Create a Movie Score Prediction Model with BQML custom ML and all of this only using SQL.
-
A browser, such as Chrome or Firefox.
-
A Google Cloud project with billing enabled.
Keep these links handy (if you wish to follow along)
-
On the project selector page, create a Google Cloud project.
-
Enable the BigQuery and Vertex AI APIs.
-
Open the Google Cloud Shell.


-
Preparing: For the purpose of this blog we are going to use this data file that is already prepared.
-
Creating:
-
Use the
bq mkcommand to create a dataset called "movies":bq mk --location=us-central1 movies
-
Clone the repository (for data file) and navigate to the project:
git clone https://github.com/AbiramiSukumaran/movie-score.git cd movie-score
-
Use the
bq loadcommand to load your CSV file into a BigQuery table:bq load --source_format=CSV --skip_leading_rows=1 movies.movies_score \ ./movies_bq_src.csv \ Id:numeric,name:string,rating:string,genre:string,year:numeric,released:string,score:string,director:string,writer:string,star:string,country:string,budget:numeric,company:string,runtime:numeric,data_cat:string
Options Description:
--source_format=CSV- uses the CSV data format when parsing the data file.--skip_leading_rows=1- skips the first line in the CSV file because it is a header row.movies.movies- the first positional argument—defines which table the data should be loaded into../movies.csv—the second positional argument—defines which file to load.In addition to local files, the
bq loadcommand can load files from Cloud Storage with gs://my_bucket/path/to/file URIs. A schema, which can be defined in a JSON schema file or as a comma-separated list.The final result should look like this:
-
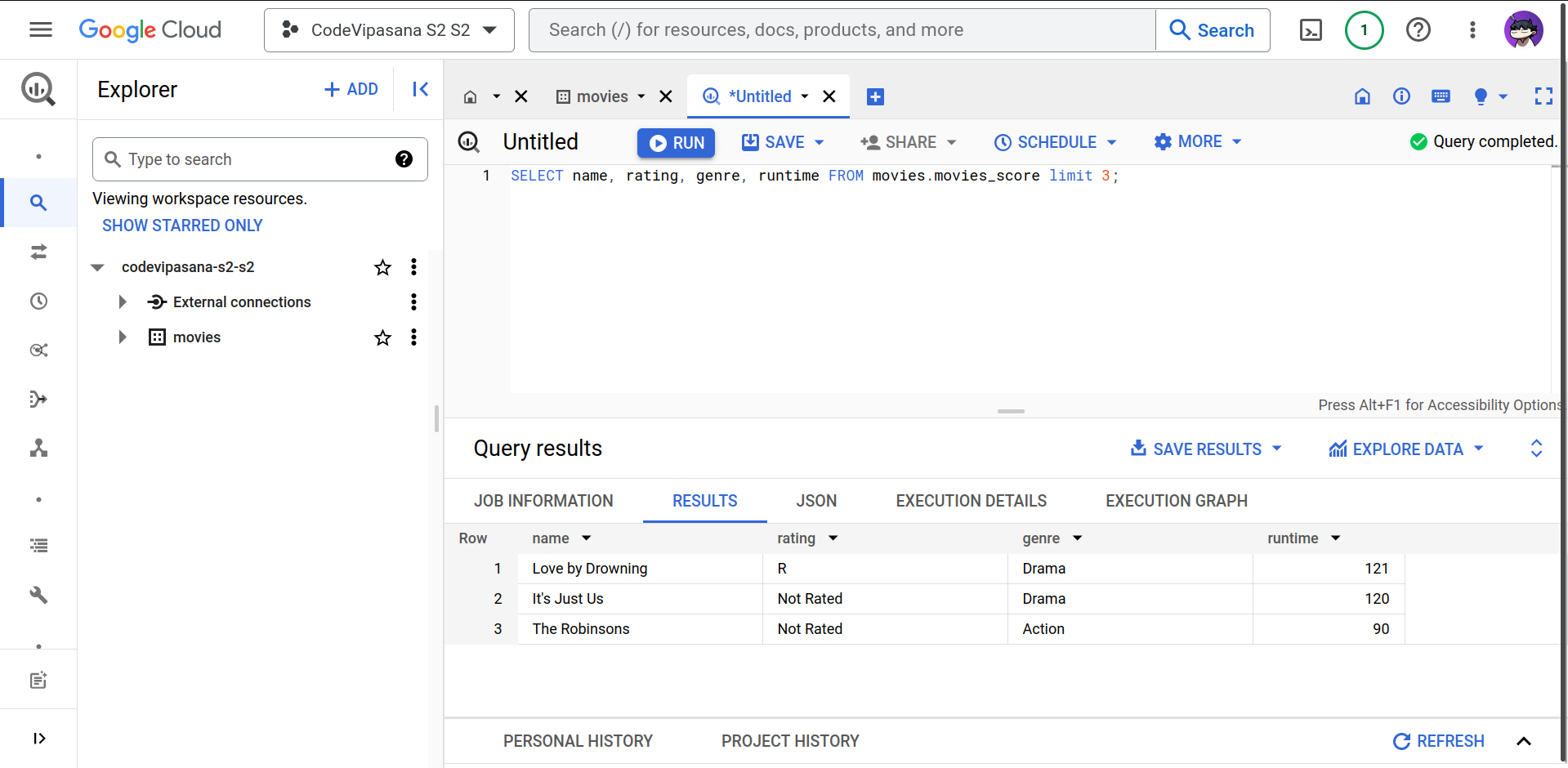
Using the BigQuery web UI, run:
SELECT name, rating, genre, runtime FROM movies.movies_score limit 3;
-

BigQuery ML supports supervised learning with the logistic regression model type. You can use the binary logistic regression model type to predict whether a value falls into one of two categories; or, you