In this project, we will be scraping StackOverflow website and:
- Goal 1: List Most mentioned/tagged languages along with their tag counts
- Goal 2: List Most voted questions along with with their attributes (votes, summary, tags, number of votes, answers and views)
We will divide our project into the above mentioned two goals.
Before starting our project, we need to understand few basics regarding Web Scraping.
Before starting our project, we need to understand few basics regarding Web Pages and Web Scraping.
When we visit a page, our browser makes a request to a web server. Most of the times, this request is a GET Request. Our web browser then receives a bunch of files, typically (HTML, CSS, JavaScript). HTML contains the content, CSS & JavaScript tell browser how to render the webpage. So, we will be mainly interested in the HTML file.
HTML has elements called tags, which help in differentiating different parts of a HTML Document. Different types of tags are:
html- all content is inside this taghead- contains title and other related filesbody- contains main cotent to be displayed on the webpagediv- division or area of a pagep- paragrapha- links
We will get our content inside the body tag and use p and a tags for getting paragraphs and links.
HTML also has class and id properties. These properties give HTML elements names and makes it easier for us to refer to a particular element. Class can be shared among multiple elements and an element can have moer then one class. Whereas, id needs to be unique for a given element and can be used just once in the document.
The requests module in python lets us easily download pages from the web.
We can request contents of a webpage by using requests.get(), passing in target link as a parameter. This will give us a response object.
Beautiful Soup library helps us parse contents of the webpage in an easy to use manner. It provides us with some very useful methods and attributes like:
find(),select_one()- retuns first occurence of the tag object that matches our filterfind_all(),select()- retuns a list of the tag object that matches our filterchildren- provides list of direct nested tags of the given paramter/tag
These methods help us in extracting specific portions from the webpage.
Tip: When Scraping, we try to find common properties shared among target objects. This helps us in extracting all of them in just one or two commands.
For e.g. We want to scrap points of teams on a league table. In such a scenario, we can go to each element and extract its value. Or else, we can find a common thread (like same class, same parent + same element type) between all the points. And then, pass that common thread as an argument to BeautifulSoup. BeautifulSoup will then extract and return the elements to us.
Now that we know the basics of Web Scraping, we will move towards our first goal.
In Goal 1, we have to list most tagged Languages along with their Tag Count. First, lets make a list of steps to follow:
- 1. Download Webpage from stackoverflow
- 2. Parse the document content into BeautifulSoup
- 3. Extract Top Languages
- 4. Extract their respective Tag Counts
- 5. Put all code together and join the two lists
- 6. Plot Data
Let's import all the required libraries and packages
https://gist.github.com/1cb20019552735207e564a0ba542edae
We will download the tags page from stackoverflow, where it has all the languages listed with their tag count.
https://gist.github.com/2df3e99383170d9c8be3202db8271bba
200
https://gist.github.com/a300a379086b9ec369fb5d13d9370986
bs4.element.Tag
In order to acheive this, we need to understand HTML structure of the document that we have. And then, narrow down to our element of interest.
One way of doing this would be manually searching the webpage (hint: print body variable from above and search through it).
Second method, is to use the browser's Developr Tools.
We will use this second one. On Chrome, open tags page and right-click on the language name (shown in top left) and choose Inspect.

We can see that the Language name is inside a tag, which in turn is inside a lot of div tags. This seems, difficult to extract. Here, the class and id, we spoke about earlier comes to our rescue.
If we look more closely in the image above, we can see that the a tag has a class of post-tag. Using this class along with a tag, we can extract all the language links in a list.
https://gist.github.com/9689d80e4d5fb1b7b8597425bfe2670c
[<a class="post-tag" href="/questions/tagged/javascript" rel="tag" title="show questions tagged 'javascript'">javascript</a>,
<a class="post-tag" href="/questions/tagged/java" rel="tag" title="show questions tagged 'java'">java</a>]
Next, using list comprehension, we will extract all the language names.
https://gist.github.com/2a72b87540759e402bf006f4916f31a5
['javascript', 'java', 'c#', 'php', 'android']
To extract tag counts, we will follow the same process.
On Chrome, open tags page and right-click on the tag count, next to the top language (shown in top left) and choose Inspect.
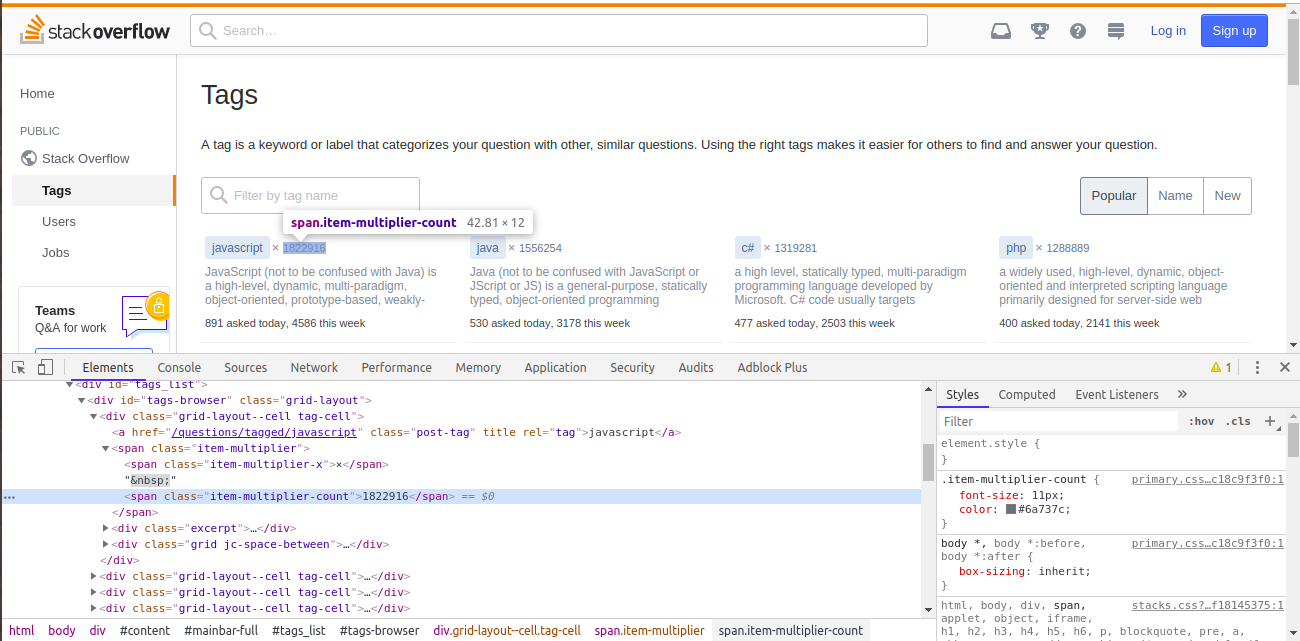
Here, the tag counts are inside span tag, with a class of item-multiplier-count. Using this class along with span tag, we will extract all the tag count spans in a list.
https://gist.github.com/a19bd6c1d86e000c24e236803048cf7f
[<span class="item-multiplier-count">1824582</span>,
<span class="item-multiplier-count">1557391</span>]
Next, using list comprehension, we will extract all the Tag Counts.
https://gist.github.com/e92f88669bf756403ffdbb6bd216bc30
[1824582, 1557391, 1320273, 1289585, 1200130]
We will use Pandas.DataFrame to put the two lists together.
In order to make a DataFrame, we need to pass both the lists (in dictionary form) as argument to our function.
https://gist.github.com/d3dab2f2060b63aba839eae8b8cb1bd1
https://gist.github.com/f2c1532d9485e985362f415b138bb2a7
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Languages | Tag Count | |
|---|---|---|
| 0 | javascript | 1824582 |
| 1 | java | 1557391 |
| 2 | c# | 1320273 |
| 3 | php | 1289585 |
| 4 | android | 1200130 |
Now, we will plot the Top Languages along with their Tag Counts.
https://gist.github.com/91205ae109bad5a0fb1534ecd3c605d3

Now that we have collected data using web scraping one time, it won't be difficult the next time.
In Goal 2 part, we have to list questions with most votes along with their attributes, like:
- Summary
- Tags
- Number of Votes
- Number of Answers
- Number of Views
I would suggest giving it a try on your own, then come here to see my solution.
