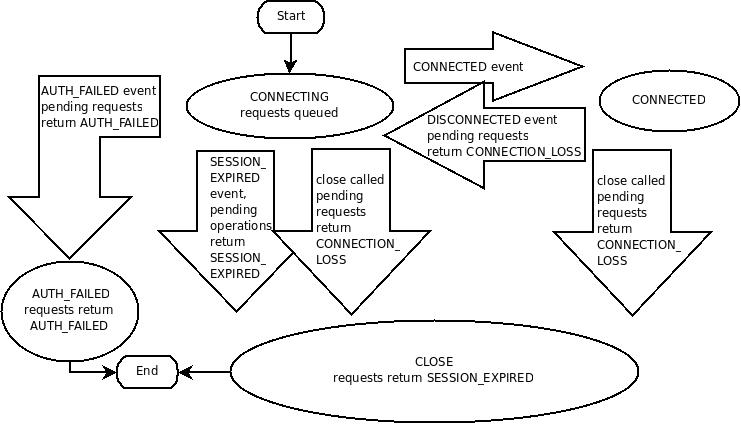
Node.js から Apache ZooKeeper を使うのに必要そうなことを勉強するために、ドキュメントを読んで、自己解釈を書きました。
大体、日本語訳みたいになってると思いますが、正確な単語や表現の選定をするきはありませんし、誤読してる箇所もあるでしょうから、必ず本家ドキュメントも読んでください。
この記事を書いている時点で、Apache ZooKeeper の最新バージョンは 3.5.5 なので、そのドキュメントを読んでいます。 http://zookeeper.apache.org/doc/r3.5.5/
ZooKeeper はハイパフォーマンスなコーディネーションサービスをアプリケーションに提供するミドルウェアです。 "naming" "configuration management" "synchronization" "group services" のような機能を、シンプルなインターフェースで提供します。 内部的な "consensus" "group management" "leader election" "presence protocol" は ZooKeeper が勝手にやってくれます。
ZooKeeper は distributed で opens-source な coodination service です。 "synchronization" "configuration maintenace" "groups" "naming" のようなサービスを、シンプルでプリミティブな方法で提供します。 データは、ファイルシステムのようなディレクトリツリー型のデータ構造で管理します。 Java で実装されてます。(※実装はともかく、JVM で動くよって話。)
- ZooKeeper is simple
- ZooKeeper is replicated
- Zookeeper is ordered
- Zookeeper is fast
一般的なファイルシステムのような、階層化された名前空間でデータを管理します。 一つ一つののデータノードを、ZooKeeper では znode と呼びます。 znode は、一つのファイル/フォルダに相当します。 ZooKeeper のデータはすべて im-memory です。
ZooKeeper は、ハイパフォーマンスで高い可用性があり "strictly ordered access" な実装をされています。
- 大規模分散システムから使えるパフォーマンスを提供します(ハイパフォーマンス)
- 単一障害点になりません(高可用性)
- The strict ordering means that sophisticated synchronization primitives can be implemented at the client(strictly ordered access)
- クライアント側で、同期すべきタイミングを知り、プリミティブな同期する って実装ができるよ、ってこと?わからん
- たぶん、変更通知のイベントが飛んできたり、矛盾したデータへアクセスされない(トランザクションレベルが SERIALIZABLE)ってことだと思う
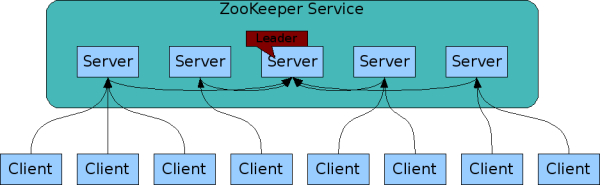
全サーバがお互いを認識している必要があります。
- すべてのServer は、同じ ZooKeeper サービス に参加している他のすべてのサーバを知っている必要があります
- トランザクションログとスナップショットは永続化されますが、 state (current なデータのこと?)はすべて in-memory image です
- 大半のサーバー(過半数)が生きていれば、サービス自体は Available です。
ひとつのクライアントは、ひとつの ZooKeeper Server にアクセスします。
- 通信プロトコルは TCP を使います
- リクエスト/レスポンス
- イベントの通知の watch
- ハートビート
- コネクションが壊れたら、クライアントは、他のサーバへ再接続しにいきます
Zookeeper はすべてのトランザクションに更新順序が採番されます。 その与えられた更新順序を、よりハイレベルで抽象的な目的に利用できます。
ZooKeeper は「読み取り>書き込み」なワークロードにおいてより高速に動作します。 ZooKeeper は、以下のような条件が揃うような場合が得意です。
- ZooKeeper を使ったアプリケーションが 1000 台を超えるような台数のマシンで動いていること
- 読み書きの比率が 10:1 くらいで、読み取りのほうが多いこと
ZooKeeper で使える名前空間は、一般的なファイルシステムのそれによく似ています。
ノード名はスラッシュ / で区切られたパスとして識別されます。
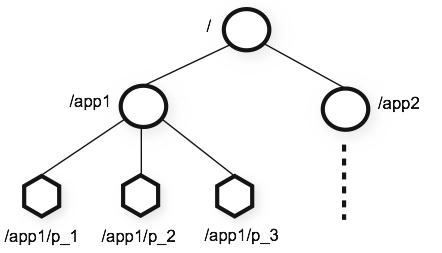
一般的なファイルシステムと異なる点は、ZooKeeper の各 Node には、子ノードだけでなく、そのノード自身にもデータを持つことができます。
znode は自身のステータス情報として「そのノードのバージョン番号」「ACL」「タイムスタンプ」などを持っており、キャッシュの検証やデータ更新の調整などに利用できます。 znode のデータが変更されれば、「バージョン番号」はインクリメントされます。 クライアントはデータを取得する際にバージョン番号も得られます。
ノードにあるデータの変更は Atmically に行われます。 各ノードは各々の Access Control List を持ちます。
ZooKeeper には Ephemeral Node という概念があります。
この znode は、作成したセッションがアクティブである限り存在し、セッションが終了すると削除される というものです。
一時ノードの使用例は [TBD] 。
ZooKeeper には Watches(監視)という概念があります。 クライアントは znode の変更を watch することができます。 watch は znode の変更によって発火され削除されます。 watch が発火されると、クライアントは znode が変更された旨のパケットを受け取ります。
クライアント・サーバ間のコネクションが切断されると、クライアントは local notification を受け取ります。使用例は [TBD]
ZooKeeper is very fast and very simple. ZooKeeper のゴールは「同期する」という点でより複雑なサービスを構成する基礎になる、ということです。 そのために、以下のような保証を提供します。
- Sequential Consistency(逐次一貫性): クリアントからの更新は、送信された順序で適用される
- Atmicity(原子性)
- Single System Image(単一システムイメージ):クライアントはどの ZooKeeper サーバに接続しても、同じサービスのビューになる
- Reliability(信頼性):クライアントからの更新はそのまま適用され、その後クライアントから更新されない限り、更新されることはない(サーバサイドのストアドプロシージャやトリガーなどは存在できない)
- Timeliness(適時性):システムのクライアントビューは、一定の時間内に最新のものである
より深い情報や使用例については [TBD]
ZooKeeper の設計のゴールは、めっちゃシンプルな API を提供する、ということです。 その結果、以下のような操作 だけ をサポートすることになりました:
- create: create a node
- delete: delete a node
- exists: test if a node exists
- get data: reads the data from a node
- set data: writes data to a node
- get children: ノードの子ノード一覧を取得する
- sync: データの変更が ZooKeeper Service 全体に浸透するのを待つ
より深い情報や使用例などについては [TBD]
この図は、ZooKeeper Service 内部のコンポーネント図です。 Request Processor 以外のコンポーネントは、各サーバにそれぞれのコンポーネントの replicates があります。
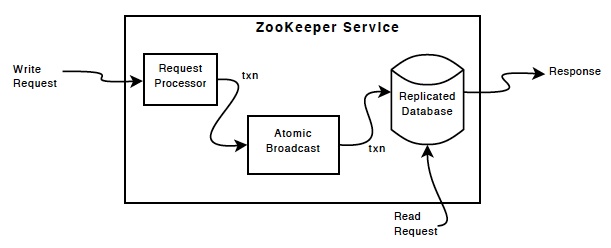
Replicated Databaes は im-memory データベースです。 すべての "更新" は、リカバリ可能にするためにディスクへログとして残され、シリアル化されてディスクに保存され、その後 im-memory データベースに適用されます。 (※ここでいってるのは、MySQL で言うところの general log みたいなのが常にディスクへ書き込まれているよ、という話です。)
クライアントは、ZooKeeper Service の中に存在する一つの ZooKeeper Server に接続し、リクエストを送信します。 Read Requests は、接続したサーバにある Replica から読み込まれます。 変更を伴う Requests は、Agreement Protocol によって処理されます。
