2019-09-29 更新一版运行结果,增加 C++20 Coroutine 测试结果
| 组件(Avg) | 协程数:1 切换开销 | 协程数:1000 创建开销 | 协程数:1000 切换开销 | 协程数:30000 创建开销 | 协程数:30000 切换开销 |
|---|---|---|---|---|---|
| 栈大小(如果可指定) | 16 KB | 2 MB | 2 MB | 64 KB | 64 KB |
| C++20 Coroutine - Clang | 5 ns | 130 ns | 6 ns | 136 ns | 9 ns |
| C++20 Coroutine - MSVC | 10 ns | 407 ns | 14 ns | 369 ns | 28 ns |
| libcopp | 77 ns | 4.1 us | 105 ns | 3.8 us | 273 ns |
| libcopp+动态栈池 | 74 ns | 101 ns | 110 ns | 222 ns | 270 ns |
| libcopp+libcotask | 96 ns | 4.2 us | 156 ns | 4.2 us | 389 ns |
| libcopp+libcotask+动态栈池 | 96 ns | 197 ns | 153 ns | 329 ns | 371 ns |
| libco+静态栈池 | 84 ns | 3.9 us | 168 ns | 4.2 us | 450 ns |
| libco(共享栈4K占用) | 83 ns | 3.9 us | 529 ns | 3.9 us | 1073 ns |
| libco(共享栈8K占用) | 86 ns | 4.0 us | 828 ns | 3.9 us | 1596 ns |
| libco(共享栈32K占用) | - | 4.0 us | 9152 ns | 3.9 us | 11.5 us |
| libgo | 30 ns | 8.3 us | 5.5 us | ||
| libgo 2018年版本 with boost | 197 ns | 5.3 us | 124 ns | 2.3 us | 441 ns |
| libgo 2018年版本 with ucontext | 539 ns | 7.0 us | 482 ns | 2.7 us | 921 ns |
| goroutine(golang) | 425 ns | 1.0 us | 710 ns | 1.0 us | 1047 ns |
| linux ucontext | 439 ns | 4.4 us | 505 ns | 4.8 us | 890 ns |
关于libgo: libgo 似乎比我最早测试的版本来了一次大改版,现在它也和libcopp一样内置了boost.context了,不再能自己切ucontext;另外它的执行线程Processer采用一次性从调度器分配一堆Task的方式去调度任务。这使得它的协程任务调度过程中不再需要保证线程安全了,少了很多同步操作和状态检查的开销。它可以这么设计的其中一个原因也是它是把协程任务的接口给隐藏起来的,用户不太会去显式调用它,也就不会有误用的问题。另外它的Task对象和以前的libcopp v1版一样是另外存储的,简单压测的话和libcopp v1版一样,缓存命中率会偏高,是更加无法真实地反映实际项目中的使用的。所以简单压测协程切换它的性能逼近 boost.context 原生cache 不miss时的开销(boost.context 原生切换 cache的miss的时候也到不了30ns,印象中以前测过是60ns+)。也是这个原因,它的协程数量上来以后命中率下降之后它的性能也下降得也非常厉害。我也尝试了下稍微改动了 libgo 的代码,提高cache miss的情况下,测试数据下降也很明显,不过 libgo 的切换性能仍然是和 libcopp 相近,不过我没太深入去看它的细节,不知道为什么增大栈的情况下它的切换性能和创建性能变化很剧烈,按道理只是分配了地址空间,并没有使用到不应该有这么大的变化。另外 libgo 的
co::CoroutineOptions可以自定义全局的分配器,所以它也是可以自己手动接栈池的,否则它每次创建协程都会走mmap系统调用然后触发缺页中断,创建开销比较大。 按照 libgo 作者自己的测试来看, 关于libgo的性能大约是 goroutine(golang) 的3-4倍,这个数值可我之前测试的老版本的测试方法结果比较相近,也和 libcopp 的性能接近。所以也贴了以前的测试结果(以前跑测试的老机器和现在测试的新机器硬件有差异,老机器的单核切换性能普片比新机器高一些)。
bash ./cmake_dev.sh -b RelWithDebInfo -us;
make -j4;
make benchmark;/usr/local/go/bin/go build -o goroutine_benchmark goroutine_benchmark.go;
./goroutine_benchmark 1 3000000;
./goroutine_benchmark 1000 1000;
