RHEL 8.4 4.18.0-305.19.1.el8_4.x86_64
lspci -nnv |grep -i nvidiae.g.
# lspci -nnv |grep -i nvidia
00:1e.0 VGA compatible controller [0300]: NVIDIA Corporation GM204GL [Tesla M60] [10de:13f2] (rev a1) (prog-if 00 [VGA controller])
Subsystem: NVIDIA Corporation Device [10de:113a]
echo 'blacklist nouveau' >> /etc/modprobe.d/blacklist.conf
dnf config-manager --add-repo=https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/cuda-rhel8.repo
dnf module install nvidia-driver:latest -yThen reboot.
Note, if secure boot is enabled, nvidia kernel modules may not be able to load. Refer to this to disable secure boot if necessary. After reboot,
nvidia-smi
Here is the output
# nvidia-smi
Thu Sep 16 14:53:09 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00000000:00:1E.0 Off | 0 |
| N/A 35C P0 38W / 150W | 0MiB / 7618MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+Install podman and crun, and ensure crun as the default oci runtime
dnf install -y crun
dnf install -y podman
cp /usr/share/containers/containers.conf /etc/containers/containers.conf
sed -i 's/^# runtime = "crun"/runtime = "crun"/;' /etc/containers/containers.confpodman info |grep -i cgroupIf the cgroup version is not v2, do the following to swtich to v2
grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"
reboot(note, currently no rhel 8.4 support yet, so use rhel 8.3 for now)
curl -s -L https://nvidia.github.io/nvidia-docker/rhel8.3/nvidia-docker.repo | tee /etc/yum.repos.d/nvidia-docker.repo
dnf install nvidia-container-toolkit -y
curl -LO https://raw.githubusercontent.com/NVIDIA/dgx-selinux/master/bin/RHEL7/nvidia-container.pp
semodule -i nvidia-container.pp
nvidia-container-cli -k list | restorecon -v -f -
Use the following /etc/nvidia-container-runtime/config.toml for rootless access
disable-require = false
#swarm-resource = "DOCKER_RESOURCE_GPU"
#accept-nvidia-visible-devices-envvar-when-unprivileged = true
#accept-nvidia-visible-devices-as-volume-mounts = false
[nvidia-container-cli]
#root = "/run/nvidia/driver"
#path = "/usr/bin/nvidia-container-cli"
environment = []
debug = "/var/log/nvidia-container-toolkit.log"
#ldcache = "/etc/ld.so.cache"
load-kmods = false
no-cgroups = false
#user = "root:video"
ldconfig = "@/sbin/ldconfig"
[nvidia-container-runtime]
debug = "/var/log/nvidia-container-runtime.log"
# podman run --rm --privileged nvidia/samples:vectoradd-cuda11.2.1-ubi8
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done# podman run --privileged -ti nvidia/cuda:12.1.0-base-ubi8 nvidia-smi
Thu Sep 16 18:26:26 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla M60 Off | 00000000:00:1E.0 Off | 0 |
| N/A 38C P0 38W / 150W | 0MiB / 7618MiB | 98% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+Refer to MicroShift Doc for installation guide.
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin && helm repo update
helm install --generate-name nvdp/nvidia-device-plugin --namespace kube-system# kubectl logs -n kube-system nvidia-device-plugin-1632319880-nq9gs
2021/09/22 14:37:43 Loading NVML
2021/09/22 14:37:43 Starting FS watcher.
2021/09/22 14:37:43 Starting OS watcher.
2021/09/22 14:37:43 Retreiving plugins.
2021/09/22 14:37:43 Starting GRPC server for 'nvidia.com/gpu'
2021/09/22 14:37:43 Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
2021/09/22 14:37:43 Registered device plugin for 'nvidia.com/gpu' with Kubelet
kubectl describe nodes
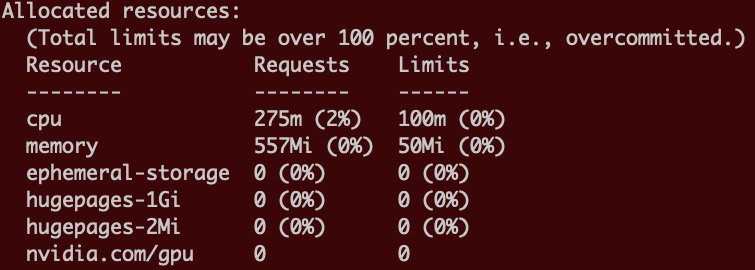
[root@rhel ~]# cat gpu.t
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/samples:vectoradd-cuda10.2"
resources:
limits:
nvidia.com/gpu: 1
[root@rhel ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default gpu-operator-test 0/1 Completed 0 40s
kube-system kube-flannel-ds-45g7v 1/1 Running 0 4m
kube-system nvidia-device-plugin-1632322815-kg4jq 1/1 Running 0 2m47s
kubevirt-hostpath-provisioner kubevirt-hostpath-provisioner-lbpsz 1/1 Running 0 4m1s
openshift-dns dns-default-76jzs 3/3 Running 0 4m
openshift-ingress router-default-6d8c9d8f57-qqbcv 1/1 Running 1 4m
openshift-service-ca service-ca-64547678c6-wmgs4 1/1 Running 2 4m1s
[root@rhel ~]kubectl logs -n default gpu-operator-test
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done- When installing nvidia operator helm chart, certain gpu are not supported, using this value in running helm
# more gpu-operator-values.yaml
validator:
driver:
env:
- name: DISABLE_DEV_CHAR_SYMLINK_CREATION
value: "true"
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator -f gpu-operator-values.yaml - nvidia container runtime needs to find
ldconfig.real. Make a link/sbin/ldconfig.real -> /usr/sbin/ldconfig
Install NVIDIA driver on FC 39
https://phoenixnap.com/kb/fedora-nvidia-drivers