You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Bell Labs research
Brendan G. Cain and James O. Coplien.
A Role-Based Empirical Process Modeling Environment.
In Proceedings of Second
International Conference on the Software Process (ICSP-2), pages 125-133,
February 1993. Los Alamitos, California, IEEE
Computer Press.
Neil B. Harrison and James O. Coplien. Patterns of productive software
organizations. Bell Labs Technical Journal, 1(1):138-
145, Summer (September) 1996.
Organizational Patterns of Agile Software
Development. Upper Saddle River, NJ: Prentice-
Hall/Pearson, July 2004.
James Coplien and Neil Harrison.
SIMULA 67 Common Base Language. Norwegian
Computing Center, 1968. O.-J. Dahl, B. Myhrhaug, K. Nygaard:
Borland Software Craftsmanship: A New Look at Process,
Quality and Productivity. In Proceedings of the
Fifth Borland International Conference, Orlando, Florida, June 1994. James O. Coplien.
Agile Software Development with Scrum. Pearson,
October, 2001. Mike Beedle and Ken Schwaber.
Software in 30 Days: How Agile Managers Beat the Odds, Delight
Their Customers, and Leave Competitors in the
Dust. Wiley, 2012. Ken Schwaber.
Ikujiro Nonaka. The Knowledge Creating Company. Oxford University Press, 1995.
Ikujiro Nonaka and R. Toyama. Managing Flow: A Process Theory of the
Knowledge-Based Firm. Palgrave Macmillan, 2008.
A Development Process Generative Pattern Language. In James O.
Coplien and Douglas C. Schmidt, editors,
Pattern Languages of Program Design, chapter 13, 183-237. Addison-Wesley,
Reading, MA, 1995. James O. Coplien.
A Laboratory for Teaching Object-Oriented Thinking. Proceedings of
OOPSLA ’89, SIGPLAN Notices 24(10), October,
1989. Kent Beck.
Architecture and the Child Within. Games versus Play,
Alan C. Kay. A Personal Computer for Children of All
Ages. Original between 1968 and 1982. New York:
ACM Press, Proceedings of the ACM Annual Conference - Volume 1, 1972,
http://doi.acm.org/10.1145/800193.1971922.
The Humane Interface: New Directions for Designing Interactive
Systems. Addison-Wesley: 2000. Jef Raskin.
A Laboratory for Teaching Object-Oriented Thinking. Proceedings of
OOPSLA ’89, SIGPLAN Notices 24(10), October,
1989. Kent Beck.
Comparative Case Study on the Effect of Test-Driven
Development on Program Design and Test
Coverage, ESEM 2007 Siniaalto and Abrahamsson,
Does Test-Driven Development Improve the Program Code? Alarming results from a Comparative Case Study.
Siniaalto and Abrahamsson, Proceedings of Cee-Set 2007, 10 - 12 October, 2007, Poznan, Poland.
John Thackara. Design After Modernism: Beyond the Object. New York: Thames and
Hudson, Inc., 1988.
Nigel Cross, ed. Developments in design methodology. Chichester, UK: Wiley,
1984.
An overview into the value system that kdb/q has inherited from APL, see Aaron Hsu's video, "Design Patterns vs Anti pattern in APL by Aaron W Hsu at FnConf17".
https://confengine.com/functional-conf-2017/proposal/4620/design-patterns-vs-anti-pattern-in-apl
Skip the first few minutes due to audio problems:
https://www.youtube.com/watch?v=v7Mt0GYHU9A&t=3m15s
At 40m50s, Hsu contrasts "APL Practice" vs "Accepted Practice"
Brevity vs Verbosity
Macro vs Micro
Transparency vs Abstraction
Idioms vs Libraries
Data vs Control Flow
Structure vs Names
Implicit vs Explicit
Syntax vs Semantics
These differences make APL / q very productive in the hands of a skilled developer. However the more traditional patterns have established themselves for a reason.
Here are some forces which stand in the way of using q in the “APL style” in Production in large organizations:
Zero Developer Access to Production
ZDAP is a specialization of "Separation of Duties". It is intended to prevent developers from tampering with Production systems to perpetrate fraud or accidentally destabilize the system.
It falls upon the Production Management / DevOps team to determine the cause of the error and whether to escalate. Often, the support team is not deeply steeped in q. Instead, they consult “run books” for the list of steps to restore smooth functioning.
Much of the core functionality in q.k such as .Q.chk[…] reports nonspecific error messages which assume access to the console to decode the root cause. This is not feasible in a ZDAP environment and that core functionality must be reimplemented with more detailed logging.
Organizational Silos
Wherever there’s an organizational boundary, there’s a chance that technology choices will be different on each side.
Some parts of the organization may choose to interact with kdb+ only through client APIs and develop the barest minimum of q familiarity.
There may be separate teams who support kdb vs Python (for example) with different deployment permissions. Therefore, cross-language plugins may need to be buildable in a way that allows deployment in two pieces.