can use the multi-class regression model type to predict whether a value falls into one of multiple categories. These are known as classification problems because they attempt to classify data into two or more categories.
-
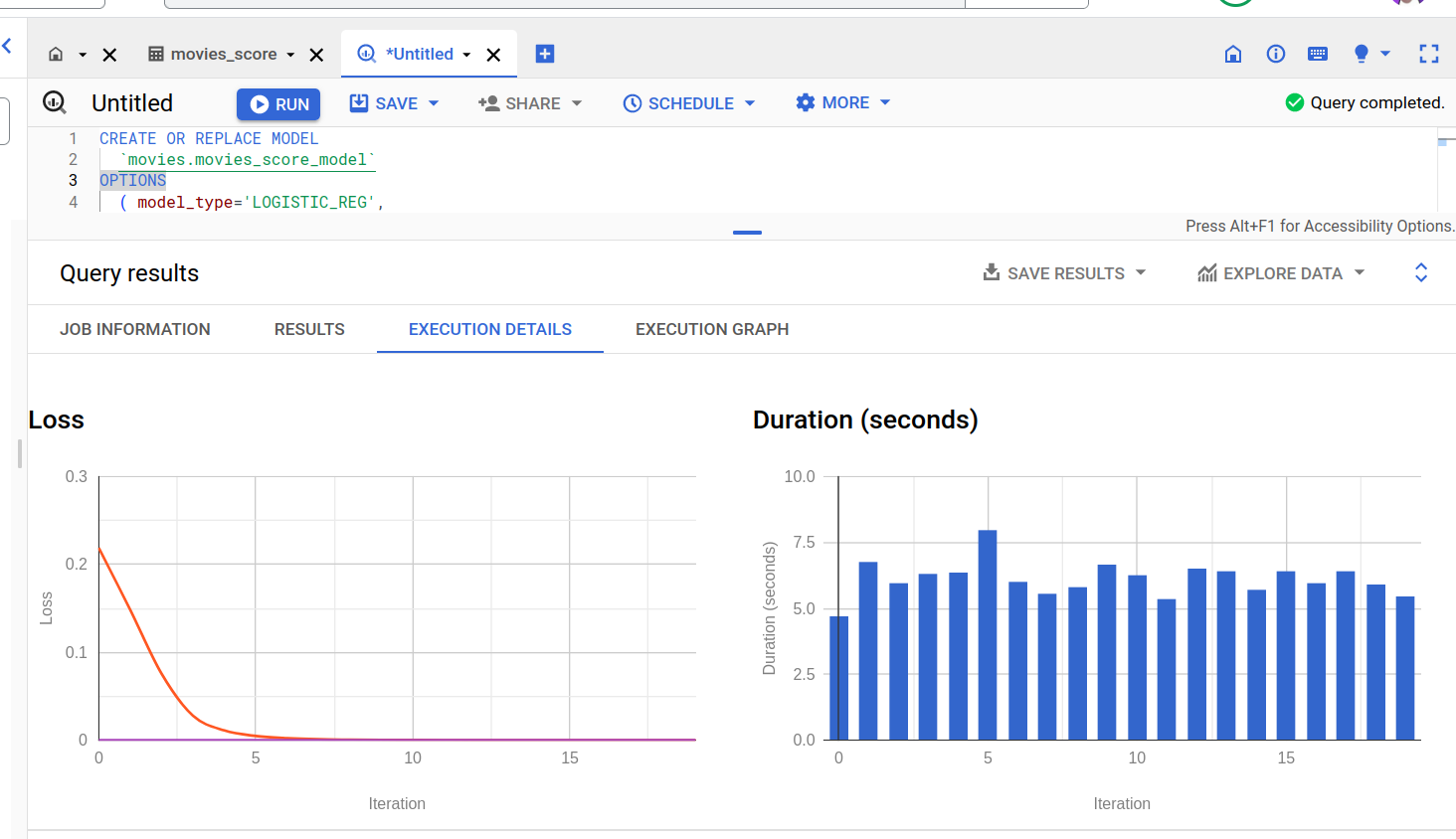
Create the logistic regression model:
CREATE OR REPLACE MODEL `movies.movies_score_model` OPTIONS ( model_type='LOGISTIC_REG', auto_class_weights=TRUE, data_split_method='NO_SPLIT', input_label_cols=[‘score'] ) AS SELECT * EXCEPT(id, data_cat) FROM ‘movies.movies_score' WHERE data_cat = 'TRAIN';
Query Details:
-
The CREATE MODEL statement trains a model using the training data in the SELECT statement
-
The OPTIONS clause specifies the model type and training options. Here, the LOGISTIC_REG option specifies a logistic regression model type. It is not necessary to specify a binary logistic regression model versus a multiclass logistic regression model: BigQuery ML can determine which to train based on the number of unique values in the label column
