-
-
Save seaside2mm/376926aecb0e230af44554f869af871a to your computer and use it in GitHub Desktop.
GPU显卡 ls -l /dev/nv* 查看是否安装GPU加速卡
// cudaDeviceProp deviceProp;
// CHECK(cudaGetDeviceProperties(&deviceProp, dev));
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 3080"
CUDA Driver Version / Runtime Version 11.7 / 11.7
CUDA Capability Major/Minor version number: 8.6
Total amount of global memory: 10.00 MBytes (10736893952 bytes)
GPU Clock rate: 1710 MHz (1.71 GHz)
Memory Clock rate: 9501 Mhz
Memory Bus Width: 320-bit
L2 Cache Size: 5242880 bytes
Max Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072,65536), 3D=(16384,16384,16384)
Max Layered Texture Size (dim) x layers 1D=(32768) x 2048, 2D=(32768,32768) x 2048
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Maximum sizes of each dimension of a block: 1024 x 1024 x 64
Maximum sizes of each dimension of a grid: 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes- nvcc
-archsm_86: 为不同架构生成设备代码
--device-debug (-G) : 关闭大多数优化
-lineinfo :文件名和行号关联
-Xcompiler -rdynamic : 堆栈信息
- cuda-gdb 焦点:cuda thread lane warp block sm grid device kernel 检查共享内存: print (@shared int)0x4 环境信息: help info cuda
cuda-memcheck
cuda-racecheck
-
printf
-
assert
nvvp & nvprof nvprof 获取时间线信息,包括内核执行,内存传输以及CUDA API的调用等。
- nvprof 4种模式 summary mode trace mode --print-gpu-trace --print-api-trace event/metric summary mode --metrics event/metric trace mode
分析内存带宽
全局内存访问
加载和存储吞吐量: gld_throughput gst_throughput
加载和存储效率: gld_efficientcy gst_efficientcy
共享内存存储体冲突
效率: shared_efficientcy
寄存器溢出
指令吞吐量
线程束分化: branch_efficientcy
- 局部分析
如果只想对某一段代码进行分析,在目标代码段前后加上
cudaProfilerStart()和cudaProfilerStop()。
对于 nvvp,需要在设置中取消勾选 Start execution with profiling enabled。对于 nvprof,也有相应的参数可以配置。
NSight System
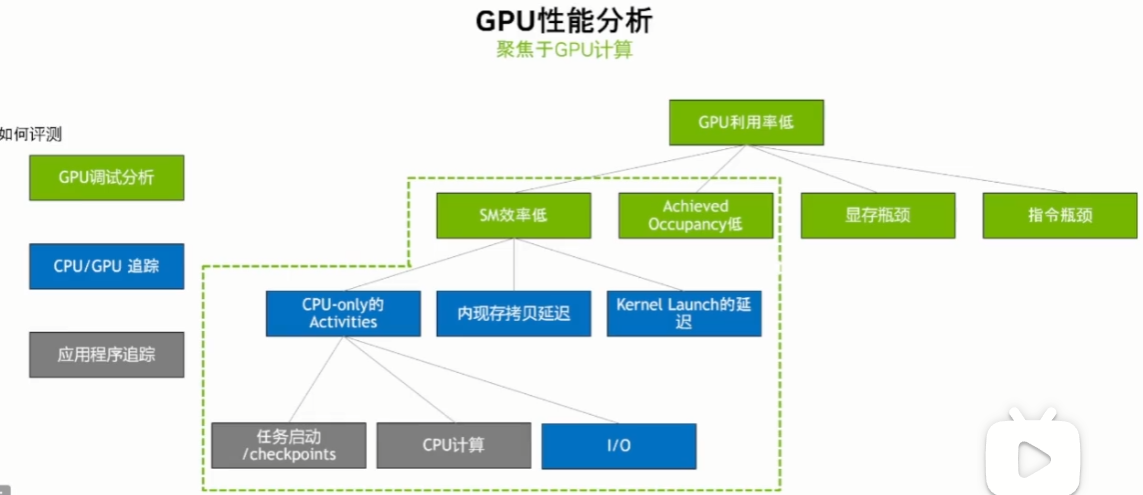
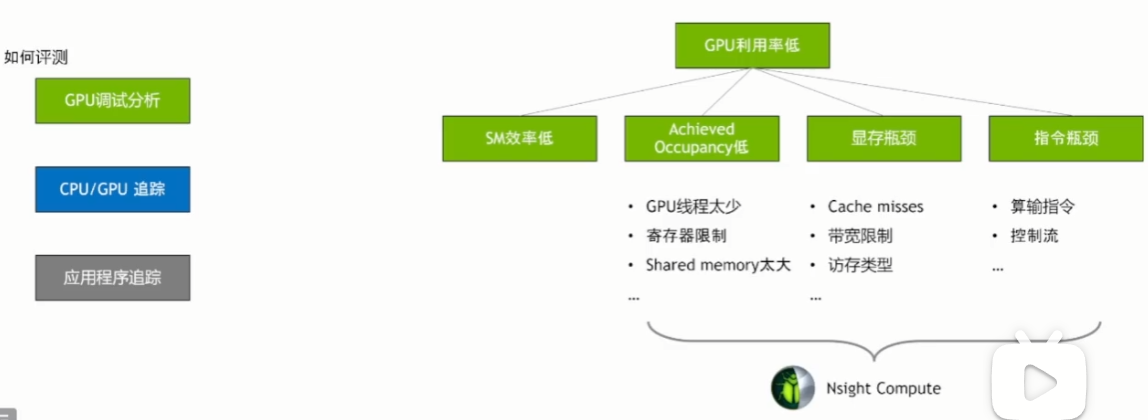
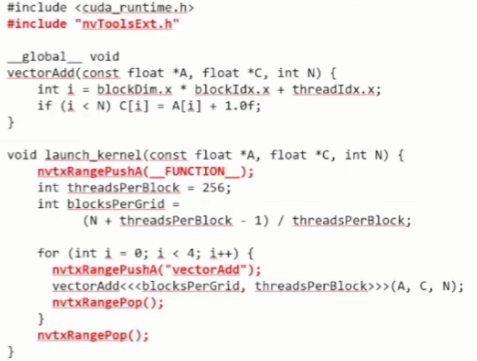
NVTX
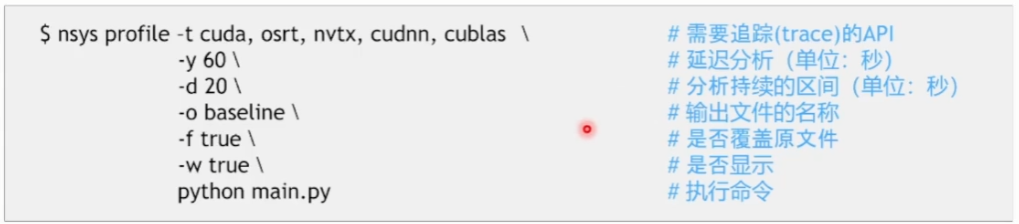 The most commonly used nsys commands are:
profile Run an application and capture its profile into a QDSTRM file.
launch Launch an application ready to be profiled.
start Start a profiling session.
stop Stop a profiling session and capture its profile into a QDSTRM file.
cancel Cancel a profiling session and discard any collected data.
stats Generate statistics from an existing nsys-rep or SQLite file.
status Provide current status of CLI or the collection environment.
shutdown Disconnect launched processes from the profiler and shutdown the profiler.
sessions list List active sessions.
export Export nsys-rep file into another format.
analyze Run rules on an existing nsys-rep or SQLITE file.
nvprof Translate nvprof switches to nsys switches and execute collection.
