参照型のみが型引数として有効であることを要求します。
今日、人々は List<Integer> と書いています。
これは List<int.ref> および List<Point.ref> と一般化されます。
私たちが取ったアプローチは、プリミティブと参照における既存の分断構造を維持する一方で、より規則的でパフォーマンスの高いものにすることです。 ボクシングはずっとコストが低くなって影の中に遠ざかり、「インライン」は「プリミティブ」の新しい言葉であり、プリミティブの集合は拡張可能です。 私たちは「重いボクシングを伴う参照とプリミティブ」から「軽いボクシングを伴う参照とインライン」に移行しましたが、2つの世界はほぼ同型のままです。
| 現在の世界 | Valhalla |
|---|---|
| 参照とプリミティブ | 参照とインライン(プリミティブはインライン) |
| プリミティブにはボックスがあります | インラインには参照射影があります |
| ボックスにはアイデンティティがあり、 getClass() で表示されます | 参照射影は実行時に表示されません |
| ボクシングとアンボクシングの変換 | インラインの縮小拡大変換、ただしルールは同じ |
| プリミティブは組み込みで、魔法 | プリミティブはほとんど単なるインラインクラスで、追加のVMサポートを備えています |
| プリミティブにはメソッドもスーパータイプもありません | プリミティブはインラインクラスであり、インラインクラスにはメソッドとスーパータイプがあります |
| プリミティブ配列は単相です | インライン配列は多相です |
A First Look at Java Inline Classes https://www.infoq.com/articles/inline-classes-java/