On Jul 4, 2017 theverge.com posted an article about photobucket (silently) no longer allowing their users to source their images on 3rd party websites for free, thus leaving websites all over the web broken displaying the following image in replace:

Me being one of those individual, I attempted to go into my photobucket account and download my content as I now have my own hosting I am able to store those images on; however, the only ways to bulk download (on desktop) is by downloading albums through their interface. Doing so, gave me the following error message: "Hmmm. Something didn't click. Want to give it another shot? Try again now."
Doing this serveral times, in different browsers (chrome, firefox and safari), after disabling all my addons and extensions (including ad blockers), it still didn't work.
At this point, doing anything on their website would flood my screen with popups and 3+ ads. I swear I haven't seen anything like it since AOL. But I took screenshots of the errors, doing my due diligance and went to create a ticket for their support team to investigate. Only one problem: their ticket creation system's image uploader doesn't work. Interesting considering their whole business model is designed around you being able to upload images to their interface and serve them on the web...
At this point, I am just under the impression everything is broken and this site is just run down hoping it will get fixed soon. But after talking to their support, they pretty much shrugged their shoulders and said "if you don't have the android app, thats the only way to download them" - HENCE why I am writing this how-to on getting all your image!
- Ability to run bash commands
- Terminal application to run bash on
- Text editor
- Patience to collect all the links via the ad cluttered photobucket website
Fun fact: Unlike photobuckets interface, this also works with your video files and gifs.
- Navigate to the album or folder you are wanting to download
- Check one of the boxes of the images you want to download
- A
select alloption will pop up in the buttons above, click that button - this will select all the images in that album, not just the images on your current page view. - At the bottom of your screen, a menu bar will show up with your selections. WAIT for the number count of selected items to update before moving onto the next step!
- Navigate to the next album or folder you want to download and select those images as well. The selection you made from the previous album(s) will continue to accumulate as you continue to move from album to album.
- Once you have collected all the items you want to download, click the
linkoption at the menu displayed at the bottom of the screen - Photobucket will populate a box with all the direct links to the content you've selected, once you click on this, it will copy them to your computer's clipboard. NOTE: I had to do this in firefox, because the button to copy the links didn't work in chrome (might have been a popup blocker or something of that nature)
- Create a folder on your desktop titled
photobucket - Open a text editor you have on your computer (I use sublime which is available for Mac and PC), paste your links into a new blank document and save it on your photobucket folder on your desktop as a txt file type (ie. photobucket_files.txt)
- Open up a terminal based application and run the following commands:





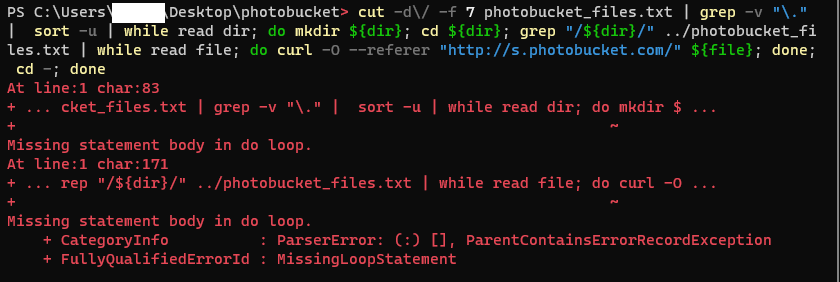
cd ~/Desktop/photobucket
cut -d\/ -f 7 photobucket_files.txt | grep "\." | while read file; do grep "${file}$" photobucket_files.txt; done | while read file; do curl -O --referer "http://s.photobucket.com/" ${file}; done
cut -d\/ -f 7 photobucket_files.txt | grep -v "\." | sort -u | while read dir; do mkdir ${dir}; cd ${dir}; grep "/${dir}/" ../photobucket_files.txt | while read file; do curl -O --referer "http://s.photobucket.com/" ${file}; done; cd -; done
What this does is tricks the request to the image file is coming from photobucket themselves by definining --referer "http://s.photobucket.com/" allowing you to download the file without dealing with the redirect to their upgrade/update image.
According to the time stamps of my commands, it took roughly 8 minutes for all of the content to download (~347M worth of content, over 1300 files).
NOTE: These scripts will create the albums for you on your personal computer; however, it will only create the albums one level deep. So I feel like this is more than enough just to get away from them if you need to download your content and don't want to pay them.
These one-liners aren't the cleanest in regards to code, but this isn't something I have any interest in cleaning up or improving as it completed the job it was intended for with me.
Hope this helps you as it did me.




{kind=link}
I've done this, I'm still getting the same result.