There are many ways that a robot can get information from humans, such as voice, keyboard, or camera. This project recognizes human interaction via visual features from body/hands actions. The main topic is divided into two parts:
- Body and hand detection: detect body and hand joints in the image/video.
- Gesture recognition: The sequence of detected body/hand joints is used for recognizing sign language. In this step, the library should be extended to acknowledge word gestures from the entire image sequence, not only a single char from an image.
- Extension: Currently, the robot can only learn the gesture from the predefined patterns, which appear in the training data. However, the training dataset is not always available for all motions. Therefore, by applying some unsupervised techniques, which I will explain later, the robot can recognize some gestures without any supervised dataset.
There are 2 approaches to recognize sign language: image-based and pose-based. In image-based approach, the video frames are used directly and feed directly to recognizer. Meanwhile, the input for pose-based model is body/hand joint positions. Therefore, we need to implement the body hand joint detector for this project. I also set up some requirements for this project to fit with edge devices and real-time inference:
- Using only images from CameraSimple component.
- The performance on frame per second (FPS) is higher than 12.
- Models have to be compact with size is less than 30Mb.
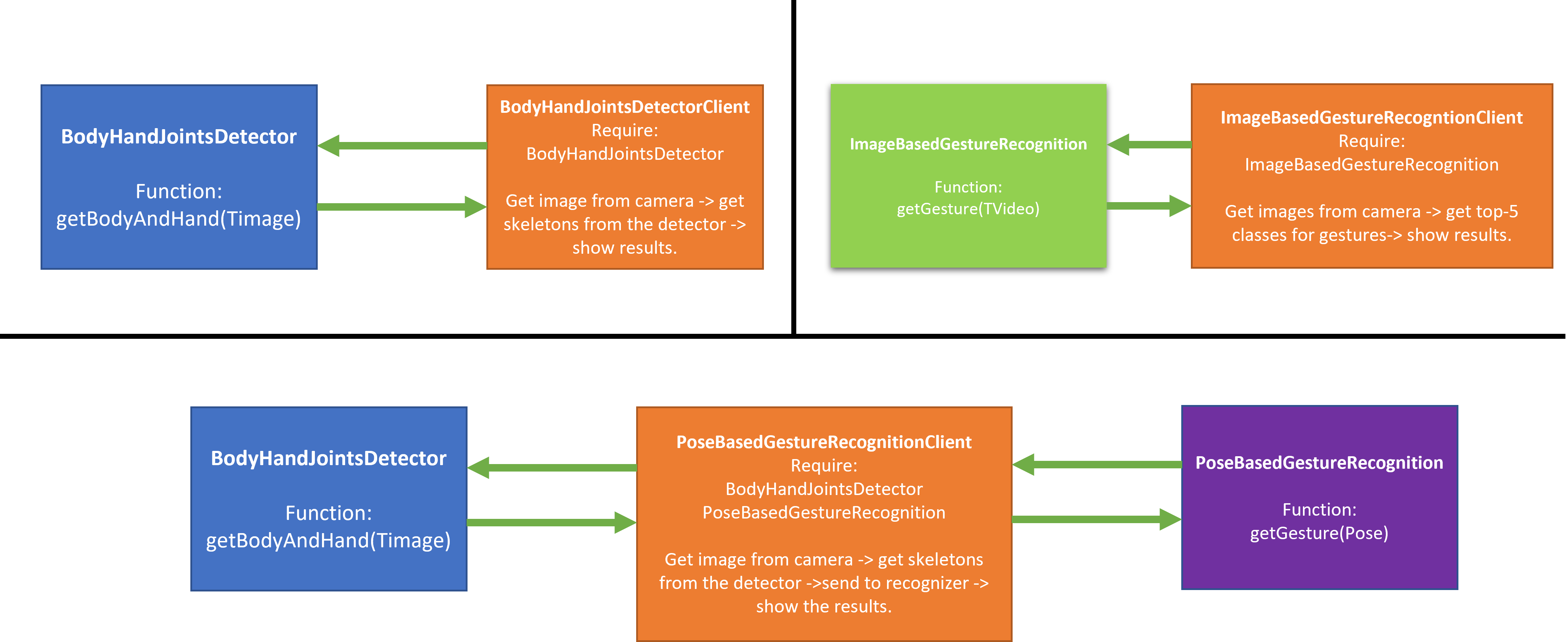
Three components are published: BodyHandJointsDetector, ImageBaseGestureRecognition, PoseBasedGestureRecognition. I will also code the testing client for each approach.
-
BodyHandJointsDetector: component , client. In this component, I use Oenpose light model and media-pipe lib to get skeleton from image body.
-
ImageBasedRecognition: component , client. In this project, we implement WLASL recognizer. There are pretrained model for this dataset. Therefore, we reuse these models without any training. In the image-based approach, they use I3D model for recognition. Please follow instruction in this blog for updating the WLASL models link
-
PoseBasedRecognition: component , client. For pose-based reocngition, we reuse Pose-TGCN (graph neural network). This model have body/hand joints input and output the gesture classes.
The inference directly from Python for Pytorch models usually performs poorly. Therefore, I apply some techniques:
- Using C++ code for post-processing.
- Change the Pytorch format to ONNX format.
- Combine trained ONNX model with NVIDIA® TensorRT.
HandBodyDetectors:
ImageBasedRecognizer:
Some pull requests of my project:
- For all components: robocomp/robocomp-robolab#77, robocomp/robocomp-robolab#80.
- For IDSL files: robocomp/robocomp#343
- For blog: robocomp/web#259, robocomp/web#252, robocomp/web#250, robocomp/web#224, robocomp/web#265.
Throughout my GSoC 21, I am also writing some blog to record my process, and detail information about my work:
- Introduction.
- Fast inference.
- 1st Phase report.
- Body and Hand detection + Image based recognition (Installation and Usage).
- Pose based recognition + WLASL models + demo video for sign language project.
- Conclusion and Future work.
I have just finished 3 listed components. However the accuracy of PoseBasedRecognizer is still low. Furthermore, the applying of Unsupervised model is still not used. Therefore, in the future, we would like to:
- Improve result of Pose-based approach.
- Apply unsupervised techniques for gesture recognition.
My name is Trung. Currently, I am a master student in Computer Science at the Tokyo university of Agriculture and Technology. This is my first time in GSoC, hope we will have a good summer. I just start to learn about Robotic. This is my first step in this domain.
My hobbie : Programming, swimming, practicing martial art, hiking.
The journey of GSoC 2021 is really interested. I learn a lot about: open source contribution, robocomp library, and also about sign language problem for the first time. Furthermore, I faced some challenges and it's quite fun to deal with.
I would like to thank Aditya Aggarwal and Kanva Gupta for patiently help me in this project.