Last active
March 29, 2024 10:50
-
-
Save nikhilweee/24cae428f68c153afda495dc17ef43d6 to your computer and use it in GitHub Desktop.
Convert HDFC Bank Credit Card statements from PDF to Excel
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| # This script is designed to convert bank statements from pdf to excel. | |
| # | |
| # It has been tweaked on HDFC Bank Credit Card statements, | |
| # but in theory you can use it on any PDF document. | |
| # | |
| # The script depends on camelot-py, | |
| # which can be installed using pip | |
| # | |
| # pip install "camelot-py[cv]" | |
| import os | |
| import argparse | |
| import camelot | |
| import pandas as pd | |
| from collections import defaultdict | |
| def extract_df(path, password=None): | |
| # The default values from pdfminer are M = 2.0, W = 0.1 and L = 0.5 | |
| laparams = {'char_margin': 2.0, 'word_margin': 0.2, 'line_margin': 1.0} | |
| # Extract all tables using the lattice algorithm | |
| lattice_tables = camelot.read_pdf(path, password=password, | |
| pages='all', flavor='lattice', line_scale=50, layout_kwargs=laparams) | |
| # Extract bounding boxes | |
| regions = defaultdict(list) | |
| for table in lattice_tables: | |
| bbox = [table._bbox[i] for i in [0, 3, 2, 1]] | |
| regions[table.page].append(bbox) | |
| df = pd.DataFrame() | |
| # Extract tables using the stream algorithm | |
| for page, boxes in regions.items(): | |
| areas = [','.join([str(int(x)) for x in box]) for box in boxes] | |
| stream_tables = camelot.read_pdf(path, password=password, pages=str(page), | |
| flavor='stream', table_areas=areas, row_tol=5, layout_kwargs=laparams) | |
| dataframes = [table.df for table in stream_tables] | |
| dataframes = pd.concat(dataframes) | |
| df = df.append(dataframes) | |
| return df | |
| def main(args): | |
| for file_name in os.listdir(args.in_dir): | |
| root, ext = os.path.splitext(file_name) | |
| if ext.lower() != '.pdf': | |
| continue | |
| pdf_path = os.path.join(args.in_dir, file_name) | |
| print(f'Processing: {pdf_path}') | |
| df = extract_df(pdf_path, args.password) | |
| excel_name = root + '.xlsx' | |
| excel_path = os.path.join(args.out_dir, excel_name) | |
| df.to_excel(excel_path) | |
| print(f'Processed : {excel_path}') | |
| if __name__ == '__main__': | |
| parser = argparse.ArgumentParser() | |
| parser.add_argument('--in-dir', type=str, required=True, help='directory to read statement PDFs from.') | |
| parser.add_argument('--out-dir', type=str, required=True, help='directory to store statement XLSX to.') | |
| parser.add_argument('--password', type=str, default=None, help='password for the statement PDF.') | |
| args = parser.parse_args() | |
| main(args) |
I had to install Ghostscript along with camelot-py[cv] after that it worked perfectly fine - Thank you @nikhilweee
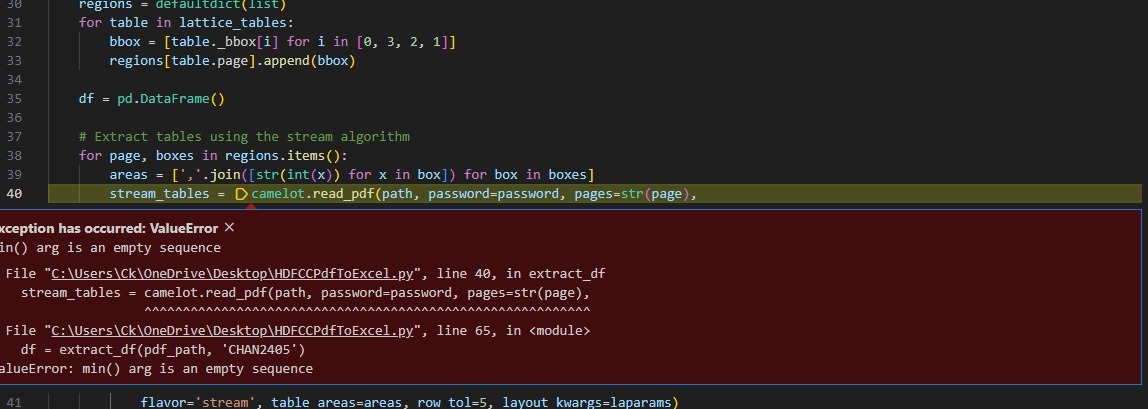
@simplyrahul I got the same error
ValueError: min() arg is an empty sequence
in my Windows system. After some debugging, I found a fix by changing the _text_bbox(t_bbox) method in camelot-py's file 'stream.py' as below. It works for me now. Hope it helps.
`
def _text_bbox(t_bbox):
"""Returns bounding box for the text present on a page.
Parameters
----------
t_bbox : dict
Dict with two keys 'horizontal' and 'vertical' with lists of
LTTextLineHorizontals and LTTextLineVerticals respectively.
Returns
-------
text_bbox : tuple
Tuple (x0, y0, x1, y1) in pdf coordinate space.
"""
xmin = 0
ymin = 0
xmax = 0
ymax = 0
if len([t.x0 for direction in t_bbox for t in t_bbox[direction]])>0:
xmin = min([t.x0 for direction in t_bbox for t in t_bbox[direction]])
ymin = min([t.y0 for direction in t_bbox for t in t_bbox[direction]])
xmax = max([t.x1 for direction in t_bbox for t in t_bbox[direction]])
ymax = max([t.y1 for direction in t_bbox for t in t_bbox[direction]])
text_bbox = (xmin, ymin, xmax, ymax)
return text_bbox
`
Thanks a lot, @nikhilweee for this! Been using it from the last three years.
While running on a new system, got the following error:
PyPDF2.errors.DeprecationError: PdfFileReader is deprecated and was removed in PyPDF2 3.0.0. Use PdfReader insteadRefer camelot-dev/camelot#339
What worked for me
python3.8 -m pip uninstall PyPDF2
python3.8 -m pip install PyPDF2~=2.0The code is not working, kindly check...
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
@cstambay glad that I could be of help :)