Similar to previous step, we will make a list of steps to act upon:
- 1. Download Webpage from stackoverflow
- 2. Parse the document content into BeautifulSoup
- 3. Extract Top Questions
- 4. Extract their respective Summary
- 5. Extract their respective Tags
- 6. Extract their respective no. of votes, answers and views
- 7. Put all code togther and join the lists
- 8. Plot Data
We will download the questions page from stackoverflow, where it has all the top voted questions listed.
Here, I've appended ?sort=votes&pagesize=50 to the end of the defualt questions URL, to get a list of top 50 questions.
https://gist.github.com/ff1bdfb133c7858879c200638f66add7
200
In this section, we will use select() and select_one() to return BeautifulSoup objects as per our requierment. While find_all uses tags, select uses CSS Selectors in the filter. I personally tend to use the latter one more.
For example:
p a— finds all a tags inside of a p tag.
soup.select('p a')
div.outer-text— finds all div tags with a class of outer-text.div#first— finds all div tags with an id of first.body p.outer-text— finds any p tags with a class of outer-text inside of a body tag.
https://gist.github.com/1239ea01a201cdd29057006f90ff7edf
bs4.element.Tag
On Chrome, open questions page and right-click on the top question and choose Inspect.
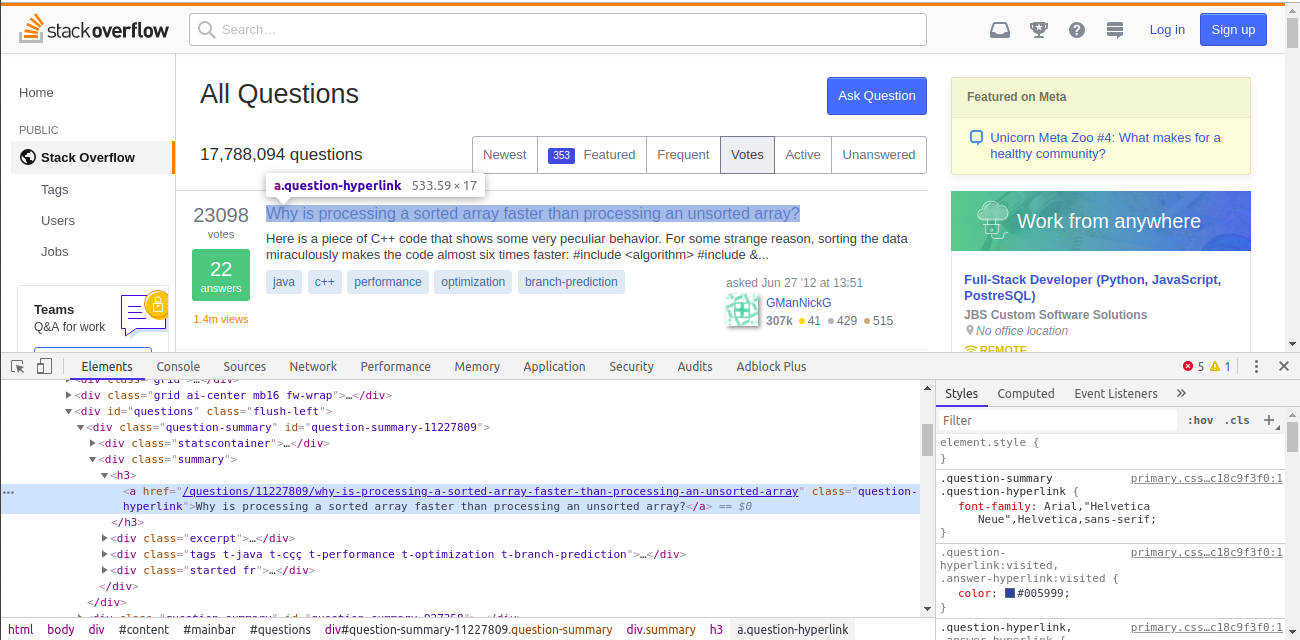
We can see that the question is inside a tag, which has a class of question-hyperlink.