Versioning
Even if multiple teams choose q, they may evolve their components / systems on different timelines. A module loading system needs to allow for this.
Plugins need to be binary compatible. Although the C ABI is stable, the C++ ABI is not. Compiler upgrades or library evolution can result in a process that fails to start up, or worse yet, mysteriously crashes or otherwise misbehaves.
Security
Out of the box, “that which is not forbidden is permitted”. Given that kdb instances in financial services organizations may hold confidential data, the narrative needs to be flipped to, “that which is not permitted is forbidden”.
As the number of users grows, access controls need to become finer grained to provide data on a “need to know” basis. At the most basic level, there will be a division between those with “administrative” access and those who do not. However, there are other entitlements which may need to be enforced based on role (eg. may view P&L) or client coverage.
Complexity
For systems with hundreds of thousands of lines of code, it’s simply unrealistic for every developer to know all of them in detail. Specialization naturally occurs. Abstraction becomes necessary.
Short names inevitably lead to collisions resulting in confusion.
Debugging Insights (collection of stories on separate pages, submitted to Dave Agans, the author of "Debugging: The 9 Indispensable Rules for Finding Even the Most Elusive Software and Hardware Problems")
I recently read the article The sad graph of software death by Gregory Brown.
Brown describes a software project wherein tasks are being opened faster than
they are being closed in the project’s task tracker. The author describes this
as “broken”, “sad”, and “wasteful.” The assumption behind the article seems to
be that there is something inherently bad about tasks being opened faster than
they are being closed.
The author doesn’t explain why this is bad, and to me this article and the
confused discussion it prompted on Reddit are symptomatic of the fact that most
people don’t have a clear idea of the purpose of software project management.
Another symptom is that so many software projects run into problems, causing
tension between engineering, product, and other parts of the company. It is
also the reason there is such a proliferation of tools that purport to help
solve the problem of project management, but none of them do because they don’t
start from a clear view of what exactly this problem is.
Two complimentary goals
In my view, the two core goals of project management are prioritization and
predictability.
Prioritization ensures that at any given time, the project’s developers are
working on the tasks with the highest ratio of value to effort
Predictability means accurately estimating what will get done and by when, and
communicating that with the rest of the company.
A task tracker maintains a record of who is currently working on specific tasks,
which tasks are completed, and the future tasks that could be tackled. As such,
the trackers do not address the two core goals of project management directly.
I have actually thought about building a project management tool that addresses
these goals, i.e. prioritization and predictability, much more directly than is
currently the case with existing systems. Unfortunately, to date the value to
effort ratio hasn’t been high enough relative to other projects 🙂
When a task is created or “opened” in a task tracker, this simply means “here is
something we may want to do at some point in the future.”
Opening a task isn’t, or shouldn’t be, an assertion that it must get done, or
must get done by a specific time. Although this might imply that some tasks may
never be finished, that’s ok. Besides, a row in a modern database table is very
cheap indeed.
Therefore, the faster rate at which tasks are opened rather than closed is not
an indication of a project’s impending demise; rather, it merely reflects the
normal tendency of people to think of new tasks for the project faster than
developers are able to complete those tasks.
Once created, tasks should then go through a prioritization or triage process;
however, the output isn’t simply “yes, we’ll do it” or “no, we won’t.” Rather,
the output should be an estimate of the value provided to complete the task, as
well as an estimate of the effort or resources required to complete it. Based on
these two estimates, we can calculate the value/effort for the tasks. It is
only then that we can stack-rank the tasks.
Estimating value and effort
Of course, this makes it sound much simpler than it is. Accurately estimating
the value of a task is a difficult process that may require input from sales,
product, marketing, and many other parts of a business. Similarly, accurately
estimating the effort required to complete a task can be challenging for even
the most experienced engineer.
There are processes designed to help with these estimates. Most of these
processes, such as planning poker, rely on the wisdom of crowds. These are
steps toward the right direction.
I believe the ultimate solution to estimation will exploit the fact that people
are much better at making relative, rather than absolute, estimates. For
example, it is easier to guess that an elephant is 4 times heavier than a horse,
than to estimate that the absolute weight of an elephant is 8000 pounds.
This was recently supported by a simple experiment that I conducted. First, I
asked a group to individually assign a number of these relative or comparative
estimates. Then, I used a constraint solver to turn these into absolute
estimates. The preliminary results are very promising. This approach would
almost certainly be part of any project management tool that I might build.
Once we have good estimates for value/effort, we can then prioritize the tasks.
Using our effort estimate, combined with an understanding of the resources
available, we can come up with better time estimates. This will enhance
predictability that can be shared with the rest of the company.
Pivotal Tracker
I have had quite a bit of experience with Pivotal Tracker, which I would
describe as the “least bad” project management tool. Pivotal Tracker doesn’t
solve the prioritization problem, but it does attempt to help with the
predictability problem. Unfortunately, it does so in a way that is so
simplistic as to make it almost useless. Let me explain.
