-
-
Save sandeepkumar-skb/03c2f7582fda454889e5f010e7e06e97 to your computer and use it in GitHub Desktop.
| #include <chrono> | |
| #include <iostream> | |
| #include <vector> | |
| #include <thread> | |
| __global__ void do_nothing(int time_us, int clock_rate) { | |
| clock_t start = clock64(); | |
| clock_t end; | |
| for (;;) { | |
| end = clock64(); | |
| // 1.12 is just an empirical correction for straggler threads, etc. | |
| int elapsed_time_us = | |
| static_cast<int>(static_cast<float>(end - start) / clock_rate * 1000000 * 1.12); | |
| if (elapsed_time_us > time_us) { | |
| break; | |
| } | |
| } | |
| } | |
| int main() { | |
| using namespace std::chrono; | |
| int num_calls = 10000; | |
| int num_threads = 10; | |
| int wait_us = 35; | |
| int kernel_us = 5; | |
| cudaStream_t default_stream = 0; | |
| cudaDeviceProp props; | |
| cudaGetDeviceProperties(&props, 0); | |
| // clock is in kHz | |
| int clock_rate = props.clockRate * 1000; | |
| // Titan RTX has 4608 CUDA cores and 72 SMs. 4608 / 72 = 64 | |
| dim3 grid(72, 1, 1); | |
| dim3 block(64, 1, 1); | |
| auto f1 = [grid, block, kernel_us, wait_us, clock_rate](cudaStream_t stream) { | |
| do_nothing<<<grid, block, 0, stream>>>(kernel_us, clock_rate); | |
| std::this_thread::sleep_for(microseconds(wait_us)); | |
| }; | |
| auto t1 = high_resolution_clock::now(); | |
| for (int i = 0; i < num_calls; ++i) { | |
| f1(default_stream); | |
| } | |
| cudaDeviceSynchronize(); | |
| auto t2 = high_resolution_clock::now(); | |
| auto f2 = | |
| [f1, num_calls, num_threads]() { | |
| cudaStream_t local_stream; | |
| cudaStreamCreateWithFlags(&local_stream, cudaStreamNonBlocking); | |
| for (int i = 0; i < num_calls / num_threads; ++i) { | |
| f1(local_stream); | |
| } | |
| cudaStreamSynchronize(local_stream); | |
| cudaStreamDestroy(local_stream); | |
| }; | |
| std::vector<std::thread> threads; | |
| auto t3 = high_resolution_clock::now(); | |
| for (int i = 0; i < num_threads; ++i) { | |
| threads.push_back(std::move(std::thread(f2))); | |
| } | |
| for (int i = 0; i < num_threads; ++i) { | |
| if (threads[i].joinable()) { | |
| threads[i].join(); | |
| } | |
| } | |
| auto t4 = high_resolution_clock::now(); | |
| auto single_dur = duration_cast<duration<double, std::micro>>(t2 - t1).count(); | |
| auto multi_dur = duration_cast<duration<double, std::micro>>(t4 - t3).count(); | |
| std::cout << "Single-threaded time: " << single_dur << " us" << std::endl; | |
| std::cout << "Multi-threaded time: " << multi_dur << " us" << std::endl; | |
| std::cout << "Multi-threaded speed-up: " << (1.0 * single_dur / multi_dur) << "x" << std::endl; | |
| return 0; | |
| } |
Here the CUDA kernels are very small(smaller than launch latency) so launching all the kernels by the same thread is not a going to give any benefit over launching all of them on the same stream. This is because although the main thread doesn't wait for the kernel to finish before launching another kernel on a different stream the overhead the main thread to launch itself hurts here because the kernels are very small.
As it can be seen from the results below:
Single-threaded time: 1.08287e+06 us
Multi-threaded time: 988459 us
Multi-threaded speed-up: 1.09552x
To repro the above results change comment out the following snippet:
for (int i = 0; i < num_threads; ++i) {
threads.push_back(std::move(std::thread(f2)));
}
for (int i = 0; i < num_threads; ++i) {
if (threads[i].joinable()) {
threads[i].join();
}
}
and add the following:
for (int i=0; i < num_threads; ++i){
f2();
}
This wouldn't be the case if the kernels are were big enough to run 10s of us and not fill all the SMs then we would get good perf benefit from a single thread launching CUDA kernels on different streams.
Single Stream:

Multi Stream:
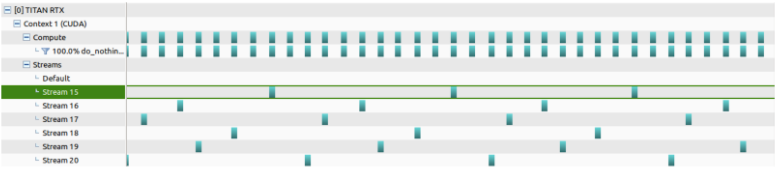
This example shows how improving scheduling to reduca launch latency can help even though each individual kernel takes up the whole GPU. Here, the GPU in question is a Titan RTX, with 4,608 CUDA cores and 72 SMs, so we launch 72 thread blocks with 64 threads each.
compile:
nvcc -std=c++14 -arch=sm_75 multi_streaming_to_reduce_launch_latency.cu -o multi_streaming_to_reduce_launch_latencyOutput: