原題:Dynamo: Amazon’s Highly Available Key-value Store
原文: Amazon's Dynamo - All Things Distributed (PDF Version)
This article is translated by @ono_matope. Please contact me if any problem.
Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall and Werner Vogels
Amazon.com
大スケールでの信頼性は、我々が世界最大のe-commerceサイトであるAmazon.comで直面した最大の挑戦の一つでした。ほんのわずかなサービス停止でさえ甚大な金銭的影響や顧客の信頼へのインパクトが発生するためです。世界中の多くのWebサイトにサービスを提供しているAmazon.comプラットフォームは世界中のデータセンターに配置された数万のサーバーとネットワークコンポーネントによる単一のインフラ上に実装されています。この規模において、大小のコンポーネントは絶え間なく壊れ、これらの障害を見越した永続化の方法がソフトウェアシステムの信頼性とスケーラビリティを実現します。
この論文では、いくつかのAmazonのコアサービスが"always-on"体験を提供するために利用している高可用性key-valueストレージシステムDynamoの設計と実装を説明します。このレベルの可用性を実現するため、Dynamoは特定の障害シナリオ下で一貫性を犠牲にしています。これはオブジェクトバージョニングとアプリケーションアシストによる衝突解決の使い方を開発者に取って斬新なインターフェイスで押し広げます。
D.4.2 [Operating Systems]: Storage Management; D.4.5 [Operating Systems]: Reliability; D.4.2 [Operating Systems]: Performance;
Algorithms, Management, Measurement, Performance, Design, Reliability.
Amazonは世界中のデータセンターに配置された数万サーバーを使い、ピーク時数千万カスタマーに応答するワールドワイドなe-commereプラットフォームを展開しています。Amazonプラットフォームにはパフォーマンス、信頼性、効率性の観点での運用上の厳しい要件が存在し、継続的な成長をサポートするためにプラットフォームは高度にスケーラブルである必要があります。特に信頼性は一番重要です。わずかな停止でさえ、多大な金銭的影響と顧客の信頼にインパクトをもたらすからです。加えて、継続的な成長のために、プラットフォームは高度にスケーラブルである必要があります。
我々がAmazonプラットフォームの運営で学んだ事の一つは、システムの信頼性とスケーラビリティはそのアプリケーションの状態がどのように管理されているかに依存するということです。Amazonは数百のサービスからなる高度に分散管理された、疎結合で、サービス指向アーキテクチャを利用しています。このような環境では、常に利用可能なストレージ技術へのある特定のニーズが存在します。たとえば、顧客は例えディスクが壊れていようが、ネットワーク経路が断線しようが、データセンターが竜巻で破壊されようが、彼らのショッピングカートを閲覧したり、アイテムを追加したりできるべきです。したがって、ショッピングカートの管理を受け持つサービスは、いつでもそのデータストアから読み書きできて、複数のデータセンター間で利用可能だという要件が求められます。
数百万のコンポーネントで構成される単一のインフラの中で障害を取り扱うというのは、私たちにとって運用の平常モードです。少数とはいえ大変な数のサーバーやネットワークコンポーネントが常に障害を起こしています。Amazonのようなソフトウェアシステムは、障害を一般的な事態と捉え、可用性やパフォーマンスへの影響なく取り扱うことが求められます。
信頼性とスケーリングのニーズを満たすため、Amazonは多くのストレージ技術を開発してきましたが、おそらくAmazon Simple Storage Service(Amazonの外でもAmazon S3として知られている)がもっともよく知られているでしょう。この論文は、Amazonのプラットフォームのために開発されたもう一つの高可用性・スケーラブル分散データストアであるDynamoの設計と実装を説明します。Dynamoは非常に高い信頼性要件をもち、可用性、一貫性、コスト効率性、そしてパフォーマンスに関するタイトなトレードオフを必要とするサービスの状態を管理するために使われています。Amazonのプラットフォームには、異なるストレージ要件を持つ多様なアプリケーションが存在します。一部のアプリケーションは設計者がある程度のコスト効率性の中で高可用性とパフォーマンス保つのに適切なトレードオフをするのに充分な柔軟性を備えたストレージ技術を求めています。
Amazonのプラットフォームにはデータストアに主キーアクセスしか必要ないサービスが沢山あります。これらベストセラーリスト、ショッピングカート、カスタマー設定、セッション管理、セールスランク、製品カタログのような多くのサービスにとって、リレーショナルデータベースを利用する一般的なパターンはスケールと可用性の非効率と制限を招きます。これらのアプリケーションの要件に適合するため、Dynamoはシンプルな主キーのみのインターフェイスを提供します。
Dynamoはスケーラビリティと可用性を達成するよく知られた技術の統合を用います:データはコンシステントハッシング[10]でパーティショニングとレプリケーションされ、オブジェクトバージョニング[12]によって一貫性が達成されています。更新中のレプリカ間の一貫性はquorumライクな技法と分散されたレプリカ同期プロトコルで保たれています。Dynamoはgossipベースの分散障害検知とメンバーシッププロトコルを採用しています。Dynamoは人間による管理が最小限しか必要ない、完全に分散管理されたシステムです。ストレージノードは手動パーティショニングと再分散を全く必要とすることなくDynamoに追加したり除外したりできます。
過去数年、DynamoはAmazonのeコマースプラットフォームのたくさんのコアサービスを支えてきました。それにより、忙しいホリデイショッピングシーズンの期間中もひとつのダウンタイムも無く厳しいピーク負荷を効果的にスケールすることができました。例えば、ショッピングカートを保持するサービス(Shopping Cart Service)は一日で300万チェックアウトを達成する1000万リクエストを受け、セッション状態を管理するサービスは10万並列のアクティブセッションをハンドリングしました。
この仕事の研究コミュニティに対する主な貢献は、どのように異なった技術を一つの高可用性システムとして組み合わせて提供するかという評価です。それは結果整合性ストレージシステムが酷使されるアプリケーションとしてプロダクション運用出来るという論証です。それはまたパフォーマンス要件が非常に厳密なプロダクションシステムの要件を満たすこれらの技術のチューニングに対する洞察も提供します。
この論文は次のように構成されます。第2章で背景を説明し、第3章では関連研究を示します。第4章ではシステムデザインを説明し、第5章では実装を記述します。第6章ではDynamoのプロダクション運用によって得られた経験と洞察を詳説します。第7章はこの論文のまとめです。この論文では追加情報が的確に掲載されている箇所が沢山ありますが、Amazonのビジネス上の都合で詳細をぼかして書いてあるところもあります。このような理由で、第6章のデータセンター内/外レイテンシー、第6.2章の絶対リクエストレートと第6.3章の停止の長さとワークロードは絶対値のかわりに統計的計測で提供されています。
Amazonのe-commerceプラットフォームは決済、不正検知に至るまで様々な範囲の機能を協調動作して提供する数百のサービスから構成されており、お互いはネットワーク越しによく定義されたインターフェイスでやりとりされます。それらは世界中のデータセンターに配置され、ステートレス(他サービスへのアグリゲーション)であったり、ステートフル(レスポンスを生成するビジネスロジック)であったりします。
伝統的なプロダクションシステムは状態をリレーショナルデータベースに保存します。しかし状態永続化のより共通な利用パターンにとって、RDBは理想からはほど遠いです。これらのサービスのほとんどはデータを主キーで保存/取得しており、RDBMSが提供する複雑なクエリや管理機能は不要です。この過剰な機能は高価なハードウェアや高スキルな運用技術者を必要とし、非常に非効率的なソリューションにしてしまいます。加えて、利用可能なレプリケーションテクノロジーは限られ、可用性より一貫性を選択しているものばかりです。近年の大きな進歩に関わらず、それはまだ容易にスケールアウトしたり不可分散のためにスマートパーティショニングをしたりできるデータベースではありません。
この論文はDynamoを、これらの重要なサービスのニーズを解決する高可用性データストレージ技術として説明してゆきます。Dynamoはシンプルなkey/valueインターフェイスを持ち、明確に定義された一貫性ウィンドウによる高度な可用性があり、効率的にリソースを使用し、データセットのサイズやリクエストのレートの成長に対処可能なシンプルなスケールアウトスキームを持っています。Dynamoを利用する各サービスは、それぞれのDynamoインスタンスを運用します。
このクラスのサービスのためのストレージシステムには、次のような要件があります。
クエリモデル:キーによって一意に識別されるデータアイテムのためのシンプルなreadとwriteのオペレーション。状態はユニークキーによって識別されるバイナリオブジェクト(つまりblob)としてストアされます。複数のデータアイテムにまたがるオペレーションは存在せず、リレーショナルなスキーマは必要ありません。この要件はAmazonのサービスの大部分はシンプルなクエリモデルで動作可能でリレーショナルスキーマが不要だという観察に基づいています。Dynamoは比較的小さな(通常1MB以下)オブジェクトをストアするアプリケーションをターゲットにしています。
ACID特性:ACID(Atomicity, Consistency, Isolation, Durability)はデータベーストランザクションが信頼出来るプロセスであることを保証する特性の組み合わせです。データベースの文脈においては、単一の論理オペレーションはトランザクションと呼ばれます。Amazonでの経験は、ACID保証の提供は貧弱な可用性につながりがちであると示しています。この事は産業界学術界の両方に広く知られています。Dynamoは、高い可用性を達成するために弱い一貫性(ACIDの"C")で運用されるアプリケーションをターゲットにしています。Dynamoはいかなる分離性保証も提供しませんし、単一キーの更新しか許可しません。
効率性:このシステムは普通のハードウェアインフラストラクチャ上で機能する必要があります。Amazonのプラットフォームでは、サービスは一般的に分布の99.9パーセンタイルで計測される厳しいレイテンシ要件を持っています。そのような厳しいSLAを満たす能力のあるストレージシステムはサービス運用に取って決定的な役割です。サービスはレイテンシとスループットを恒常的に達成するようDynamoを設定出来る事でしょう。そのトレードオフはパフォーマンス、コスト効率性、可用性、そして永続性保証におよびます。
その他の責務:DynamoはAmazonの内部サービスのみで使われるので、その運用環境は非敵対的で、認証や認可と言ったセキュリティ上の要件は存在しないものとします。そのうえ、各サービスは個別のDynamoインスタンスを使うので、その初期設計ターゲットは数百のストレージホストまでスケールします。Dynamoのスケーラビリティの制限と拡張に関係して可能性のあるスケーラビリティについては後の章で論じましょう。
アプリケーションがある時間領域内で機能を提供出来る事を保証するために、そのプラットフォームのそれぞれ、全ての依存性はよりタイトな領域で機能を提供する必要があります。クライアントとサービスはService Level Agreement(SLA)、堅苦しく言えばクライアントとサービスがいくつかのシステム関係の特徴を合意するという契約に従事します。その契約は最重要なものでは、特定のAPIについてのリクエストレートの予測や、それらの条件下でのサービスレイテンシーの予測を含みます。例えば、シンプルなSLAは秒間500リクエストのピーククライアント負荷において300msで99.9%のリクエストのレスポンスを提供するであろうというサービス保証です。
Amazonの分散管理されたサービス指向インフラストラクチャにおいて、SLAは重要な役割を演じます。例えばe-commerceサイトのページリクエストは、概して150以上のサービスにリクエストを送信してそれを構築するレンダリングエンジンが必要です。それらのサービスはしばしば複数の依存性を持ち、それはたびたび他のサービスなので、アプリケーションのコールグラフが1レベル以上になるのは珍しい事ではありません。ページレンダリングエンジンが明確な時間領域でページ配信出来る事を保証するために、コールチェイン内のそれぞれのサービスがそのパフォーマンス契約に従う必要があるのです。
図1はAmazonプラットフォームの概念図を示していますが、動的Webコンテンツは他のたくさんのサービスにクエリを投げるページレンダリングコンポーネントによって生成されています。サービスはその状態を異なるデータストアに保存でき、これらのデータはそのサービス領域の間でのみアクセス可能です。レスポンスの合成を生成するためにいくつかの他のサービスを使ってアグリゲーターを演じるサービスもあります。通常は、それらは広大なキャッシュは使うものの、ステートレスです。

図 1: Amazonプラットフォームのサービス指向アーキテクチャ
業界的にパフォーマンス指向のSLAは平均値、中央値、予想される変動値で記述されるのが普通です。Amazonでは、私たちはこれらのメトリクスは単なる多数の人ではなく経験を積んだ「全ての」カスタマーが良い結果をシステムを構築する事をゴールとするならば不十分だと気づきました。例えば、もし公汎なパーソナライゼーション技術が使われるなら、履歴データの長大なカスタマーほど処理能力を必要として、すなわち得意客のパフォーマンスに影響を与えます。平均や中央値の観点では、宣言されたSLAはこの重要なカスタマーセグメントのパフォーマンスを解決できません。この問題を解決するため、Amazonでは、SLAは分布の99.9パーセンタイルで計測され、表現されます。99.9%という選択は、それ以上の性能の達成にはコストが大きく上昇するというコスト-利益分析によるものです。Amazonのプロダクションシステムでの経験では、このアプローチは平均や中央値ベースで定義されたSLAより概してよい結果を見せてきました。
この論文ではこの分布の99.9パーセンタイルがたくさん参照されますが、これはAmazonエンジニアの顧客体験の観点からのパフォーマンスへの飽くなきフォーカスを反映しています。世間の論文では平均値ばかり取り上げられますが、Amazonのエンジニアリング/最適化は平均値には注目しません。writeコーディネーターの負荷分散など、いくつかの技術は純粋に99.9パーセンタイルのパフォーマンスの制御がターゲットです。
状態管理がサービスSLAの主立った部分になるので、多くの、特に軽量なAmazonサービスにとって、ストレージシステムはSLAの確立に重要です。Dynamoの主なデザイン上の配慮の一つは、サービスに永続性や一貫性などの彼らのシステム特性のコントロールを提供して、機能性、パフォーマンス、コスト効率性のトレードオフをしてもらうことです。
商用システムで使われるデータレプリケーションアルゴリズムは、強一貫性のデータアクセスインターフェイスを提供するため、伝統的に同期的なレプリカコーディネーションを行います。このレベルの一貫性を実現するため、これらのアルゴリズムは特定の障害シナリオにおける可用性とのトレードオフを強いられています。例えば、答えの正しさの不確実さを扱うよりも、データが絶対に正しくなるまで使用不可能にします。レプリケーションデータベースの黎明期から、ネットワーク障害の可能性を取り扱うとき、強一貫性と高データ可用性は同時に達成出来ない事がよく知られていました[2,11]。そのようなシステムとアプリケーションはどのような状況でどの特性が達成されているかに注意を払う必要があります。
サーバーとネットワークが障害を起こしがちなシステムにとって楽観的レプリケーション、つまり変更はバックグラウンドで並行して伝播し、ネットワーク切断されての動作を容認するような技術を使う事で可用性が上昇する可能性があります。このアプローチの課題は、検知して解決しなければならないような変更の衝突を招く可能性があるという事です。この衝突解決のプロセスは二つの問題をはらんでいます。いつ解決するのか、誰が解決するのか。Dynamoは結果整合性をもつデータストアとして設計されていて、つまり全ての更新は全てのレプリカに「結果的に」到達します。
重要な設計上の配慮のひとつは、更新衝突の解決のプロセスをいつ行うのか決める事、つまり、readかwriteの実行中に衝突を解決するべきかどうかです。多くの伝統的なデータストアは衝突解決をwriteの実行中に行い、readの処理をシンプルに保っています[7]。そのようなシステムでは、決められた時間内にデータストアが変更を全て(または大部分)のレプリカに到達できなければ、そのwriteは却下されます。一方、Dynamoは『いつでも書き込み可能 ("always writeable”)』なデータストア(すなわち、writeの可用性の高いデータストア)という設計を目指しています。いくつかのAmazonサービスにとって、カスタマーの更新の却下は顧客体験の貧弱さに直結します。例えば、ショッピングカートサービスは、ネットワークやサーバーの障害の最中であろうがショッピングカートに商品を追加と削除を許さなければなりません。この要件は我々に、writeが決してリジェクトされないことを保障するため、衝突解決の複雑性をreadに押し付けることを強いてきます。
次の設計上の選択は、「誰が」衝突解決のプロセスを実行するのかです。これはデータストアまたはアプリケーションが実行する事が出来ます。データストアがこれを行った場合、その選択はどちらかというと制限されます。そのようなケースでは、データストアは更新の衝突を解決するのに、「最後の書き込みが勝つ("last write wins")[22]」のようなシンプルなポリシーしか使えません。一方、アプリケーションは、データスキーマに注意を払っているので、クライアントにとって最も適した衝突解決の手法を決定する事が出来ます。例えば、カスタマーのショッピングカートを保持するアプリケーションはバージョン衝突に「結合("merge")」を選択して単一の統合されたショッピングカートを返却することができます。この柔軟性にかかわらず、彼ら自身の衝突解決メカニズムを書きたがらず、その仕事をデータストアに押し付けるアプリケーション開発者もいるかもしれませんが、その場合データストアは「最後の書き込みが勝つ」といった簡単なポリシーを順々に選択します。
その他の取り込まれた重要な原則:
線形スケーラビリティ(Incremental Scalability): Dynamoは、システム管理者とシステム自体にとって最小のインパクトで一度にひとつのストレージホスト(以下、"node")をスケールアウト出来るべきです。
対称性(Symmetry): Dynamoの全てのノードは、そのpeerと同等の責務を持つべきです。nodeやnode群には特別な役割や余分な責務セットなどの区別はありうべからざるものです。我々の経験上、対称性はシステムのプロビジョニングやメンテナンスをシンプル化します。
分散化(Decentralization):対称性をさらに拡大し、その設計は集中管理よりも分散化されたpeer-to-peer風であるべきです。過去に集中管理がサービス停止を引き起こしたので、可能な限りそれを避けるのがゴールです。
異種混交性(Heterogeneity):システムはそれが実行されるシステムの異種混交性が利用出来る必要があります。例えば、仕事の分散は各々のサーバーの能力に比例している必要があります。これは、一度に全てのホストをアップグレードすることなしにより高性能なノードを追加するために不可欠です。
データストレージと分散の問題を考察する、いくつかのpeer-to-peer(P2P)システムがあります。FreenetやGnutellaのような第一世代P2Pは、大部分はファイル共有システムとして使われました。peer間でリンクをオーバーレイする非構造化P2Pネットワークは自由に構築されるという例です。これらのネットワークでは、データを共有するpeerが多くなるにつれて検索クエリがネットワークに溢れてしまいます。P2Pシステムは構造化P2Pネットワークとして広く知られる次世代型に進化しました。これらのネットワークは全てのノードが望みのデータを持つpeerまで検索クエリを効果的にルーティング出来るように全体で一貫したプロトコルを採用しました。Pastry[16]やChord[20]のようなシステムはクエリが特定のホップ数以内で回答出来ることを保障するためのルーティングメカニズムを使っています。多段ホップが生む追加のレイテンシを低減するために、各peerがルートリクエストを定数ホップ内で適切なpeerにルーティングするために充分なルーティング情報をローカルに保持するO(1)ルーティングを採用するP2Pシステム[14]もあります。
Oceanstore[9]やPAST[17]のようなさまざまなストレージシステムはこれらのルーティングオーバーレイの上に構築されています。Oceanstoreは広く複製されたデータへのシリアライズドアップデートに対応した、グローバルにトランザクショナルな永続化ストレージサービスを提供します。広域ロッキングが引き起こす多くの問題を回避して平行更新を許可するため、Oceanstoreは衝突解決に基づく更新モデルを採用しています。衝突解決はトランザクションのアボート数を低減するために[21]に導入されました。Oceanstoreは一連の更新を処理し、それら全ての順序を決定し、その順序にそって自動的にそれらを適用することで衝突を解決します。これは信頼性の低いインフラ上でデータをレプリケートする環境のために構築されました。それに比べて、PASTは永続的で不変なオブジェクトのためのPastryの上にシンプルな抽象的レイヤーを提供します。これはアプリケーションがアプリケーション上に必要なストレージセマンティクス(可変なファイルなどの)を構築出来るものと仮定します。
パフォーマンス、可用性、永続性のため、データ分散はファイルシステムやデータベースシステムのコミュニティで広く研究されてきました。フラットな名前空間しかサポートしないP2Pストレージシステムと比べて、大概の分散ファイルシステムは階層的な名前空間をサポートします。Ficus[15]やCoda[19]のようなシステムは高可用性を得るために一貫性を犠牲にしてファイルをレプリケートします。更新の衝突は例によって特別な衝突解決手続きを使って管理されます。Farsiteシステム[1]はNFSのようにいかなる集中管理も使わない分散ファイルシステムです。Farsiteはレプリケーションによって高い可用性とスケーラビリティを達成しています。Google File System[6]はGoogleの内部アプリケーションの状態をホストするために作られたもう一つの分散ファイルシステムです。GFSは、全てのmetadataをホストする単一のマスターサーバーと、データをチャンクに分割してチャンクデータがストアされるチャンクサーバーで構成されたシンプルなデザインを採用しています。Bayouは切断されたオペレーションを許可しデータの結果整合性を提供する分散リレーショナルデータベースです[21]。
これらの中で、Bayou, Coda, Ficusは切断されたオペレーションを許可し、ネットワーク分断や停電のような問題に弾力性があります。これらのシステムは解決の手続きが異なります。例えば、CodaとFicusはシステムレベルの衝突解決を行い、Bayouはアプリケーションレベルの解決を許可しています。これらのシステムと同様に、Dynamoはネットワーク分断の発生中であってもread/writeオペレーションを許可し、更新衝突を異なる衝突解決メカニズムで解決します。FAB[18]のような分散ブロックストレージシステムはサイズの大きなオブジェクトを小さなブロックに分割して、各ブロックを可用性の高いやり方でストアします。これらのシステムと比べて、key-valueストアは以下の理由でこのようなケースにより適しています:(a)比較的小さなオブジェクトをストアする傾向がある(サイズ < 1M )。そして、 (b) kye-vallueストアはアプリケーションごとにコンフィグを行うのがより簡単です。Antiquityは複数サーバーの障害をハンドリングするよう設計された広域分散ストレージシステムです[23]。これは完全なデータ保護のためにセキュアログを用い、それぞれのログを永続性のために複数のサーバーにレプリケートし、データの一貫性を保証するためByzantine 耐障害プロトコルを利用します。Antizuityとは対称的に、Dynamoは信頼出来る環境のために構築されたのでデータ完全性とセキュリティの問題にフォーカスしていません。Bigtableは構造化データを管理するための分散ストレージシステムです。それはsparseと多次元的にソートされたマップを保持し、アプリケーションに複数の属性を使ってのデータアクセスを許可します[2]。Bigtableと比べると、Dynamoはネットワーク分断やサーバー障害の直後でも更新がリジェクトされないような高い可用性に一番にフォーカスしたkey/valueアクセスが必要なアプリケーションがターゲットです。
伝統的なレプリケートするリレーショナルデータベースはレプリカデータに強一貫性を保証するための問題にフォーカスしています。強一貫性はアプリケーション開発者に便利なプログラミングモデルを提供するのですが、これらのシステムはスケーラビリティと可用性が限定されてしまいます[7]。これらのシステムは、典型的には強一貫性保証を提供するため、ネットワーク分断をハンドリングするような能力はありません。
Dynamoはその要件定義の観点で、前述の分散ストレージシステムと異なります。まず、Dynamoはおもに障害や平行書き込みによって更新がリジェクトされる事のない、『いつでも書き込み可』データストアを必要とするアプリケーションをターゲットとしています。これは多くのAmazonアプリケーションにとって決定的な要件です。次に、先程述べたように、Dynamoは、全てのノードが信頼出来ると想定される、単一の管理されたドメイン内のインフラのために構築されました。第三に、Dynamoを使うアプリケーションは階層的な名前空間(多くのファイルシステムの標準)も、複雑なリレーショナルスキーマ(伝統的なデータベースでサポートされる)も必要としません。第四に、Dynamoは少なくとも99.9%のread/writeオペレーションが数百ミリ秒で実行される事が求められるレイテンシに敏感なアプリケーションのために作られました。これらの厳格なレイテンシー要件に合致するため、我々が複数ノードに渡るリクエストルーティング(ChordやPastryのようないくつかの分散ハッシュテーブルシステムが採用している)を避けるのは必須です。これはマルチホップルーティングがレスポンスタイムの変動を増加させ、そのためにレイテンシーを高いパーセンタイルに増加させてしまうからです。DynamoはゼロホップDHTとして特徴づけられ、各ノードはリクエストを適切なノードに直接ルーティングするための充分な経路情報をローカルに保持しています。
プロダクション設定で運用する必要のあるストレージシステムのアーキテクチャは複雑です。データ自体の永続性コンポーネントに加えて、システムはロードバランシング、メンバーシップ、障害検知、障害リカバリ、レプリカ同期、過負荷ハンドリング、状態転送、平行性とジョブスケジューリング、リクエスト整理、リクエストルーティング、システムモニタリングとアラーム、そして設定管理について、スケーラブルかつ堅牢な解決策を持っていなくてはならないのです。Dynamoで使われている各ソリューションの詳細を詳説することは不可能なので、この論文ではパーティショニング、レプリケーション、バージョニング、メンバーシップ、障害ハンドリング、スケーリングという、Dynamoで用いられているコアな分散システム技術についてフォーカスします。Table 1はDynamoが使っている技術とそのそれぞれの長所のリストです。
Table 1: Summary of techniques used in Dynamo and their advantages.