-
data_split_method=‘NO_SPLIT' forces BQML to train on the data per the query conditions (data_cat = ‘TRAIN'), also note that it's better to use the ‘AUTO_SPLIT' in this option to allow the framework (or service in this case) to randomize the partition of train/test splits
-
The input_label_cols option specifies which column in the SELECT statement to use as the label column. Here, the label column is score, so the model will learn which of the 10 values of score is most likely based on the other values present in each row
-
The ‘auto_class_weights=TRUE' option balances the class labels in the training data. By default, the training data is unweighted. If the labels in the training data are imbalanced, the model may learn to predict the most popular class of labels more heavily
-
The SELECT statement queries the table we loaded with the CSV data. The WHERE clause filters the rows in the input table so that only the TRAIN dataset is selected in this step
-
-
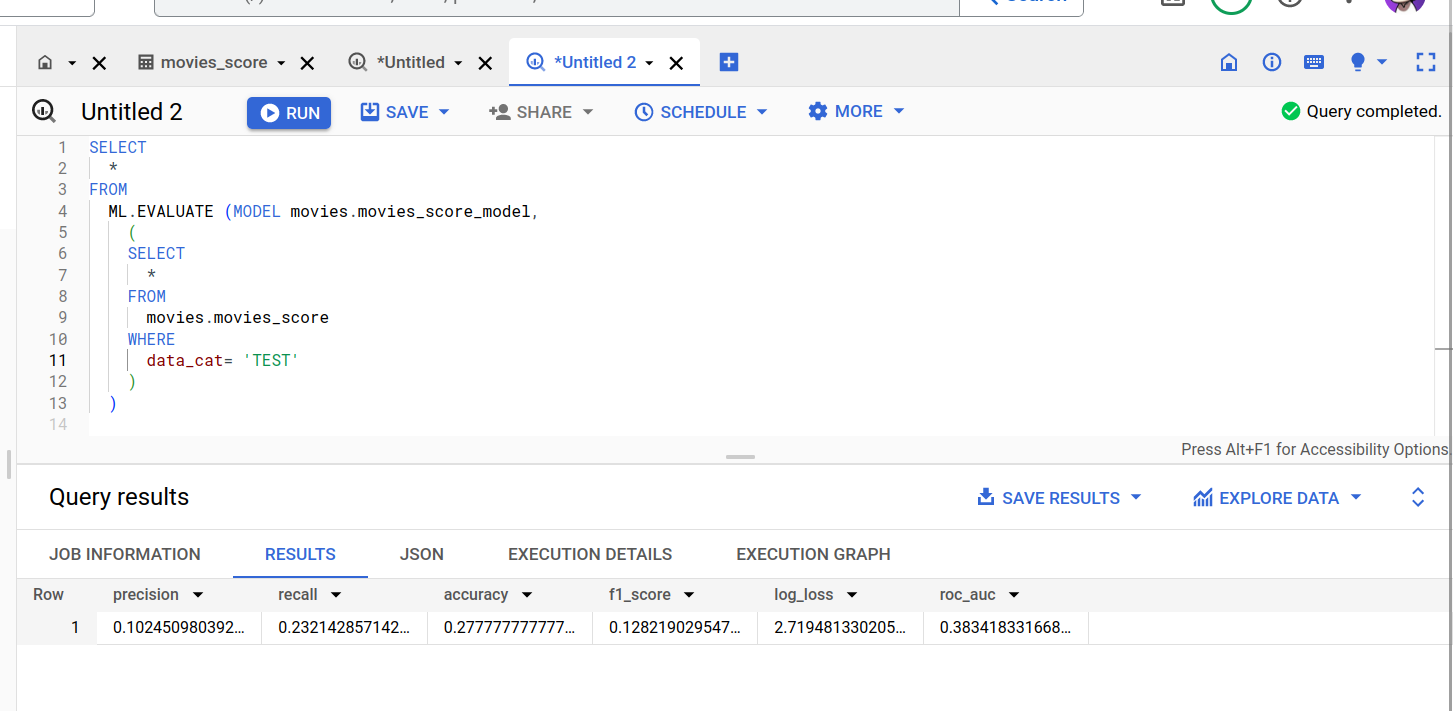
