The progress in research of Machine Learning algorithms and the rise in their applications is one of the major technological advances in the last decade. The news we frequently hear about Machine learning algorithms doing real-world tasks with human-like (or in some cases even better) efficiency is evident of this fact.
While you might already be familiar with the functioning of various machine learning algorithms, and capable of implementing them using libraries & frameworks like pytorch, tensorflow, and Keras, doing so at scale is a more tricky game.
This two post series answers why scalability is such an important aspect of real-world machine learning and throws light on the architectures, practices, and some optimizations that are useful while doing Machine learning at scale. Basic familiarity with Machine learning, i.e., awareness of the terms and concepts like Neural Network, CNN, Imagenet is assumed while writing this post.
If we see applications of machine learning like Automatic Machine translation, Image colorization, Playing games like Chess, Go, and even DOTA-2, or generating real-like faces, such kind of tasks require model training on massive amounts of data (more than 100s of GB), and very high processing power (on specialized hardware accelerated chips like GPUs and ASICs). We can't simply feed the Imagenet dataset to the CNN model we trained on our laptop to recognize handwritten MNIST digits and expect it to give decent accuracy a few hours of training.
Machine learning has been existing for years, but the rate at which developments in machine learning and associated fields are happening, scalability is becoming a prominent topic of focus.
The internet has been reaching masses, network speeds are rising exponentially, and the data footprint of an average internet citizen is rising too, which means more data for the algorithms to learn from. Products related internet of things is ready to gain mass adoption, eventually providing more data for us to leverage.
Due to better fabricating techniques and advances in technology, storage is getting cheaper day by day. Moore's law continued to hold for several years, although it has been slowing now. The efficiency and performance of the processors have grown at a good rate enabling us to do computation intensive task at low cost.
The last decade has not only been about the rise of the Machine learning algorithms, but it has also been about the rise of containerization, orchestration frameworks, and all other things that make organization of a distributed set of machines easy.
Scalability matters in Machine learning because,
- Training a model can take a looong time

- A model can be so big that it can't fit into the working memory of the training device.
- Even if we decide to buy a big machine with lots of memory and processing power, it is going to be more expensive than somehow using a lot of smaller machines. In other words, vertical scaling is expensive.
Scalability is about handling huge amounts of data, performing a lot of computations, in a cost-effective and time-saving way. Here are the inherent benefits of caring about scale,
- Productivity: A lot of machine learning these days happens in the form of experiments, for solving a novel problem with a novel architecture (algorithm). A pipeline with fast executions of every stage (training, evaluation, deployments) will enable us to try more things and be more creative.
- Modularity, portability and composition: It'd be beneficial if the results of the training and the trained model can be leveraged by other teams.
- Cost reduction: It never hurts to optimize for the costs. Scaling helps in utilizing available resources to maximum, and make a trade-off between marginal cost and accuracy.
- Minimizing human involvement: The pipeline should be as automated as possible so that humans can step out and enjoy coffee while machines do their tasks.
For instance, 25% of engineers at Facebook work on training models, training 600k models per month. Their online prediction service makes 6M predictions per second. Baidu's Deep Search model training involves computing power of 250 TFLOP/s on a cluster of 128 GPUs. So we can imagine how important is it for such companies to scale efficiently and why scalability in machine learning matters these days.
Let's try to explore what are the areas that we should focus upon for making our Machine learning pipeline scalable.
To better understand the opportunities to scale, let's quickly go through broad steps involved in a typical machine learning process,
1. Domain understanding
The first step is usually to gain an in-depth understanding of the problem, and its domain. In this step, we consider the constraints of the problem, think about the inputs and outputs of the solution that we are trying to develop, and how the business is going to interpret the results.
2. Data collection and warehousing
The next step is to collect and preserve the data relevant to our problem. The amount of data that we need depends on the problem we're trying to solve. For example, training a general image classifier on thousands of categories will need huge data of labeled images (just like ImageNet).
3. Exploratory Data analysis and feature engineering
Next step is usually is performing some statistical analysis on the data, handling outliers, handling missing values, and removing highly correlated features to subset the data that we'll be feeding to our machine learning algorithm.
4. Modeling (training)
Now comes the part when we train a Machine learning model on the prepared data. Depending upon our problem statement and the data we have, we might have to try a bunch of training algorithms and architectures to figure out what fits our use-case the best.