| Problem | Technique | Advantage |
|---|---|---|
| パーティショニング | コンシステントハッシング | 線形的なスケーラビリティ |
| writeの高可用性 | read時の調停を伴うVector clock | バージョンサイズが更新頻度に比例しない。 |
| 一時的障害への対応 | Sloppy Quorumとhinted hand off | いくつかのレプリカが停止している時に高い可用性と永続性を提供する。 |
| 永続的障害からのリカバリ | Markle木を用いたAnti-entropy | バックグラウンドでレプリカの不一致を同期する |
| メンバーシップと障害検知 | Gossipベースのメンバーシッププロトコルと障害検知 | 対称性を保護し、メンバーシップとノード生存情報の集約管理的な登録を避ける。 |
Dynamoは、get()とput()という二つの命令による、シンプルなインターフェイスでkeyと関連づけられたオブジェクトをストアします。get(key)命令はkeyと関連づけられたストレージシステム内のオブジェクトレプリカを見つけ、単一のオブジェクトか、contextにそった衝突バージョンのオブジェクトのリストを返却します。put(key, context, object)命令はオブジェクトのレプリカがどこに置かれるべきか決定し、そのレプリカをディスクに書き込みます。contextは呼び出し元には知らされないオブジェクトに関するシステムメタデータを符号化し、オブジェクトのバージョンのような情報を含みます。context情報はオブジェクトといっしょに保存されるので、システムはputリクエストに与えられたcontextの正当性を検証出来ます。
Dynamoは呼び出し元により与えられたkeyとオブジェクトの両方を不透過なバイト列として扱います。128-bit識別子を生成するためにMD5ハッシュをkeyに適用します。識別子はそのkeyを受け付ける責任のあるストレージノードを決定するために使われます。
Dynamoに求められた主要な設計要求のひとつは、線形にスケールしなければならないことです。これはシステム内のノードの組をまたいだ動的なデータパーティションの仕組みを必要とします。Dynamoのパーティショニング手法は、負荷を複数ストレージにわたって分散させるコンシステント・ハッシングに頼っています。コンシステント・ハッシング[10]では、ハッシュ関数の出力レンジは固定された環状の空間または"リング"(すなわち、最大のハッシュ値が最小値に包み込まれる)として扱われる。システムの各ノードはこのリング上の"位置"を表す空間上のランダムな値として割り当てられます。keyで識別されるそれぞれのデータアイテムは、リング上の位置を算出するデータアイテムのkeyをハッシュする事でノードに割り当てられます。そのとき、リングを時計回りにまわってアイテムのポジションよりも高いポジションにある最初のノードを見つけます。なので、各ノードはリング上で自分と自分の前のノードの間の領域について責任を持つようになります。コンシステント・ハッシングの主要な利点は、ノードの離脱や参入が直接の隣のノードにのみ影響を影響を与え、その他のノードは影響を被らない事です。一般的なコンシステント・ハッシングにはいくつかの問題があります。最初に、リング上での各ノードのランダムな位置割り当ては不均一なデータと負荷の分散を招きます。次に、一般的なアルゴアリズムはノードのパフォーマンスのばらつきを考慮していません。この問題を解決するため、Dynamoは、ノードを環の一点にマッピングするかわりに、各ノードが環の複数の点に関連づけられるという、コンシステント・ハッシングのバリエーション([10,20]で用いられているものと似ている)を使います。このため、Dynamoは"仮想ノード"の概念を使います。ひとつの仮想ノードはシステム内で単一のノードのように見えますが、各ノードは一つ以上の仮想ノードを受け持つ事が出来ます。事実上、新しいノードがシステムに追加された時、それはリング上の複数のポジション(以後、"tokens"とする)に割り当てられます。よく調整されたDynamoのパーティショニング手法のプロセスは、Section 6で議論します。
仮想ノードを使う事で、次のような利点があります。
- あるノードが(障害や計画メンテナンスで)使用不可能になったら、このノードによってハンドリングされる負荷は残りの使用可能なノードに平等に散らばります。
- ノードがまた利用可能になるか、新しいノードがシステムに追加されたとき、新しく使えるようになったノードは、他の使用可能なノードからおおよそ同じ量だけの負荷を受け入れます。
- ノードが受け持つ仮想ノードの数は、その物理インフラのばらつきによるキャパシティから決定されます。
高い可用性と永続性を達成するため、Dynamoは複数のホストにデータを複製します。それぞれのデータアイテムはNホストにレプリケートされますが、Nは"インスタンスごと"設定パラメータです。各キー k は(前章で述べた)コーディネーターノードに割り当てられます。あるコーディネーターはそのレンジに落ちてくるデータアイテムのレプリケーションに責任を持っています。レンジ内の各キーのローカル保存に加えて、コーディネーターはこれらのキーをリング上を時計回りに N-1個までのノードに複製します。この振る舞いは、システムを各ノードがリング上で自分とN個前までの間の区画に関して責任を持つシステムにします。図2では、ノードBはキー kをノードCとDに複製し、加えてローカルに保存します。ノードDはレンジ(A,B], (B,C], そして(C,D]のレンジに落ちて来たキーをストアします。
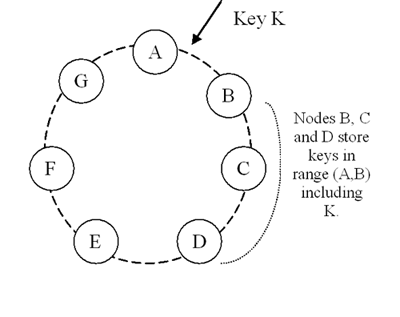
図2: Dynamoリングのキーのパーティショニングとレプリケーション
特定のキーをストアする責任のあるノードのリストを、preference listと呼びます。システムはSection 4.8で説明するように設計されているので、どの特定のキーについても、どのノードがこのリストに入るべきか、システム内の全てのノードが決定出来ます。ノード障害に対応するため、preference listはN個以上のノードを含みます。仮想ノードに注意すると、特定のキーの最初のN個の後継者パーティションはN以下の異なる物理ノードによって所有されるかもしれません(すなわち、ノードは最初のN個の位置の一つ以上に保持されるかもしれない)。これを解決するため、keyのpreference listが異なる物理ノードのみを含む事を確かにするため、リング上の位置を飛び飛びで構築されます。
Dynamoは結果整合性を提供しますが、これは更新が全てのレプリカに非同期的に伝播する事を許します。put()命令は全てのレプリカに更新が適用される前に呼び出し元に戻るかもしれませんが、これは後に続くget()命令が、最後の更新がされていないオブジェクトを返すかもしれないというシナリオに帰結します。障害がなければ、更新伝播時間は制限されます。しかし、特定の障害シナリオ下(例えば、サーバー障害、ネットワーク分断)においては、更新は延長された時間内に全てのレプリカに到達しないかもしれません。Amazonのプラットフォームのアプリケーションには、このような状況下でそういった不一致に耐えたり、命令を構築したりしうる種類のアプリケーションがあります。たとえば、ショッピングカートアプリケーションは"カートに追加"オペレーションを決してロストしたり却下したりしないことを要求します。もし最も新しいカートの状態が入手不可能で、ユーザーがカートの古いバージョンに変更を加えたら、その更新は重要で、保護されるべきです。しかし同時に、現在のカートの入手不可能な状態も保護されるべき変更を含むかもしれないので、破棄されるべきではいです。"カートに追加"と"カートから削除"はDynamoへのputリクエストに変換されることに注意してください。カスタマーがアイテムをショッピングカートに追加(または削除)したくて、最新バージョンが入手出来ないとき、アイテムは古いバージョンのカートに追加(または削除)され、枝分かれしたバージョンはのちに再統合されます。
この種の保証を提供するために、Dynamoは各変更の結果をデータの新しく不変のバージョンとして扱います。これにより、オブジェクトの複数のバージョンが同時にシステム内に存在することがゆるされます。殆どの場合、新しいバージョンは前のバージョンを包含し、システム自身が正式なバージョンを決定する事が出来ます(統語的調停)。しかしながら、バージョンブランチングは並列更新と結びついた障害のいたるところで発生し、オブジェクトのバージョン衝突に帰結します。このような場合、システムは同じオブジェクトの複数バージョンを調停することができないので、クライアントがデータの複数ブランチでの進化ををつぶして一つに戻す(統語的調停)ために、調停を行う必要があります。つぶす(collapse)オペレーションの典型的な例はカスタマーの異なるショッピングカートの"マージ"です。この調停メカニズムによって、"add to cart"オペレーションは決して消失しません。しかし、削除したアイテムが復活する事はあり得ます。
特定の障害モードで二つだけでなくいくつかの同じデータのバージョンが現れる潜在的な可能性があることを理解するのは重要です。ネットワーク分断およびノード障害の存在する中での更新は潜在的にオブジェクトが異なるバージョンサブヒストリーを持ち、将来調停する必要が生まれる可能性があります。このことは我々に、明示的に同じデータの複数バージョンの可能性を考慮したアプリケーションを設計することを求めます(決して更新をロストしないために)。
Dynamoは同じオブジェクトの異なるバージョン間の因果関係をキャプチャーするためにベクタークロック[12]を用います。ベクタークロックは事実上、(node, counter)ペアのリストです。ベクタークロックは全てのオブジェクトの全てのバージョンに関連づけられています。それぞれのベクタークロックを検査する事で、オブジェクトの二つのバージョンが平行ブランチなのか、因果的な順序をもっているのかを決定出来ます。もし一つ目のオブジェクトのクロックのカウンターが二つ目のクロック内の全てのノード以下であれば、一つ目のものは二つ目のものの祖先であり、かつ忘れられているかもしれないです。そうでなければ、二つの変更はコンフリクトと考えられ、統合を必要とします。
Dynamoでは、クライアントがオブジェクトの更新を望むとき、アップデートする対象のバージョンを指定する必要があります。これは先立つreadオペレーションから得られた、ベクタークロック情報を含むcontextを渡す事で行われます。readリクエストを処理する際、統語的に調停出来ない複数のブランチにアクセスした場合、Dynamoは付随するバージョン情報をcontextに格納して、全てのオブジェクトを返却します。このcontextを使った更新は枝分かれしたバージョンの調停とみなされ、ブランチは一つの新しいバージョンにたたみこまれます。

図3: オブジェクトの時間的なバージョンの展開