Pivotal Tracker assumes that for each task, you have assigned effort estimates
which are in the form of “points” (you are responsible for defining what a point
means). It also assumes that you have correctly prioritized the tasks, which
are then placed in the “backlog” in priority order.
Pivotal Tracker then monitors how many points are “delivered” within a given
time period. It then uses these points to project when future tasks will be
completed.
The key problem with this tool is that it pretends that the backlog is static,
i.e. that new tasks won’t be added to the backlog before tasks are prioritized.
In reality, tasks are constantly being added to any active project, and these
new tasks might go straight to the top of the priority list.
Nevertheless, the good news is that Pivotal Tracker could probably be improved
to account for this addition of new tasks without much difficulty. Perhaps a
third party could make these improvements by using the Java library I created
for integrating with PT’s API. 🙂
Breaking down tasks
Most tasks start out as being quite large, and need to be broken down into
smaller tasks, both to make it easier to divide tasks among developers, but also
to improve the accuracy of estimates.
However, there isn’t much point in breaking down tasks when nobody is going to
start work on them for weeks or months. For this reason, I advise setting
time-horizon limits for task sizes. For example, you might say that a task that
is estimated to be started within three months can’t be larger than 2 man-weeks,
and a task to be started within 1 month cannot be larger than 4 man-days.
As a task crosses each successive time-horizon, it may need to be broken into
smaller tasks (each of which will, presumably, be small enough until they hit
the next time horizon). In practice this can be accomplished with a weekly
meeting, that can be cancelled if there are no tasks to be broken down. We
would assign one developer to break down each oversized task and then the
meeting would break up so that they could go and do that. Typically each large
task would be broken down into 3-5 smaller tasks.
This approach has the additional advantage that it spreads out the process of
breaking down tasks over time and among developers.
Resource allocation
So how do you decide who works on what? This is fairly simple under this
approach. Developers simply pick the highest priority task that they can work
on (depending on skill set or interdependencies).
At OneSpot, when we broke down tasks, we left the subtasks in the same position
in the priority stack as the larger task they replaced. Since developers pull
new tasks off the top of the priority list, this has the tendency to encourage
as many people as possible to be working on related tasks at any given time,
which minimizes the number of projects (large tasks) in-flight at any given
time.
Conclusion
To conclude, without a clear view of the purpose of successful project
management, it is not surprising that so many projects flounder with many
project management tools failing to hit the mark. I hope I was able to provide
the beginnings of a framework to think about project management in a goal-driven
way.
Some of you might disagree, so here's the main reason why it's fantastic: over the last few years, it has popularized the idea of using message-passing to manage application state. Instead of making arbitrary method calls to various class instances or mutating data structures, we now can think of state as being in a "predictable container" that only changes as a reaction to these "messages."
It is universal enough to be used with any framework (or no framework at all), and has inspired libraries for other popular frameworks such as:
However, Redux has recently come under scrutiny by some prominent developers in the web community:
{% twitter 1191487232038883332 %}
{% twitter 1195126928799227905 %}
If you don't know these developers, they are the co-creators of Redux themselves. So why have Dan and Andrew, and many other developers, all but forsaken the use of Redux in applications?
The ideas and patterns in Redux appear sound and reasonable, and Redux is still used in many large-scale production apps today. However, it forces a certain architecture in your application:
{% twitter 1025408731805184000 %}
As it turns out, this kind of single-atom immutable architecture is not natural nor does it represent how any software application works (nor should work) in the real-world, as we will soon find out.
Redux is an alternative implementation of Facebook's Flux "pattern". Many sticking points and hardships with Facebook's implementation have led developers to seek out alternative, nicer, more developer-friendly APIs such as Redux, Alt, Reflux, Flummox, and many more.. Redux emerged as a clear winner, and it is stated that Redux combines the ideas from:
However, not even the Elm architecture is a standalone architecture/pattern, as it is based on fundamental patterns, whether developers know it or not:
Rather than someone inventing it, early Elm programmers kept discovering the same basic patterns in their code. It was kind of spooky to see people ending up with well-architected code without planning ahead!
In this post, I will highlight some of the reasons that Redux is not a standalone pattern by comparing it to a fundamental, well-established pattern: the finite state machine.
I hope that some of these comparisons and differences will help you realize how some of the common pain points in Redux-driven applications materialize, and how you can use this existing pattern to help you craft a better state management architecture, whether you're using Redux or another library, or even another language.
Wikipedia has a useful but technical description on what a finite state machine is. In essence, a finite state machine is a computational model centered around states, events, and transitions between states. To make it simpler, think of it this way:
Any software you make can be described in a finite number of states (e.g., idle, loading, success, error)
You can only be in one of those states at any given time (e.g., you can’t be in the success and error states at the same time)
You always start at some initial state (e.g., idle)
You move from state to state, or transition, based on events (e.g., from the idle state, when the LOAD event occurs, you immediately transition to the loading state)
It’s like the software that you’re used to writing, but with more explicit rules. You might have been used to writing isLoading or isSuccess as Boolean flags before, but state machines make it so that you’re not allowed to have isLoading === true && isSuccess === true at the same time.