The most commonly used nsys commands are:
profile Run an application and capture its profile into a QDSTRM file.
launch Launch an application ready to be profiled.
start Start a profiling session.
stop Stop a profiling session and capture its profile into a QDSTRM file.
cancel Cancel a profiling session and discard any collected data.
stats Generate statistics from an existing nsys-rep or SQLite file.
status Provide current status of CLI or the collection environment.
shutdown Disconnect launched processes from the profiler and shutdown the profiler.
sessions list List active sessions.
export Export nsys-rep file into another format.
analyze Run rules on an existing nsys-rep or SQLITE file.
nvprof Translate nvprof switches to nsys switches and execute collection.
global 用于定义核函数,他在 GPU 上执行,从 CPU 端通过三重尖括号语法调用,可以有参数,不可以有返回值。
device 则用于定义设备函数,他在 GPU 上执行,但是从 GPU 上调用的,而且不需要三重尖括号,和普通函数用起来一样,可以有参数,有返回值。
host device 这样的双重修饰符,可以把函数同时定义在 CPU 和 GPU 上,这样 CPU 和 GPU 都可以调用
#include <cstdio>
#include <cuda_runtime.h>
__host__ __device__ void say_hello() {
#ifdef __CUDA_ARCH__
printf("Hello, world from GPU architecture %d!\n", __CUDA_ARCH__);
#else
printf("Hello, world from CPU!\n");
#endif
}
__global__ void kernel() {
say_hello();
}
int main() {
kernel<<<1, 1>>>();
//GPU和CPU之间的通信是异步的,下函数让CPU 陷入等待,等GPU完成队列的所有任务后再返回。
cudaDeviceSynchronize();
say_hello();
return 0;
}两层的线程层次结构:
- 线程网格
一个内核启动产生的所有线程统称为一个网格,共享全局内存空间。 块数量:
gridDim
- 线程块
一个线程块包含一组线程。线程数量:
blockDim
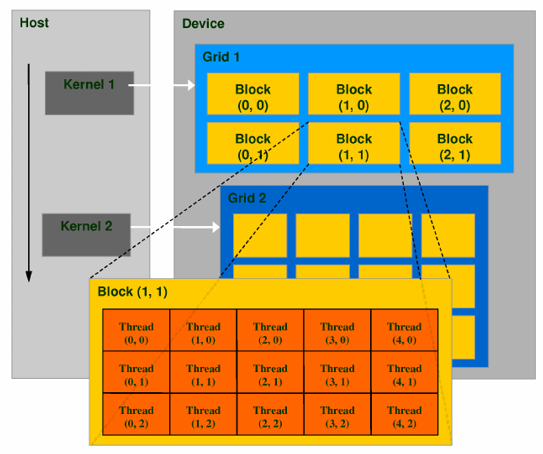
线程依靠两个坐标变量区分:
- 当前线程在板块中的编号:threadIdx
- 当前板块的编号:blockIdx
Inx与Dim: 有
x,y,z三个字段
- 如需总的线程数量:
blockDim * gridDim - 如需总的线程编号:
blockDim * blockIdx + threadIdx
// 2维
__global__ void kernel() {
printf("Block %d of %d, Thread %d of %d\n",
blockIdx.x, gridDim.x, threadIdx.x, blockDim.x);
// 扁平化
unsigned int tid = blockDim.x * blockIdx.x + threadIdx.x;
unsigned int tnum = blockDim.x * gridDim.x;
printf("Flattened Thread %d of %d\n", tid, tnum);
}
int main() {
//块数量,每个板块中的线程数量
kernel<<<2, 3>>>();
cudaDeviceSynchronize();
return 0;
}
// 3维
__global__ void kernel() {
printf("Block (%d,%d,%d) of (%d,%d,%d), Thread (%d,%d,%d) of (%d,%d,%d)\n",
blockIdx.x, blockIdx.y, blockIdx.z,
gridDim.x, gridDim.y, gridDim.z,
threadIdx.x, threadIdx.y, threadIdx.z,
blockDim.x, blockDim.y, blockDim.z);
}
int main() {
// x维度2个block,每个block的x,y,z维度都两个,总共16个线程
kernel<<<dim3(2, 1, 1), dim3(2, 2, 2)>>>();
cudaDeviceSynchronize();
return 0;
}
- 设备内存
| C函数 | CUDA函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
- 统一内存(managed): cudaMallocManage, cudaFree