Taking cue from our previous Goal, we can use this class along with a tag, to extract all the question links in a list. However, there are more question hyperlinks in sidebar which will also be extracted in this case. To avoid this scenario, we can combine a tag, question-hyperlink class with their parent h3 tag. This will give us exactly 50 Tags.
https://gist.github.com/4714fd1bbd7dfd32101b9e0c005bf9e2
[<a class="question-hyperlink" href="/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array">Why is processing a sorted array faster than processing an unsorted array?</a>,
<a class="question-hyperlink" href="/questions/927358/how-do-i-undo-the-most-recent-local-commits-in-git">How do I undo the most recent local commits in Git?</a>]
List comprehension, to extract all the questions.
https://gist.github.com/7a52e67ee1ea351e9ca8185cb45e3ba4
['Why is processing a sorted array faster than processing an unsorted array?',
'How do I undo the most recent local commits in Git?']
On Chrome, open questions page and right-click on summary of the top question and choose Inspect.
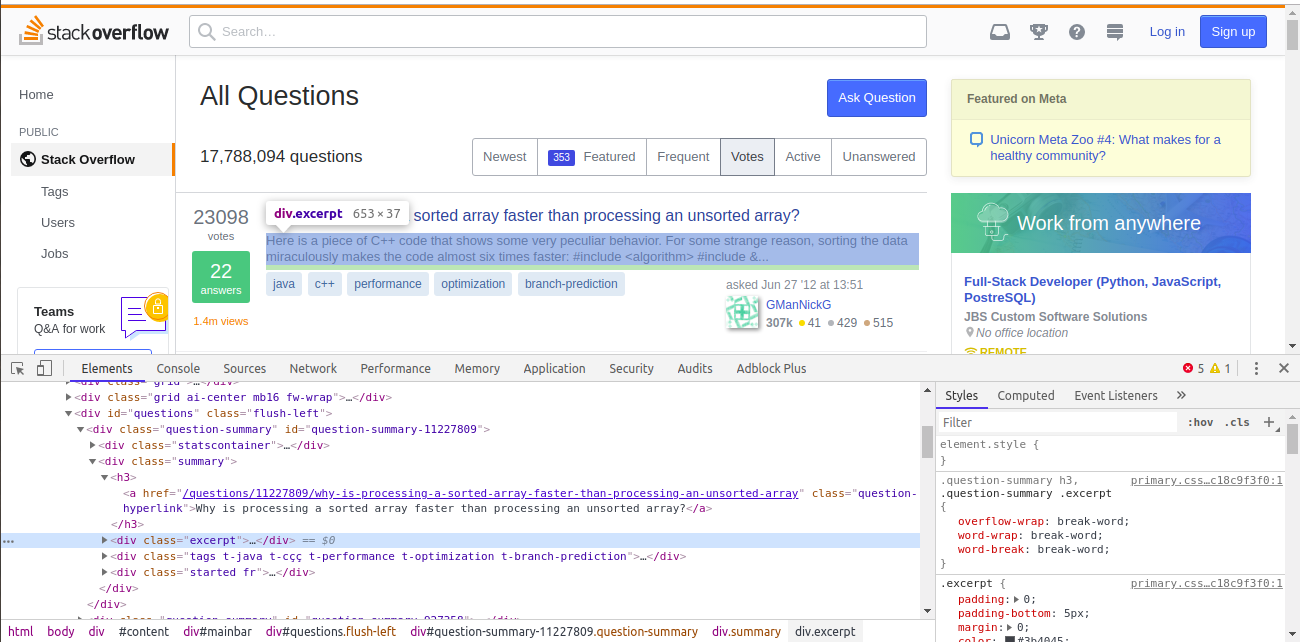
We can see that the question is inside div tag, which has a class of excerpt. Using this class along with div tag, we can extract all the question links in a list.
https://gist.github.com/f060e11714160cbe0557d385cd899e7a
<div class="excerpt">
Here is a piece of C++ code that shows some very peculiar behavior. For some strange reason, sorting the data miraculously makes the code almost six times faster:
#include <algorithm>
#include &...
</div>
List comprehension, to extract all the questions.
Here, we will also use strip() method on each div's text. This is to remove both leading and trailing unwanted characters from a string.
https://gist.github.com/5e4f88954c903952ab726cd14ff5bbbc
'Here is a piece of C++ code that shows some very peculiar behavior. For some strange reason, sorting the data miraculously makes the code almost six times faster:\n\n#include <algorithm>\n#include &...'
On Chrome, open questions page and right-click on summary of the top question and choose Inspect.

Extracting tags per question is the most complex task in this post. Here, we cannot find unique class or id for each tag, and there are multiple tags per question that we n eed to store.
To extract tags per question, we will follow a multi-step process:
- As shown in figure, individual tags are in a third layer, under two nested div tags. With the upper div tag, only having unique class (
summary).- First, we will extract div with
summaryclass. - Now notice our target div is third child overall and second
divchild of the above extracted object. Here, we can usenth-of-type()method to extract this 2nddivchild. Usage of this method is very easy and few exmaples can be found here. This method will extract the 2nddivchild directly, without extractingsummary divfirst.
- First, we will extract div with
https://gist.github.com/ab045d8d0c7acf359b195ec801b3604f
<div class="tags t-java t-cçç t-performance t-optimization t-branch-prediction">
<a class="post-tag" href="/questions/tagged/java" rel="tag" title="show questions tagged 'java'">java</a> <a class="post-tag" href="/questions/tagged/c%2b%2b" rel="tag" title="show questions tagged 'c++'">c++</a> <a class="post-tag" href="/questions/tagged/performance" rel="tag" title="show questions tagged 'performance'">performance</a> <a class="post-tag" href="/questions/tagged/optimization" rel="tag" title="show questions tagged 'optimization'">optimization</a> <a class="post-tag" href="/questions/tagged/branch-prediction" rel="tag" title="show questions tagged 'branch-prediction'">branch-prediction</a>
</div>
- Now, we can use list comprehension to extract
atags in a list, grouped per question.
https://gist.github.com/dadda8a67e05b85c4fe7cff220d3bb67
[<a class="post-tag" href="/questions/tagged/java" rel="tag" title="show questions tagged 'java'">java</a>,
<a class="post-tag" href="/questions/tagged/c%2b%2b" rel="tag" title="show questions tagged 'c++'">c++</a>,
<a class="post-tag" href="/questions/tagged/performance" rel="tag" title="show questions tagged 'performance'">performance</a>,
<a class="post-tag" href="/questions/tagged/optimization" rel="tag" title="show questions tagged 'optimization'">optimization</a>,
<a class="post-tag" href="/questions/tagged/branch-prediction" rel="tag" title="show questions tagged 'branch-prediction'">branch-prediction</a>]
- Now we will run a for loop for going through each question and use list comprehension inside it, to extract the tags names.
