自分のtypoの多さが気になっているが、書いた文をじっくり読み返して校正するのが面倒なので誰かに校正してほしいと常々思っている。既存の日本語校正ツールには使いづらい点があったため、自分で入力ミス訂正ツールを作ってみた。
この記事では
について記載する。記事が長いので、興味がある項目を選んで読んでいただければ幸いである。
主にリクルートによって開発されているOSSの文章校正ツール。
ルールベースであるため、
- 何の観点でチェックに引っかかったか分かる
- チェック内容のカスタマイズを細かく行える
- 多言語対応可能
といった特長がある。
過去に使用した経験からは「チェックのルールを細かく設定して、しっかり指摘内容を読み込んで、自分で文章を直す」使い方を想定していると感じた。「適当にいい感じに自動で直してほしい」という自分の要望とコンセプトが違い、今回は利用しなかった。良い製品であるとは思う。
朝日新聞社が開発した日本語校正支援API。
朝日新聞社が持つ日本語文章の誤り訂正データを機械学習させたもの。「いい感じ」の修正案を提示してくれ、機能的はまさに求めているものだ。朝日新聞社はPFNから派生したレトリバというAIベンチャーと共同研究をしており、技術の高さ・修正精度の確かさも期待できる。
一方、TyEはソースコード非公開の商用製品であるため、利用には朝日新聞社との契約が必要になる。試用版には利用回数制限がある上、送信データは朝日新聞社に保存・利用されることが利用規約に明記されている。仕事に使うと情報漏洩が発生してしまう。
日本語文に対する単語の置換、削除による訂正提案を行える。単語の追加には対応していない。
入力できる文字列は最大128「単語」で、最大文字数は形態素解析の都合で変動する。128文字までなら確実に大丈夫である。
HTMLフォームに文字列を入力して視覚的に校正できるのに加え、APIからJSONで校正結果を取得できる。
リクエスト
GET http://localhost:9310/correct?text=${URLエンコードされたUTF-8の文字列}
レスポンス
{
# GETパラメータで入力した文字列
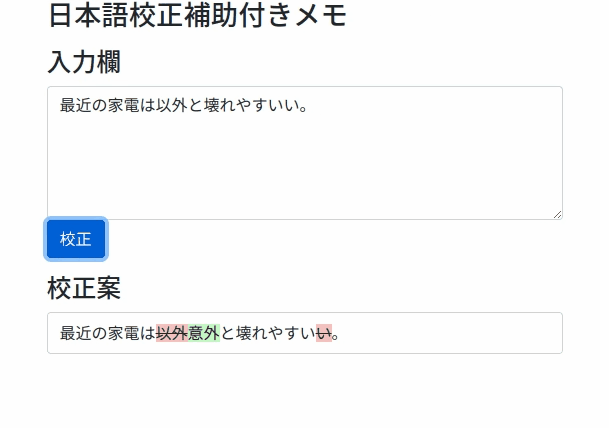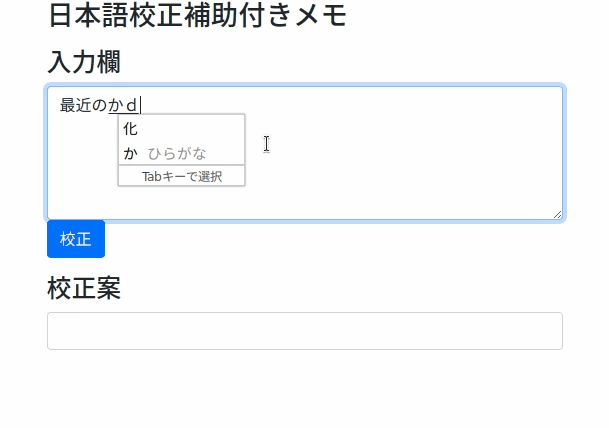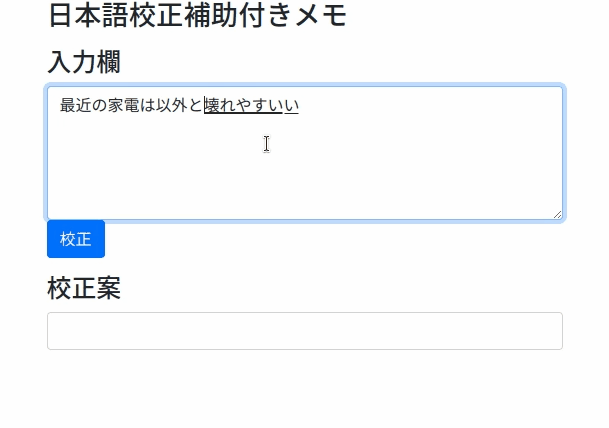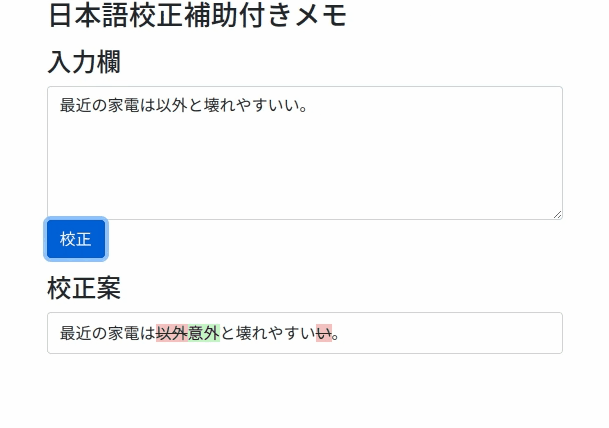
"input": "最近の家電は以外と壊れやすいい。",
# 校正後の文字列
"output": "最近の家電は意外と壊れやすい。",
# 単語単位で、どこをどう修正するべきかを示す結果
# op(operation)は null=変更不要, replace=置換すべき, delete=削除すべき
"tokens": [
{"from": "最近", "to": "最近", "op": null},
{"from": "の", "to": "の", "op": null},
{"from": "家電", "to": "家電", "op": null},
{"from": "は", "to": "は", "op": null},
{"from": "以外", "to": "意外", "op": "replace"},
{"from": "と", "to": "と", "op": null},
{"from": "壊れ", "to": "壊れ", "op": null},
{"from": "やすい", "to": "やすい", "op": null},
{"from": "い", "to": "", "op": "delete"},
{"from": "。", "to": "。", "op": null}
]
