Created
October 10, 2018 06:40
-
-
Save shegdaMM/cfb5e3f1ce3665cc32b97f6230c01159 to your computer and use it in GitHub Desktop.
notepad++ (регулярные выражения)
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| - 1. Удалить все html-теги, оставить только текст: | |
| **[<].*?>** | |
| - 2. В списке ссылок вида <a href=»LINK»>TITLE</a> удалить все html-теги, оставить только ссылки: | |
| **^[^"]+.([^"]+).*заменить на:$1** | |
| - 3. В том же самом списке оставить только тайтлы: | |
| **</?[^>]*.** | |
| - 4. Удалить пустые строки из файла — уже встроено в саму программу. Смотрите скриншот: | |
| 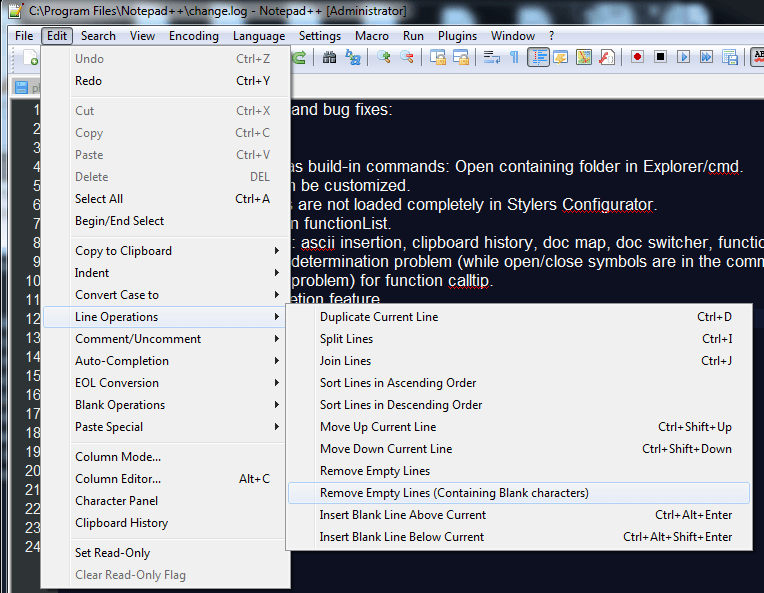 | |
| - 5. Удалить строки с заданным количеством вхождения определенного символа. (Мне это понадобилось, когда нужно было очистить большой список ссылок на товары — 45 тыс. позиций — от ссылок на категории. Друг от друга они отличались общим количеством слешей — в категориях было 5, а в товарах — 6) | |
| **^([^/]*/){5}[^/]*$** | |
| **разъяснение:** | |
| **^ начало строки( начало группы[^/]* любой символ кроме слеша, 0 или более раз/ слеш){5} закончить и повторить группу 5 раз[^/]* любой символ кроме слеша, 0 или более раз$ конец строки** | |
| - 6 Удалить весь текст между двумя определенными символами (в данном примере — между двух кавычек): | |
| **"([^"]*)"** | |
| - 7. Удалить все html-теги с определенным атрибутом. Например, мы хотим удалить все теги (и содержимое тегов), у которых совпадает класс, или инлайн-стили | |
| **<td class="nowrap">([^<]*)</td> - то есть задаем искомую строку, внутри которой может быть произвольный текст. Текст оформляем как ([^<]*) - любые символы,кроме символа открытия (или закрытия) тега.** | |
| - 8. Удалить все теги, внутри которых содержатся только числа: | |
| **<td>(\d+)</td>** | |
| - 9. Удалить заданное количество символов от начала строки (данный пример удаляет первые 9 символов): | |
| **^.{0,9}** | |
| В данном примере выражение \d+ означает любую цифры от 0 до 9 любое количество раз | |
| **Аналогично можно использовать следующие наборы выражений:** | |
| **. — Один произвольный символ** | |
| **^ — Начало строки** | |
| **$ — Конец строки** | |
| **\s — Пробел** | |
| **\S — Не Пробел** | |
| **\w — Буква, цифра или символ подчёркивания _** | |
| **\d — Любая цифра** | |
| **\D — Любой символ кроме цифр** | |
| **[0-9] — Любая цифра** | |
| **[a-z] — Любая буква от a до z (весь латинский набор символов) в нижнем регистре** | |
| **[A-Z] — Любая буква от a до z в ВЕРХНЕМ регистре** | |
| **[a-zA-Z] — Любая буква от a до z в произвольном регистре** | |
| **[a-Z] — Любая буква от a до z в произвольном регистре** | |
| *** — Повторение. Означает, что предшествующий символ может повторяться (0 или более раз)** | |
| **.* — Любой набор символов. Например, условие <p> .*</p> — найдет все что между тегами <p> </p>** | |
| **(^.*$) — Любой текст между началом и концом строки** | |
| **([0-9][0-9]*.) — Любое двухзначное число** | |
| **\n\r — Пустая строка** | |
| **^\s*$ — Пустая строка с пробелом** | |
| **^*$ — Ищет пустые строки содержащие пробел.** | |
| EX: | |
| <!DOCTYPE.*<map name="map"> | |
| </map>.*</html> | |
| <area .*onmouseenter='dShow | |
| <area .*href='javascript:window.pShow | |
| ");' alt=""> | |
| ");' onmouseleave="dHide();"> | |
| ^[^J]* | |
| http://falkhausen.de/docs/ | |
| $ | |
| .html |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment