| Git | Hg | SVN |
|---|---|---|
| Based on C | Based on Python and C | Based on C |
| Git thinks of its data more like a set of snapshots of a miniature filesystem | Hg also has snapshot oriented design | SVN only measures the diffs of the files |
| Distributed | Distributed | Centralized |
Distributed : Rather than a single, central repository on which clients synchronize, each peer's working copy of the codebase is a complete repository. Communication is only necessary when sharing changes among other peers. Peer to peer network.
Centralized : A Client-Server closed network. The central repository is always at the server. Clients cannot interact amongst each other, and can only communicate with server. In fact, they have to for most operations.
SVN essentially sucks because of it's "diff" approach of recording changes, and not because of it's centralized model. Git beats SVN majorly because it records snapshots so that each commit can generate entire repo, only those operations which involve remote host are network dependednt (internet/intranet) and rest operations are smoothly executed locally, and it is decentralized so anyone can share their patches with anyone, with virtually no network constraints.
Source : Self (slightly inspired from Wiki and Git Docs).
| Term | Huh ? |
|---|---|
| Branch | A copy of files which may develop at different speed or in different ways independently of other branches. |
| Diff | Represents a specific modification to a document under version control. |
| Checkout | To check out is to create/switch to a local working copy from the repository from a certain point of history. |
| Clone | Cloning means creating a repository containing the revisions from another repository. This represents the fundamental of DVCS as any repo on a certain network can be cloned to local machine. |
| Fork | A fork is analogous to branch, with the difference that fork represents a clone of a repository developed at different speed or in different direction, independent of the original repo. |
| Commit | To commit is to write or merge the changes made in the working copy back to the repository. |
| Conflict | A conflict occurs when different parties make changes to the same document, and the system is unable to reconcile the changes during merge. |
| Merge | It is an operation in which two sets of changes are applied to a file or set of files. These "sets" may be branch-branch, fork(any branch)-original(any-branch), local-remote, remote-local. |
| Pull, push | Copy revisions from one repository into another. Pull is initiated by the receiving repository (remote to self), while push is initiated by the source (self to remote). |
| Remote | These repositories are versions of your project that are hosted on the Internet or network somewhere. You can have several of them, each of which generally is either read-only or read/write for you. Collaborating with others involves managing these remote repositories and pushing and pulling data to and from them when you need to share work. |
| Trunk | The unique line of development that is not a branch. Alias to master. |
This list is manually assembled. Feel free to add to them.
| Term | Huh ? | Use Cases |
|---|---|---|
| .gitignore | Specifies the files and folders which are to be ignored by Git for tracking. | |
| .gitattributes | It can override configuration for specific files or paths. In effect, this means that you can check project-specific configuration directly into your git repo, and be assured that every developer will be working with roughly the same configuration options. | this article sums it up perfectly. Read more here about line endings. |
| .gitmodules | This is a configuration file that stores the mapping between the project’s URL and the local subdirectory you’ve pulled into it. | Privly is a great example of sub module usage. See the .gitmodules file in their repo, and see how the cloning is done with those in their Readme. |
| .gitkeep | Used to track empty folders as well, which usually Git doesn't. | Sails.js is a highly modern framework which generates an empty app which is version controlled by Git. To maintain the initial directory structure, which consists of many empty folders, .gitkeep is used. |
| .gitconfig | Keeps the Git config variables. Found at different levels, viz. system, global (user), and local. | See this example. You can probably set the defaults for how the diffs are generated and viewed etc. |
Source : Git Docs, and general internet stuff.
These are almost self explanatory. Best for quick revision of concepts.
