クラスタ上のリソース管理・スケジューリングを行うクラスタ管理システム。Mesosを利用することで、HadoopやMPIといった複数のクラスタコンピューティングフレームワーク間で、粒度の高いリソース共有が可能になる。これにより、クラスタのリソース利用効率が上がり、巨大なデータセットを複数フレームワークで共有することができる。また、複数フレームワークがリソースを共有できることで、開発者は汎用的なフレームワークではなく、特定の問題領域に特化したフレームワークを自由に開発・動作させることができる。従って、フレームワークの成長が加速し、各問題領域に対してより良いサポートを提供できるようになる。
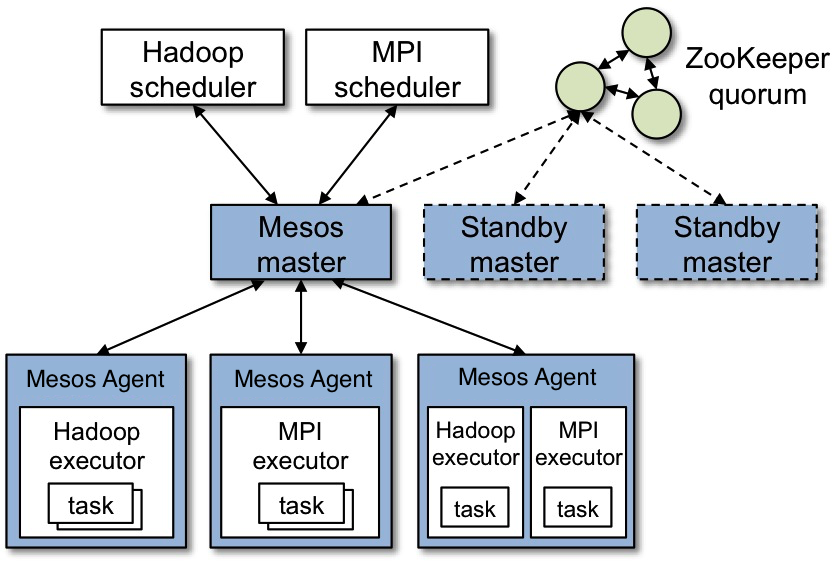
各Agentから利用可能なリソースの情報を受け取り、各FrameworkのScheduler(以下、Scheduler)に提示する。この時、どういったポリシーでリソースを分配するかをプラグインで設定することができる。予め用意されているポリシーには、Dominant Resource Fairnessというfair sharingの一種と、strict priorityがある。
Schedulerがリソースを受け取った場合、タスクと実際に使う分のリソース情報が送られてくるのでそれをAgentに送る。また、Agentから通知されるタスクの実行結果をSchedulerに伝える。
各ノードで実行されるプロセス。ノード上のリソースの死活監視、及び利用可能なリソースの情報をMasterに伝える。
Masterからタスク情報が送られてくると、FrameworkのExecutorプロセス(以下、Executor)を立ち上げる。Executorからタスクの実行結果を受け取ってMasterへ送る。
Mesos上で動作するフレームワーク。SchedulerとExecutorという2つの要素から構成される。
- Scheduler:Masterに登録され、リソースを提示してもらう。リソースを受け取る場合、どれだけのリソースを使うを決定しタスクをmasterに渡す。
- Executor:Agent上で起動され、タスクを実行する。また、実行結果をAgentに伝える。
多種多様なフレームワークをサポートするため、MesosはResource Offerと呼ばれる分散Two-levelスケジューリング方式を導入している。 この方式では、リソース管理とスケジューリングを分離し、スケジューリング及びタスク実行に関する制御を各フレームワークに委任する。この方式では、
- Masterがクラスタ上のリソースを管理し、利用可能なリソースを各Frameworkに提示する。
- 各Frameworkは、Masterから提示されたリソースを見て、それを使うかどうかを決める。
- もし使う場合、必要なリソースとその上で実行するタスクの情報をMasterに伝える。
- 使わないという選択もできる。その場合、リソースは違うFrameworkに提示される。
この設計により、次の様な利点がある。
- Frameworkは、目的に応じてスケジューリングのアプローチを実装し、切り替えることができる。
- Mesosそのものはシンプルさが保たれ、スケーラビリティと堅牢性が維持できる。
一方で、次の様な制約も発生する
- タスクのリソース要求が不均一だった場合、リソース利用効率を最適化できない。
- フレームワーク同士が依存しあっているケースに対処できない。
- Resource Offerを用いることで、スケジューリングに複雑さが生まれる。
Mesosでは、各Frameworkに自身の制約条件を満たさないResource Offerを断る能力を与えることで、各Frameworkの複雑なリソース制約をサポートしている。特にデータローカリティに関しては、入力データが格納されているノードが確保できるまで一定時間待機するというDelay-Schedulingと呼ばれるポリシーを用いることで、ほとんど最適なデータローカリティが得られることがわかっている。
Mesosでは、高可用化のために以下の対処を行っている。
- Masterの内部状態を、AgentとSchedulerが保持する情報から復元することができるように設計
- ZooKeeperを利用して複数Masterをhot-standby構成で立ち上げる。
フレームワークに対してシンプルなAPIを提供しており、Mesos上でフレームワークを動かす場合はAPIを使ってスケジューラを実装する。これにより、幅広いフレームワークをサポートすることが可能となっている。
Hadoop MapReduceの単一マスタープロセスであるJobTrackerから、リソース管理・スケジューリングの機能を分離したもの。これまでのHadoop MapReduce v1 では、JobTrackerがクラスタ上のリソース管理、タスクの割り当て、モニタリング等を全て行っており、負荷が非常に高いことがスケーラビリティを制限する原因となっていた。TaskTrackerにおいては、map処理を実行するmapスロットとreduce処理を実行するreduceスロットの数が固定されるため、リソース利用効率が悪いという問題があった。また、MapReduce以外のプログラミングモデルをサポートしたいという要求も強く、これらの要求に応える次世代のプラットフォームとしてYARNが開発された。
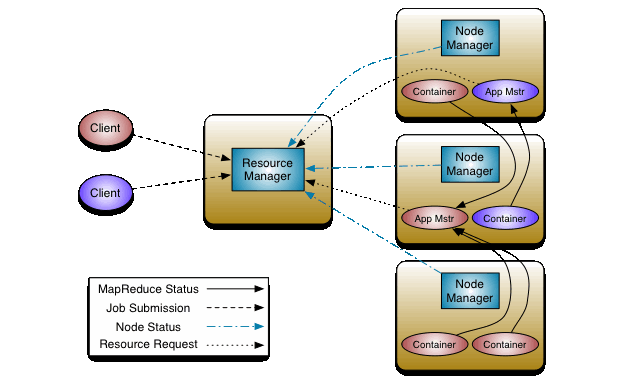
専用マシン上で実行されるマスタープロセス。各ノードで実行されるNMの死活監視、及びクラスタ全体のリソースを管理してアプリケーションに分配する。この時、どういったポリシーでリソースを分配するかをプラグインで設定することができる。現在用意されているポリシーにはfair sharingとcapacityがある。
Clientからジョブの実行依頼を受け取ると、NMにリソースを要求してAMを起動し、その死活監視とリソース要求の受け付けを行う。
各ノードで実行されるエージェントプロセス。各NMはノード上のリソースの死活監視、管理を行う。リソースはcontainerという単位(CPU、メモリ、ディスク、ネットワークを含むリソースの集合)で管理され、動的に作成される。NMはリソース利用状況を逐次RMに報告し、RMからのリソース要求に応じてリソースを確保する。
AMからタスク実行のリクエストを受け取ると、container内でタスクを実行させ、container内のリソース使用量などをモニタリングして、RMに報告する。
アプリケーションの実行を調整するプロセス。ジョブの実行に必要なリソースをデータローカリティに関する条件も含めてRMに要求する。RMからある特定のノードに結び付けられたcontainer情報を受け取った後、受け取ったcontainerに応じて実行プランを修正し、次に要求するリソースの条件を更新する。
containerを受け取った後、NMにリクエストを送ってタスクを実行させる。RM経由でタスクの進行状況をモニタリングし、失敗したタスクの再開などを行う。
YARNではAMがRMにリソースをリクエストするというアプローチをとっている。これにより、AMはローカリティを含めた様々な基準に基づきリソースを要求することができ、与えられたリソースと現在の利用状況に応じて次に要求するリソースの条件を修正することができる。
YARNではジョブ毎にAMが起動されるため、ジョブの起動にオーバーヘッドがかかる。
RMが単一障害点となっており、ZooKeeperを利用した高可用化への取り組みが進められている。
(ResourceManager High Availability)
各フレームワークがAMを実装することで、幅広いフレームワークをYARN上で動作させることができる。
Googleの巨大なクラスタ上で、多種多様なアプリケーションから送られる大量のジョブの受け入れ、スケジューリング、起動、モニタリング等を行うクラスタ管理システム。Borgはリソース管理と障害対応に関する詳細を隠蔽し、ユーザー(Googleの開発者、システム管理者)がアプリケーション開発に集中できるようにする。また、高信頼性、高可用性で運用され、数万台のマシンを効率的に使ってワークロードを走らせることができる。
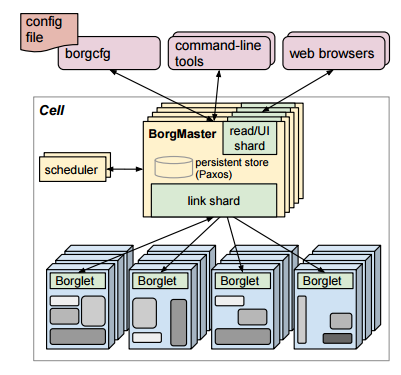
ユニットとして管理されるマシンの集合。中間的なcellのサイズは約一万台で、cell内のマシンはリソースのサイズやプロセッサの種類、性能など多くの側面で不均一である。
通常、1つの巨大なcellとテストや特別な用途に使用する幾つかの小さなcellで構成される。cluster内のマシンは全て高性能ネットワークで接続されている。clusterはデータセンターの建物内で稼働し、幾つかの建物がサイトを構成する。
各ジョブは名前、所有者、タスク数といったプロパティを持つ。また、タスクを実行させるマシンの要件をプロセッサアーキテクチャやOSのバージョンといった属性で設定することができる。ジョブには優先度があり、優先度の高いジョブによって低いジョブがpreemptionされる可能性がある。
各タスクはリソース要件、ジョブ内におけるインデックスといったプロパティを持つ。実行環境への依存を少なくするため静的リンクされ、バイナリとデータファイルがpackageとしてまとめられる。このpackageのインストールはBorgによってオーケストレートされる。タスクにはHTTPサーバが組み込まれており、タスクの実行状況やパフォーマンスに関する情報などのモニタリングに利用される。
一つ以上のタスクを実行させるためにあるマシンで確保されたリソースのセット。異なるジョブのタスクを同じマシンに移動させるために利用される。もし、allocが別のマシンに移動しなければならない場合、タスクも最スケジュールされる。
cell毎に存在するマスタープロセス。各マシンで実行されているBorgletと通信し、システム内の全オブジェクト(マシン、タスク、allocs)の状態を管理する。また、ClientからRPCでジョブの操作を受け付け、pendingキューにジョブの追加を行う。Borgmasterとそのデータは5回複製され、Paxos-basedストアに保存される。
pendingキューを非同期的にスキャンするプロセス。ジョブに設定されているリソース要件を見て、それを満たす十分なリソースがある場合タスクをマシンに割り当てる。スケジューリングアルゴリズムはfeasibility checkingとscoringの2つのフェーズで構成される。
feasibility checkingでは、タスクのリソース要件を満たし、かつ十分に利用可能なリソースがあるマシンの集合を探す。
scoringでは、feasibility checkingフェーズで見つけたマシンにスコアを付けて、最も良いマシンを決める。スコアにはユーザーが指定した設定も考慮されるが、ほとんどはpreemptされたタスク数の最小化や、既にタスクpackageのコピーを持っているか、といった条件でスコアが決まる。scoringフェーズで選ばれたマシンに新しいタスクに合う十分なリソースがなかった場合、優先度の低いタスクはpreemptされ、pendingキューに送られる。
cell内の各マシンで実行されるエージェントプロセス。タスクの起動・停止・再起動を行い、リソースの管理を行う。Borgmasterから数秒おきにマシンの状態を聞かれるのでそれに答える。もし、BorgletがBorgmasterの呼びかけに何回か答えなかったら、そのマシンはダウンしたものとして扱われ、そのマシンで実行されているタスクは再スケジュールされる。
