This gist shows how a regular expression (regex) is used to match URLs. Each part of the regex is explained within the context of the URL with examples.
The regular expression below matches URLs. It matches URLs with or without the internet protocol.
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
A URL is made up of differnet parts. I refer to these parts to explain how the regex applies to them.
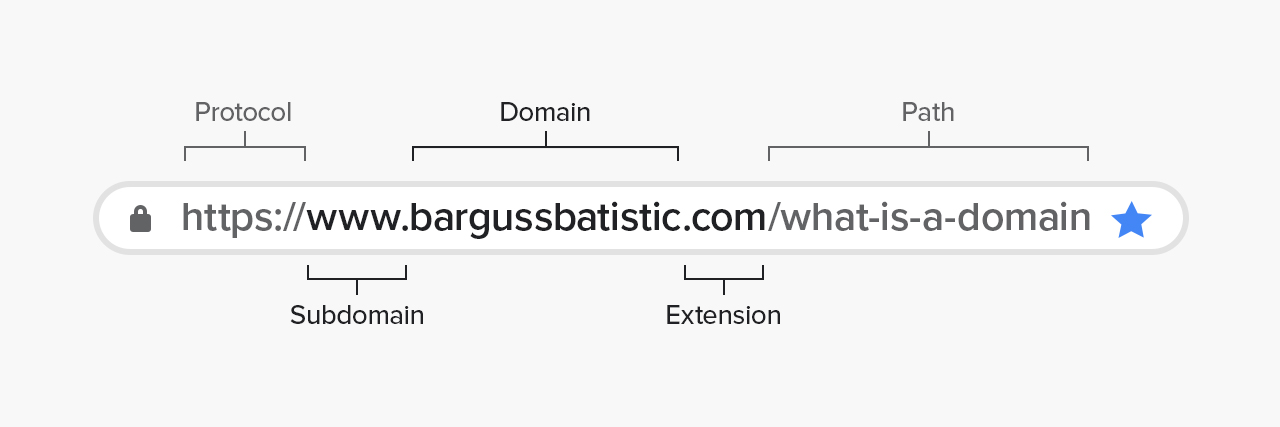
- Protocol: http:// and https://
- Sub Domain: www or dev for example. It is the text that comes before the domain and after the protocol
- Domain: your second level domain name, which can include numbers and dashes
- Domain extension: what comes after your second level domain such as .com, .net, .info
- Path: what comes after your extension. It is an endpoint for a particular page like /about, or /post-123
Here is a visual representation of the parts that make up a URL. This photo is from https://bargussbatistic.com/what-is-a-domain/
Not all domain rules are followed in this regex. So it would not be good for a domain creation site.
Rules not included in this regex are:
- Second level domains have a 63 character limit
- Second level domains cannot start or end with
-symbol
Here are some references for domain rules: https://www.dynadot.com/community/blog/domain-name-rules.html https://www.20i.com/support/domain-names/domain-name-restrictions
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Anchors help deliminate what you are searching for. Just like how forward slashes open and enclose a regex, the ^ symbol means to look for matches after this point. The $ symbol means to find matches before this point. When ^ and $ are used together they mean look for what's in between them.
In this case of matching a URL regex, the ^ is right after the opening /and the $ is at the end before the closing slash. It means to find a match within these points.
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Quantifiers specify a match for a certain number of times.
The first quantifier used in this regex is ? after the https. It is saying look for matches with https OR http. The ? quantifier specifies a match or 0 or 1 times for the character preceeding it.
The ? is used again after (https://)? so it is saying to look for matches of https:// or http:// or none. So it's saying a url be valid with or without the http:// protocol
The + symbol is next quantifier. It matches once or many times, but not zero. So there must be numbers, or characters, or dashes, or dots to match. This is to cover all ranges of sub domains included www, www-2, dev, and dev.www for example. This would also match a second level domain because + symbol says it can be repeated which means dev.www.sitereworks is considered a match.
Another quantifier is used to identify the domain extension: ([a-z\.]{2,6})
The quantifier here is {2,6} and it is saying any 2 characters minimun and up to 6 characters max. This will cover extensions com, co, info, biz etc PLUS the additional country codes extensions; for example com.dz and info.us.
The last quanitfier used is the * symbol: ([\/\w \.-]*)*
It says that the regex preceeding it can be matched as many times possible. So for the last part of the URL regex it is saying the regex of any letter, symbol or number followed by a period or dash can be reapeated indefinetly. This will cover the paths in the URLs which can be long.
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Character Classes are also known as Character Sets. They search for a single digit or character. There are 3 possible character sets in our regex for URLS.
The first set is any digit, any lowercase letter a through z, any period or any dash. [\d] is short for [0-9] which is any single digit 0 through 9. This set is used to identify sub domains and second level domains.
[\da-z\.-]
The second set matches any lowercase a through z or period. It does not include numbers. This helps identify extensions that do not allow numbers.
[a-z\.]
The third is a slash or any letter, number, any symbol, period or dash.
[\/\w \.-]
[\w] means Word character and is very broad. It matches single character of any the following: [A-Za-z0-9_]
This includes any capital letter A-Z, any lowercase letter a-z, any number 0-9 and any special character as identified in ASCII. The underscore identifies special characters. These include: !@#$%^&*()-_+={}[]|?<>,.:;"'~`
Here is a reference for ACSII characters from W3 schools https://www.w3schools.com/charsets/ref_html_ascii.asp
Groups are defined by parentheses () and let you apply quantifiers to a group of rules.
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
There are 4 groups used in this URL regex. See groups below.
-
Protocol group e.g. https://
(https?:\/\/)?
This group looks for http and https. Because it's in a group we can add a quantifier outside of it to say look for 1 match or none. The URL will be valid by this regest without a protocol because of the ? quantifier outside of the parentheses.
-
Subdomain AND Domain group e.g. www.sitereworks. or www-2.mybankportal.
([\da-z\.-]+)\.
This is trying to match a subdomain by any single digit, any single lowercase letter, any dot or any dash. It can find any of these matches multiple times. Then it specifies that what follows after this character class is a dot .
-
Domain Extension group
\.([a-z\.]{2,6})
This is looking for the domain extension. This can include up to certain amount of characters only and dots. This would include common top-level domains such as .com, .net, .info, .online. The quantifies states 2 character minimum and 6 character max. It will also include country code top-level domains such as .co.uk for United Kingdom and .govt.nz for New Zealand.
Note that this will exclude top-level domains that are longer than 6 characters. While it is uncommon to see longer ones, they do exisit. See a list here from Iana.com which is managed by ICANN that has approved top-level domains https://www.iana.org/domains/root/db
.LAMBORGHINI is an example of one over 6 characters.
-
Path group
([\/\w \.-]*)*
Here the group has a * quantifier on the outside and allows 0 or infinite repetition or the path group. So it will match www.sitereworks.com/ and www.sitereworks.com/about-me/mission
/^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$/
Quantifiers are defined either as lazy or greedy, meaning they count a match a using least amount as possible and they count as much as possible for match if greedy. An example from Stack Overflow says if you want to match just a specific html tag such as you would have to include an additional ? quantifier.
All of the quantifiers in are greedy in our URL example. If they were to be lazy we would add a ? after every quantifier.
https://www.regular-expressions.info/ https://www.w3schools.com/charsets/ref_html_ascii.asp https://stackoverflow.com/questions/2301285/what-do-lazy-and-greedy-mean-in-the-context-of-regular-expressions https://www.iana.org/domains/root/db https://www.icann.org/en/system/files/files/ua-factsheet-a4-17dec15-en.pdf https://bargussbatistic.com/what-is-a-domain/