}日本語事前学習済みBERTモデルを日本語Wikipedia入力誤りデータセット (v2) でファインチューニングして校正モデルを作成した。BERTによる自然言語処理入門の内容に毛が生えた程度の実装となっている。
入力誤りがある未修正データを入力、修正済みデータを出力として学習させた。入出力の単語数が変わると学習が非常に難しくなるので、単語数が必ず揃うように削除は[MASK]への置換として学習させた。また、訂正不要の場合は入力文字列をそのまま返せば良いことを学習させるため、入出力の両方が修正後のデータを一定の割合で学習データに混ぜている。
入力: ["最近", "の", "家電", "は", "以外", "と", "壊れ", "やすい", "い", "。"]
出力: ["最近", "の", "家電", "は", "意外", "と", "壊れ", "やすい", "[MASK]", "。"]
テストデータでの正解率(accuracy)は文単位で79.28%、単語単位で99.24%となった。
この校正モデルに簡単なAPIとサンプルHTMLを追加したのが今回の実装である。校正モデルの処理がCPU・メモリ両面で重いので、リソースを過度に消費することを防ぐため並列処理を避け、直列に1件ずつ処理するようAPIを実装してある。
機能拡充、精度向上、軽量化をバラバラに検証し、芽が出た方向に進むことを予定している。
単語の追加に対応したい。
単純に単語の追加も含めた学習データを与えれば良いように見えるかもしれないが、それではうまく学習できないことが分かっている。何の工夫もなく学習させた場合、テストデータでの正解率は文単位で57.27%、単語単位で89.07%まで下がってしまった。「不必要な誤った訂正案を頻繁に出力する」という形で正解率が下がっており、体感的には邪魔でしかなかった。
この方法での学習が難しい理由は、直感的に2つ考えられる。
- 単語が文の途中に追加されると、他の単語は変更不要でも出力位置を後ろにずらす必要がある。単語の正誤に加え出力位置の変更も学習・予測する必要があり、単語数が揃っている場合と比べて課題設定自体が難しい。
- 学習データ中の入出力の単語は大部分が同じなので、「迷ったら入力単語をそのまま返す」ように学習が行われる。結果、同じ単語を繰り返すような間違いが多くなる。
["今日", "カレー", "食べ, "た"]が入力される- 2単語目("今日"と"カレー"の間)に1単語追加するのが正しそうと判断
- どの単語を入れるか迷い、可能性の高そうな
入力文字列の2単語目を採用 今日カレー食べた=>今日カレーカレー食べた
出現位置を変えずに単語追加に対応するには、単語間に予め単語追加用の枠を設けておけばよい。
入力: ["この", "[PAD]", "を", "[PAD]", "追加", "[PAD]", "し", "[PAD]", "この", "[PAD]", "単語", "[PAD]", "を", "[PAD]", "削除"]
出力: ["この", "単語", "を", "[PAD]", "追加", "[PAD]", "し", "[PAD]", "この", "[PAD]", "[MASK]", "[PAD]", "を", "[PAD]", "削除"]
この方法で学習させたところ、テストデータでの正解率は文単位で68.75%、単語単位で94.93%まで改善した。単語追加対応前と比べると精度が低いのは、単語間への[PAD]追加により入力パターンが事前学習と違うものになり、事前学習の効果を活かせなくなったためだと推測している。
[PAD]を含んだ状態で事前学習させると精度がどこまで改善するのか気になる。少しモデルは異なるが、早稲田大学が公開しているRoBERTaの事前学習はNvidia A100 GPU 8枚で1週間程度かかったと書かれている。[PAD]で入力長が2倍になると2週間程度かかり、AWS EC2のp4d.24xlarge 8インスタンスで学習させるには$88093の予算が必要と見込まれる。2週間でそんなにかかるなら、自分でA100を8枚購入して使い放題にしたほうがお得ではないか? どちらにせよ資金提供お待ちしております。