//自动同步,无需cudaDeviceSynchronize
cudaError_t cudaMemcpy(void * dst,const void * src,size_t count, cudaMemcpyKind kind)
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice

- 每个线程负责处理一个元素
//除余为了向上取整,这样会多出来一些线程,因此要在 kernel 内判断当前 i 是否超过了 n,如果超过就要提前退出,防止越界。
int nthreads = NUM;
int nblocks = (n + nthreads + 1) / nthreads;- 网格跨步循环(grid-stride loop) 英伟达官方博客
利用扁平化的线程数量和线程编号实现动态大小。 同样,无论调用者指定每个板块多少线程(blockDim),总共多少板块(gridDim)。都能自动根据给定的 n 区间循环,不会越界,也不会漏掉几个元素。 这样一个 for 循环非常符合 CPU 上常见的 parallel for 的习惯,又能自动匹配不同的 blockDim 和 gridDim,看起来非常方便。
__global__ void kernel(int *arr, int n) {
for (int i = threadIdx.x; i < n; i += blockDim.x) {
arr[i] = i;
}
}
__global__ void kernel(int *arr, int n) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
arr[i] = i;
}
}template <class T>
struct CudaAllocator {
using value_type = T;
T *allocate(size_t size) {
T *ptr = nullptr;
checkCudaErrors(cudaMallocManaged(&ptr, size * sizeof(T)));
return ptr;
}
void deallocate(T *ptr, size_t size = 0) {
checkCudaErrors(cudaFree(ptr));
}
//初始化的时候(或是之后 resize 的时候)会调用所有元素的无参构造函数,对 int 类型来说就是零初始化。
//然而这个初始化会是在 CPU 上做的,因此我们需要禁用他。
//可以通过给 allocator 添加 construct 成员函数,来魔改 vector 对元素的构造。默认情况下他可以有任意多个参数,而如果没有参数则说明是无参构造函数。
//因此我们只需要判断是不是有参数,然后是不是传统的 C 语言类型(plain-old-data),如果是,则跳过其无参构造,从而避免在 CPU 上低效的零初始化。
template <class ...Args>
void construct(T *p, Args &&...args) {
if constexpr (!(sizeof...(Args) == 0 && std::is_pod_v<T>))
::new((void *)p) T(std::forward<Args>(args)...);
}
};
//核函数自然也是可以为模板函数的。
template <class Func>
__global__ void parallel_for(int n, Func func) {
for (int i = blockDim.x * blockIdx.x + threadIdx.x;
i < n; i += blockDim.x * gridDim.x) {
func(i);
}
}
/* 核函数可以接受函子(functor),实现函数式编程
1.这里的 Func 不可以是 Func const &,那样会变成一个指向 CPU 内存地址的指针,从而出错。所以 CPU 向 GPU 的传参必须按值传。
2.做参数的这个函数必须是一个有着成员函数 operator() 的类型,即 functor 类。而不能是独立的函数,否则报错。
3.这个函数必须标记为 __device__,即 GPU 上的函数,否则会变成 CPU 上的函数。
*/
struct MyFunctor {
__device__ void operator()(int i) const {
printf("number %d\n", i);
}
};
int main() {
int n = 65536;
std::vector<int, CudaAllocator<int>> arr(n);
parallel_for<<<32, 128>>>(n, MyFunctor{});
// lambda 表达式
// [&] 捕获变量是会出错的,毕竟这时候捕获到的是堆栈(CPU内存)上的变量 arr 本身,而不是 arr 所指向的内存地址(GPU内存)
// [=] 按值捕获,会把 vector 整个地拷贝到 GPU 上!而不是浅拷贝其起始地址指针
// 正确:先获取 arr.data() 的值到 arr_data 变量,然后用 [=] 按值捕获 arr_data,函数体里面也通过 arr_data 来访问 arr。
parallel_for<<<32, 128>>>(n, [arr = arr.data()] __device__ (int i) {
arr[i] = i;
});
checkCudaErrors(cudaDeviceSynchronize());
for (int i = 0; i < n; i++) {
printf("arr[%d] = %d\n", i, arr[i]);
}
return 0;
}