Cellで実行されるワークロードは大きく以下の2種類に分類される。Cellにおけるワークロードの比率は異なり、時間帯によっても傾向が変わる。
GmailやGoogle Docs、BigTableなどといった長時間実行されるサービス。これらは低レイテンシ(数マイクロ秒 ~ 数百ミリ秒)での応答が求められる。こういったジョブはproductionジョブという高い優先度を持ったジョブに分類される。
完了するのに、数秒〜数日かかるバッチジョブ。短期間のパフォーマンス変動には、あまり影響されない。こういったジョブはnon-productionジョブという優先度の低いジョブに分離される。
Borgでは各タスクに対してcell名、ジョブ名、タスクIDからなるタスク名を与える。Borgはタスク名とともにタスクのホスト名、ポート番号をChubbyに保存し、RPCでどのタスクがどのマシンに割り当てられたのかを調べるのに利用される。
Borgでは、エージェントであるBorgletがマスターのBorgmasterに状態を通知するのではなく、Borgmasterが各Borgletの状態を尋ねて回る。従って、Borgmasterが通信の割合を制御することができるため、明示的なフロー制御が必要なくなり、負荷が急増するのを防ぐことができる。
Mesosは、リソース管理とスケジューリングの機能が分離されたアーキテクチャであることに加えて、各フレームワークがリソースを受け取るか断るかを決めるというモデルによって、シンプルで柔軟性が高いものとなっている。各フレームワーク側が目的(データローカリティの実現など)に応じてスケジューラを実装し切り替えることで、より柔軟なリソース分配が実現できる。一方、Masterの負担は少なく、より高いスケーラビリティが得られる。
一方、YARNとBorgではRequest-basedなリソース割り当てを行う。 このリソース要求は予め決められた仕様に基づいて行われるため、柔軟なリソース分配を実現しにくい。また、YARNとBorgはMasterが各フレームワークから送られるリソース要求を全て見て、データローカリティなどを考慮に入れた割り当てを行っており、Mesosに比べてMasterの負荷が高く複雑である。
YARNはHadoopクラスタでの利用を主として考えられており、Hadoop関連のフレームワークをメインターゲットにしている。また、BorgはGoogleが自分達のクラスタとアプリケーションを管理するためのクローズドソースなシステムであり、我々は利用できない。一方、Mesosはより汎用的に幅広い環境で利用することができる。
Mesosを高可用化するためには、ZooKeeperを用いて複数Masterをhot-standby構成で立ち上げる必要がある。YARNも同様にZooKeeperを利用した高可用化への取り組みが進められている。
一方、BorgではZooKeeperを使わず自前で高可用化を行っている。Borgmasterは5回複製され、各レプリカはメモリ上でcell内のほとんどのオブジェクトの状態を管理している。このcellの状態データはPaxos-basedストアで永続化される。また、ある時点でのBorgmasterの状態はcheckpoint(定期的に取られるスナップショット + 変更ログ)と呼ばれ、これもPaxos-basedストアで永続化される。
Mesosにおいて、各Schedulerがリソースを得るためにはMasterの提示を待つ必要があり、他のリソースがどういったタスクに使われているかといった情報は得ることができない。従って、優先度の高いタスクのために低いタスクをpreemptするといった仕組みを導入することが難しい。YARNもMesosと同様に優先度に基づくpreemptionの仕組みがない。
一方、Borgではジョブに優先度を設定することができ、状況に応じて優先度の高いタスクが低いタスクをpreemptする仕組みが導入されている。