単語を追加するべき位置と数を予測するモデルを別途作成し、2段階の処理を行う案もある。ディスクとメモリの使用量が2倍になってしまうことが気がかりだが、最も現実的な案だろう。まだ実装しておらず、これから実験する予定。
["今日", "カレー", "食べ, "た"]を単語追加位置予測モデルに入力する- どこに何単語追加するべきかを示す配列
[0, 1, 0, 0, 0]が出力される ["今日", "[MASK]", "カレー", "食べ, "た"]を置換・削除予測モデルに入力する["今日", "は", "カレー", "食べ, "た"]が出力される
精度を向上させるため、モデルの変更と学習データの拡充の2案を考えている。
BERTの日本語事前学習済モデルは複数公開されている。同じBERTでより高い精度を実現したというNICT BERT 日本語 Pre-trained モデルを試したところ、テストデータでの正解率は文単位で79.45%(+0.17%)、単語単位で99.24%(+0.0%)と僅かな改善が見られた。このモデルは前処理に難があるので採用していないが、ベースモデルの精度が上がれば日本語校正の精度向上が期待できることは分かった。
2018年にBERTが登場してから現在までに、BERTよりも高精度であることを謳う後発モデルが多数生まれている。高精度なモデルはパラメータ数と計算量が多い傾向があり、残念ながらBERTの処理で精一杯の自宅サーバでは学習できないことが多い。また、日本語事前学習済モデルが公開されていることは少ない。「BERTより高精度」「BERTと同等以下の計算リソース」「日本語事前学習済」の3つを全て満たすモデルは意外と少ないのだが、見つかったら試す予定である。
モデルはそのままでも、学習データを増やせば精度向上が期待できる。日本語の文字列に機械的に誤りを加えることで、無尽蔵の学習データを手に入れられるかもしれない。人間の間違いを再現する良い方法が思いつけば試したい。データセット生成だけで年単位の研究時間を使うなら、GANで高精度な日本語誤り(?)データセットを生成できそうな気がする。
将来的にはサーバ不要、エッジ端末完結で動作させたい。モデルが小さければONNX Runtime Webを使いJavascriptのみで推論処理を完結できる。過去に作ったJavascript動作の顔検出のように静的ページで提供したり、ブラウザ拡張機能として配ることで誰でも気兼ねなく利用できるようにしたい。
現在の構成はJavascriptで動かすには大きすぎ、軽量化が必要だ。まずBERTモデルのファイルサイズが425MBあり、軽量なモデルへ置き換えは必須。前処理の形態素解析も諦めるしかない。unidic-liteは辞書が249MBもあるし、Javascriptの形態素解析器を用意するハードルもある。
ということで、モデルを軽量なALBERTに変更し、文字単位での処理を検証している。
BERT,ALBERTの入力は単語IDの配列、出力は「認識できる全単語について、その位置で出現する確率」の配列である。日本語モデルの場合は認識できる語彙を3万語程度にすることが一般的で、語彙が3万語で入出力の最大長が128単語の場合は3万 x 128 個の数値が出力となる。3万のところは、その位置に単語ID1が出現する確率, 単語ID2が出現する確率, ..., 単語ID30000が出現する確率を表している。認識できる語彙を減らすほど出力が小さくなり、パラメータを削減できる。また、単語と単語IDの相互変換表が必要となる。
