Last active
May 16, 2024 10:44
-
-
Save scruel/36cb4614665acc5943ff8c563e884081 to your computer and use it in GitHub Desktop.
修正微软拼音输入法无法添加多个格式化自定义短语的问题,默认添加 sj 和 rq 两个自定义短语
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| """ | |
| 修正微软拼音输入法无法添加多个格式化自定义短语的问题 | |
| Author: Scruel Tao | |
| """ | |
| import os | |
| import re | |
| import pathlib | |
| import traceback | |
| from pathlib import Path | |
| # 自定义: 下面设置自定义短语,格式<拼音 位置 短语>,一行一项,短语中可放心包含空格 | |
| # 或也可在该脚本的同目录下,创建一个 phrases.txt,在其中以同一格式写入自定义短语 | |
| PHRASES_TEXT = """ | |
| rq 1 %yyyy%-%MM%-%dd% | |
| sj 1 %yyyy%-%MM%-%dd% %HH%:%mm%:%ss% | |
| """.strip() | |
| LEX_FILE = os.path.join(os.getenv('APPDATA'), | |
| r'Microsoft\InputMethod\Chs\ChsPinyinEUDPv1.lex') | |
| HEADER_LEN = 16 + 4 | |
| PHRASE_64PCNT_POS = HEADER_LEN | |
| TOTAL_BYTES_POS = HEADER_LEN + 4 | |
| PHRASE_CNT_POS = HEADER_LEN + 8 | |
| PADDED_ENCODING = 'utf-16le' | |
| HEADER_BYTES = bytes('mschxudp', encoding='ascii') | |
| HEADER_BYTES = HEADER_BYTES + bytes('\x02\x60\x01\x00', PADDED_ENCODING) | |
| PHRASE_SEPARATOR_BYTES = b'\x00\x00' | |
| PHRASE_SEPARATOR_SIZE = len(PHRASE_SEPARATOR_BYTES) | |
| PHRASE_LEN_FIRST_POS = PHRASE_CNT_POS + 40 | |
| phrase_fixed_last_bytes = b'\xA5\x2C' | |
| def read_bytes(position, length=1): | |
| with open(LEX_FILE, 'rb+') as file: | |
| file.seek(position) | |
| return file.read(length) | |
| def replace_bytes(position, value): | |
| with open(LEX_FILE, 'rb+') as file: | |
| file.seek(position) | |
| data = file.read() | |
| file.seek(position) | |
| file.write(value + data[len(value):]) | |
| def bytes2int(data): | |
| return int.from_bytes(data, byteorder='little') | |
| def int2bytes(data, length=1): | |
| return int.to_bytes(data, length=length, byteorder='little') | |
| def padded_bytes(s): | |
| def padded_byte(c): | |
| b = bytes(c, PADDED_ENCODING) | |
| return b + b'\x00' if len(b) == 1 else b | |
| return b''.join([padded_byte(c) for c in s]) | |
| def get_phrase_header(header_pinyin_len, index): | |
| return (b'\x10\x00\x10\x00' + int2bytes(header_pinyin_len, 2) | |
| + int2bytes(index) + b'\x06\x00\x00\x00\x00' + b'\x00\x00' | |
| + phrase_fixed_last_bytes) | |
| def main(): | |
| global phrase_fixed_last_bytes | |
| current_dir = os.path.dirname(os.path.realpath(__file__)) | |
| phrases_file = Path(current_dir) / 'phrases.txt' | |
| phrases_text = PHRASES_TEXT | |
| if phrases_file.exists(): | |
| try: | |
| phrases_file_text = phrases_file.read_text('utf-8') | |
| except: | |
| phrases_file_text = phrases_file.read_text('gbk') | |
| phrases_text += '\n' + phrases_file_text.replace('\r\n', '\n') | |
| phrase_items = list(set([x.strip() for x in phrases_text.split('\n') if x])) | |
| print(f"==================\n" | |
| f"Author: Scruel Tao\n" | |
| f"==================\n\n" | |
| f"正在修正巨硬拼音并添加\n" | |
| f"预置的日期格式化短语……\n" | |
| f"\n" | |
| f"短语数量:{len(phrase_items)}\n" | |
| ) | |
| last_phrase_pos = 0 | |
| phrase_list = [] # (is_new, pinyin, header, phrase)) | |
| if not os.path.exists(LEX_FILE): | |
| with open(LEX_FILE, 'wb') as f: | |
| # Initing lex file | |
| f.write(HEADER_BYTES) | |
| f.write((b'\x40' + b'\x00' * 3) * 3) | |
| f.write(b'\x00' * 4) | |
| f.write(b'\x38\xd2\xa3\x65') | |
| f.write(b'\x00' * 32) | |
| else: | |
| phrase_cnt = bytes2int(read_bytes(PHRASE_CNT_POS, 4)) | |
| phrase_block_first_pos = PHRASE_LEN_FIRST_POS + 4 * (phrase_cnt - 1) | |
| # Read existing phrases | |
| for i in range(phrase_cnt): | |
| if i == phrase_cnt - 1: | |
| phrase_block_pos = phrase_block_len = -1 | |
| else: | |
| phrase_block_pos = bytes2int( | |
| read_bytes(PHRASE_LEN_FIRST_POS + i * 4, 4)) | |
| phrase_block_len = phrase_block_pos - last_phrase_pos | |
| phrase_block_bytes = read_bytes( | |
| phrase_block_first_pos + last_phrase_pos, phrase_block_len) | |
| last_phrase_pos = phrase_block_pos | |
| pinyin_bytes, phrase_bytes = re.match( | |
| (b'(.+)' + PHRASE_SEPARATOR_BYTES) * 2, phrase_block_bytes[16:]).groups() | |
| phrase_fixed_last_bytes = phrase_block_bytes[14:16] | |
| # Prevent deleted phrases | |
| if phrase_block_bytes[9:10] == b'\x00': | |
| phrase_list.append((0, pinyin_bytes, | |
| phrase_block_bytes[:16], phrase_bytes)) | |
| # Fix custom phrases | |
| for item in phrase_items: | |
| if not item: | |
| continue | |
| pinyin, index, phrase = item.split(maxsplit=2) | |
| pinyin_bytes = padded_bytes(pinyin) | |
| phrase_bytes = padded_bytes(phrase) | |
| phrase_list = [x for x in phrase_list if x[0] or not x[1] == pinyin_bytes] | |
| header = get_phrase_header( | |
| 16 + len(pinyin_bytes) + PHRASE_SEPARATOR_SIZE, int(index)) | |
| phrase_list.append((1, pinyin_bytes, header, phrase_bytes)) | |
| # Necessary fix, otherwise the order of phrases will be messed up. | |
| phrase_list.sort(key=lambda x: x[1]) | |
| # Write phrases | |
| tolast_phrase_pos = 0 | |
| total_size = PHRASE_LEN_FIRST_POS | |
| with open(LEX_FILE, 'rb+') as file: | |
| file.seek(PHRASE_LEN_FIRST_POS) | |
| file.truncate() | |
| for _, *items in phrase_list[:-1]: | |
| phrase_len = sum(map(len, items)) + PHRASE_SEPARATOR_SIZE * 2 | |
| tolast_phrase_pos += phrase_len | |
| file.write(int2bytes(tolast_phrase_pos, length=4)) | |
| total_size += PHRASE_SEPARATOR_SIZE * 2 | |
| for _, pinyin_bytes, header, phrase_bytes in phrase_list: | |
| file.write(header) | |
| data_bytes = PHRASE_SEPARATOR_BYTES.join( | |
| [pinyin_bytes, phrase_bytes, b'']) | |
| file.write(data_bytes) | |
| total_size += len(header) + len(data_bytes) | |
| # Fix file header | |
| replace_bytes(PHRASE_64PCNT_POS, int2bytes( | |
| 64 + len(phrase_list) * 4, length=4)) | |
| replace_bytes(PHRASE_CNT_POS, int2bytes(len(phrase_list), length=4)) | |
| replace_bytes(TOTAL_BYTES_POS, int2bytes(total_size, length=4)) | |
| if __name__ == "__main__": | |
| try: | |
| main() | |
| print('Done') | |
| except: | |
| traceback.print_exc() | |
| os.system('pause') |
@latv666 看了下之前上传的是写了一半的代码,现在没问题了。
同时顺便简化了一下代码,增加了你要的自定义候选词位置和对中文的支持。
@latv666 看了下之前上传的是写了一半的代码,现在没问题了。 同时顺便简化了一下代码,增加了你要的自定义候选词位置和对中文的支持。
非常感谢,测试成功

非常感谢,问题已经解决了~
非常感谢!您编写的脚本成功的帮助了我👍
非常感谢, 让我不用再去下载qq输入法了...
效果非常好,解决了手动设置两个变量,就无法使用

Traceback (most recent call last):
File "PyCharm2023.3\light-edit\fix-ms-input-pinyin-phrase.py", line 168, in <module>
main()
File "PyCharm2023.3\light-edit\fix-ms-input-pinyin-phrase.py", line 118, in main
pinyin_bytes, phrase_bytes = re.match(
AttributeError: 'NoneType' object has no attribute 'groups'
4月2日使是正常的, 这次使用就报错了.
我尝试了最新版也是这里报错, 我也尝试了先清空自定义短语, 直接使用, 还是同样的问题.
@luoshuaidev 我这里仍正常,另外最近比较忙,可能没时间解决相关问题,建议自行调试一下。
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
你好,非常感谢你在国庆期间写了这个脚本
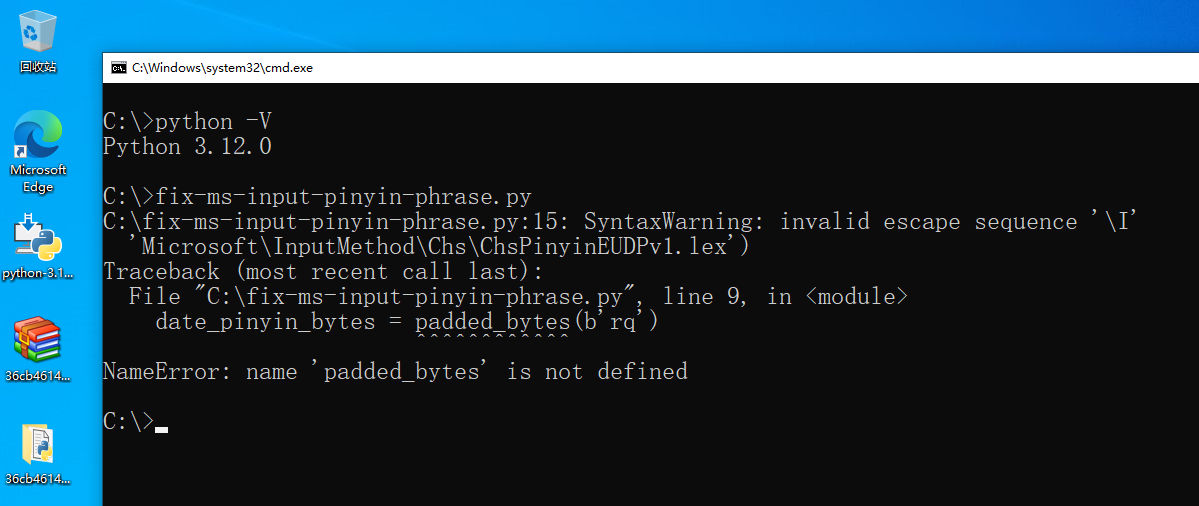
我在运行时报错,如图,环境是 VMware 16 + win10 x64 + python 3.12
目前是可以自定义首个候选字,可不可以定义为首个以外的候选字? 比如我自定义 rq,首候选字是 2023年10月07日,次候选字是 2023年10月07日_125521
另外这个脚本似乎对中文支持的不是很好,比如我自定义的是 %yyyy%年%MM%月%dd%日,好像也会报错