Evaluate your logistic regression model:
SELECT * FROM ML.EVALUATE (MODEL movies.movies_score_model, ( SELECT * FROM movies.movies_score WHERE data_cat= ‘TEST' ) )
The ML.EVALUATE function takes the model trained in our previous step and evaluation data returned by a SELECT subquery. The function returns a single row of statistics about the model.
-
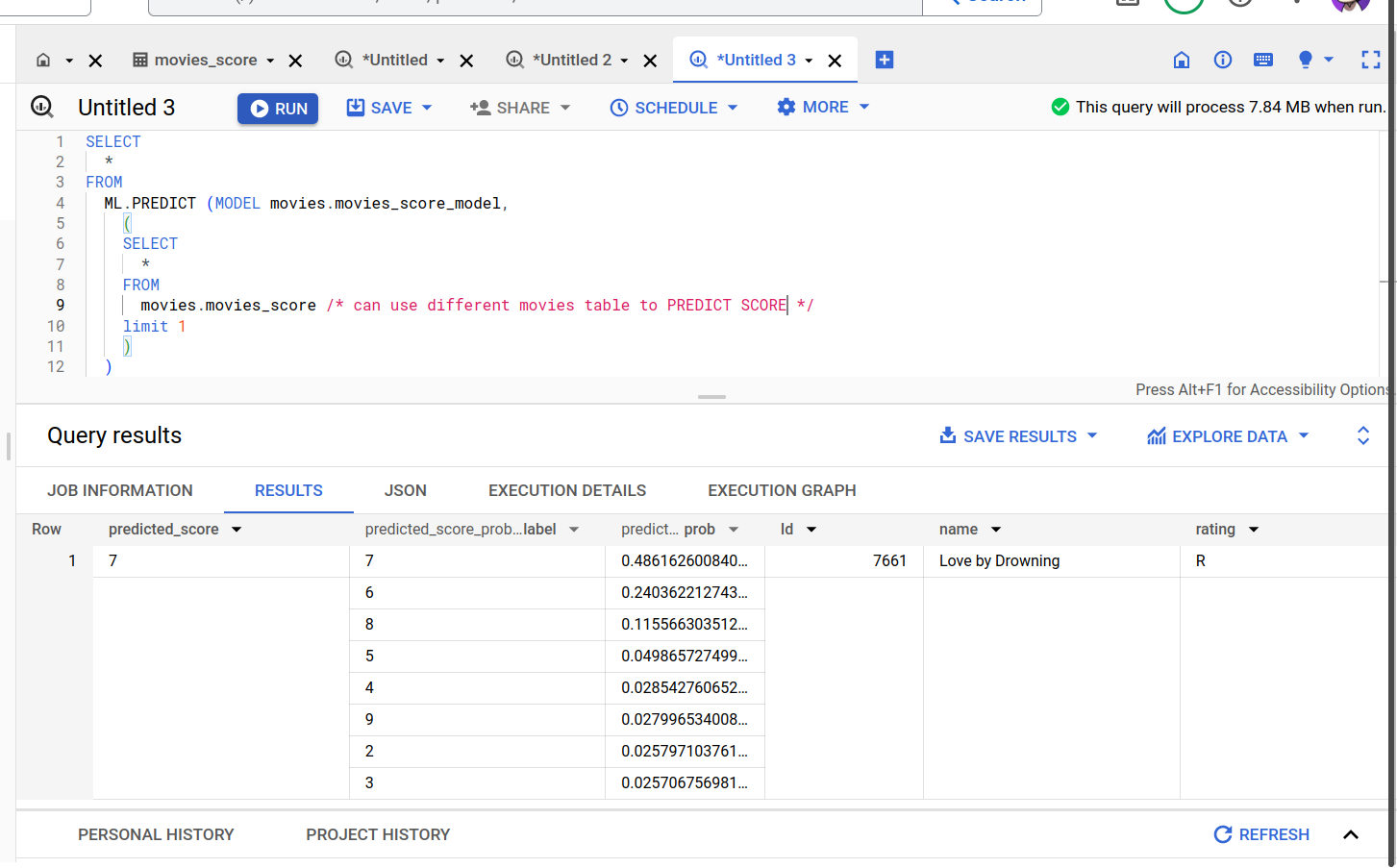
Predict movie ratings using ML.PREDICT:
SELECT * FROM ML.PREDICT (MODEL movies.movies_score_model, ( SELECT * FROM movies.movies_score limit 1 ) )
The model result shows the predicted SCORE of the movie on a scale of 1 to 10 (classification) and their probabilities.
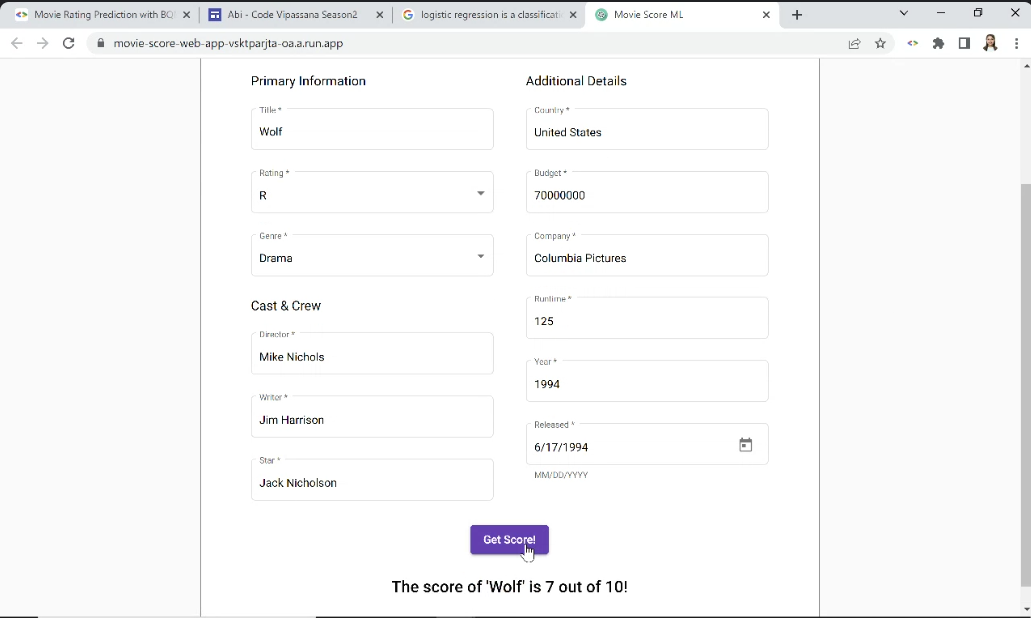
- Deploy the model and make it available as an API endpoint.
-
How to take data (from day-to-day life) and make a simple ML model using GCP using point and click methodologies.
-
Create a simple Classification model.
-
Create a custom prediction model using only BigQuery data SQLs and no other coding