
GoogleでのSREチームの始め方
- 大きなプロジェクトの一部として新たにチームを作る
- 水平(組織横断型)のチームを設立する
- 既存のチーム、例えば運用チームをSREにする
どのアプローチを選択するかは組織によるが、チームにはサービスを運営できるのに必要なオペレーション作業を扱えるようなSREが十分に必要である。このことから、第3の原則が出てくる。
- SREチームは自分たちの作業量を制限できる
- (権限が与えられる?作業量を調整できるスキルが必要ということ?)
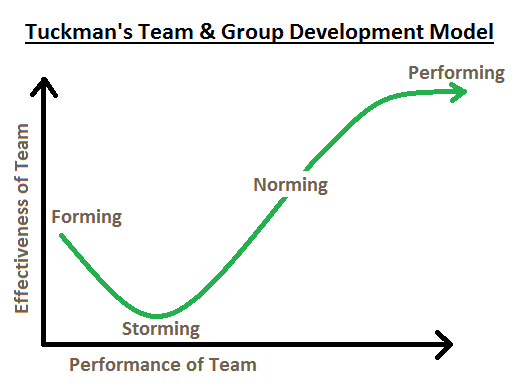
大きなSRE組織以外では、この原則の考えを初日から内包することはできない(チームの中に持つことはできない)。この原則はいろんな解釈が可能(open to interpretation)で、組織的に実践に持ち込むのが難しくなりうる。Googleの3原則の中で最も繊細であり、いくつかのunpackingが生じる(箱からなにかから出てくるイメージ?)。以降のセクションではチームビルディングのステージを、Tuckman's performance modelと_forming_, storming, norming, そして _performing_を利用して、順を追って説明していく。
bear 産む、出産する、つける、結ぶ、生む、身につける、帯びる、記載がある、抱く、もつ https://ejje.weblio.jp/content/bear
あなたが作るチームは以下を含む経験と専門分野を兼ね備えてと良い。
- アプリケーション・ソフトウェアをreliabilityと性能を改善するために修正すること
- ソフトウェアを以下の目的のために書くこと
- 本番環境での問題検知と緩和を手早く片付けること
- 手動で行っている処理を自動化すること
- 長期的なメンテナンス性を容易にするための強いソフトウェアプラクティスと標準(基準?)を確立し使うこと
- オペレーションの変更を行うために理路整然として丁寧なアプローチを持つこと
- つまり、なぜある方法が信頼できるものなのかを説明できること
- (分散システムの設計や運用の)システム・アーキテクチャを理解すること
expedite はかどらせる、促進する、手早く片づける https://ejje.weblio.jp/content/Expedite facilitate 容易にする、楽にする、促進する https://ejje.weblio.jp/content/facilitate methodical (規則正しく論理的で組織的な)方法によった、(秩序)整然とした、系統的な、規則正しい、きちょうめんな https://ejje.weblio.jp/content/methodical
理想的には:
- 新しい働き方を取り入れる準備ができていること
- スキルのバランスと他のチームとの個人的な信頼関係があること
可能であれば、社内異動でチームの準備(種を撒く?)をしていると良い。そうすればチームが動き出すための時間を減らすことができる。
- internal transfer -> 社内異動?
- 外部から人を集めてくるんじゃなくて、社内異動で人を集めてチームを作ると良いということ?
大きなプロジェクでは、reliabilityやオペレーション能力をプロジェクトのリスクとされている場合に、新しいSREチームを作ることがあるだろう。例としては、新規サービスの開発や技術面における重要な変更(パブリッククラウドへの移行)などがある。
justify 正しいとする、正当だと理由づける、自分の行為を弁明する、身のあかしを立てる、(…の)正当性を示す、正当化する、(…の)正当な理由となる、正当な理由となる、罪がないとして許す、整える https://ejje.weblio.jp/content/justify
3センターの開発支援的なチーム。小さなSREチームが多くのチームにわたってコンサルティングしていく感じ。 コンフィグマネジメント、モニタリングそして、アラーティングのためのベストプラクティスやツールを確立しているかもしれない。
既存のチームをSREチームに転換できるかもしれない。既存のチームはプロダクト開発チームのようなものではないかもしれない。典型的な候補となるチームには、運用チームだったり、あなたの組織がよく使っているOSSを管理するチーム(LINEで言うとKafkaとかHBaseとか?)かもしれない。SREの実践や原則を適用することなく、"Operation"から"SRE"という名前変更だけはしないようにしてください!リブランディング(チームの転換)の努力を怠ってしまったら、その後、間違ったSREのコンセプトが組織内に蔓延してしまうだろう
一旦チームが組み上がったら、仲良く働き始める必要がある。そのために、チームの"凝集度"を高めるいくつかのやり方がある。Googleだと、定期的なSREの勉強会やディスカッションをやってたりする。
このフェーズの間、新しいSREメンバーに自分自身をストレッチ(?練習する?訓練する?)することを奨励しよう。新しいSREメンバーは自分の組織には合わなかったSREの実践と、その実践を変更してフィットさせる価値があるかどうかについて気持ちよく話せるようになっていると良い。
cohesion 結合(力)、(分子の)凝集力 https://ejje.weblio.jp/content/cohesion
SREへの道の初期段階の間は、いろんな形でチームは失敗を味わうことになるかもしれない。以降では、どのようにSREチームを形成したかに応じて、いくつかのリスクと取りうる対処法について説明する。それぞれのリスクに対して1つまたはそれ以上の対処法を使うことができるかもしれない。
nascent 発生しようとする、初期の https://ejje.weblio.jp/content/nascent
- 一度に多くのことをやろうとしすぎて薄っぺらいことしかできない
- しょっちゅう炎上しているチームはより恒久的な方法でリスクに取り組む時間がない
- 非常に内省的(外部を顧みない?)なやり方でSREの原則やそれらの実現方法を理解しようとしてしまう。結果として実現できなくなる
- 例えば、完璧なSLO定義を開発するために(時間を)費やしてしまい、その間、サービス側からの要求を無視してしまうとか
- 徹底的に調べない。結果として、サービス管理は以前の振る舞いに戻ってしまう
- そのチームは日に100回の呼び出し(というか通知)が発生していた。その呼び出しは即時の介入を示していないので、彼らは呼び出しを無視するようになった
- プロダクトのマイルストーンを達成するためにSREの原則や実践を放棄する
- SLOを守るためにreliabilityを改善すること、例えばアーキテクチャの変更、は決して実装されないだろう。なぜなら、それらが開発のタイムラインを遅らせることになるから。
- 新しいSREチームの結果として、影響力やパワーの欠如を感じるチームとの対立によって気が散ってしまう(仕事に集中できないみたいな?)
- 必要とされている範囲のスキルがないので、必要な改善の一部しか提供できない
- 例えば、プログラミングの能力無しでSREはreliabilityを測定するためのプロダクトを計測できない
intervention 間に入ること、介在、調停、仲裁、干渉 https://ejje.weblio.jp/content/intervention abandon 捨てる、見捨てる、捨て去る、(中途で)やめる、(…を)やめて(…に)する、身を任せる、ふける https://ejje.weblio.jp/content/abandon distracted そらされた、気の散った、取り乱した、狂気のような、(…に)取り乱して、気が狂いそうで https://ejje.weblio.jp/content/distracted