It also makes it visually clear that event handlers can only do one main thing: forward their events to a state machine. They’re not allowed to “escape” the state machine and execute business logic, just like real-world physical devices: buttons on calculators or ATMs don’t actually do operations or execute actions; rather, they send "signals" to some central unit that manages (or orchestrates) state, and that unit decides what should happen when it receives that "signal".
What about state that is not finite?
With state machines, especially UML state machines (a.k.a. statecharts), "state" refers to something different than the data that doesn't fit neatly into finite states, but both "state" and what's known as "extended state" work together.
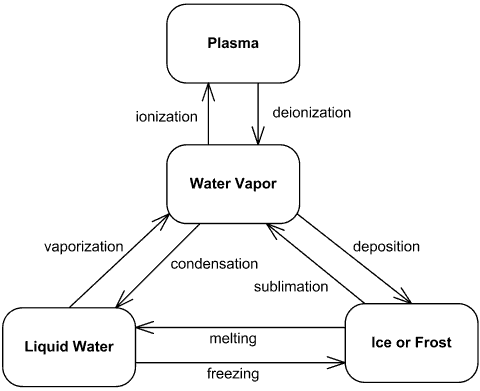
For example, let's consider water 🚰. It can fit into one of four phases, and we consider these the states of water:
However, the temperature of water is a continuous measurement, not a discrete one, and it can't be represented in a finite way. Despite this, water temperature can be represented alongside the finite state of water, e.g.:
liquid where temperature === 90 (celsius)
solid where temperature === -5
gas where temperature === 500
There's many ways to represent the combination of finite and extended state in your application. For the water example, I would personally call the finite state value (as in the "finite state value") and the extended state context (as in "contextual data"):
constwaterState={value: 'liquid',// finite state context: {// extended statetemperature: 90}}
But you're free to represent it in other ways:
constwaterState={phase: 'liquid',data: {temperature: 90}}// or...constwaterState={status: 'liquid',temperature: 90// anything not 'status' is extended state}
The key point is that there is a clear distinction between finite and extended state, and there is some logic that prevents the application from reaching an impossible state, e.g.:
constuserState={status: 'loading',// or 'idle' or 'error' or 'success'user: null,error: null}
How does Redux compare to a finite state machine?
The reason I'm comparing Redux to a state machine is because, from a birds-eye view, their state management models look pretty similar. For Redux:
state + action = newState
For state machines:
state + event = newState + effects
In code, these can even be represented the same way, by using a reducer:
functionuserReducer(state,event){// Return the next state, which is// determined based on the current `state`// and the received `event` object// This nextState may contain a "finite"// state value, as well as "extended"// state values.// It may also contain side-effects// to be executed by some interpreter.returnnextState;}
There are already some subtle differences, such as "action" vs. "event" or how extended state machines model side-effects (they do). Dan Abramov even recognizes some of the differences:
{% twitter 1064661742188417029 %}
A reducer can be used to implement a finite state machine, but most reducers are not modeled as finite state machines. Let's change that by learning some of the differences between Redux and state machines.
Difference: finite & extended states
Typically, a Redux reducer's state will not make a clear distinction between "finite" and "extended" states, as previously mentioned above. This is an important concept in state machines: an application is always in exactly one of a finite number of "states", and the rest of its data is represented as its extended state.
Finite states can be introduced to a reducer by making an explicit property that represents exactly one of the many possible states:
What's great about this is that, if you're using TypeScript, you can take advantage of using discriminated unions to make impossible states impossible:
In state machine terminology, an "action" is a side-effect that occurs as the result of a transition:
When an event instance is dispatched, the state machine responds by performing actions, such as changing a variable, performing I/O, invoking a function, generating another event instance, or changing to another state.
This isn't the only reason that using the term "action" to describe something that causes a state transition is confusing; "action" also suggests something that needs to be done (i.e., a command), rather than something that just happened (i.e., an event).
So keep the following terminology in mind when we talk about state machines:
An event describes something that occurred. Events trigger state transitions.
An action describes a side-effect that should occur as a response to a state transition.
The Redux style guide also directly suggests modeling actions as events:
However, we recommend trying to treat actions more as "describing events that occurred", rather than "setters". Treating actions as "events" generally leads to more meaningful action names, fewer total actions being dispatched, and a more meaningful action log history.
When the word "event" is used in this article, that has the same meaning as a conventional Redux action object. For side-effects, the word "effect" will be used.
Difference: explicit transitions
Another fundamental part of how state machines work are transitions. A transition describes how one finite state transitions to another finite state due to an event. This can be represented using boxes and arrows:
This diagram makes it clear that it's impossible to transition directly from, e.g., idle to success or from success to error. There are clear sequences of events that need to occur to transition from one state to another.
However, the way that developers tend to model reducers is by determining the next state solely on the received event:
functionuserReducer(state,event){switch(event.type){case'FETCH':
// go to some 'loading' statecase'RESOLVE':
// go to some 'success' statecase'REJECT':
// go to some 'error' statedefault:
returnstate;}}
The problem with managing state this way is that it does not prevent impossible transitions. Have you ever seen a screen that briefly displays an error, and then shows some success view? If you haven't, browse Reddit, and do the following steps:
Search for anything.
Click on the "Posts" tab while the search is happening.
Say "aha!" and wait a couple seconds.
In step 3, you'll probably see something like this (visible at the time of publishing this article):
After a couple seconds, this unexpected view will disappear and you will finally see search results. This bug has been present for a while, and even though it's innocuous, it's not the best user experience, and it can definitely be considered faulty logic.
However it is implemented (Reddit does use Redux...), something is definitely wrong: an impossible state transition happened. It makes absolutely no sense to transition directly from the "error" view to the "success" view, and in this case, the user shouldn't see an "error" view anyway because it's not an error; it's still loading!
You might be looking through your existing Redux reducers and realize where this potential bug may surface, because by basing state transitions only on events, these impossible transitions become possible to occur. Sprinkling if-statements all over your reducer might alleviate the symptoms of this:
functionuserReducer(state,event){switch(event.type){case'FETCH':
if(state.status!=='loading'){// go to some 'loading' state...// but ONLY if we're not already loading}// ...}}
But that only makes your state logic harder to follow because the state transitions are not explicit. Even though it might be a little more verbose, it's better to determine the next state based on both the current finite state and the event, rather than just on the event:
functionuserReducer(state,event){switch(state.status){case'idle':
switch(event.type){case'FETCH':
// go to some 'loading' state// ...}// ...}}
But don't just take my word for it. The Redux style guide also strongly recommends treating your reducers as state machines:
[...] treat reducers as "state machines", where the combination of both the current state and the dispatched action determines whether a new state value is actually calculated, not just the action itself unconditionally.
If you look at Redux in isolation, its strategy for managing and executing side-effects is this:
¯\_(ツ)_/¯
That's right; Redux has no built-in way of handling side-effects. In any non-trivial application, you will have side-effects if you want to do anything useful, such as make a network request or kick off some sort of async process. Importantly enough, side-effects should not be considered an afterthought; they should be treated as a first-class citizen and uncompromisingly represented in your application logic.
Unfortunately, with Redux, they are, and the only solution is to use middleware, which is inexplicably an advanced topic, despite being required for any non-trivial app logic:
Without middleware, Redux store only supports synchronous data flow.
With extended/UML state machines (also known as statecharts), these side-effects are known as actions (and will be referred to as actions for the rest of this post) and are declaratively modeled. Actions are the direct result of a transition:
When an event instance is dispatched, the state machine responds by performing actions, such as changing a variable, performing I/O, invoking a function, generating another event instance, or changing to another state.
This means that when an event changes state, actions (effects) may be executed as a result, even if the state stays the same (known as a "self-transition"). Just like Newton said:
For every action, there is an equal and opposite reaction.
Source: Newton's Third Law of Motion
Actions never occur spontaneously, without cause; not in software, not in hardware, not in real life, never. There is always a cause for an action to occur, and with state machines, that cause is a state transition, due to a received event.
Statecharts distinguish how actions are determined in three possible ways:
Entry actions are effects that are executed whenever a specific finite state is entered
Exit actions are effects that are executed whenever a specific finite state is exited
Transition actions are effects that are executed whenever a specific transition between two finite states is taken.
Fun fact: this is why statecharts are said to have the characteristic of both Mealy machines and Moore machines:
With Mealy machines, "output" (actions) depends on the state and the event (transition actions)
With Moore machines, "output" (actions) depends on just the state (entry & exit actions)
The original philosophy of Redux is that it did not want to be opinionated on how these side-effects are executed, which is why middleware such as redux-thunk and redux-promise exist. These libraries work around the fact that Redux is side-effect-agnostic by having third-party, use-case specific "solutions" for handling different types of effects.
So how can this be solved? It may seem weird, but just like you can use a property to specify finite state, you can also use a property to specify actions that should be executed in a declarative way:
Now, your reducer will return useful information that answers the question, "what side-effects should be executed as a result of this state transition?" The answer is clear and colocated right in your app state: read the actions property for a declarative description of the actions to be executed, and execute them:
// pretend the state came from a Redux React hookconst{ actions }=state;useEffect(()=>{actions.forEach(action=>{if(action.type==='fetchUser'){fetch(`/api/user/${action.id}`).then(res=>res.json()).then(data=>{dispatch({type: 'RESOLVE',user: data});})}});},[actions]);
Having side-effects modeled declaratively in some state.actions property (or similar) has some great benefits, such as in predicting/testing or being able to trace when actions will or have been executed, as well as being able to customize the implementation details of executing those actions. For instance, the fetchUser action can be changed to read from a cache instead, all without changing any of the logic in the reducer.
Difference: sync vs. async data flow
The fact is that middleware is indirection. It fragments your application logic by having it present in multiple places (the reducers and the middleware) without a clear, cohesive understanding of how they work together. Furthermore, it makes some use-cases easier but others much more difficult. For example: take this example from the Redux advanced tutorial, which uses redux-thunk to allow dispatching a "thunk" for making an async request:
Now ask yourself: how can I cancel this request? With redux-thunk, it simply isn't possible. And if your answer is to "choose a different middleware", you just validated the previous point. Modeling logic should not be a question of which middleware you choose, and middleware shouldn't even be part of the state modeling process.
As previously mentioned, the only way to model async data flow with Redux is by using middleware. And with all the possible use-cases, from thunks to Promises to sagas (generators) to epics (observables) and more, the ecosystem has plenty of different solutions for these. But the ideal number of solutions is one: the solution provided by the pattern in use.
Alright, so how do state machines solve the async data flow problem?
They don't.
To clarify, state machines do not distinguish between sync and async data flows, because there is no difference. This is such an important realization to make, because not only does it simplify the idea of data flow, but it also models how things work in real life:
A state transition (triggered by a received event) always occurs in "zero-time"; that is, states synchronously transition.
Events can be received at any time.
There is no such thing as an asynchronous transition. For example, modeling data fetching doesn't look like this:
idle . . . . . . . . . . . . success
Instead, it looks like this:
idle --(FETCH)--> loading --(RESOLVE)--> success
Everything is the result of some event triggering a state transition. Middleware obscures this fact. If you're curious how async cancellation can be handled in a synchronous state transition manner, here's a couple of guiding points for a potential implementation:
A cancellation intent is an event (e.g., { type: 'CANCEL' })
Cancelling an in-flight request is an action (i.e., side-effect)
"Canceled" is a state, whether it's a specific state (e.g., canceled) or a state where a request shouldn't be active (e.g., idle)
The primary reason for this is that it makes many things easier, such as sharing data, rehydrating state, "time-travel debugging", etc. But it suffers from a fundamental contradiction: there is no such thing as a single source of truth in any non-trivial application. All applications, even front-end apps, are distributed at some level:
{% twitter 1116019772238454784 %}
Whenever something is done for the sole purpose of making something easy, it almost always makes some other use-case more difficult. Redux and its single-source-of-truth is no exception, as there are many problems that arise from fighting against the nature of front-end apps being "distributed" instead of an idealistic atomic, global unit:
Multiple orthogonal concerns that need to be represented in the state somehow.
Irrelevant state updates: when separate concerns are combined (using combineReducers or similar) into a single store, whenever any part of the state updates, the entire state is updated, and every "connected" component (every subscriber to the Redux store) is notified.
This is "solved" by using selectors, and perhaps by using another library like reselect for memoized selectors.
I put "solved" in quotes because these are all solutions that are all but necessary due to problems that are caused solely by using a global, atomic store. In short, it's unrealistic, even for apps that are already using global stores. Whenever you use a 3rd-party component, or local state, or local storage, or query parameters, or a router, etc., you have already shattered the illusion of a single global store. App data is always distributed at some level, so the natural solution should be to embrace the distribution (by using local state) rather than fighting against it just for the sake of making some use-cases easier to develop in the short run.
Acting differently
So how do state machines address this global state problem? To answer that, we need to zoom out a little bit and introduce another old, well-established model: the actor model.
The actor model is a surprisingly simple model that can be extended slightly beyond its original purpose (concurrent computation). In short, an actor is an entity that can do three things:
It can receive messages (events)
It can change its state/behavior as a reaction to a received message, including spawning other actors
It can send messages to other actors
If you thought "hmm... so a Redux store is sort of an actor", congratulations, you already have a good grasp on the model! A Redux store, which is based on some single combined reducer thing, can receive events, changes its state as a reaction to those events, but... it can't send messages to other stores (there's only one store) or between reducers (dispatching happens externally). It also can't really spawn other "actors", which makes the Reddit example in the official Redux advanced tutorial more awkward than it needs to be:
We're taking only the relevant slice of state we need (state[action.subreddit]), which should ideally be its own entity
We are determining what the next state of only this slice should be, via posts(state[action.subreddit], action)
We are surgically replacing that slice with the updated slice, via Object.assign(...).
In other words, there is no way we can dispatch or forward an event directly to a specific "entity" (or actor); we only have a single actor and have to manually update only the relevant part of it. Also, every other reducer in combineReducers(...) will get the entity-specific event, and even if they don't update, they will still be called for every single event. There's no easy way to optimize that. A function that isn't called is still much more optimal than a function that is called and ultimately does nothing.
So back on topic: how do state machines and actors fit together? Simply put, a state machine describes the behavior of an individual actor:
Events are sent to a state machine (this is, after all, how they work)
A state machine's state/behavior can change due to a received event
A state machine can spawn actors and/or send messages to other actors (via executed actions)
This isn't a cutting-edge, groundbreaking model; in fact, you've probably been using the actor model (to some extent) without even knowing it! Consider a simple input component:
It "receives events" using React's slightly awkward parent-to-child communication mechanism - prop updates
It changes state/behavior when an event is "received", such as when the disabled prop changes to true (which you can interpret as some event)
It can send events to other "actors", such as sending a "change" event to the parent by calling the onChange callback (again, using React's slightly awkward child-to-parent communication mechanism)
In theory, it can "spawn" other "actors" by rendering different components, each with their own local state.
Multi-Redux?
Again, one of Redux's three main principles is that Redux exists in a single, global, atomic source of truth. All of the events are routed through that store, and the single huge state object is updated and permeates through all connected components, which use their selectors and memoization and other tricks to ensure that they are only updated when they need to be, especially when dealing with excessive, irrelevant state updates.
And using a single global store has worked pretty well when using Redux, right? Well... not exactly, to the point that there are entire libraries dedicated to providing the ability to use Redux on a more distributed level, e.g., for component state and encapsulation. It is possible to use Redux at a local component level, but that was not its main purpose, and the official react-redux integration does not naturally provide that ability.
You should think about what to do before you do it.
You should try to talk about what you’re planning to do before you do it.
You should think about what you did after you did it.
Be prepared to throw away something you’ve done in order to do something
different.
Always look for better ways of doing things.
“Good enough” isn’t good enough.
Code
Code is a liability, not an asset. Aim to have as little of it as possible.
Build programs out of pure functions. This saves you from spending your brain
power on tracking side effects, mutated state and actions at a distance.
Use a programming language with a rich type system that lets you describe the
parts of your code and checks your program at compile time.
The expressivity of a programming language matters hugely. It’s not just a
convenience to save keypresses, it directly influences the way in which you
write code.
Have the same high standards for all the code you write, from little scripts to
the inner loop of your critical system.
Write code that is exception safe and resource safe, always, even in contexts
where you think it won’t matter. The code you wrote in a little ad-hoc script
will inevitably find its way into more critical or long-running code.
Use the same language for the little tools and scripts in your system too. There
are few good reasons to drop down into bash or Python scripts, and some
considerable disadvantages.
In code, even the smallest details matter. This includes whitespace and layout!
Design
Model your domain using types.
Model your domain first, using data types and function signatures, pick
implementation technologies and physical architecture later.
Modelling - the act of creating models of the world - is a crucial skill, and
one that’s been undervalued in recent years.
Implement functionality in vertical slices that span your whole system, and
iterate to grow the system.
Resist the temptation to use your main domain types to describe interfaces or
messages exchanged by your system. Use separate types for these, even if it
entails some duplication, as these types will evolve differently over time.
Prefer immutability always. This applies to data storage as well as in-memory
data structures.
When building programs that perform actions, model the actions as data, then
write an interpreter that performs them. This makes your code much easier to
test, monitor, debug, and refactor.
Dependency management is crucial, so do it from day one. The payoff for this
mostly comes when your system is bigger, but it’s not expensive to do from the
beginning and it saves massive problems later.
Avoid circular dependencies, always.
Quality
I don’t care if you write the tests first, last, or in the middle, but all code
must have good tests.
Tests should be performed at different levels of the system. Don’t get hung up
on what these different levels of tests are called.
Absolutely all tests should be automated.
Test code should be written and maintained as carefully as production code.
Developers should write the tests.
Run tests on the production system too, to check it’s doing the right thing.
Designing systems
A better system is often a smaller, simpler system.
To design healthy systems, divide and conquer. Split the problem into smaller
parts.
Divide and conquer works recursively: divide the system into a hierarchy of
simpler sub-systems and components.
Corollary: When designing a system, there are more choices than a monolith vs.
a thousand “microservices”.
The interface between parts is crucial. Aim for interfaces that are as small and
simple as possible.
Data dependencies are insidious. Take particular care to manage the coupling
introduced by such dependencies.
Plan to evolve data definitions over time, as they will inevitably change.
Asynchronous interfaces can be useful to remove temporal coupling between parts.
Every inter-process boundary incurs a great cost, losing type safety, an making
it much harder to reason about failures. Only introduce such boundaries where
absolutely necessary and where the benefits outweigh the cost.
Being able to tell what your system is doing is crucial, so make sure it’s
observable.
Telling what your system has done in the past is even more crucial, so make sure
it’s auditable.
A modern programming language is the most expressive tool we have for describing
all aspects of a system.
This means: write configuration as code, unless it absolutely, definitely has to
change at runtime.
Also, write the specification of the system as executable code.
And, use code to describe the infrastructure of your system, in the same
language as the rest of the code. Write code that interprets the description of
your system to provision actual physical infrastructure.
At the risk of repeating myself: everything is code.
Corollary: if you’re writing JSON or YAML by hand, you’re doing it wrong. These
are formats for the machines, not for humans to produce and consume. (Don’t
despair though: most people do this, I do too, so you’re not alone! Let's just
try to aim for something better).
The physical manifestation of your system (e.g. choices of storage, messaging,
RPC technology, packaging and scheduling etc) should usually be an
implementation detail, not the main aspect of the system that the rest is built
around.
It should be easy to change the underlying technologies (e.g. for data storage,
messaging, execution environment) used by a component in your system, this
should not affect large parts of your code base.
You should have at least two physical manifestations of your system: a fully
integrated in-memory one for testing, and the real physical deployment. They
should be functionally equivalent.
You should be able to run a local version of your system on a developer’s
computer with a single command. With the capacity of modern computers, there is
absolutely no rational reason why this isn’t feasible, even for big, complex
systems.
There is a running theme here: separate the description of what a system does
from how it does it. This is probably the single most important consideration
when creating a system.
Building systems
For a new system, get a walking skeleton deployed to production as soon as
possible.
Your master branch should always be deployable to production.
Use feature branches if you like. Modern version control tools make merging easy
enough that it’s not a problem to let these be long-lived in some cases.
Ideally, deploy automatically to production on every update to master. If that’s
not feasible, it should be a one-click action to perform the deployment.
Maintain a separate environment for situations when you find it useful to test
code separately from production. Avoid more than one such extra environment, as
this introduces overheads and cost.
Prefer feature flags and similar mechanisms to control what's enabled in
production over separate test/staging environments and manual promotion of
releases.
Get in the habit of deploying from master to production from the very beginning
of a project. Doing this shapes both your system and how you work with it for
the better.
In fact, follow all these practices from the very beginning of a new system.
Retrofitting them later is much, much harder.
Technology
Beware of hyped or fashionable technologies. The fundamentals of computer
science and engineering don’t change much over time.
Keep up with latest developments in technology to see how they can help you, but
be realistic about what they can do.
Choose your data storage backend according to the shape of data, types of
queries needed, patterns of writes vs. reads, performance requirements, and
more. Every use case is different.
That said, PostgreSQL should be your default and you should only pick something
else if you have a good reason.
Teams
Hiring is the most critical thing you do in a team, so allocate time and effort
accordingly.
Use the smallest team possible, but no smaller.
Do everything you can to keep the team size small. Remove distractions for the
team, delegate work that isn’t crucial, provide tools that help their
productivity. Increasing the team size should be the last resort.
Teams need to be carefully grown, not quickly put together. When companies brag
about how many engineers they’re planning to hire in the near future, this is a
massive red flag.
New systems are best designed by a small numbers of minds, not committees. Once
the structure of the system is clear and the main decisions made, more people
can usefully get involved.
Code ownership may be undesirable, but it’s important to have someone who owns
the overall vision and direction for a system. Without it, the architecture will
degrade over time as it gets pulled in different directions.
Prefer paying more to get a smaller number of great people instead of hiring
more people at a lower salary.
Use contractors to bring in expertise, to ramp up a project quickly, for work on
trial projects, or to deal with specialised work of a temporary nature. Don’t
use contractors as a substitute for ordinary staff. (I say this as a
contractor.)
If you’re hiring contractors because you can’t get permanent staff, you’re not
paying your permanent staff enough.
As a team lead, if things go well, give your team the credit. If things go
badly, take the blame yourself.
A team member who isn’t a good fit for the team can kill the performance of the
whole team.
Inter-personal conflict is likewise poison to a team. While it may be possible
to resolve underlying issues, if it proves difficult, it’s usually better for
everyone to accept this and move people on.
Many people do “agile” badly, but that doesn’t mean that “agile” is bad.
Out of all the agile practices commonly used, estimating task sizes and trying
to measure project velocity is the least useful. (Its utility is often less than
zero).
People
Be kind towards others, everyone faces their own battles no matter how they
appear externally.
Be kind to yourself. What you’re doing is hard, so accept that it sometimes
takes longer than you’d like and things don’t always work out.
Don't let your own desire to get things done quickly turn into undue pressure on
your peers.
The more certain people are about their opinions, the more you should take them
with a pinch of salt.
Imposter syndrome is a thing, as is the Dunning-Kruger effect. So judge people
on their contributions, not on how confident they seem.
Personal development
Always keep learning.
Read papers (of the scientific variety).
Read the classics. So many “new” ideas in software development have actually
been around for decades.
Rest. Don’t work more than 8 hours a day. Get enough sleep. Have interests
outside your work.
Work efficiently instead of very long days. Try to remove distractions as much
as possible, for example pointless meetings. (As an aside, some meetings are
actually useful.)
When looking for a solution to a problem, don’t just pick the first one that
comes to mind. Learn to look for alternatives and evaluate them to find the best
choice.
Don’t work in isolation. Share ideas, talk new ideas and designs over with your
peers.
Don't be afraid to have strong opinions, but listen carefully to the opinions of
others too.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters


fixed, thx