今回文字単位で入出力を行うにあたり、Shift_JIS-2004の未使用領域である第一バイトの00-7F,A0-DF,FD-FFと第二バイトの00-3F,FD-FFを除去した場合のコードポイントを単語IDとして扱っている。これにより語彙数が11596に抑えられ、文字とIDの対応を簡単な計算で求められるため変換表が不要になる。
def char_to_token_id(char: str) -> int:
""" 文字から単語IDを計算する処理のサンプル。IDから文字を計算する場合は逆算する """
try:
b = bytes(c, encoding='sjis')
except:
# sjisで扱えない文字は未知語扱いとし、訂正対象外とする
return SPECIAL_TOKENS.UNKNOWN
# 1バイト文字はそのままintとして採用
if len(b) == 1:
return b[0]
# 2バイト文字の場合、
# 第一バイトは未使用の00-7FとA0-DFを除去してオフセットさせる
# 第二バイトは未使用の00-3Fを除去してオフセットさせる。
# FD-FFも使用されないため取りうるのは189パターン
# 1バイト目が81-9Fの場合
if 128 < b[0] <= 160:
# 第一バイトの00-7Fを除去してオフセットし、
# 最初の1バイトは1バイト256パターン、以降は1バイト189パターンとしてint化
b0 = 256 + 189 * (b[0] - 129)
# 第二バイトの00-3Fを除去してオフセット
b1 = b[1] - 64
return b0 + b1
# 1バイト目がE0-FCの場合
elif 224 <= b[0] < 254:
# 第一バイトの00-7F,A0-DFを除去してオフセットし、
# 最初の1バイトは1バイト256パターン、以降は1バイト189パターンとしてint化
b0 = 256 + 189 * (b[0] - 193)
# 第二バイトの00-3Fを除去してオフセット
b1 = b[1] - 64
return b0 + b1ALBERTモデルのファイルサイズは34MBとなり、形態素解析辞書と変換表の廃止も合わせれば95%のファイルサイズ縮小に成功した。
このようなエンコーディングで日本語事前学習を行ったモデルは当然世の中に存在しないので、事前学習なしで日本語校正を学習させてみた。テストデータでの正解率は文単位で45.77%、文字単位で98.85%となった。いくつかサンプルで確認したところ、不要な訂正提案はなく邪魔にはならないものの、置換に全く対応できておらず役に立たない状態になっていた。精度の向上が必要だ。
from: 最近の家電は以外と壊れやすい。
to : 最近の家電は以外と壊れやすい。
-----
from: 取るべき手順が明確でで、誤解サれないことを確認する。
to : 取るべき手順が明確で、誤解サれないことを確認する。
-----
from: 細菌サッカーが流行してているらしい。
to : 細菌サッカーが流行しているらしい。
精度が低い原因は4つ考えられる。
- 文字単位での処理に無理がある
- 軽量化のためにモデルの表現力を落としすぎている
- 日本語事前学習をしていない
- 学習データ内の訂正不要データの割合が高すぎる
エッジ完結動作のためには文字単位処理と軽量モデルは必須なので、事前学習とデータ調整でなんとか精度を上げたい。しかし事前学習には膨大な計算力が必要で、投資したところで良い結果が出る保証はなく、今後の進め方に頭を悩ませている。
学習環境
- CPU: Ryzen 1700 (8C16T)
- Memory: 16GB DDR3-2133 Dual Channel
- GPU: GeForce GTX 1070 (8GB)
- Disk: NVMe SSD 256GB
学習にかかる時間
- BERTの日本語校正ファインチューニング: 約1.5日
- ALBERTの日本語校正学習: 約8日