./goroutine_benchmark 30000 100;g++ -O2 -g -DNDEBUG -ggdb -Wall -Werror -fPIC ucontext_benchmark.cpp -o ucontext_benchmark ;
./ucontext_benchmark 1 3000000 16;
./ucontext_benchmark 1000 1000 2048;
./ucontext_benchmark 30000 100 64;# build libco
mkdir build && cd build;
cmake ../libco;
make -j4;
cd ..;
# build exe
g++ -O2 -g -DNDEBUG -ggdb -Wall -Werror -fPIC libco_benchmark.cpp build/libcolib.a -o libco_benchmark -Ilibco -lpthread -lz -lm -ldl ;
# static stack pool
./libco_benchmark 1 3000000 16;
./libco_benchmark 1000 1000 2048;
./libco_benchmark 30000 100 64;
# shared stack=4K
./libco_benchmark 1 3000000 16 4;
./libco_benchmark 1000 1000 2048 4;
./libco_benchmark 30000 100 64 4;
# shared stack=8K
./libco_benchmark 1 3000000 16 8;
./libco_benchmark 1000 1000 2048 8;
./libco_benchmark 30000 100 64 8;
# shared stack=32K
./libco_benchmark 1000 1000 2048 32;
./libco_benchmark 30000 100 64 32;最新的 libgo 已经内置 boost.context 了, 不需要再指定BOOST安装地址
# build libgo
mkdir build && cd build;
cmake ../libgo -DCMAKE_BUILD_TYPE=RelWithDebInfo;
make -j4;
cd ..;
# build exe
g++ -O2 -g -DNDEBUG -ggdb -Wall -Werror -fPIC libgo_benchmark.cpp -o libgo_benchmark -Ilibgo -Ilibgo/libgo -Ilibgo/libgo/linux -Lbuild -llibgo -lrt -lpthread -ldl;
./libgo_benchmark 1 3000000 16;
./libgo_benchmark 1000 1000 2048;
./libgo_benchmark 30000 100 64;最新的 libgo 已经内置 boost.context了,没有使用ucontext的选项了,这个分支仅针对老版本
# build libgo
mkdir build && cd build;
cmake ../libgo -DCMAKE_BUILD_TYPE=RelWithDebInfo -DENABLE_BOOST_CONTEXT=NO;
make -j4;
cd ..;
# build exe
g++ -O2 -g -DNDEBUG -ggdb -Wall -Werror -fPIC libgo_benchmark.cpp -o libgo_benchmark -Ilibgo -Ilibgo/libgo -Ilibgo/libgo/linux -Lbuild -llibgo -lrt -lpthread -ldl;
./libgo_benchmark 1 3000000 16;
./libgo_benchmark 1000 1000 2048;
./libgo_benchmark 30000 100 64;clang++ -std=c++2a -O2 -g -ggdb -stdlib=libc++ -fcoroutines-ts -lc++ -lc++abi cxx20_coroutine.cpp -o cxx20_coroutine
./cxx20_coroutine 1 3000000
./cxx20_coroutine 1000 1000
./cxx20_coroutine 30000 1000cl /nologo /O2 /std:c++latest /Zi /MDd /Zc:__cplusplus /EHsc /await cxx20_coroutine.cpp
./cxx20_coroutine.exe 1 3000000
./cxx20_coroutine.exe 1000 1000
./cxx20_coroutine.exe 30000 1000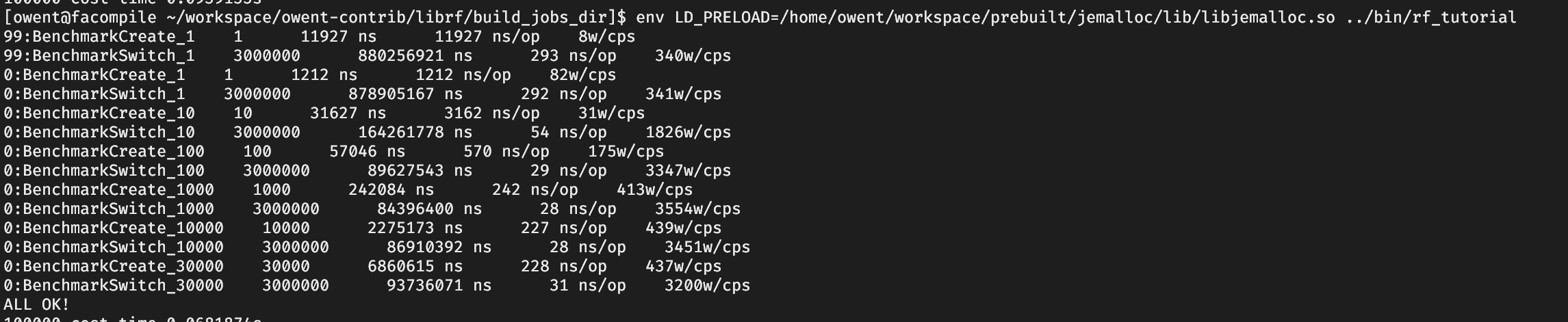
有兴趣测试下librf吗?
https://github.com/tearshark/librf
运行resumable_main_resumable()函数即可得到结果。