ベクタークロックの使い方を説明するため、Figure 3のような例を考えます。クライアントが新しいオブジェクトをwriteします。このキーへのwriteをハンドリングするノード(Sxとする)がそのシーケンス番号を増加させ、それをこのデータのベクタークロックを作るのに使います。これでオブジェクトD1とそれに関連付けられたクロック[(Sx, 1)]が出来ました。クライアントがオブジェクトを更新します。同じノードがこのリクエストもハンドリングすると想定します。システムにはオブジェクトD2と関連づけられたクロック[(Sx, 2)]ができます。D2はD1の子孫であり、したがってD1を上書きしますが、しかしD2がまだ到達していないノードに、ぐずついているD1のレプリカがあるかもしれません。同じクライアントがオブジェクトをまた更新しようとして、違うサーバー(Syとする)がリクエストを受けたとします。このときシステムにはデータD3とそれに関連づけられたクロック[(Sx,2),(Sy,1)]があります。
次は、異なるクライアントがD2をreadして更新を試み、他のノード(Szとする)がwriteしたたとします。システムには[(Sx,2),(Sz,1)]というバージョンクロックを持つD4(D2の子孫)ができます。D1またはD2に気づいているノードはD4とそのクロックを受け取ったときに、D1とD2が新しいデータによって上書きされ、ガベージコレクトできるかどうかを決定出来ます。D3に気づいていてD4を受け取ったノードは、それらの間に因果関係がない事に気づきます。いいかえれば、D3とD4の間に、お互いに反映されない変更があったということです。データの両方のバージョンはそのまま、意味論的調停のために、(read時に)クライアントに送られます。
さて、いくつかのクライアントがD3とD4の両方を読んだとします(contextはread時に見つかった全ての値に反映されます)。readのcontextはD3とD4のクロックの要約で、すなわち [(Sx,2),(Sy,1),(Sz,1)]です。クライアントが調停を行いSxがwriteをコーディネートした場合、Sxはクロック内のシーケンス番号を更新します。新しいデータD5は次のクロックを持ちます:[(Sx,3),(Sy,1),(Sz,1)]。
ベクタークロックによって起こりうる問題の一つに、たくさんのサーバーがオブジェクトのwriteをコーディネートした場合、ベクタークロックのサイズが大きくなってしまうかもしれないことです。実際には、writeは通常preference listの先頭Nノードのうちのひとつによってハンドリングされるため、起こりそうも無い事です。ネットワーク分断か複数のサーバー障害の場合、writeリクエストはpreference listの先頭Nノード以外のノードによってハンドリングされる可能性があり、これがvector clockのサイズ増大を引き起こします。これらのシナリオでは、ベクタークロックの大きさに制限を設ける事が望ましいです。この目的を達成するために、Dynamoは次のようなクロック切り捨て手法を採用しています:それぞれの(node, counter)ペアとともに、Dynamoはノードがそのデータアイテムを更新した最後の時刻を示すタイムスタンプを保存します。ベクタークロック内の(node,counter)ペアの数がしきい値(10とする)に達したら、最も古いペアはクロックから除外されます。明らかに、この切り捨て手法は子孫関係を正しく辿れなくなるので、調停の非効率を生み出します。しかし、この問題はプロダクション環境で発生した事は無いので、この問題は深く研究されていません。
Dynamoのどのストレージノードも、どのキーに対するクライアントのgetとput命令でも受けとる資格があります。この章では、簡単のため、これらのオペレーションが障害のない環境でどのように実行されるかを説明し、つづく章では障害中にどのようにread/write命令が実行されるかを述べます。getとput命令はどちらも、Amazonのインフラストラクチャ特有のHTTPでのリクエスト処理フレームワークを使って起動されます。クライアントがノードを選択するには二つの戦略があります。 (1) 負荷情報に基づく一般的なロードバランサーを通じてリクエストをルーティングする、または (2) リクエストを直接適切なコーディネーターノードにルーティングする、partitionを意識したクライアントライブラリを利用することです。最初のアプローチの利点は、クライアントがアプリケーションにDynamo特有のコードをリンクしなくても良い事です。一方、後者の戦略では、潜在的なフォワーディングのステップをスキップする事で、レイテンシを低下出来るという事です。
readまたはwrite命令をハンドリングするノードはコーディネーターとして知られています。典型的には、これはpreference listの先頭Nノードの一つ目のものです。リクエストがロードバランサー経由で届いた場合、キーにアクセスするリクエストはリングのランダムなノードにルーティングできます。このシナリオでは、そのリクエストを受け取ったノードがキーのpreference listの先頭のN個でなければ、そのノードはコーディネートを行いません。そのかわり、preference listの先頭N個のノードの最初のものにリクエストを転送します。
readとwriteの命令はpreference listの最初の健康なN個のノードを行使し、ダウンしていたりアクセス不能なノードをスキップします。全てのノードが健康であれば、キーのpreference listの先頭N個のノードにアクセスします。障害やネットワーク分断状態のノードがあったら、preference listの下位のノードにアクセスします。
レプリカで一貫性を保持するため、Dynamoは定足数システム(quorum systems)で使われているものに似た一貫性プロトコルを使います。このプロトコルはRとWという、二つの主要な設定値を持ちます。Rはread命令の成功のために加わらなければならないノードの最小数、Wはwrite命令の成功のために加わらなければならないノードの最小数です。R+W>N となるようなR、Wの設定は定足数風のシステム(quorum-like system)を生み出します。このモデルではget(またはput)命令のレイテンシは最も遅いR(またはW)のレプリカに従属します。この理由から、RとWは通常Nより低く設定され、よりよいレイテンシを提供します。
キーへのput()リクエストを受け取ったとき、コーディネーターは新しいバージョンのベクタークロックを生成し、その新しいバージョンをローカルに書き込みます。そしてコーディネーターは新しいバージョンを(新しいベクタークロックとともに)最もランクの高いN個の到達可能なノードに送信します。少なくともW-1個のノードが返答したらwriteは成功したと考えられます。
似たように、get()リクエストは、コーディネーターがキーに関する全ての存在するデータのバージョンをそのキーのpreference list内で最もランクの高いN個の到達可能なノードから取得し、そしてクライアントに結果を返すまでR個のノードからのレスポンスを待ちます。もしコーディネーターが最後にデータの複数バージョンをまとめあげるなら、因果関係の無いと思われる全てのバージョンを返します。枝分かれしたバージョンはそのとき調停され、現行バージョンに取って代わった調停されたバージョンは書き戻されます。
もしDynamoが従来的なquorum(定足数)アプローチを取っていたら、Dynamoはサーバー障害やネットワーク分断の間使用不能に陥り、もっとも単純な条件の障害状況下においてすら永続性を低下させていたでしょう。これを救済するため、Dynamoは厳格なquorumメンバーシップを強制する代わりに、"sloppy quorum(だらしない定足数)"を使います。これは、全てのreadとwrite命令はpreference listの先頭N個の健康なノード上で実行されますが、それはいつもコンシステントハッシングリングを順に巡って遭遇する最初のNノードではないというものです。 Figure 2で示した例をN=3で考えます。この例では、write命令の実行中にノードAが一時的にダウンしたり到達不能になったら、通常であればA上で生きていたレプリカはノードDに送られません。これは望ましい可用性と永続性の保障のために行われます。Dに送られたレプリカはそのメタデータの中にどのノードがレプリカの本来の受取人であったか(この場合A)を提案するヒントをメタデータの中に含むでしょう。ヒントつきレプリカを受け取ったノードは、定期的にスキャンされる隔離されたローカルデータベースにそのレプリカを保持します。Aが復旧した事が察知出来たとき、DはレプリカのAへの配送を試みます。いったん転送が成功してしまえば、Dはシステム内のレプリカの総数を低下させる事無く、ローカルストアからオブジェクトを削除出来ます。
ヒントつき受け渡し(Hinted handoff)を使う事で、Dynamoはreadとwrite命令が一時的なノードやネットワークの障害から失敗しない事を確実にしています。最高レベルの可用性が必要なアプリケーションはWを1にセットし、システム内に1ノードでもローカルストアにキーを書き込み可能であればwriteが受け付けられる事を確実にすることもできます。それゆえに、writeリクエストはシステムの全ノードが利用不能なときにしかリジェクトされません。しかしながら、実際には、プロダクション環境のほとんどのAmazonサービスは望ましいレベルの永続性を手に入れるためにより大きいWを設定しています。N,R,W設定のより詳しい議論はsection 6にて行います。
高可用性ストレージシステムが(複数の)データセンター全体の障害をハンドリングする能力を持つ事は必須です。データセンターは電力の停止、空調の故障、ネットワーク障害、そして自然災害によって障害を起こします。Dynamoはそれぞれのオブジェクトを複数のデータセンターにレプリケーションするように設定されています。本質的には、キーのpreference listを複数のデータセンター間に散らばったストレージノードで構築するのです。これらのデータセンターは高速なネットワークリンクで接続されています。このデータセンター間レプリケーション手法により、私たちはデータセンター障害全体をデータ欠損させることなくハンドリングする事が出来るのです。
ヒントつき受け渡しはシステムのメンバーシップの変動が低く、ノード障害が一時的であるときに最も良く動作します。ヒントつきレプリカがオリジナルレプリカノードに返却される前に利用不能になるというシナリオがあります。これや他の永続性への脅威に対処するために、Dynamoは反エントロピー(レプリカ同期)プロトコルを使ってレプリカを同期状態に保っています。レプリカ間の不整合を素早く検知して転送データ量を最小化するため、Dynamoはマークル木(Markle tree)を利用します。マークル木はそれぞれの葉が個々のキーの値のハッシュである、ハッシュ木の一種です。ツリーの上位にいる親ノードはめいめいの子供のハッシュです。マークル木の主要なアドバンテージは、すべてのノードにツリー全体やデータセット全体のダウンロードを要求する事無く、木の各枝を独立にチェックできる事です。そのうえ、マークル木は不整合のチェック中にレプリカ間で交わされるデータの量を低減するのに役立ちます。例えば、二つの木の根のハッシュ値が等価であれば、そのときツリーの葉の値も等価なので、そのノードは同期する必要はありません。そうでなければ、それは違うレプリカがあることを暗示しています。そのような場合、ノードは子供たちのハッシュ値を交換して、その葉にたどり着くまで続け、そのポイントでホストは"未同期"なキーを特定する事が出来ます。マークル木は同期のために転送されるデータ量を最小化し、反エントロピープロセス中に実行されるディスク読み込みを低減します。
Dynamoは反エントロピーのために次のようにマークル木を使います:それぞれのノードは自分でホストするキー範囲(仮想ノードがカバーされているキーの組)に分割されたマークル木を保持しています。これによってノードはキー範囲内のキーが最新かどうか比較することができます。この手法では、二つのノードは彼らが共通でホストしているキー範囲に一致するマークル木の根を交換します。その後、上で述べたツリー探索手法でそられに違いがあるかどうかを明らかにし、適切な同期化アクションを実行します。この手法の欠点は、ひとつのノードがシステムに参加か離脱してたくさんのキー範囲が変更されたときに、ツリーを再計算しなければならないことです。この問題は解決されましたが、Section 6.2で再び述べましょう。
Amazonの環境では、ノード停止(障害や、メンテナンス手順による)はしばしば一時的ですが、予定の時間を超過してしまうかもしれません。ノード停止が永続的な離脱の兆候であることは殆どないので、パーティション再割り当てや到達不能レプリカの修復を行うべきではありません。同様に、人的エラーは意図しない新しいDynamoノードの起動を引き起こす可能性があります。これらの理由により、Dynamoリングへのノードの追加や削除は明示的な開始メカニズムを使うことが適切であるとみなされてきました。管理者がコマンドラインツールやブラウザでDynamoノードに接続してノードのリングへの追加か削除をするメンバーシップ変更を発行するのです。リクエストを受けたノードはメンバーシップ変更と、その発行時刻を永続的ストレージに書き込みます。ノードは除外してまた追加することを何度も出来るので、メンバーシップ変更はヒストリーを形作ります。gossipベースのプロトコルはメンバーシップ変更を伝播させ、メンバーシップの見た目の結果整合性を維持します。各ノードは毎秒ランダムに選択されるpeerに連絡し、そのふたつのノードは効果的にかれらの持続的な変更履歴を統合します。
ノードが開始したとき、ノードはそのトークンのセット(コンシステントハッシュ空間の仮想ノード)を選びノードを彼らの受け持ちトークンセットにマッピングします。マッピングはディスクに永続化され、内部的にはローカルノードとトークンセットのみを含みます。異なるDynamoノードにストアされたマッピングはメンバーシップ変更履歴を調停するのと同じコミュニケーション交換の間に調停されます。従って、パーティショニングと配置の情報もgossipベースドプロトコルによって伝播し、各ストレージノードはそのpeerがハンドルするトークン範囲の変更を知ることが出来ます。これによって各ノードはキーのread/writeオペレーションを直接正しいノードセットに転送することができます。
上で述べたメカニズムは、一時的なDyamoリングの論理的分断を発生させる可能性があります。例えば、管理者はノードAにコンタクトしてAをリングに繋げ、ノードBにコンタクトしてBをリングに繋げるかもしれません。このシナリオでは、ノードAとBはそれぞれ自分をリングのメンバーだと認識するが、どちらもまだすぐにはお互いに気づきません。論理的な分断を避けるために、いくつかのDynamoノードはシードの役割を演じます。シードは外部のメカニズムによって発見され全てのノードを知っているノードです。全てのノードはシードによって結果的に調停されるので、論理的分断はとても起こりにくいです。シードは静的なコンフィグかコンフィグサービスから取られるかもしれません。一般的にはシードはフル機能のDynamoリングノードです。
Dynamoにおける障害検知は、get()/put()命令時とパーティション/ヒントつきレプリカの転送時に到達不可能なpeerと通信を試みるのを避けるために利用されます(?)。通信においての試行失敗をさける目的であれば、純粋にローカル内での障害検知でまったく十分です:ノードBがノードAのメッセージに応答しなければノードAはノードBが障害中であるとみなせます(たとえBがノードCのメッセージに応答出来たとしても)。Dynamoリングないでノード内コミュニケーションを生成するクライアントリクエストの安定したレートがあれば、Bがメッセージ応答に失敗したときにAはすぐにBが応答しないことを検知します;そのときAはBのパーティションにマップされている代替ノードを利用します;Aは定期的にBがリカバリしてないかチェックするためリトライします。もし2ノード間のトラフィックを行き交うクライアントリクエストが無い場合、ノードは実際に他ノードが到達可能であるのかどうか知る必要はありません。
分散された障害検知プロトコルはシステム内のそれぞれのノードが他のノードの到着と離脱を知ることの出来るシンプルなgossipスタイルのプロトコルを使います。分散障害検知器とその精度に影響するパラメータの詳細について知りたい読者は[8]を参照のこと。Dynamoの初期の設計は分散障害検知器をグローバルな障害状態のconsistent viewを維持するために用いていました。後に明示的なノードのjoin/leaveメソッドが障害状態のグローバルビューを不要にすると判断されました。これは明示的なノードの追加と削除メソッドでは永続的なノードの追加と削除がノードに通知され、一時的なノード障害は各々のノードが通信に失敗したときに検知されるからです。
新しいノード(Xとする)がシステムに追加されたとき、リング上をランダムに選択するいくつかのトークンが割り当てられます。ノードXに割り当てられた全てのキー範囲について、(N以下の)いくつかのノードが現在そのトークンレンジ内に落ちたキーをハンドリングする責任があるかもしれません。Xのキー範囲割り当てのため、いくつかの既存のノードはもはやそのキーのいくつかをストアしなくてもよくなるので、これらのノードはXにそれらのキーを転送します。Figure 2にあるようにAとBの間にノードXが追加される独立した例を考えましょう。Xがシステムに追加されたとき、レンジ(F,G],(G,A], そして(A,X]をストアする責任があります。その結果として、ノードBとCとDはもはやその責任範囲のキーをストアする必要が無くなります。なので、ノードB,C,Dは適切なキーセットの転送をXに提案して承諾を得ます。ノードがシステムから除外されたときは、逆のプロセスでキーの再配置が発生します。
運用上の経験によると、このアプローチはキー配分の負荷をストレージノード群にわたって均一に分散しますが、これはレイテンシー要件を満たし高速な起動を確実にするために必要です。最後に、送信側と受信側の間に確認フェイズを追加することで、受信側ノードが重複したキーレンジを受信しないことを確かめています。
Dynamoでは、それぞれのストレージノードは主にrequest coordination, membership and failure detection, local persistence engineの3つのソフトウェアコンポーネントから構築されています。これらはすべてJavaで実装されています。 Dynamoのローカル永続化コンポーネントは異なるストレージエンジンをプラグインすることができます。Berkeley Database(BDB) Transactinal Data Store, BDB Java Engine, MySQL, 永続化バックアップ保存に対応したインメモリバッファなどが使われています。永続かコンポーネントをプラガブルに設計したのは、アプリケーションのアクセスパターンにもっとも適したストレージエンジンを選択出来るようにするためです。たとえば、BDBは一般的にほぼ数十キロバイトのオブジェクトを扱うのに対して、MySQLはもっと大きいサイズのオブジェクトを扱います。アプリケーションはオブジェクトサイズの区分によって永続化エンジンを選択します。Dynamoのプロダクションインスタンスの大半はBDB Transactional Data Storeを利用しています。
リクエストコーディネーションコンポーネントはメッセージ処理パイプラインがSEDAアーキテクチャ[24]に似た複数のステージに分かれるイベント駆動メッセージ基板上に構築されています。全てのコミュニケーションはJava NIOチャンネルを用いて実装されています。コーディネーターは一つ以上のノードからデータを収集し、(readの場合)、データを保存して(writeの場合)クライアントに代わってreadとwriteリクエストを実行します。各クライアントリクエストは、クライアントリクエストを受信したノード上でステートマシンの生成をもたらします。ステートマシンは、キーを受け持つノードを特定し、リクエストを送信し、レスポンスを待ち、潜在的にはリトライを行い、返信を処理し、クライアントへのレスポンスをパッケージングするためのすべてのロジックを含んでいます。それぞれのステートマシンのインスタンスはきっちり一つのクライアントリクエストを処理します。たとえば、read命令は次のステートマシンを実装します:(i)ノードにreqdリクエストを送信 (ii)必要なレスポンスの最小数を待つ, (iii) もし一定の期限内に受信した返信が少なすぎれば、リクエストをfailさせ、(iv)そうでなければ全てのデータバージョンを集め、返却すべきものを決定し、 (v)もしバージョニングが有効であれば、統語的調停を実行し、全ての残留しているバージョンを包括するベクタークロックを含む透過的なwriteコンテキストを生成します。簡単のため、障害ハンドリングとリトライのステートは省略します。
readレスポンスが呼び出し元に返却された後、ステートマシンは未処理のレスポンスを受け取るため短い時間だけ待ちます。もしどこかのレスポンス内に古いバージョンが返却されて来たらコーディネーターはこれらのノードを最新バージョンで更新します。このプロセスは最近の更新を失ったレプリカを便宜的なタイミングで修復し、これをすることで反エントロピープロトコルを受信するので、read repairと呼ばれます。
前述の通り、writeリクエストはpreference listのトップNノードのひとつにコーディネートされます。常にトップN個のうちの最初のノードがwriteをコーディネートし、それによって全てのwriteが一カ所でシリアライズされるのが理想的ですが、このアプローチは負荷分散を不均一にし、SLA違反を招きます。これはリクエストの負荷はオブジェクト間で均一に分散されていないからです。これに対抗するために、preference list内のいずれのトップNノードもwriteをコーディネートすることが許されています。特に、writeリクエストは通常readオペレーションの後に続くので、あるwriteのコーディネーターはリクエスト内にコンテキスト情報を含む直前のread命令に最速で返信したノードが選ばれます。この最適化によって直線のread命令でreadされたデータを持つノードを選択することが可能になり、それにより"read-your-write"一貫性を得られる可能性が向上します。また、パフォーマンスを99.9パーセンタイルに向上するリクエスト処理のパフォーマンスの変動を減少させることも出来ます。
Dynamoはいくつかのサービスで異なる設定で使われています。これらのインスタンスはバージョン調停ロジック、read/writeのquorum特性において異なります。下記は、Dynamoが利用の主なパターンです。
-
ビジネスロジック特化調停(Business logic specific reconciliation):これはDynamoのユースケースにとって人気です。各データオブジェクトは複数のノード間でレプリケートされます。バージョン分岐の場合、クライアントアプリケーションはそれ自身の調停ロジックを実行します。前に述べたショッピングカートサービスはこのカテゴリの代表例です。そのビジネスロジックは顧客のショッピングカートの異なるバージョンをマージすることでオブジェクトを調停します。
-
タイムスタンプベース調停(Timestamp based reconciliation):これは前述のケースと調停メカニズムのみ異なります。バージョン分岐の場合、Dynamoはタイムスタンプに基づいた簡単な"last write wins"、すなわち最大の物理timestamp値を持つオブジェクトが正しいバージョンとなる調停ロジックを実行します。
-
高パフォーマンスreadエンジン(High performance read engine):Dynamoが"always writeable"データストアとして設計されている一方、少数のサービスはそのquorum特性を調整し、高性能なreadエンジンとして利用しています。典型的には、これらのサービスは高いreadリクエストレートと少数の更新を行います。この設定では、一般的にRは1、WはNとなります。これらのサービスに、Dynamoは彼らのデータのパーティションと複数ノードにわたるレプリケートを提供し、それによって線形なスケーラビリティを提供しています。これらのインスタンスのいくつかはもっと重量級のバックアップストアのための信頼性のある永続化キャッシュとして機能します。製品カタログや商材を保持するサービスはこのカテゴリに向いています
Dynamoの主な長所は、クライアントアプリケーションがN,R,Wの値をチューニングして希望のパフォーマンス、可用性、永続性のレベルを達成出来ることです。例えば、Nの値は各オブジェクトの永続性を決定します。Dynamoユーザーの一般的なN値は3です。WとRの値はオブジェクトの可用性、永続性、そして一貫性に影響します。例えば、もしWが1に設定されていれば、writeリクエストの処理が可能なノードがシステム内で少なくとも1台存在すれば決してwriteリクエストをリジェクトしません。しかし、WとRの値が低いと、たとえレプリカの大半で処理が行われなかったとしてもwriteリクエストが成功とみなされてクライアントに返るため、一貫性低下のリスクが増大します。これはまた、少数のノードにしか永続化できていなくてもwriteリクエストが成功としてクライアントに返却されたときに永続性が脆弱な時間帯(a vulnerability window for durability)を招きます。
伝統的な知恵では、永続性と可用性には緊密な関係があると考えています。しかしながら、これはここでは必ずしも真とはいえません。例えば、永続性が脆弱な時間帯はWを増加させることで減少できます。これはより多くのストレージホストがwriteリクエスト中に生きている必要があるため、リクエストのリジェクトの可能性を増大させます。
いくつかのDynamoインスタンスで利用されている一般的な(N,R,W)設定は(3,2,2)です。この値はパフォーマンス、永続性、一貫性、可用性のSLAの必要なレベルに合致するために選ばれます。
この章での全ての測定は(3,2,2)設定と数百のホモジニアスなハードウェア設定のノードで運用されているライブシステムで計測されました。前に述べたように、それぞれのDynamoインスタンスのノードは複数のデータセンターに配置されています。これらのデータセンターは一般的にハイスピードネットワークリンクで接続されています。get(またはput)レスポンスを成功させるにはR(またはW)個のノードがコーディネーターに返答する必要があることを思い出してください。明らかに、データセンター間のレイテンシはレスポンス時間に影響を与えるので、アプリケーションの目標SLAに合致するノード(とそれらのデータセンターの位置)が選ばれます。
Dynamoの原則的な設計上の目的が高度に可用性の高いデータストアの構築だとしても、パフォーマンスはAmazonのプラットフォームにおいて同じように重要です。前述のように、一貫した顧客体験を提供するために、Amazonのサービスは自らのパフォーマンス目標を高いパーセンタイル(99.9th or 99.99th percentiles)に設定しています。Dynamoを使うサービスの典型的なSLA要求は99.9%のread/writeリクエストを300ms以内で実行することです。
Dynamoはハイエンドなエンタープライズサーバーよりも遥かにI/Oスループットが貧弱な標準的なコモディティハードウェアコンポーネント上で動作しているので、read/writeオペレーションに一貫して高パフォーマンスを提供するのは簡単な仕事ではありません。複数のストレージノードがread/write命令に関わってくると、これらのパフォーマンスはR/W個のレプリカの中で最も遅いものに制限されてしまうため、よりチャレンジングになります。図4は30日の期間でのDynamoのread/writeの平均/99.9th パーセンタイルレイテンシを示しています。図に示されているように、レイテンシはリクエストレートの日次パターンの結果としての日次パターンを描きます(すなわち、日中と夜間ではリクエストレートに大きな違いがあります)。そのうえ、writeレイテンシは常にディスクアクセスを発生させるのでreadレイテンシより明らかに高いです。また、99.9パーセンタイルレイテンシは200前後で、大きさのオーダーは平均より大きいです。これは、99.9thパーセンタイルレイテンシがリクエスト付加、オブジェクトサイズ、位置などの多様な要因を受けるからです。

図4: 私たちの2006年12月シーズンのピークリクエスト期間中のread writeリクエストレイテンシの平均と99.9パーセンタイル値。X軸の目盛りの間隔は12時間に相当します。レイテンシはリクエストレートに似た日次パターンに従い、99.9パーセンタイルレイテンシは平均よりも一ケタ高くなっています。
このパフォーマンスのレベルは多くのサービスにとっては許容可能なものですが、いくつかの顧客に面したサービスはより高いパフォーマンスのレベルを要求します。これらのサービスには、Dynamoは永続性の保証とパフォーマンスのトレードオフ機能を提供します。この最適化では、各ストレージノードはメインメモリ内にオブジェクトバッファを保持します。各writeオペレーションはバッファに保存され、writer threadによって定期的にストレージに書き込まれます。この手法では、read命令は最初に要求されたキーがバッファに存在するかどうか調べます。もしあれば、オブジェクトはストレージエンジンからのかわりにバッファからreadされます。
この最適化は、数千オブジェクトのとても小さなバッファの場合でも、ピークトラフィック時に99.9パーセンタイルレイテンシを5倍縮小します(図5を見よ)。図のように、writeバッファリングは高いパーセンタイルを平均化します。もちろん、この手法は永続性とパフォーマンスをトレードしています。この手法では、ひとつのサーバークラッシュがバッファにキューされたwriteの喪失を招く恐れがあります。永続性のリスクを減らすため、writeオペレーションはNレプリカのうちから"durable write"を行うコーディネーターを持つように改良されています。コーディネーターはW個のレスポンスしか待たないので、writeオペレーションのパフォーマンスは各レプリカで行われるdurable writeオペレーションのパフォーマンスの影響を受けません。

図5: バッファと非バッファ時の99.9thパーセンタイルレイテンシのパフォーマンス比較。X軸の目盛りの間隔は1時間に相当します。
Dynamoはキースペースをレプリカに分割し、負荷を均一に分散するためにコンシステントハッシングを用いています。均一なキー分散はキーのアクセス分布があまり偏っていないと想定される均一な負荷分布の達成を助けます。特に、Dynamoの設計はアクセス分布が大きく偏っている箇所でさえ分布の人気な側には十分なキーがあるので、人気なキーのハンドリングの負荷はパーティショニングを越えてノード間に均一にアクセスが散らばると想定します。この章ではDynamoに見られる負荷の偏りと負荷分散の異なるパーティショニング戦略の影響を議論しましょう。
負荷の偏りとそのリクエスト負荷との相関を調べるため、各ノードから受信したリクエストの総数を24時間単位で(30分間隔で)計測しましょう。もしノードのリクエスト負荷が特定のしきい値(ここでは15%)よりも逸脱していなければ、ある時間のなかで、あるノードは"均一(in-balance)"とみなされます。さもなければ、ノードは"不均衡(out-of-balance)"とされます。図6は、この時間の中で"不均衡(以下"不均衡比率(imbalance ration)"とする)"なノードの一部を表しています。参照のため、この時間内にシステム全体から受信した対応するリクエスト負荷もプロットされています。図から分かるように、不均一比率は負荷の上昇に従って減少しています。例えば、低負荷のあいだは不均衡比率は20%までで、負荷が高いときは10%に近づきます。直感的には、高負荷時には大量の人気のキーがアクセスされ、キーの均一な分布によって負荷が均一に分散されていると説明出来ます。一方、(ピークロードの1/8の)低負荷時のときに、人気のキーは少ししかアクセスされず、高い負荷不均一を招いています。

図6:バランスを崩したノードの割合(すなわち、リクエスト負荷が平均のシステム負荷より一定量高いノード)とそれぞれのリクエスト負荷。X軸の目盛りは30分に相当します。
この章ではDynamoのパーティショニング手法がどのように時間をかけて発展してきたかと、その負荷分散への影響を議論します。
戦略1: ノードごとにT個のランダムトークンとトークン値によるパーティショニング: これはプロダクションにデプロイされた最初の戦略でした(4.2章で述べられています)。この方法では、各ノードはTトークン(ハッシュ空間から不均一に)に割り当てられます。全ノードのトークンはハッシュ空間に値順に並べられます。全ての連続した2ノードはレンジを定義します。最後のトークンと最初のトークンはハッシュ空間内で最大値と最小値を覆う"ラップ"を形成します。トークンはランダムに選ばれるので、レンジはサイズにばらつきがあります。ノードはシステムにジョインしたり離脱したりするので、トークンセットは変化し、その結果レンジも変化します。空間はシステム内の書くノードの数が線形に増加するときに各ノードのメンバーシップを保持する必要があることに注意してください。
この戦略をとっているとき、次の問題が発生しました。まず、新しいノードがシステムにジョインしたとき、他のノードからキーレンジを"盗んで"くる必要があります。しかし、ノードがキーレンジを新しいノードに受け渡すには、ローカル永続化ストアをスキャンして適切なデータアイテムのセットを受け取る必要があります。プロダクションオードでそのようなオペレーションを行うのは、スキャンが高度にリソース食いなオペレーションであり、それを顧客へのパフォーマンスへの影響なくバックグラウンドで実行せねばならないことからトリッキーです。これは私たちに最低の優先度で立ち上げタスク(bootstrapping task)を実行することを要求します。しかし、立ち上げタスクと、ノードが一日に数百万リクエストを扱っている忙しいショッピングシーズンの期間は重大な速度低下を起こし、立ち上げタスクの完了にはまる一日を要します。次に、ノードがシステムにjoin/leaveしたとき、たくさんのノードにハンドルされているキーレンジが変更され、新しいレンジのためのマークル木が再計算される必要があり、それはプロダクションシステムで実行するには無視出来ないオペレーションです。最後に、キーレンジのランダム性のため、全キースペースのスナップショットを取る簡単な方法は存在しないので、このためアーカイバルの手順は複雑になります。この手法では、全てのキー空間をアーカイブ化するには各ノード別々にキーを取得する必要があり、これは非常に非効率的です。
この戦略の基本的な問題はデータパーティショニングとデータプレースメントの手法が関連づけられていることです。例えば、リクエスト負荷の増加に対処するためにシステムにノードを追加することが好まれる場面があります。しかしこのシナリオでは、データパーティショニングの影響を受けずにノードを追加することは不可能です。理想的には、パーティショニングと配置の問題に独立した手法を用いることが望ましいです。このため、次の戦略が評価されました。
戦略2:ノードごとにT個のランダムトークンと同サイズパーティショニング: この戦略では、ハッシュ空間はQ個の同一サイズのパーティション/レンジに分割され、各ノードはT個のランダムトークンが割り当てられます。Qは一般的に Q >> N and Q >> S*Tで、Sはシステムのノード数です。この戦略では、トークンはノードの順序つきリストを指すハッシュ空間の値をマップする機能を構築するためだけに使われ、パーティショニングを決定するためには使われません。パーティションは、パーティションの終端からコンシステントハッシュリングを時計回りに探索するときに遭遇した最初のNこのユニークなノード上に配置されます。図7はN=3におけるこの戦略を図示します。この例では、ノードA,B,Cはキーk1を含むパーティションを終端から探索しているときに遭遇します。この戦略の主要な利点は:(i)パーティショニングとパーティション配置が粗結合、(ii) 実行時に配置手法の変更が可能になる、です。

図7:3戦略におけるキーのパーティショニングと配置。A,B,Cは、コンシステントハッシングリング(N=3)上でキーk1のpreference listを形成する3つのユニークなノードを示しています。共有されている領域はノードA,B,Cがpreference listを形成するキー範囲を示しています。暗い領域は様々なノードのトークン位置を示しています
戦略3:ノードごとにQ/S個のトークンと、同一サイズのパーティション: 戦略2と似たように、この戦略はハッシュ空間をQ個の同一サイズのパーティションに分割し、パーティションの配置はパーティション手法と分離しています。さらに、各ノードにはSがシステム内のノード数であるところのQ/S個のトークンがアサインされます。ノードがシステムを離脱するとき、そのトークンはランダムに残りのこれらの所有権(properties)が保持されたノードに分散されます。同じように、ノードがシステムに参加するとき、それはトークンをノードから"盗み"、ある意味でこれらの所有権(properties)を保持します。
これら三種類の戦略の効率性はS=30、N=3のシステムで評価されます。しかし、これらの戦略は効率性を調整する異なる設定を持っているので、公平に比較するのは困難です。例えば、戦略1の負荷分散の特性はトークンの数(すなわちT)に依存し、一方戦略3はパーティションの数(すなわちQ)に依存しています。これらの戦略を公平に比較する一つの方法は、全てのメンバーシップを保持する同じ量の空間を全ての戦略が使ったときのをそれらの負荷分散の偏りを評価することです。例えば、戦略1において各ノードはリング中の全てのノードのトークン位置を保持する必要があり、戦略3では各ノードは各ノードにアサインされたパーティションに従って情報を保持しなくてはなりません。
私たちの次の実験で、これらの戦略は関連パラメーター(TとQ)で異なる評価がされます。各戦略の負荷分散効率は各ノードが保持する必要のあるメンバーシップ情報の異なる量ごとに計測され、負荷分散効率性(Load balancing efficiency)は各ノードが受け付けたリクエストの平均数対最もホットなノードが受け付けたリクエスト数の最大値の比率として定義されます。
その結果が図8です。図にあるように、戦略3が最大の負荷分散効率性を達成し、戦略2が最悪でした。一時的に、戦略2は戦略1から3を使うDynamoインスタンスからのマイグレーションプロセスのセットアップを行っていました。戦略1と比べると、戦略3はよりよい効率性を達成し、三つの大きさの順で各ノードが保持するメンバーシップ情報のサイズを削減します。ストレージはノードが定期的にgossipするメンバーシップ情報として主要な問題ではありませんが、小さいにこしたことはありません。これにくわえ、戦略3は次の理由でデプロイするのに有利でシンプルです:(1)高速な立ち上げ/修復タスク:パーティションレンジが固定なので、個別のファイルにストアできます。これは、(特定のアイテムを配置するために必要なランダムアクセスを回避して)そのファイルを転送することで一単位としてシンプルにパーティションを再配置することができることを意味します。これは立ち上げとリカバリのプロセスをシンプル化します。(ii)アーカイバルの容易さ:定期的なデータセットのアーカイブ化はほとんどのAmazonのストレージサービスにとっての強制的義務です。戦略3はパーティションファイルが別々にアーカイブ可能なため、Dynamoにストアされた全てのデータセットのアーカイブ化を容易にします。対照的に、戦略1では、トークンがランダムに選択され、Dynamoにストアされたデータのアーカイブ化は各ノードからバラバラにキーを取得する必要があり、それは通常非効率で低速です。戦略3の不利な点は、ノードメンバーシップの変更が割り当て要求された所有権の保存のためにコーディネーションが必要なことです。

図8: 各ノードにおいて同じ量のメタデータを保持した時の30ノード、N=3なシステムの時の異なる負荷分散効率の戦略の比較。システムサイズとレプリカ数の値は私たちのサービスの多数で採用されている設定に準じました。
前に述べたように、Dynamoは一貫性と可用性のトレードオフのために設計されています。異なる一貫性の損失の精密な影響を理解するために、複数の要素の詳細なデータが必要です:停止の長さ、損失の種類、コンポーネント信頼性、仕事量、etc… これらの詳細を数え上げるのはこの論文のスコープ外です。しかし、この章では基準:ライブなプロダクション環境においてアプリケーションに見られる分岐バージョンの数の概要について論じます。
データアイテムの分岐バージョンは二つのシナリオで増加します。一つ目はシステムがノード障害、データセンター障害、ネットワーク分断のような障害シナリオに直面しているときです。二つ目は、システムが一つのデータアイテムに対して大量の並列書き込みを処理し、複数のノードの更新コーディネートが並列的に終わったときです。利便性と効率性の観点から、どのタイミングにおいても可能な限り分岐バージョンの数は少なく保つことが望ましいです。バージョンがベクタークロックベースで統語的に調停できない場合、セマンティック(意味論的)に調停するためビジネスロジックにそれらを渡す必要があります。セマンティックな統合はサービスに追加の負荷をまねくので、最小に押さえることが望ましいです。
次の実験では、ショッピングカートサービスが返却するバージョンの数を24時間単位でプロファイルしました。この期間中、99.94%のリクエストがきっかり一つのバージョンを返却し、0.00057%のリクエストが2バージョン、0.00047%のリクエストが3バージョン、0.00009%のリクエストが4バージョンを返しました。これは、分岐バージョンはめったに作られないということを表します。
実験は分岐バージョンの数の増加は障害に寄与されず、並列書き込みの数の増加によると示します。並列書き込み数の増加は通常忙しいロボット(クライアントの自動プログラム)、そしてまれに人間によって引き起こされます。この問題は話の敏感な性質上、詳しくは論じません。
第5章で論じたように、Dynamoは入力されたリクエストをハンドリングするため、ステートマシンを用いたリクエストコーディネーションコンポーネントを有しています。クライアントリクエストはロードバランサーによってリングの中のノードに均一に割り当てられます。どのDynamoノードもreadリクエストに対してコーディネーターとして振る舞うことが出来ます。一方writeリクエストはキーのその時のpreference list内のノードによって処理されます。この制約は、これらのノードはwriteリクエストによって更新される因果を包括したバージョンの新しいバージョンスタンプ生成の追加の責務を持つという事実のためです。もしDynamoのバージョニング手法が物理的なタイムスタンプベースであれば、どのノードもwriteリクエストをコーディネート出来ることに注意してください。
リクエストのコーディネートの他のアプローチは、状態マシンをクライアントノードに移してしまうことです。この手法では、クライアントアプリケーションはローカルでリクエストコーディネートを行うライブラリを使います。クライアントは定期的にランダムなDynamoノードを選択し、そのDynamoメンバーシップステートのviewをダウンロードします。この情報を使ってクライアントはどのノードセットが任意のキーに対してpreference listを形成しているのか判断します。readリクエストはクライアントノードでコーディネート出来るので、リクエストがロードバランサーによってランダムにDynamoノードに割り当てられた時に起こる余分なネットワークホップを回避出来ます。書き込みはキーのpreference listに転送されるか、もしDynamoがtimestampベースドバージョニングを使っていればローカルでコーディネートできます。
クライアントドリブンコーディネーションの重要な利点は、クライアント負荷を均一に分散するためにロードバランサーは必要なくなるということです。公平な負荷分散はストレージノードへのキーの均一に近い割り当てによって暗示的に保証されます。明らかに、この手法の効率はクライアントの持つメンバーシップ情報がどれだけ新鮮かに掛かっています。現在はクライアントはランダムなDynamoノードを10秒ごとにポーリングしてメンバーシップを更新しています。pullベースの手法はpushベースのそれより、クライアント数の増大によくスケールし、かつクライアントに関係するサーバーにとても小さい状態しか必要としないという理由で好まれます。しかし、クライアントは最悪10秒間、失効したメンバーシップ情報にさらされることになります。この場合、クライアントがそのメンバーシップテーブルが失効していることに気づいたら(たとえば、いくつかのメンバーが到達不能であるなど)、すぐにメンバーシップ情報が更新されます。
表2はクライアント駆動コーディネートを利用した場合の99.9th パーセンタイルと平均における、サーバー駆動アプローチと比べてのレイテンシ改善を示しています。表に見られるように、クライアント駆動アプローチは99.9thパーセンタイルで最低30ミリ秒レイテンシを削減し、平均を3から4ミリ秒削減します。レイテンシの改善はクライアント駆動アプローチがランダムなノードに割り当てられた時のロードバランサーと余計なネットワークホップのオーバーヘッドを排除したことによります。表にあるように、平均レイテンシは99.9thパーセンタイルよりとても低い傾向にあります。これはDynamoのストレージエンジンのキャッシュとwriteバッファーのヒット率が良好なためです。さらに、ロードバランサーとネットワークはレスポンスに変動しやすさを追加するので、99.9thパーセンタイル応答時間の上昇は平均よりも高いです。
Table 2: Performance of client-driven and server-driven coordination approaches.