Agreement Protocol は、リーダーと呼ばれる、一つの ZooKeeper Service に一つだけあるサーバに "提案" されます。 リーダーは、フォロワー(リーダ以外のすべてのサーバ)に、変更してもいいかを問い合わせ、問題なさそうであれば、変更し、フォロワーにあるデータが更新されます。 (※要するに、ZooKeeper Service 全体での 2相コミット をしているということ)
ZooKeeper は custom atomic messaging protocol を使用しています。(※詳しい話は ZooKeeper Internals に書かれている)
(※本家ドキュメントは、ここまでに書いたことと重なる内容も多く長々と書かれていたり、最後の方は [TBD] になっていたりと、ドキュメントとしてどうんだって状態です。初出な情報を適宜メモ程度に書いておきます。)
znode のデータには、タイムスタンプやバージョンも含むと言いました。 クライアントから更新リクエストを送る場合、更新内容のほかに、どのバージョンに対して更新をするのか、という情報も必要です。 更新リクエストを送ったときに、更新しようとしている znode がすでにそのリクエストで指定されたバージョンよりも新しいバージョンになっている場合、更新は失敗します。
前述したとおり。
znode を create するときに sequencial にすると、パスの終端に %010d なカウンタを追加されます。
カウンタは符号付き4バイト整数なので、2,147,483,647 を超えるとオーバーフローして -2147483648 になります。
3.5.3 で追加されました。
子ノードがなくなると、そのノード自体も自動的に削除される znode 。(※いつ削除されるかは未定義)
container znodes を作る場合は、子ノードを create するときに KeeperException.NoNodeException プロパティをつければよいです。
/path/to/my という znode が 存在しない状態で /path/to/my/node という znode を KeeperException.NoNodeException 付きで create すると、 /path/to/my という名前 Container Node が内部で自動的に作られます。
(※ようするに、 mkdirp ってことだな)
PERSISTENT か PERSISTENT_SEQUENTIAL な znode を create した場合、ミリ秒で TTL を設定することができます。
この TTL の間に znode が更新されず、子ノードも存在しない場合、削除されます。(※いつ削除されるかは未定義)
TTL Nodes は、デフォルトでは作成できません。システム起動時に明示的に有効にする必要があります。
有効になっていない場合、 KeeperException.UnimplementedException が throw されます。
ZooKeeper は、いくつかの方法で時間的な前後関係を特定できるようにしています。
- zxid(Zookeeper TransaCTion ID): すべての変更には、zxid があります。 zxid
1は zxid2のトランザクションよりも前に発生したトランザクションです。 - Version Numbers: 各 znode ごとにある、変更ごとにインクリメントされる値。znode の変更は version 、znode の ACL の変更は aversion という名前で管理されている。
- Ticks: 内部的に使っているもの。クライアント側では、「最小のセッションタイムアウト」が Tick Time の 2 倍の数として、間接的に知ることはできます(が、知ったところで用途はありません)。
- Real Time: ただし、これは本当の real time や clock time ではなく、 znode にある timestamp の話です。
- czxid: Created Zookeeper transaCTion ID
- ctime: Created TIME
- mzxid: Modified Zookeeper transaCTion ID
- mtime: Modified TIME
- pzxid: 一番最近の、直属の子ノードが作られたトランザクションの ID 。孫以下は含まれない。
- version: その znode のバージョン(変更回数)
- cversion: 直属の全子ノードの変更回数の合計。孫以下は含まれない。
- aversion ACL のバージョン
- ephemeral Owner: if it's not ephemeral node, it'll be zero.
- dataLength
- numChildren