Current configuration works for my GPU and notebook, hope it helps
It is based on (a different configuration): https://gist.github.com/jganzabal/8e59e3b0f59642dd0b5f2e4de03c7687
and on (multiple choices for different GPU drivers): https://www.tonymacx86.com/threads/nvidia-releases-alternate-graphics-drivers-for-macos-sierra-10-12-6-378-05-05-25.227494/
- MacBook Pro (Retina, 13-inch, Early 2015)
- Nvidia Video Card: GTX 1080 Ti
- EGPU: Akitio Node
- Apple Thunderbolt3 to Thunderbolt2 Adapter
- Apple Thunderbolt2 Cable
- macOS Sierra Version 10.12.6 (16G1036)
- GPU Driver Version: 10.18.5 (378.05.05.25f03)
- CUDA Driver Version: 8.0.90 (IMPORTANT: The two drivers should be matched with each other)
- cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0: Need to register and download
- tensorflow-gpu 1.0.0
- ShutDown your system, power it up again with pressing (⌘ and R) keys until you see , this will let you in Recovery Mode.
- From the Menu Bar click Utilities > Terminal and write ‘csrutil disable; reboot’ press enter to execute this command.
- When your mac restarted, run this command in Terminal:
cd ~/Desktop; git clone https://github.com/goalque/automate-eGPU.git; chmod +x ~/Desktop/automate-eGPU/automate-eGPU.sh; sudo ~/Desktop/automate-eGPU/./automate-eGPU.sh
- Unplug your eGPU from your Mac, and restart. This is important if you did not unplug your eGPU you may end up with black screen after restarting.
- When your Mac restarted, Open up Terminal and execute this command: sudo ~/Desktop/automate-eGPU/./automate-eGPU.sh -a
- Plug your eGPU to your mac via TH2.
- Restart your Mac.
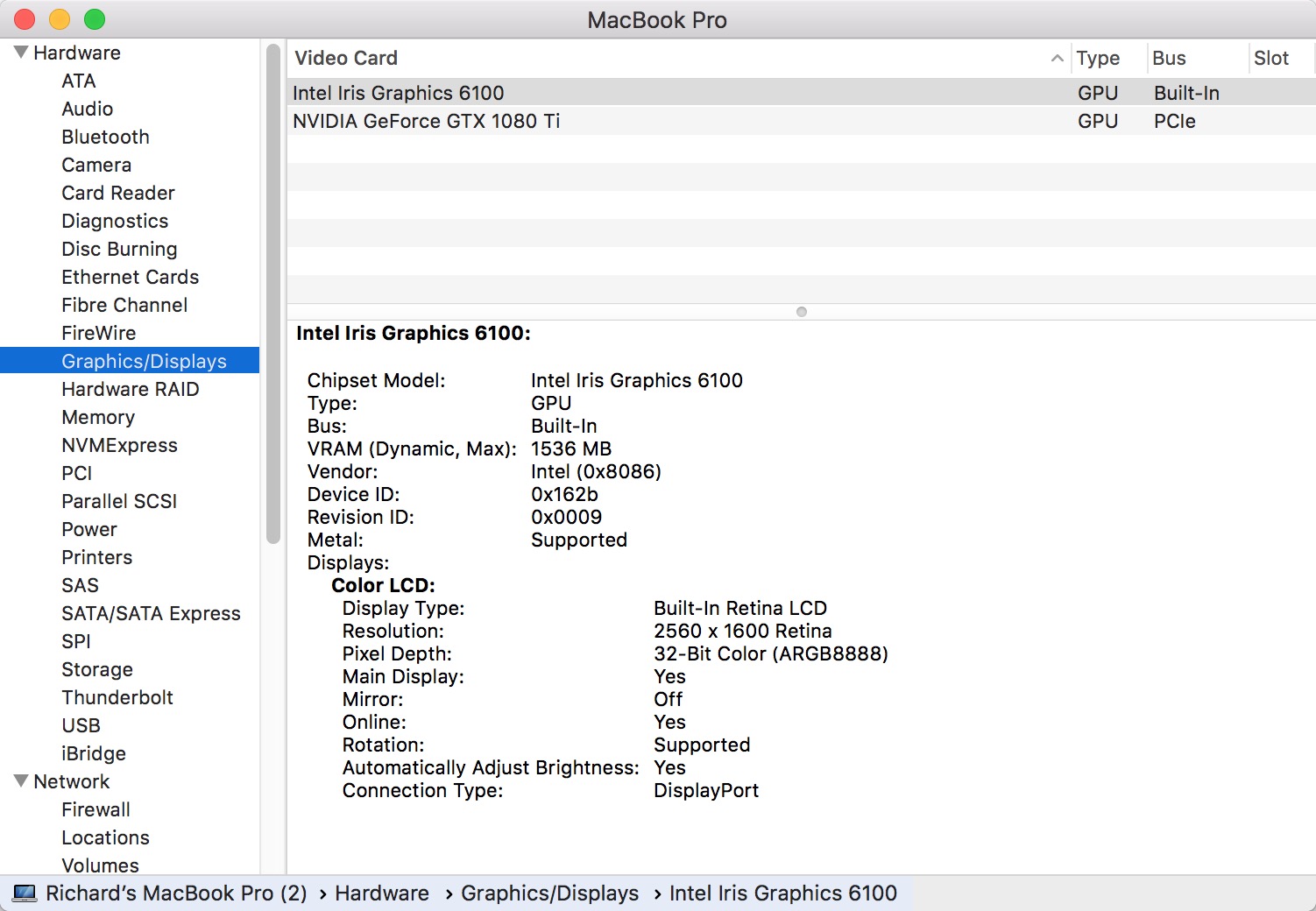
- Got to About this Mac / Sytem Report / Graphics/Displays and you should see the Nvidia Card with the correct model.
- Disconnect and Re-plug GPU for later use:
# restart and unplug
sudo ~/Desktop/automate-eGPU/./automate-eGPU.sh -a
# plug
# restart
A supported version of Xcode must be installed on your system, which in the case of macOS Sierra 10.12.6, is version 8.2.1. Older versions of Xcode can be downloaded from the Apple Developer Download Page. Once downloaded, the Xcode.app folder should be copied to a version-specific folder within /Applications. For example, in my case Xcode 8.2.1 could be copied to /Applications/Xcode_8.2.1.app.
Once an older version of Xcode is installed, it can be selected for use by running the following command, replacing <Xcode_install_dir> with the path that you copied that version of Xcode to, in my case is:
sudo xcode-select -s /Applications/XCode8.2.1/Xcode.app/
The CUDA Toolkit requires that the native command-line tools are already installed on the system. Xcode must be installed before these command-line tools can be installed. The command-line tools can be installed by running the following command:
xcode-select --install
You can verify that the toolchain is installed by running the following command:
/usr/bin/cc --version
Ouput:
Apple LLVM version 8.0.0 (clang-800.0.42.1)
Target: x86_64-apple-darwin16.7.0
Thread model: posix
InstalledDir: /Applications/XCode8.2.1/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin
Install CUDA driver and CUDA 8.0 Toolkit GA2 (Feb 2017):
- Follow the GUI instruction and install the toolkit first and then the driver (with a newer update), sequence IMPORTANT
- Set up the env variables
nano ~/.bash_profile
export CUDA_HOME=/usr/local/cuda
export DYLD_LIBRARY_PATH="$CUDA_HOME/lib:$CUDA_HOME:$CUDA_HOME/extras/CUPTI/lib"
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib:$LD_LIBRARY_PATH
source ~/.bash_profile
- Verify CUDA successfully identify your GPU device
cd /usr/local/cuda/samples
sudo make -C 1_Utilities/deviceQuery
./bin/x86_64/darwin/release/deviceQuery
Output:
./bin/x86_64/darwin/release/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1080 Ti"
CUDA Driver Version / Runtime Version 8.0 / 8.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 11264 MBytes (11810963456 bytes)
(28) Multiprocessors, (128) CUDA Cores/MP: 3584 CUDA Cores
GPU Max Clock rate: 1582 MHz (1.58 GHz)
Memory Clock rate: 5505 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 2883584 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 195 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 8.0, CUDA Runtime Version = 8.0, NumDevs = 1, Device0 = GeForce GTX 1080 Ti
Result = PASS
- If sth wrong, Uninstall and delete CUDA files
cd /Developer/NVIDIA/CUDA-8.0/bin
sudo perl uninstall_cuda_8.0.pl
# Driver: /Library/Frameworks/CUDA.framework
sudo rm -rf /usr/local/cuda
sudo rm -rf /Library/Frameworks/CUDA.framework
sudo rm -rf /System/Library/Extensions/CUDA.kext
sudo rm -rf /Library/LaunchAgents/com.nvidia.CUDASoftwareUpdate.plist
sudo rm -rf /Library/PreferencePanes/CUDA/Preferences.prefPane
sudo rm -rf /System/Library/StartupItems/CUDA/
# Toolkit
sudo rm -rf /Developer/NVIDIA
Install cuDNN (cudnn-8.0-osx-x64-v5.1), register needed
- Copy cuDNN files to ~/Desktop
cd ~/Desktop
tar -zxf cudnn-8.0-osx-x64-v5.1.tgz
- unzip and copy to CUDA
cd ~/cuda
sudo cp include/* /usr/local/cuda/include/
sudo cp lib/* /usr/local/cuda/lib/
- Create envirenment and install tensorflow
cd ~
conda create -n egpu python=3
source egpu/bin/activate
pip install tensorflow-gpu==1.0.0
- Copy the following script:
nano easy.py
import tensorflow as tf
with tf.device('/gpu:0'):
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
with tf.Session() as sess:
print (sess.run(c))
- Run the script:
python easy.py
See output:
I tensorflow/stream_executor/dso_loader.cc:135] successfully opened CUDA library libcublas.8.0.dylib locally
I tensorflow/stream_executor/dso_loader.cc:135] successfully opened CUDA library libcudnn.5.dylib locally
I tensorflow/stream_executor/dso_loader.cc:135] successfully opened CUDA library libcufft.8.0.dylib locally
I tensorflow/stream_executor/dso_loader.cc:135] successfully opened CUDA library libcuda.1.dylib locally
I tensorflow/stream_executor/dso_loader.cc:135] successfully opened CUDA library libcurand.8.0.dylib locally
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:874] OS X does not support NUMA - returning NUMA node zero
I tensorflow/core/common_runtime/gpu/gpu_device.cc:885] Found device 0 with properties:
name: GeForce GTX 1080 Ti
major: 6 minor: 1 memoryClockRate (GHz) 1.582
pciBusID 0000:c3:00.0
Total memory: 11.00GiB
Free memory: 10.81GiB
I tensorflow/core/common_runtime/gpu/gpu_device.cc:906] DMA: 0
I tensorflow/core/common_runtime/gpu/gpu_device.cc:916] 0: Y
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:c3:00.0)
[[ 22. 28.]
[ 49. 64.]]
eGPU node with GPU card mounted:

GPU recognized and shown in System Report
CUDA is able to detect GPU driver, with no update required