| 99.9th percentile read latency (ms) | 99.9th percentile write latency (ms) | Average read latency (ms) | Average write latency (ms) | |
|---|---|---|---|---|
| Server-driven | 68.9 | 68.5 | 3.9 | 4.02 |
| Client-driven | 30.4 | 30.4 | 1.55 | 1.9 |
それぞれのノードはそれぞれの通常のフォアグラウンド put/get処理に加え、レプリカ同期とデータ受け渡し(ヒントつきまたはノード追加/削除のため)の異なる種類のバックグラウンドタスクを実行しています。初期のプロダクション設定では、これらのバックグラウンドタスクはリソース競合の引き金になり、通常のputとgetオペレーションのパフォーマンスに影響を与えました。なので、バックグラウンドタスクは通常のクリティカルオペレーションが大きく影響を受けないときにのみ実行するように確かめることが必要になりました。この目的のために、バックグランドタスクは許可制御(Admission controller)メカニズムに統合されることになりました。それぞれのバックグラウンドタスクはこのコントローラーを使ってリソース(データベースなど)のランタイムスライスを予約し、全てのバックグラウンドタスクにわたって共有されます。フォラグラウンドタスクの監視されたパフォーマンスに基づくフィードバックメカニズムがバックグランドタスクが利用可能なスライス数の変更のために採用されています。
Admission controllerは"フォアグラウンドの"put/getオペレーションの実行中にリソースアクセスの振る舞いを定期的に監視します。監視項目にはディスクオペレーションのレイテンシ、ロック競合やトランザクションタイムアウトによるデータベースアクセスの失敗、そしてリクエストキューの待ち時間が含まれます。この情報は任意の時間のレイテンシのパーセンタイル(または失敗)が理想的なしきい値と近いかをチェックするために使われます。例えば、バックグラウンドコントローラーは99thパーセンタイルデータベースreadレイテンシー(最新の60秒の)がプリセットされたしきい値(50ms)にどれほど近いかチェックします。コントローラーはそのような比較をフォアグラウンドオペレーションにとってのリソース可用性を評価するために利用します。その後に、バックグラウンドに何回スライスを提供するか決定し、それによってフィードバックループをバックグランドアクティビティの侵入性の制限に使っています。これと似たようなバックグラウンドタスク管理の問題が[4]で研究されています。
この章ではDynamoの実装とメンテナンスの過程で得られたいくつかの経験をまとめます。多くのAmazon内部のサービスは過去2年にわたりDynamoを利用し、素晴らしいレベルの可用性をそのアプリケーションに提供してきました。特に、アプリケーションはそのリクエストの99.9995%で(タイムアウトすることなく)成功のレスポンスを受け取り、今日に至るまでデータロスの事象は発生していません。
さらに、Dynamoの主要な利点は、利用者のニーズに合わせて彼らのインスタンスをチューンするための必要なノブを、(N,R,W)の三つのパラメーターを通じて提供していることです。人気の商用データストアと違い、Dynamoはデータの一貫性を危機に捨て、調停ロジックがデベロッパーに開かれています。最初は、アプリケーションロジックがより複雑になると予想するかもしれません。しかし、歴史的に、Amazonのプラットフォームは高可用性のために構築され、多くのアプリケーションは異なる失敗モードと起きうる非一貫性をハンドリングするよう設計されています。なので、そのようなアプリケーションをDynamoに移行することは比較的シンプルなタスクです。Dynamoを使いたい新しいアプリケーションに取っては、開発の初期段階でビジネスケースを適切に満たす正しい衝突解決メカニズムを選択するためのいくつかの分析が必要です。最後に、Dynamoは各ノードがそれらpeerによって干すとされているデータを知っているフルメンバーシップモデルを採用しています。このため、各ノードはシステム内の他のノードへのフルルーティングテーブルを活発にgossipします。このモデルは数百のノードを持つシステムでうまく働きます。しかしながら、そのような設計を数万ノードで実行するよう設計するのは、ルーティングテーブルの保持のオーバーヘッドがシステムサイズとともに増えるため、簡単な仕事ではありません。この制限は階層的な拡張をDynamoに導入することで乗り越えることが出来るかもしれません。この問題はO(1)な分散ハッシュテーブルでも活発に指摘されていることにも注意してください(たとえば[14])
この論文では、Amazon.comのe-commerceプラットフォームの数多くのコアサービスの状態を保存している高可用性スケーラブルデータストアDynamoについて述べてきました。Dynamoは希望のレベルの可用性と性能を提供し、サーバー障害、データセンター障害、ネットワーク分断のハンドリングに成功してきました。Dynamoは線形にスケーラブルでサービスオーナーに現在のリクエスト負荷に応じたスケールアップ/ダウンを可能にしました。Dynamoはサービスオーナーに、彼らのストレージシステムをN,R,Wのパラメーターを調整することで希望の性能、永続性、一貫性SLAに合致するようカスタマイズすることを許します。
過去数年のDynamoのプロダクション利用は分散管理された技術は単一の高可用性システムを提供するために組み合わせられることを実証しました。そのもっともチャレンジングなアプリケーション環境の一つでの成功は、結果整合性ストレージシステムは高可用性アプリケーションのための建築ブロックになり得ることを示しています。
著者はDynamoの初期のデザインに貢献してくれたPat Hellandに感謝します。私たちはまた、コメントをくれたMarvin TheimerとRobert van Renesseにも感謝したいです。最後に、詳細なコメントとインプットで撮影用論文をとても向上してくれた私たちの羊飼い、Jeff Mogulにも感謝します。
[1] Adya, A., Bolosky, W. J., Castro, M., Cermak, G., Chaiken, R., Douceur, J. R., Howell, J., Lorch, J. R., Theimer, M., and Wattenhofer, R. P. 2002. Farsite: federated, available, and reliable storage for an incompletely trusted environment. SIGOPS Oper. Syst. Rev. 36, SI (Dec. 2002), 1-14.
[2] Bernstein, P.A., and Goodman, N. An algorithm for concurrency control and recovery in replicated distributed databases. ACM Trans. on Database Systems, 9(4):596-615, December 1984
[3] Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., Chandra, T., Fikes, A., and Gruber, R. E. 2006. Bigtable: a distributed storage system for structured data. In Proceedings of the 7th Conference on USENIX Symposium on Operating Systems Design and Implementation - Volume 7 (Seattle, WA, November 06 - 08, 2006). USENIX Association, Berkeley, CA, 15-15.
[4] Douceur, J. R. and Bolosky, W. J. 2000. Process-based regulation of low-importance processes. SIGOPS Oper. Syst. Rev. 34, 2 (Apr. 2000), 26-27.
[5] Fox, A., Gribble, S. D., Chawathe, Y., Brewer, E. A., and Gauthier, P. 1997. Cluster-based scalable network services. In Proceedings of the Sixteenth ACM Symposium on Operating Systems Principles (Saint Malo, France, October 05 - 08, 1997). W. M. Waite, Ed. SOSP '97. ACM Press, New York, NY, 78-91.
[6] Ghemawat, S., Gobioff, H., and Leung, S. 2003. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles (Bolton Landing, NY, USA, October 19 - 22, 2003). SOSP '03. ACM Press, New York, NY, 29-43.
[7] Gray, J., Helland, P., O'Neil, P., and Shasha, D. 1996. The dangers of replication and a solution. In Proceedings of the 1996 ACM SIGMOD international Conference on Management of Data (Montreal, Quebec, Canada, June 04 - 06, 1996). J. Widom, Ed. SIGMOD '96. ACM Press, New York, NY, 173-182.
[8] Gupta, I., Chandra, T. D., and Goldszmidt, G. S. 2001. On scalable and efficient distributed failure detectors. In Proceedings of the Twentieth Annual ACM Symposium on Principles of Distributed Computing (Newport, Rhode Island, United States). PODC '01. ACM Press, New York, NY, 170-179.
[9] Kubiatowicz, J., Bindel, D., Chen, Y., Czerwinski, S., Eaton, P., Geels, D., Gummadi, R., Rhea, S., Weatherspoon, H., Wells, C., and Zhao, B. 2000. OceanStore: an architecture for global-scale persistent storage. SIGARCH Comput. Archit. News 28, 5 (Dec. 2000), 190-201.
[10] Karger, D., Lehman, E., Leighton, T., Panigrahy, R., Levine, M., and Lewin, D. 1997. Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web. In Proceedings of the Twenty-Ninth Annual ACM Symposium on theory of Computing (El Paso, Texas, United States, May 04 - 06, 1997). STOC '97. ACM Press, New York, NY, 654-663.
[11] Lindsay, B.G., et. al., “Notes on Distributed Databases”, Research Report RJ2571(33471), IBM Research, July 1979
[12] Lamport, L. Time, clocks, and the ordering of events in a distributed system. ACM Communications, 21(7), pp. 558-565, 1978.
[13] Merkle, R. A digital signature based on a conventional encryption function. Proceedings of CRYPTO, pages 369–378. Springer-Verlag, 1988.
[14] Ramasubramanian, V., and Sirer, E. G. Beehive: O(1)lookup performance for power-law query distributions in peer-to-peer overlays. In Proceedings of the 1st Conference on Symposium on Networked Systems Design and Implementation, San Francisco, CA, March 29 - 31, 2004.
[15] Reiher, P., Heidemann, J., Ratner, D., Skinner, G., and Popek, G. 1994. Resolving file conflicts in the Ficus file system. In Proceedings of the USENIX Summer 1994 Technical Conference on USENIX Summer 1994 Technical Conference - Volume 1 (Boston, Massachusetts, June 06 - 10, 1994). USENIX Association, Berkeley, CA, 12-12..
[16] Rowstron, A., and Druschel, P. Pastry: Scalable, decentralized object location and routing for large-scale peer-to-peer systems.Proceedings of Middleware, pages 329-350, November, 2001.
[17] Rowstron, A., and Druschel, P. Storage management and caching in PAST, a large-scale, persistent peer-to-peer storage utility. Proceedings of Symposium on Operating Systems Principles, October 2001.
[18] Saito, Y., Frølund, S., Veitch, A., Merchant, A., and Spence, S. 2004. FAB: building distributed enterprise disk arrays from commodity components. SIGOPS Oper. Syst. Rev. 38, 5 (Dec. 2004), 48-58.
[19] Satyanarayanan, M., Kistler, J.J., Siegel, E.H. Coda: A Resilient Distributed File System. IEEE Workshop on Workstation Operating Systems, Nov. 1987.
[20] Stoica, I., Morris, R., Karger, D., Kaashoek, M. F., and Balakrishnan, H. 2001. Chord: A scalable peer-to-peer lookup service for internet applications. In Proceedings of the 2001 Conference on Applications, Technologies, Architectures, and Protocols For Computer Communications (San Diego, California, United States). SIGCOMM '01. ACM Press, New York, NY, 149-160.
[21] Terry, D. B., Theimer, M. M., Petersen, K., Demers, A. J., Spreitzer, M. J., and Hauser, C. H. 1995. Managing update conflicts in Bayou, a weakly connected replicated storage system. In Proceedings of the Fifteenth ACM Symposium on Operating Systems Principles (Copper Mountain, Colorado, United States, December 03 - 06, 1995). M. B. Jones, Ed. SOSP '95. ACM Press, New York, NY, 172-182.
[22] Thomas, R. H. A majority consensus approach to concurrency control for multiple copy databases. ACM Transactions on Database Systems 4 (2): 180-209, 1979.
[23] Weatherspoon, H., Eaton, P., Chun, B., and Kubiatowicz, J. 2007. Antiquity: exploiting a secure log for wide-area distributed storage. SIGOPS Oper. Syst. Rev. 41, 3 (Jun. 2007), 371-384.
[24] Welsh, M., Culler, D., and Brewer, E. 2001. SEDA: an architecture for well-conditioned, scalable internet services. In Proceedings of the Eighteenth ACM Symposium on Operating Systems Principles (Banff, Alberta, Canada, October 21 - 24, 2001). SOSP '01. ACM Press, New York, NY, 230-243.