https://gist.github.com/462f78ddd956fd8dd4a583438dd4e353
['java', 'c++', 'performance', 'optimization', 'branch-prediction']
On Chrome, open questions page and inspect vote, answers and views for the topmost answer.
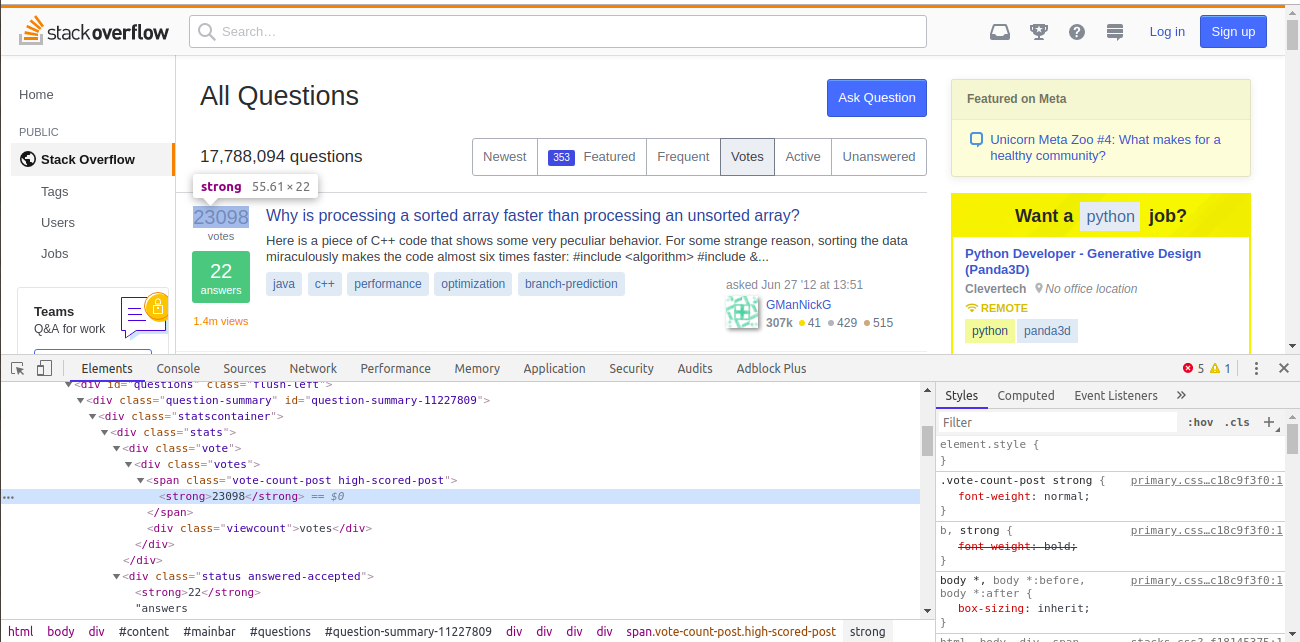
- They can be found by using
spantag along withvote-count-postclass and nestedstrongtags
https://gist.github.com/7ebfcc3d81b1f81494fad6ccd01dcd4f
[<strong>23111</strong>, <strong>19690</strong>]
List comprehension, to extract vote counts.
https://gist.github.com/fd00ff1b070dd48291a0ccdd6476ddde
[23111, 19690, 15321, 11030, 9718]
I'm not going to post images to extract last two attributes
- They can be found by using
divtag along withstatusclass and nestedstrongtags. Here, we don't useanswered-acceptedbecause its not common among all questions, few of them (whose answer are not accepted) have the class -answered.
https://gist.github.com/048d1cbd369b564f8b2dd9dde02b24be
[<strong>22</strong>, <strong>78</strong>]
List comprehension, to extract answer counts.
https://gist.github.com/0adc1f4e1b8218e60d34b7472db195f4
[22, 78, 38, 40, 34]
- For views, we can see two options. One is short form in number of millions and other is full number of views. We will extract the full version.
- They can be found by using
divtag along withsupernovaclass. Then we need to clean the string and convert it into integer format.
https://gist.github.com/04d3272bcac69fa0ed8e5be7ba0c792b
<div class="views supernova" title="1,362,267 views">
1.4m views
</div>
List comprehension, to extract vote counts.
https://gist.github.com/a667f99c948c1106211bb760ee907b59
[1362267, 7932952, 7011126, 2550002, 2490787]
https://gist.github.com/38898fcfce6c21c1518367d18dc97152
https://gist.github.com/b2ac2be7bfe949fea151666c72583084
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| question | summary | tags | no_of_votes | no_of_answers | no_of_views | |
|---|---|---|---|---|---|---|
| 0 | Why is processing a sorted array faster than p... | Here is a piece of C++ code that shows some ve... | [java, c++, performance, optimization, branch-... | 23111 | 22 | 1362267 |
| 1 | How do I undo the most recent local commits in... | I accidentally committed the wrong files to Gi... | [git, version-control, git-commit, undo] | 19690 | 78 | 7932952 |
| 2 | How do I delete a Git branch locally and remot... | I want to delete a branch both locally and rem... | [git, git-branch, git-remote] | 15321 | 38 | 7011126 |
| 3 | What is the difference between 'git pull' and ... | Moderator Note: Given that this question has a... | [git, git-pull, git-fetch] | 11030 | 40 | 2550002 |
| 4 | What is the correct JSON content type? | I've been messing around with JSON for some ti... | [json, http-headers, content-type] | 9718 | 34 | 2490787 |
https://gist.github.com/b3be5250228a90717e31a025e778dc78

Here, we may observe that there is no collinearity between the votes, views and answers related to a question.
Useful Resources: