01/13/2012. From a lecture by Professor John Ousterhout at Stanford, class CS140
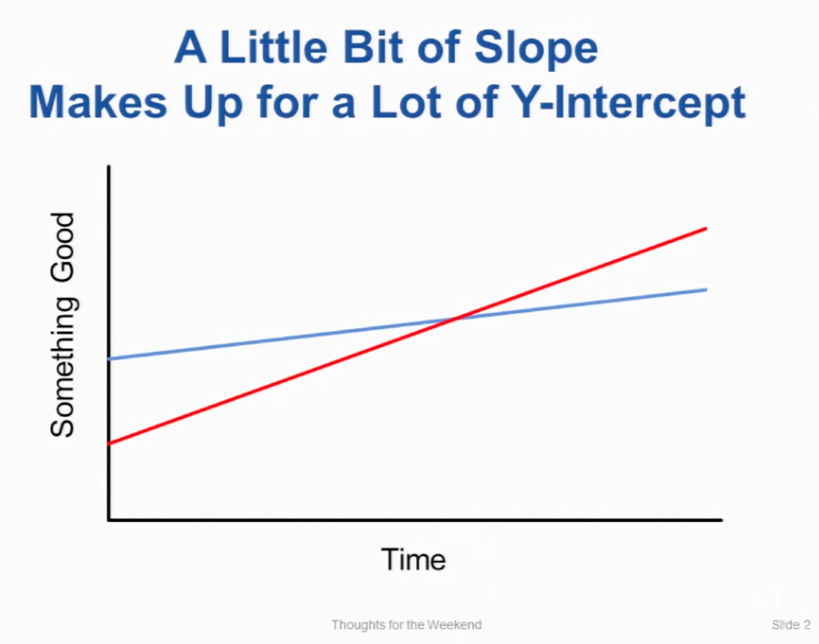
Here's today's thought for the weekend. A little bit of slope makes up for a lot of Y-intercept.
[Laughter]
| defaults write com.apple.Dock appswitcher-all-displays -bool true | |
| killall Dock |
Copyright © 2016-2018 Fantasyland Institute of Learning. All rights reserved.
A function is a mapping from one set, called a domain, to another set, called the codomain. A function associates every element in the domain with exactly one element in the codomain. In Scala, both domain and codomain are types.
val square : Int => Int = x => x * xNote: I have moved this list to a proper repository. I'll leave this gist up, but it won't be updated. To submit an idea, open a PR on the repo.
Note that I have not tried all of these personally, and cannot and do not vouch for all of the tools listed here. In most cases, the descriptions here are copied directly from their code repos. Some may have been abandoned. Investigate before installing/using.
The ones I use regularly include: bat, dust, fd, fend, hyperfine, miniserve, ripgrep, just, cargo-audit and cargo-wipe.
I was at Amazon for about six and a half years, and now I've been at Google for that long. One thing that struck me immediately about the two companies -- an impression that has been reinforced almost daily -- is that Amazon does everything wrong, and Google does everything right. Sure, it's a sweeping generalization, but a surprisingly accurate one. It's pretty crazy. There are probably a hundred or even two hundred different ways you can compare the two companies, and Google is superior in all but three of them, if I recall correctly. I actually did a spreadsheet at one point but Legal wouldn't let me show it to anyone, even though recruiting loved it.
I mean, just to give you a very brief taste: Amazon's recruiting process is fundamentally flawed by having teams hire for themselves, so their hiring bar is incredibly inconsistent across teams, despite various efforts they've made to level it out. And their operations are a mess; they don't real
| #![feature(unboxed_closures)] | |
| #![feature(core)] | |
| #![feature(io)] | |
| use std::old_io::stdio::{stdin}; | |
| use std::collections::HashMap; | |
| // This is our toy state example. | |
| #[derive(Debug)] | |
| struct State { |
Yoav Goldberg, April 2023.
With the release of the ChatGPT model and followup large language models (LLMs), there was a lot of discussion of the importance of "RLHF training", that is, "reinforcement learning from human feedback". I was puzzled for a while as to why RL (Reinforcement Learning) is better than learning from demonstrations (a.k.a supervised learning) for training language models. Shouldn't learning from demonstrations (or, in language model terminology "instruction fine tuning", learning to immitate human written answers) be sufficient? I came up with a theoretical argument that was somewhat convincing. But I came to realize there is an additional argumment which not only supports the case of RL training, but also requires it, in particular for models like ChatGPT. This additional argument is spelled out in (the first half of) a talk by John Schulman from OpenAI. This post pretty much