5. Evaluation (testing)
It's time to evaluate model performance. Usually, we have to go back and forth between modeling and evaluation a few times (after tweaking the models) before getting the desired performance for a model.
6. Deploying (inference)
Finally, we prepare our trained model for the real world. We may want to integrate our model into existing software or create an interface to use its inference.
Okay, now let's list down some focus areas for scaling at various stages in various machine learning process.
Data is iteratively fed to the training algorithm during training, so the memory representation and the way we feed it to the algorithm will play a crucial role in scaling. The journey of the data from the source to the processor for performing computations for the model may have a lot of opportunities for us to optimize.
- Model training consists of a series of mathematical computations that are applied on different (or same) data over and over again. This iterative nature can be leveraged to parallelize the training process, eventually, reduce the time required for training by deploying more resources.
- However, simply deploying more resources is not a cost-effective approach. We also need to focus on improving the computation power of individual resources, which means faster and smaller processing units than existing ones.
- Focusing on the research of newer algorithms that are more efficient the existing ones, we can reduce the number of iterations required to achieve the same performance, hence enhance scalability.
- We can also try to reduce the memory footprint of our model training for better efficiency.
- Also, there are these questions to answer, Are the extra X layers worth it? Is an extra Y amount of data really improving the model performance? When should we stop training?
Apart from being able to calculate performance metrics, we should have a strategy and a framework for trying out different models and figuring out optimal hyperparameters with less manual effort.
The models we deploy might have different use-cases and extent of usage patterns. Our systems should be able to scale effortlessly with changing demands for the model inference.
In this part, we'll discuss different possible solutions to the frequent problems and bottlenecks we may face while developing a scalable Machine learning pipeline.
There are many options available when it comes to choosing your Machine learning framework. While the gut feeling might be to just go with the best framework available in the language of your proficiency, but this might not always be the best ides. For example, the use of Java as the primary language to construct your machine learning model is highly debated. Standard java lacks hardware acceleration. One may argue that Java is faster than other popular languages like Python used for writing machine learning models. The thing to note is that most machine learning libraries with Python interface are wrappers over C/C++ code which make them faster than native Java. To achieve comparable performance with Java, we will need to wrap some C/C++/Fortran code. There are implementations which do that, but very few as compared to other languages. Moreover, since machine learning involves a lot of experimentation, the absence of REPL and strong static typing, make Java not so suitable for constructing models in it.
Beyond language, is the task of choosing a framework for your Machine learning solution. Some of the popular Deep learning frameworks are Tensorflow, Pytorch, MXNet, Caffe, and Keras. There are multiple factors to consider while choosing the framework like community support, performance, third-party integrations, use-case, and so on. We won't go into what framework is best; you can find a lot of nice feature and performance comparisons about them on the internet. However, one important thing to keep in mind while selecting the library/framework is the level of abstraction you want to deal with.
For example, consider this abstraction hierarchy diagram for tensorflow
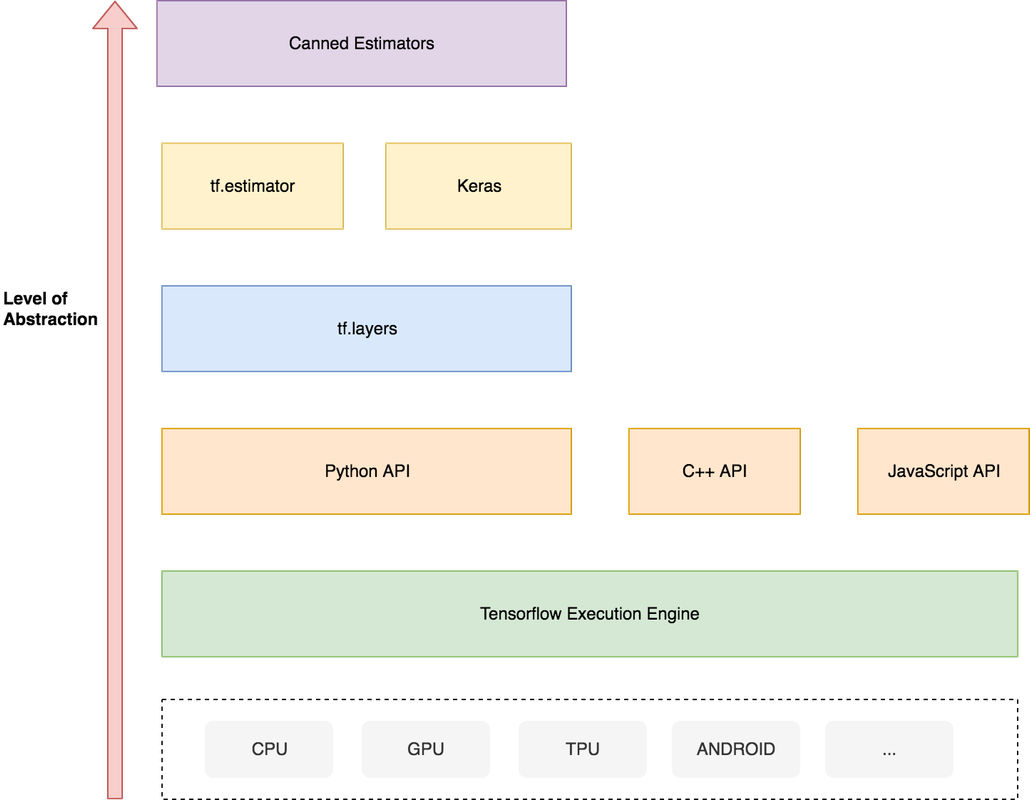
Your preferred abstraction level can lie anywhere between writing C code with CUDA extensions to using a highly abstracted canned estimator which lets you do a lot (optimize, train, evaluate) with fewer lines of code, but at the cost of less control on implementation. It mostly depends on the complexity and novelty of the solution that you intend to develop.
Since a large part of machine learning is feeding data to an algorithm that performs heavy computations iteratively, the choice of hardware also plays a significant role in scalability. Scaling activities for computations in Machine learning (specifically Deep Learning) should be concerned about executing matrix multiplications as fast as possible with lesser power consumption (because, cost!).
CPUs are not ideal for large scale Machine learning, and they can quickly turn into a bottleneck because of the sequential processing nature. An upgrade over CPUs for ML is GPUs (Graphics processing units). Unlike CPUs, GPUs contain hundreds of ALUs define ALUs? embedded which make them a very good choice for any process that can benefit by leveraging parallelized computations. GPUs are much faster than CPUs for computations like vector multiplications. However, both CPUs and GPUs are designed for general purpose usage and suffer from von Neumann bottleneck and higher power consumption.
A step beyond CPUs and GPUs is ASICs (Application Specific Integrated Chips), wherein we trade off general-flexibility for an increase in performance. There have been a lot of exciting researches being going on for designing ASICs for deep learning, and Google has already come up with three generations of ASICs called Tensor Processing Units (TPUs). TPUs exploit the fact that neural network computations are operations of Matrix multiplication and additions, and have the specialized architecture to perform just that. TPUs consist of MAC units (Multipliers and Accumulators) arranged in the systolic array fashion which enables matrix multiplications without memory access, thus consuming less power and reducing costs. This way of performing matrix multiplications also reduces the computational complexity from the order of n3 to order of 3n - 2. Explaining how exactly they work is beyond the scope of this article, you can read more about the here. Google is not the only player in this domain, other tech companies like Huawei, Microsoft, Facebook, Apple have also been actively working on designing ASICs for machine learning.

To sum it up CPUs are scalar processors, GPUs are vector processors, and ASICs like TPUs are matrix processors.
Data collection and warehousing can sometimes turn out to be the step with the most human involvement. Activities like cleaning, feature selection, labeling can often be redundant (doing similar things over and over again) and time-consuming. To reduce effort in labeling and also to expand data, there has been active research going on in the area of producing synthetic data using generative models like GANs, Variational Autoencoders, and Autoregressive models. The downside is that these models in themselves require very high computation to be able to generate synthetic data, and it's not as helpful as real-world data.
The format in which we're going to store the data is also vital. It mostly depends on the kind of data that we're dealing with, and how we're going to use it. For instance, if you have to feed the data to a distributed architecture, then formats like HDF5 can be quite efficient.
I/O hardware are also important in Machine learning at scale. The massive data on which we iteratively perform computations is fetched from and stored by I/O devices. With hardware accelerators, the input pipeline can quickly become a bottleneck if not optimized. It can broadly be seen as consisting of three steps.
