The scope of the gist is to define the process of loading of Clicks/Conversion data from Tracker to S3/Athena for Business processes
The process is described as :
-
The tracker receives the click/conversions data from outside sources and pushes to Kafka topic
-
The Matcher reads the Kafka topic produced by the tracker and matches the clicks and conversions data to produce the Matched conversion data
-
Now the Job handles the data from Kafka topic produced by the Matcher and upload the data to s3. From s3, we can define the schema in Athena and use the Athena to run the SQL queries on top of the data

The ETL job to push to big query will not be a part of System for now as discussed with Gaiar.
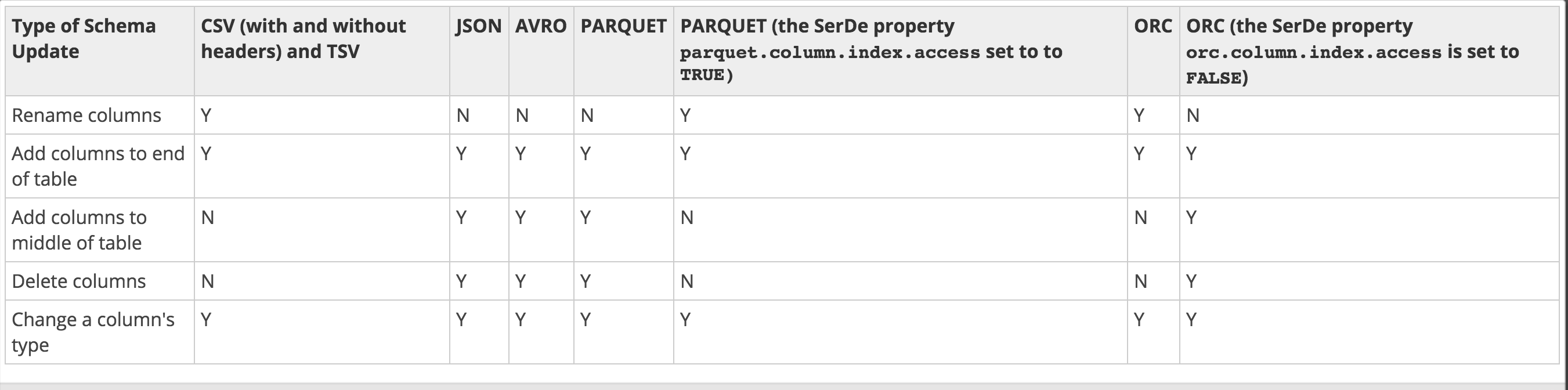
We need some insights here for the type of format we should use and how about defining the process
I have also added the screenshot of formats that we can use and what flexibility we get with the type of format