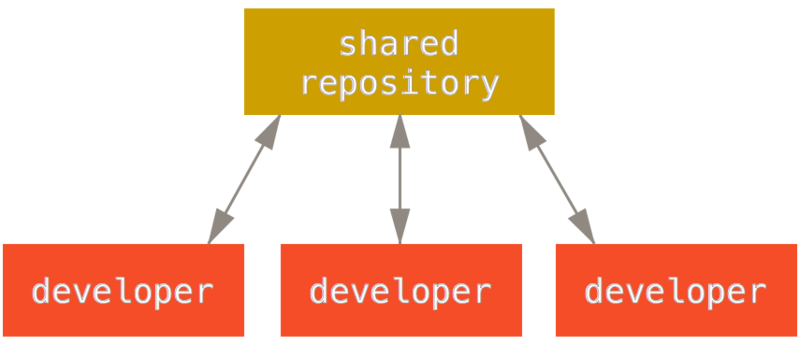
- Centralized Workflow : Good for small teams working on separate featues, however, maximum merge conficts arise in this workflow, and so the need to rebase and test after each commit is important. Clearly, these conflicts would need resolution. Thus, the next workflow was born. Usual Workflow is as follows : Master => Feature Branch (FB) => Development in FB => Testing = > Rebase/Merge Master into FB => Testing => Checkout Master => Merge FB into it => Testing => Push to central remote.
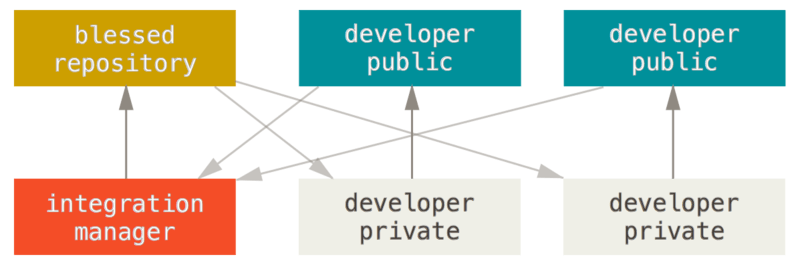
- Integration Manager Workflow : Here, the integration manager assures a more transparent workflow, and the developers push to the manager. The manager then resolves the conflicts at his/her end, and then pushes to the "Blessed" repository. Flow is similar to Centralized but the pushing is done to Manager and initial clone is from Blessed.
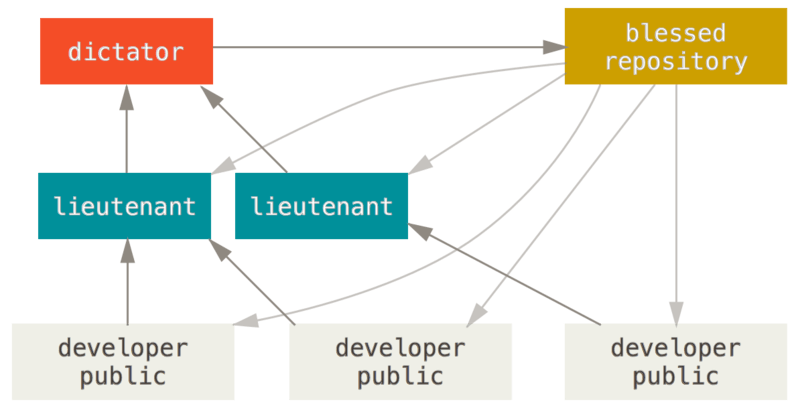
- Dictator-Lieutenants Workflow : This is something which is clearly seen at Git, Linux Kernel, FFmpeg, and the likes. It is derived from the above workflow, and is made more hierarchical by introducing more managers at different echelons.
{kind=link}
{kind=link}
{kind=link}
Source : Git Docs if not linked.
Borad Cycle : User sees View and interacts with it. This interaction triggers Controller. The Controller then performs functions on the Model to reterive data. The Model then suitably populates the View.
Low-Level Cycle
- Server starts and shifts to Public Path. Fires up
index.phpat suitable host and port. - The
index.phpfile loads the Composer generated autoloader definition, and then retrieves an instance of the Laravel application frombootstrap/app.phpscript. - Instances of Services/Application is then created.
- The HTTP Kernel is then fired up by the request. This Kernel runs a series of Bootstrappers which configure error handling, configure logging, detect the application environment, and perform other tasks that need to be done before the request is actually handled. These "services" are configured in
configure/app.php. - The request then is handled by the middlewares, defined in the Kernel itself.
- It is now sent to the Controller (Router), where route-specific middlewares receive the request.
- Controller actions are now performed, like connecting to databases and ORMs etc.
- These actions return the results directly to the View.
- The user may further initiate requests through the View, and the cycle repeats from the middlewares of the Kernel.
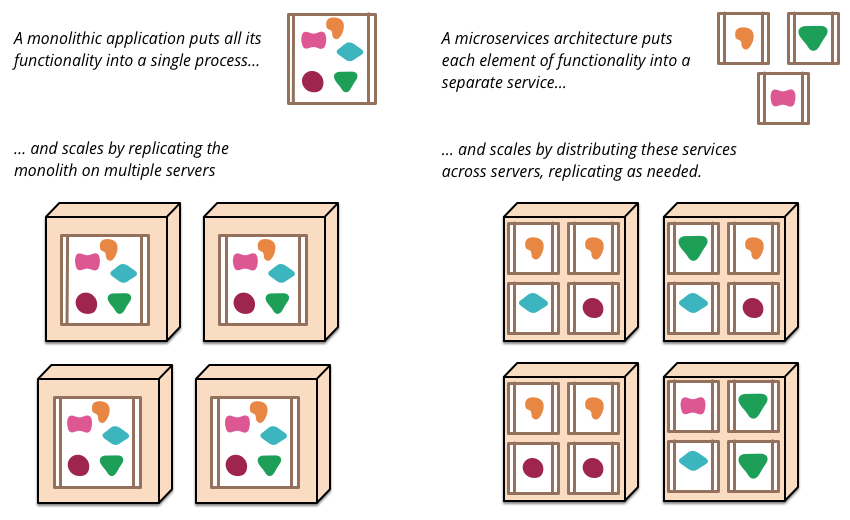
The microservice architectural style [1] is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
Processes are independent, and scaling is decentralized/distributed.
{kind=link}
Microservice architectures will use libraries, but their primary way of componentizing their own software is by breaking down into services, as they are independently deployable. We define libraries as components that are linked into a program and called using in-memory function calls, while services are out-of-process components who communicate with a mechanism such as a web service request, or remote procedure call. Meaning, in the approach of componentizing the application, Microservices Style suggest that break it down in term of services. These services would be developed and deployed independently, unlike the case when a linked library is upgraded. The smaller granularity of services can make it easier to create the personal relationships between service developers and their users. Thus, the Microservice Architecture is more product focused.
Many products and approaches stress putting significant smarts into the communication mechanism itself. The microservice community favours an alternative approach: smart endpoints and dumb pipes. Applications built from microservices aim to be as decoupled and as cohesive as possible - they own their own domain logic and act more as filters in the classical Unix sense - receiving a request, applying logic as appropriate and producing a response. These are choreographed using simple RESTish protocols rather than complex protocols. Benefits ? Highest flexibility, as zero network dependency.
Teams building microservices prefer a different approach to standards too. Rather than use a set of defined standards written down somewhere on paper they prefer the idea of producing useful tools that other developers can use to solve similar problems to the ones they are facing. This is in line with the idea of owning a product the microservice way. You own the service, you develop, deploy and maintain it as a complete product, and you create standards for that development itself independently, all the while remaining flexible and portable, thanks to modularized logic at the end points and the dumb pipes. The idea extended to decentralization of databases as well. The common views of multiple services can use a certain type of RDBMS. Domain-Driven-Design usually helps in designing relationships among domains. There is a natural correlation between service and context boundaries that helps clarify and reinforce the separations.
Continuous Integration is the practice of merging all developer working copies to a shared mainline. The idea is to automate the process of manually merging the branch/fork to the trunk, and to subsequently avoid intergration/merge hell. Naturally, the "continuous" part is event triggered, which is usually a commit at the branch. The CI server not only can automate merge, but instead can automate a lot of processes like, running unit tests (before and after build as per the case), additional static and dynamic tests, measure and profile performance, extract and format documentation from the source code, and facilitate manual QA processes. Subsequently, it's preferred to write tests of a new feature before actually implementing it. Thus, TDD or BDD practices gel best with typical CI servers.
Continuous Delivery is the next natural step after the successful and quality-assured intergration into the trunk. The CD practice involves a Deployment Pipeline which essesentially is a model of sequence in which build(s) are deployed to different environments at different stages. This is to check for performace, stability, security, and functionailty criteria, whether it is fir for production or not. Main advantages of this include the "visible" progress, and the feedback received from the staging version, which can be assesed easily manually by QA or UX people. Further, smooth deployment to staging would also mean significantly lesser risks of deploying to live production.