-
-
Save rishuatgithub/f864fd8ea7be992bb985da4372094370 to your computer and use it in GitHub Desktop.
| package com.rks.git.pdf.parser.build; | |
| import java.io.File; | |
| import java.io.IOException; | |
| import java.util.List; | |
| import org.apache.pdfbox.pdmodel.PDDocument; | |
| import technology.tabula.ObjectExtractor; | |
| import technology.tabula.Page; | |
| import technology.tabula.RectangularTextContainer; | |
| import technology.tabula.Table; | |
| import technology.tabula.extractors.SpreadsheetExtractionAlgorithm; | |
| public class PDFParserMaster { | |
| public static void main(String[] args) throws IOException { | |
| // TODO Auto-generated method stub | |
| final String FILENAME="C:\\Users\\Rishu\\Downloads\\PDF Parser Data Test.pdf"; | |
| PDDocument pd = PDDocument.load(new File(FILENAME)); | |
| int totalPages = pd.getNumberOfPages(); | |
| System.out.println("Total Pages in Document: "+totalPages); | |
| ObjectExtractor oe = new ObjectExtractor(pd); | |
| SpreadsheetExtractionAlgorithm sea = new SpreadsheetExtractionAlgorithm(); | |
| Page page = oe.extract(1); | |
| // extract text from the table after detecting | |
| List<Table> table = sea.extract(page); | |
| for(Table tables: table) { | |
| List<List<RectangularTextContainer>> rows = tables.getRows(); | |
| for(int i=0; i<rows.size(); i++) { | |
| List<RectangularTextContainer> cells = rows.get(i); | |
| for(int j=0; j<cells.size(); j++) { | |
| System.out.print(cells.get(j).getText()+"|"); | |
| } | |
| System.out.println(); | |
| } | |
| } | |
| } | |
| } |
Hi rish,
I tried your program. But still not able to read the PDF which contains tabular data.Working till getting no. of pages. Any help, please !
This code base work for a simple tablular PDF file. this will not work for complex scenarios. Request you to share your file..
Hi rish,
I tried your program and it seems excellent but I have a problem that when I process my PDF file the data of any page is tripled.
Hi rish,
I tried your program and it seems excellent but I have a problem that when I process my PDF file the data of any page is tripled.
It's difficult to say unless I can see the pdf file. Try debugging the code with your pdf and find if there is any issue with the loops.
@Vatsala12
For complex pdf, please use NurminenDectectionAlgorithm to detect. It is a bit more complex as you may have to use a combination of Tabula and Tika. Alternatively you could try some of the cloud services available.
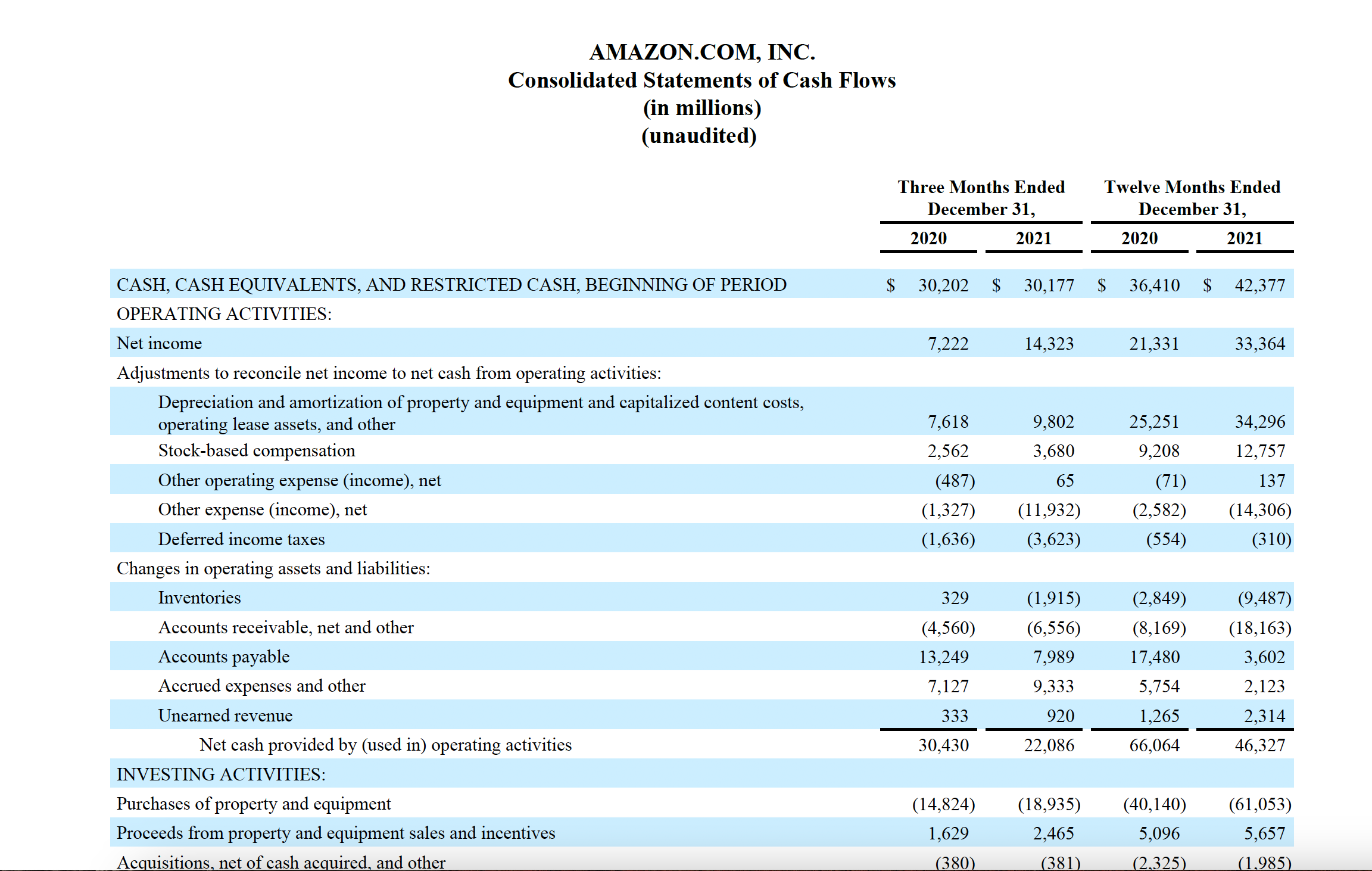
@rishuatgithub can you share some sample that I can try? The table content is working fine with the above code, but the above headers are missing in it Three Months Ended, Twelve Months Ended, and 2020, 2021 in the next line.
thank you very much rish i was maddly looking for the algorithm of table identified. you know i have tried on tabula-py and build this api for table data extraction because python having rich library . now we have a solution in java
Hi rish,
I tried your program. But still not able to read the PDF which contains tabular data.Working till getting no. of pages. Any help, please !