1. Extraction: The first task is to read from the source. The source can be a disk, a stream of data, a network of peers, etc.
2. Transformation: We might need to apply some transformations to the data. For example, in case of training an image classifier, transformations like resizing, flip, cross, rotate, grayscale are applied to the input image before feeding them to model.
3. Loading: The final step bridges between the working memory of the training model and the transformed data. Those two locations can be the same or different depending on what kind of devices are we using for training and transformation.
Now if we observe, all three steps rely on different computer resources. Extraction depends on I/O devices (reading from disk, network, etc.); transformation usually depends on CPU; and assuming that we are using accelerated hardware, loading depends on GPU/ASICs.
We can take advantage of this fact, and break down input data into batches and parallelize file reading, data transformation, and data feeding. This way we can interleave the three steps and optimize resource utilization, so that none of the steps is blocked due to dependency on the other.
Coming to the core step of a Machine learning pipeline, if we would like to see training step at a slightly more detailed level, here's how it'll look like.
A typical supervised-learning experiment consists of feeding the data via the input pipeline, doing a forward pass, computing loss, and then correcting the parameters with an objective to minimize the loss. Performances of various hyperparameters and architectures are evaluated tried before selecting the best one.
Let's explore how we can apply the "divide and conquer" approach to decompose the computations performed in these step into granular ones that can be run independently of each other, and aggregated later on to get the desired result. After decomposition, we can leverage horizontal scaling of our systems to improve time, cost, and performance.
There are two dimensions to decomposition; Functional decomposition, and data decomposition.
Functional decomposition, in general, implies breaking the logic down to distinct and independent functional units, which can be later be recomposed to get the results. "Model parallelism" is one kind of functional decomposition in the context of Machine learning. The idea is to split different parts of the model computations to different devices so that they can execute parallelly and speed up the training.
Data decomposition is a more obvious form of decomposition. Data is divided into chunks, and multiple machines perform the same computations on different data.
One instance where you can see both the functional and data decomposition in action is the training of an ensemble learning model like Random forest, which is conceptually a collection of a decision tree. Decomposing the model into individual decision trees in functional decomposition, and then further training the individual tree parallelly is data parallelism. It is also an example of what we can call as Embarrassingly parallel tasks.
Based on the idea of functional and data decomposition, let's now explore the world of distributed machine learning. You know, all the Big data/ Spark/ Hadoop stuff that everyone keeps talking about, we can leverage that for machine learning as well!
Decomposition in the context of scaling will make sense if we have set up an infrastructure that can take advantage of it by operating with a decent degree of parallelization. And when we talk about this, an important question to seek an answer to is "How do we express a program that can be run on a distributed infrastructure?"
MapReduce is a programming model built to allow parallelization of computations. The model is based on "split-apply-combine" strategy. A typical MapReduce program will express a parallelizable process in a series of map and reduce operations. Map function maps the data to zero or more key-value pairs. The MapReduce execution framework groups these key-value pairs via shuffle operation. Then the reduce function takes in those key-value groups and performs aggregation to get the final result. The thing to note is that the MapReduce execution framework handles the data in a distributed manner, takes care of running the Map and Reduce functions in a highly optimized and parallelized manner on multiple workers (a.k.a cluster of nodes), thereby helping in the scalability.

Let's talk about the components of a distributed machine learning setup.

The data is partitioned, and the driver node is responsible for assigning tasks to the nodes in the cluster. The nodes might have to communicate among each other to propagate information like the gradients; there are various arrangements possible for the nodes, a couple of extreme ones are Async parameter server arrangement and Sync Allreduce arrangement.
In the Async parameter server architecture, as the name suggests, the transmission of information in between the nodes happens asynchronously. Here's a typical architecture diagram for Async parameter server architecture,

You can see how a single worker can have multiple computing devices. The worker labeled "master" also takes up the role of the driver. Here the workers communicate the information (Example, gradients) to the parameter servers, update the parameters (or weights), and pull the latest parameters (or weights) from the parameter server itself. One drawback of this kind of set up is delayed convergence, as the workers can go out of sync.
In Sync AllReduce architecture, the focus is laid on the synchronous transmission of information between the cluster node. Here's a typical architecture diagram for Sync AllReduce architecture,

In Sync allreduce arrangement workers are mutually connected via fast interconnects. There's no parameter server. This kind of arrangement is more suited for fast hardware accelerators. All workers have to be synced before a new iteration, and the communication links need to be fast for it to be effective.
Some distributed machine learning frameworks do provide high-level APIs for defining these arrangement strategies with little effort.
A distributed computation framework should take care of data handling, task distribution, and providing desirable features like fault tolerance, recovery, etc. The most popular open-source implementation of MapReduce is Apache Hadoop. Hadoop stores the data in the Hadoop Distributed File System (HDFS) format and provides a Map Reduce API in multiple languages. The scheduler used by Hadoop is called YARN (Yet Another Resource Negotiator), which takes care of optimizing the scheduling of the tasks to the workers based on factors like localization of data.
Another popular framework is Apache Spark. Spark's design is focused on performing faster in-memory computations on streaming and iterative workloads. Spark uses immutable Resilient Distributed Datasets (RDDs) as the core data structure to represent the data and perform in-memory computations. For performing Machine learning in spark, we can write our algorithms in the map-reduce paradigm, or we can use a library like MLlib. Spark is very versatile in the sense that you can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. And there's a support for accessing data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and lots of other data sources. Another Apache framework to consider is Apache Mahout. Mahout is more focused on performing distributed linear-algebra computations. Mahout also supports Spark engine, which means it can run inline with existing Spark application. It is easier to write or extend an algorithm in Mahout if it doesn't have an implementation in any Spark library like MLlib.
That being said, MapReduce isn't the only way to have your Machine learning algorithm executed in a distributed manner. Message Passing Interface (MPI) is another programming paradigm for parallel computing. MPI is a more general model and provides a standard for communication between the processes by message-passing. It gives more flexibility (and control) over inter-node communication in the cluster. For use-cases involving smaller datasets or more communication amongst the decomposed tasks, libraries based on MPI can be a better choice.
All the mature Deep learning frameworks like tensorflow, MxNet, pytorch themselves also provide APIs to perform distributed computations by model and data parallelism. Also, there are frameworks at higher-level like horovod , elephas built on top of these frameworks. So it all boils down to what your use-case is and what level of abstraction is appropriate for you.
When solving a unique problem with Machine learning using a novel architecture, a lot of experimentation is involved w.r.t hyperparameters. The hyperparameter search space can be large, and it may not be practically feasible to try every combination. This can make the fine tuning process really difficult. The solution to this problem lies in using some Hyperparameter Optimization strategy to select the best (or approximately best) hyperparameters for the model.
Hyperparameter optimizations aim to minimize the loss function on a given set of data. One such technique that you are already familiar with is Gradient-based optimization, which is used in training neural networks to find the ideal weights. For another kind of Machine learning models like SVM, Decision trees, Q-learning, etc., we can try out other strategies like Random Search, Bayesian optimization, Evolutionary optimization, etc. Couple of popular frameworks that you can use for hyperparameter optimization in a distributed environment are ray and hyperopt.
The memory requirements for training a neural network increases linearly with depth and the batch-size. There have been active researches going on to diminish this linear scaling so that memory usage can be reduced. arXiv:1604.06174 proposes a technique for square root scaling instead of linear at the cost of little extra computation complexity. Openai/gradient-checkpointing package implements an extended version of this technique that you can use in your tensorflow models.
This is another area with a lot of active research. Machine learning frameworks by default use 32-bit floating point precision for inference and training the models. There is evidence that we can use lower numerical precision (like 16-bit for training, and 8-bit for inference) at the cost of minimal accuracy. Reducing the precision will right away lead to reduced memory footprint, better bandwidth utilization, improved caching and speeded up model performance (hardware can perform higher operations per second on low precision operands). However, reducing precision is not as straightforward as simply casting all the values to lower precision. It leads to quantization noise, gradient underflow, imprecise weight updates, and other similar problems. If you want to dig deeper on how to do it correctly, Nvidia's documentation about mixed precision training ts highly recommended.
It's easy to get lost in the sea of emerging techniques for efficiently doing machine learning at scale. We should also keep the following things in mind while judiciously designing our architecture and pipeline.
- In most use cases, accuracy is not the only thing that matters. After certain iterations of training, the extra-accuracy that we gain on every new training iteration tends to become negligible. We shouldn't strive too hard for those minimal accuracy gains and know when it's the right time to pull the brakes and stop training.
- Unless we are working on a problem statement that hasn't been solved before, or trying to come up with a novel architecture, we should try not to reinvent the wheel. For instance, for natural language processing task like sentiment analysis, we can download already existing vector embeddings like GloVe, and for image classification tasks we can use pre-trained state-of-the-art models like VGG-16 trained on Imagenet. And we can always fine-tune these pre-trained models for our use case using Transfer learning
- Try to look for distributed versions of algorithms. Elastic SGD (Asynchronous SGD, Butterfly SGD, Sparse SGD) However, There's none one-technique fits all for solving the scaling problems in the context of machine learning. Not everything can be parallelized; some algorithms do not have a distributed implementation. So it's vital to spend extra efforts during conceptual modeling and plan the architecture wisely.
- When doing Machine learning models at scale, it becomes vital to track versions and history of the models (which model was used, what hyperparameters were used, How previous iterations (during tweaking) performed? and so on). This helps to know in the long which model was chosen over the others and why.
When you're training at scale, it becomes more important to actively monitor different aspects of the pipeline for memory and CPU usage. Using cloud services like Elastic compute can turn out to be a double-edged sword (in terms of cost) if not used carefully. It's always advisable to run a mini version of your pipeline on the resource that you completely own (like your local machine) before starting full-fledged training on the cloud.
Also, to get the most out of available resources, we can interleave processes depending on different resources so that no resource is idle (Example, interleaving Extraction, transformation and loading in the input pipeline). Many companies have also designed internal orchestration frameworks responsible for scheduling of different machine learning experiments in an optimized way.
Here comes the final part, putting the model out for use by the real world. The first thing to consider is how to serialize your model. Most frameworks have high-level APIs for checkpointing (or saving) and loading the models. And if you do end up using some custom serialization method, it's a good practice to separate the architecture (algorithm), and the coefficients (parameters) learned during training. There might be various kinds of use-cases for the trained model. You might have to integrate it inside an existing software, or maybe you want to expose it to the web.
If the idea is to expose it to the web, then there are a few interesting options to explore. For instance, you can execute a tensorflow/keras model on the user's browser with tensorflowjs, which is a WebGL based library for deploying/training ML models that also supports hardware acceleration. This way you won't even need a backend. The downsides to it are that your model is publically visible (including the weights), which might be undesirable in some cases, and the inference time depends on the client's machine.
If you are planning to have a backend with an API, then it all boils down to how to scale a web application. We can consider using a typical web-server architecture with a load balancer (or a queue mechanism) and multiple worker machines (or consumers).
We can also consider a serverless architecture on the cloud (like AWS lambda) for running the inference function which will hide all the operationalization complexity and allow you to pay-per-execution. One caveat with AWS Lambda is the cold-start time of a few seconds, which by the way also depends on the language. Since cold start happens once for every concurrent execution request, if your application traffic is spikey in nature and can strictly tolerate a very less latency, than it might not be the best option. On the other hand, if the traffic is predictable and delays in very few responses are acceptable, then it's an option worth considering.
Finally, there are other full-fledge services like Amazon SageMaker, Google Cloud ML, Azure ML that you might want to have a look at. Apart from the usual cloud web features like auto-scaling, you'll get machine learning specific features like the Auto tuning of hyperparameters, monitoring dashboards, easy deployments with rolling updates, and well-defined pipelines. However, the downside is the ecosystem lock-in (less flexibility) and a higher cost.
In these posts, we analyzed the problem of building scalable machine learning solutions. We went through a lot of technologies, concepts, and ongoing research topics relevant to doing Machine learning at scale. We tried covered a lot of breadths and just-enough depth. We hope that from the next time whenever you face the challenge of implementing a Machine learning solution at scale, you know where exactly to dive deep into!
I went through the post again and felt this too. I've tried to make the transitions smoother and the post more closely-knit.
Added assumptions in the last paragraph of the section.
Agreed. Map reduce is a more general concept. I've added this because during my research a lot of resources recommended Spark MLLib. So I feel a little intro about MapReduce is required for maintaining the flow and introducing Spark, then MLLib and Mahout.
Mentioning fewer technlogies now :)