| title | type | weight | lastmod | |
|---|---|---|---|---|
Develop |
docs |
1 |
|
Last active
August 15, 2024 12:49
-
-
Save showa-93/ec10db8e4fdd60148e6acd61641b9192 to your computer and use it in GitHub Desktop.
Develop
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Microservices |
docs |
showa |
|
1 |
- マイクロサービスパターン[実践的システムデザインのためのコード解説]
- microservices.io
- Building Microservices in Go: Caching using memcached - DEV Community
システム操作とは、アプリケーションが処理するリクエストを抽象化したもの。ドメインモデルに対するふるまいを定義する仕様。
ふるまいの定義とは、システム操作が呼び出されたときに満たすべき前条件と、操作終了後に満たさないとならない後条件。これらを定義するために、高水準のドメインモデルを定義する必要がある。
ビジネスに合わせて分割するサービスを定義する
- 業務に合わせてサービスを定義する
- [ドメイン駆動設計]のサブドメインとして定義
サービスの分割に対するガイドライン⇛[サービスの分割]
個々のサービスのAPIを定義する
- システム操作のサービスへの割当
- 基本的にはサービスに関係のあるシステム操作を割り当てる
- システム操作が提供する情報を必要とするサービスに割り当てる
- サービス間の連携
- システム操作が満たすべき前条件と後条件を満たすように呼び出すサービスを決める
ただし、サービス間で連携する場合、下記に注意が必要
- ネットワークのレイテンシ
- サービス間の同期通信による可用性の低下
対応表
| 1対1 | 1対多 | |
|---|---|---|
| 同期的 | リクエスト/レスポンス | - |
| 非同期的 | 非同期リクエスト/レスポンス | パブリッシュ/サブスクライブ |
| 一方通行の通知 | パブリッシュ/非同期レスポンス |
- [同期的なリモープロシージャパターン]
- リクエスト/レスポンス:同期的な通信。サービス間が密結合になる。
- [非同期的メッセージングパターン]
- 非同期リクエスト/レスポンス:リクエストしたクライアント側がレスポンスを待つブロックをしない状態
- パブリッシュ/サブスクライブ:クライアントがメッセージをパブリッシュし、サブスクライブした0個以上のサービスがメッセージを消費する
- パブリッシュ/非同期レスポンス:パブリッシュしたクライアントが特定のサービスからのレスポンスを待つ
- 一方通行の通知:サービスにリクエストを送るが、レスポンスは期待しない
セマンティックバージョニングを使うことで、互換性のないAPIの更新によって、利用しているサービスがダウンしないような設計を心がける。
セマンティックバージョニングに従うために、以下のような観点でバージョン番号を設定する。
-
Major:APIに互換性のない変更を加えるときにインクリメントする
- HTTPベースの場合、パスにバージョンを組み込んだり、MIMEタイプにversionを含めることで互換性を保つ
-
Minor:APIに下位互換のある変更を加えるときにインクリメントする
- 前提として、堅牢性の原則に従うようにすると下位互換のある変更であれば、古いバージョンのクライアントでも問題ない
- リクエストにオプション属性の追加
- レスポンスの属性の追加
- 新しい操作の追加
-
Patch:下位互換性のあるバグフィックスをするときにインクリメントする
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
非同期的メッセージングパターン |
docs |
showa |
|
1 |
クライアントとサービスの間で対になるメッセージをやり取りする形でインタラクションを実装する。メッセージングを用いているため、非同期的な通信になるが、リプライがあるまでブロックすることで同期的に通信ができる。
- リクエストのメッセージで相関IDとリプライを返すためのチャネルを設定してチャネルに送信する
- リプライでは、リクエストでしていされた相関IDを設定してリプライチャネルに送信する
- クライアントは、リプライチャネルから相関IDに一致するメッセージを取得する
ドメインオブジェクトに変更が加えられたことを表すドメインイベントをパブリッシュするために使う。
チャネルはドメイン名から作ったものにする。特定のドメインオブジェクトに関心を持つサービスが適切なチャネルをサブスクライブするだけでイベントを検知できる。
前述の2つを組み合わせたインタラクションスタイル。
- クライアントは、相関IDとリプライチャネルを指定したメッセージをパブリッシュする。
- コンシューマ(メッセージの消費者)は、相関IDを含んだメッセージをリプライチャネルにパブリッシュする。
- クライアントは、相関IDを使ってリプライメッセージを集める
非同期メッセージングでサービス間のトランザクションを保つ方法
- Transactional outbox パターン
- レコードの変更をOutboxテーブルに保存してイベントを同一トランザクションで保存することで、イベントが発行されることを担保する
- Poling publlisher パターン
- Outboxテーブルをポーリングしてメッセージングをパブリッシュする
- DBへのアクセス負荷が高くなる可能性がある
- Transaction log tailing パターン
- データベースのトランザクションログをログマイナーで読み取り、変更点をメッセージブローカーにパブリッシュする
- データベース固有APIを呼び出す低水準コードを書く
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Circuit Breakerパターン |
docs |
showa |
|
1 |
リモートコールで呼び出し先で障害が発生した場合、呼び出しに失敗したり、応答を待ち続けることになる。
多くの呼び出しが発生した場合、リソース不足になり、連携している複数のシステムに連鎖的に障害が発生する可能性がある。
Michael Nygard氏は、著書「Release It」の中でこのような問題を防ぐためにCircuit Breakerパターンを提唱した。
リクエストの成否を数え、エラー率がしきい値を超過したらサーキットブレーカーを作動させ、その後一定の時間がすぎるまでリクエストを失敗させる。(障害が発生したサービスへのリクエストを遮断)
一定の時間がすぎると、決められた数の試験的なリクエストをおこない、成功すればサーキットブレーカーは通常動作に戻る。失敗する場合は、再度リクエストを失敗させるタイムアウト期間に入る。
TODO: パターンについてまとめる
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
補償トランザクション |
docs |
showa |
|
1 |
(compensating transaction)ローカルトランザクションが失敗した場合、それまでの別サービスのローカルトランザクションを取り消す操作を実行する必要がある。
- 補償可能トランザクション(compenstable transaction)
補償トランザクションを使ってロールバックされる可能性があるトランザクション - ピポットトランザクション
処理を最後まで実行するか、キャンセルするか判断するポイントとなるトランザクション
ピポットトランザクションがコミットされると最後まで実行される - 再試行可能トランザクション
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
カウンターメジャー |
docs |
showa |
|
1 |
countermeasure 分離性の欠如に対処するための設計手法。
あるサーガが加えた変更を他のサーガが取り消す形で書き換えたときに本来あるべき更新の状態が消失してしまう。
あるサーガが更新している途中のデータを他のサーガが読み取ってしまう。
サーガがデータを読み取った後に、他のサーガが該当のデータを書き換えて参照されているデータの値がまちまちになってしまう。
[補償可能トランザクション]は、作成・更新するレコードにフラグをセットする。 フラグによってレコードの状態(ロック中かなど)を管理する。 アプリケーションでロック管理、デッドロックの検出を行う必要がある、
どんな順序で実行しても影響のない更新操作を交換可能と呼ぶ。 他のサーガの更新結果を上書きしないような処理であるため、更新結果の消失の可能性を排除できる。
ダーティリードによるビジネスリスクを最小限に抑えるようにステップの順序を並び替える。
楽観的オフラインロックの一種。 値を更新する前に読み直し、変更されていないことを確認してからレコードを更新する。 レコードが書き換えられている場合、サーガを中止する。
レコードに対して実行された操作を記録し、実行順序をかえられるようにする。 交換不能な操作を交換可能な操作に変更する。
ビジネスリスクに基づいて、利用する並行処理のメカニズムを選択する。 個々のリクエストの性質に基づいてサーガと分散トランザクションを使うか判断する。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
メッセージブローカー |
docs |
showa |
|
1 |
メッセージブローカーは、基本的にAt least oneceを保証している。そのため、2回以上メッセージが飛ばされる可能性がある。
- 冪等なメッセージハンドラ
- アプリケーションのメッセージの処理が冪等であるように作る
- 重複メッセージを破棄
- メッセージを処理するときに消費したメッセージIDをテーブルに格納する
- 消費済みのメッセージを受けたときは登録に失敗するため検知できる
Apache Kafka、RabitMQとかとか
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Saga |
docs |
showa |
|
1 |
マイクロサービスのように個々にDBを有する複数のサービスをまたいだACDトランザクションを保証できる。[カウンターメジャー]によって、[分離性](独立性)がないことによる並行処理の異常の影響を防ぐ必要がある。
サーガのステップ通りに動かすコーディネートコードが参加サービスのトランザクションの実行指示をする。コーディネートコードの実装方法には以下の2種類の方法がある。
サーガの参加サービスに次のステップの判断を委ねる分散管理の方法。参加サービスはイベントを交換して通信をおこなう。
- 参加サービスはトランザクションの一部としてイベントをパブリッシュする必要がある
- データベースの更新とイベントのパブリッシュをアトミックに行う必要がある
- Transactional messagingパターンを利用する
- 参加サービスは受け取ったイベントを自分のデータに対応付ける必要がある
- 相関IDを含めたかたちでイベントをパブリッシュするようにする
メリット
- 単純性:サービスはオブジェクトを作成、更新、削除したときにイベントをパブリッシュする
- 疎結合:イベントをサブスクライブするだけで、お互いについて直接的な知識をもたない
デメリット
- サーガを定義しているコードがまとまっていないため、わかりづらい
- 循環的な依存関係が発生する可能性がある
- サービスが密結合になる可能性がある
サーガオーケストレートクラスでコーディネートロジックを一元管理する方法。起動の起点となるサービスでオーケストレータを作成し、サーガのステップを管理する。
参加サービスと通信を行い、サーガのステップを実行するために参加サービスにコマンドメッセージを送る。
オーケストレータを作成したサービスへのコマンドも参加サービスの1つとしてコマンドメッセージを経由して処理する。
メリット
- コレオグラフィに比べて循環依存がないため依存関係が単純
- コレオグラフィよりも疎結合。参加サービスがパブリッシュイベントについて知識が不要になる
- コーディネートのロジックがオーケストレタにまとめられるため、ドメインがサーガについての知識をもつ必要がなくなる
デメリット
- オーケストレタにビジネスロジックが集中してしまう可能性がある。ファット
状態マシンでモデリングすることで、状態とアクションを紐付けられるため、設計・実装・テストが簡単になる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
サービスディスカバリ |
docs |
showa |
|
1 |
サービスディスカバリメカニズムは、サービスインスタンスが起動・終了したときにサービスレジストリを更新する。クライアントがサービスを呼び出すと、サービスディスカバリメカニズムはサービスレジストリにクエリを送り、利用できるインスタンスの一覧を取得し、どれかにルーティングする。
サービスディスカバリとそのクライアントがサービスレジストリを操作する アプリケーションレベルでサービスディレクトリが存在すると、プラットフォームをまたいでサービスが存在しても、処理できるというメリットがある。
- Self registration パターン
- サービスインスタンスがサービスレジストリの登録APIを呼び出して自分のアドレスを登録する
- Client-side discovery パターン
- クライアントがサービスレジストリからリストを取得し、クライアント自身でバランシングアルゴリズムを使ってサービスインスタンスを選択する
DockerやKubernatesなどのデプロイプラットフォームは、組み込みでサービスがレジストリとディスカバリメカニズムを持っている。 プラットフォームが提供する最大の利点は、プラットフォームを利用する側が意識せずともサービスディスカバリを行ってくれるという点にある。また、サービスにもクライアントにもサービスディスカバリのためのコードが含まれなくなるため、言語やフレームワークに依存せずに利用ができる。
- 3rd party registration パターン
- サービスがレジストリに登録するのではなく、サードパーティであるレジストラが登録処理をする
- サービスのソースコードが影響を受けない。
- また、サービスインスタンスにヘルスチェックをおこない、インスタンスの登録/登録解除を行える
- Server-side discovery パターン
- クライアントでレジストリに問い合わせずに、DNS名をリクエストルーター(ロードバランサー)に送り、ルーターがサービスレジストリに問い合わせし、利用可能なサービスインスタンスにリクエストの転送を行う
- AWS Elastic Load Balancerなどで提供されている
- [https://scrapbox.io/files/60b78ce84b9ae5001cf91206.png]
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
サービスの分割 |
docs |
showa |
|
1 |
オブジェクト指向設計の原則のうちの2つを意識するとよりよいアーキテクチャの設計の指針になる。
- 単一責任の原則
- クラスを書き換える理由は1つでなければならない
- 各サービスでこの原則が貫かれていれば、小さい単一の責務を担うサービスにできる
- 閉鎖性共通の原則
- 1つのパッケージにまとめられるクラス郡は同じ種類の変更に対してともに影響をうけるべきである。
- ビジネスルールが変更されたときの影響が最小限になるように抑える
業務(business capability)による分割のパターン。
業務とは、企業が価値を生成するためにおこなう仕事の種類。業務自体が変更が少なく安定しているため、アーキテクチャ自体も安定しやすいというメリットがある。
- 業務の洗い出し
企業の目的、構造、ビジネスプロセスから洗い出す - 業務からサービスを定義
ここの業務または、業務グループのために1つのサービスを定義する
[ドメイン駆動設計]を用いた分割パターン。
ドメインからサブドメインを洗い出し、サブドメインごとにドメインモデルを定義する。ドメインモデルの範囲を境界づけられたコンテキストと呼ぶ。
個々の境界づけられたコンテキストは、サービスまたは、サービスを束ねるグループとして扱えるゾ。
ドメインモデル:ドメイン内の問題解決に使えるドメインの知識を捉えている
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
同期的なリモープロシージャパターン |
docs |
showa |
|
1 |
クライアントとサーバー間がプロキシインターフェースを介して同期的に(クライアントがレスポンスを期待して)やり取りを行う。プロキシインターフェースが通信のプロトコルをカプセル化する。
通信のプロトコルとして、RESTとgRPCについて取り上げる。
RESTは、ビジネスオブジェクトやそのコレクションを表すリソースを、HTTPメソッドで操作するようにエンドポイントをもつAPI。APIは、インターフェース定義言語で定義しなければならない。
メリット
- curlやPostmanで簡単にAPIを叩くことができる
- リクエスト/レスポンススタイルをサポートしている
- 中間のブローカーが不要でアーキテクチャが単純になる デメリット
- リクエスト/レスポンススタイル以外の通信を利用できない
- クライアントーサーバー間が直接通信しているので、可用性が下がる
- クライアントがサービスインスタンスの位置を知っている必要がある
- (解決策⇛[サービスディスカバリ])
- 1つのリクエストで複数のリソースをフェッチできない
HTTP/2を利用してプロトコルバッファ形式のメッセージをやりとりするAPI。
メリット
- 操作に対して命名できるのでAPIの設計がしやすい
- 大きなメッセージのやりとりでも効率的でコンパクトに通信できる
- 双方向ストリーミングのため、RPI、メッセージの両方のスタイルで通信できる
- 言語に依存しない
デメリット
- JavaScriptクライアントでは扱いづらい
- 古いファイアウォールでは対応していない場合がある
同期的にサービスを呼び出す場合、以下について検討し、障害から守る必要がある。
fault-tolerance-in-a-high-volume-distributed-system - netflix
- レスポンスを待つときはネットワークタイムアウトを指定する。リソースが必ず開放されるようにする。
- クライアントから未応答のリクエストの許容上限を決めておく
- [Circuit breaker パターン]
サービス障害時のエラーの修復としては
- クライアントにエラーを返す
- デフォルト値やキャッシュした値を返却する
- サービスそのものが障害で動作しない可能性もあるため、適切にサービスを
| title | type | weight | lastmod | |
|---|---|---|---|---|
Architecture |
docs |
2000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Action Domain Responder |
docs |
showa |
|
1 |
Action-domain-responder(ADR)は、Webアプリケーションにより適したModel-view-controller(MVC)の改良版としてPaul M. Jonesによって提案されたソフトウェアアーキテクチャパターンです. MVCと最も異なる部分は、1つのパスに対して1つのAction Classであることがあげられる。 コントローラの場合、複数のパスがメソッドによって表現されるが、これによってあるメソッドでは必要でも他のメソッドでは必要のない依存関係などがうまれたり、クラス内の複雑性は変更が加えられるたびにFatになっていく。(そして神クラスへ...) ADRでは、1つのActionでは1つのパスしか表現できないので、こうしたクラスの肥大化を防ぐことができる。 また、responseを返す部分をResponderとして切り分けられているため、より疎結合な実装が可能になる。

| title | type | weight | lastmod | |
|---|---|---|---|---|
Links |
docs |
100000 |
|
- 設計・ソフトウェアアーキテクチャを学べるGitHubリポジトリ 16選
- Awesome Software Architecture
- O'Reilly Japan - ソフトウェアアーキテクチャの基礎
- O'Reilly Japan - ソフトウェアアーキテクチャ・ハードパーツ
- nealford.com • Architectural Katas
- asynkron/protoactor-go: Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin
- Actorモデルのライブラリ
- システムの複雑さはどこから来るのか – Out of the tar pitを読む - Uzabase for Engineers
- モノリスとマイクロサービスを経てモジュラモノリスを導入した実践事例 - Speaker Deck
- モジュラモノリスにおけるトランザクション設計の考え方 / transaction design on modular monolith - Speaker Deck
- How to (and how not to) design REST APIs · stickfigure/blog Wiki
- API仕様ファースト開発:柴田 芳樹 (Yoshiki Shibata):SSブログ
- API 設計ガイド | Cloud APIs | Google Cloud
- 実践Immutable Data Model - 紙箱
-
Updateをなるべく発生させないためには、データを改変できない(つまりCreateしかできない)モデルの方が、長期的に安定した、安全なシステムが作れるはず、という考え方です。
-
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
低レイヤのお勉強 |
docs |
showa |
|
100500 |
Compiler Explorer
Cソースからアセンブリを出力してくれるサイト
.intel_syntax noprefix ;アセンブリの文法指定.x86-64
.globl plus, main ;プログラム全体のグローバルな関数であることを明示
plus:
add rsi, rdi
mov rax, rsi ;関数のリターンは、RAXレジスタに設定
ret
main:
mov rdi, 3
mov rsi, 4
call plus
ret- 関数のリターンは、RAXレジスタに設定する
- 関数の第一引数 RDIレジスタ、第二引数 RSIレジスタに入れる
call: 関数の呼び出し命令- callの次の命令のアドレスをスタックにプッシュ(戻ってくるアドレス)
- callの引数としてアドレスにジャンプ
- 四則演算: 第一引数のレジスタに結果を上書く
add: 足し算sub: 引き算imul: 符号あり掛け算- mul: 乗算。オペランドを1つとる
- mul rdi => rax = rax rdi
idiv: idivは暗黙のうちにRDXとRAXを取って、それを合わせたものを128ビット整数とみなして、それを引数のレジスタの64ビットの値で割り、商をRAXに、余りをRDXにセットする
mov: 第一引数に第二引数をコピーする- code:mov dst [rax]
- raxに入っているアドレスからメモリの値をロードして、dstに値をセットする
- code:mov [dst] src
- dstの値をアドレスとみなして、そのアドレスのメモリにsrcの値をストアする
- ⇒[]でレジスタの値をアドレスとして、メモリの内容にアクセスしてる?
- code:mov dst [rax]
- comp:
「フラグレジスタ」に比較結果をセットする
cmpの実体は、「フラグレジスタ」だけを更新する特殊なsub命令
setxxxで「フラグレジスタ」から8bitレジスタに書き込むsetl: より小さい場合バイトを設定(>,<)setle: より小さいか等しい場合バイトを設定(>=,<=)setne: 等しくない場合バイトを設定(!=)sete: 等しい場合バイトを設定(==)
ret: 呼出し元関数の実行を再開- スタック(RSP)からアドレスをpop
- popしたアドレスにジャンプ
- スタックポインタ: RSPレジスタをスタックポインタとして、RSPレジスタが指すメモリにアクセスできる
poppush
- cqo: 符号拡張。RAXに入っている64ビットの値を128ビットに伸ばしてRDXとRAXにセットする
- ジャンプ: 今いる命令のアドレスから、指定されたアドレスの命令のアドレスに移動することです.
- RAX
- RDI
- RSI
- RSP
- RBP
- 「ベースレジスタ」。関数フレームの開始位置を指すレジスタ。
- ここに入っている値を「ベースポインタ」と呼ぶ。
- ベースポインタを利用することで、RSPにpushされているローカル変数や関数パラメータを、RBPからの相対位置で変数にアクセスできるようにしている。
- What is the purpose of the RBP register in x86_64 assembler? stackoverrun
- AL
- ALはRAXの下位8ビットを指す別名レジスタ。RAXをAL経由で更新するときに上位56ビットは元の値のままになるので、RAX全体を0か1にセットしたい場合、上位56ビットはゼロクリアする必要があります。
スタックマシンは、スタックをデータ保存領域として持っているコンピュータのことです。したがってスタックマシンでは「スタックにプッシュする」と「スタックからポップする」という2つの操作が基本操作になります。プッシュでは、スタックの一番上に新しい要素が積まれます。ポップでは、スタックの一番上から要素が取り除かれます。
スタックマシンにおける演算命令は、スタックトップの要素に作用します。例えばスタックマシンのADD命令は、スタックトップから2つ要素をポップしてきて、それらを加算し、その結果をスタックにプッシュします(x86-64命令との混同を避けるために、仮想スタックマシンの命令はすべて大文字で表記することにします)。別の言い方をすると、ADDは、スタックトップの2つの要素を、それらを足した結果の1つの要素で置き換える命令です。(movzb命令)
;スタックポインタを用いた加算
;ex) 1+2
push 1
push 2
pop rdi;2
pop rax;1
add rax rdi
push rax;3Cでは、変数領域をスタック(RSP)上にもつ。
関数ごとにRSPでリターンアドレスと関数呼び出しで使われるメモリ領域を管理する。このメモリ領域のことを「関数フレーム」や「アクティベーションレコード」と呼ぶ。
| ... | ||
|---|---|---|
| 関数gのリターンアドレス | ||
| ローカル変数 | a | |
| ローカル変数 | b | ←RSP |
ただし、上記ではRSPが変更(push/pop)されるたびに、ローカル変数へのアクセスがRSPからのオフセットで利用できない。そのため、RSPとは別に関数フレームの開始位置を指す「ベースレジスタ」を用意する。
このレジスタの値を「ベースポインタ」と呼ぶ。
| ... | ||
|---|---|---|
| 関数gのリターンアドレス | ||
| 関数gの呼び出し時典のRBP | ←RBP | |
| ローカル変数 | a | RBPからの相対位置でアクセス可能 |
| ローカル変数 | b | ←RSP |
関数fを関数gで呼び出すと
| ... | ||
|---|---|---|
| 関数gのリターンアドレス | ||
| 関数gの呼び出し時典のRBP | ||
| ローカル変数 | a | |
| ローカル変数 | b | |
| 関数fのリターンアドレス | ||
| 関数fの呼び出し時典のRBP | ←RBP(関数gの呼び出し時点のRBPの位置を記録) | |
| ローカル変数 | x | |
| ローカル変数 | y | ←RSP |
この関数呼び出し時のスタックの状態を作るアセンブリは下記のようになる。この定型の命令のことを「プロローグ」と呼ぶ。
push rbp ;今のrbpをスタックにpush
mov rbp, rsp ;rbpにpushしたrbpの位置をrbpに保持
sub rsp, 16 ;必要な分だけ関数フレームを取得(メモリ確保)関数からリターンするときは、RBPを書き戻して、RSPがリターンアドレスを指している状態でret命令を呼ぶ。これを実現する下記のような定型の命令のことを「エピローグ」と呼ぶ。
mov rsp, rbp ;rspをrbpの位置に移動
pop rbp ;rbpを前の値に書き換える
ret ;リターンアドレスの位置に移動| ... | |
|---|---|
| 関数gのリターンアドレス | |
| 関数gの呼び出し時典のRBP | |
| ローカル変数 a | |
| ローカル変数 b | |
| 関数fのリターンアドレス | |
| 関数fの呼び出し時典のRBP | ←RBP |
| ローカル変数 x | |
| ローカル変数 y | ←RSP |
| ... | |
|---|---|
| 関数gのリターンアドレス | |
| 関数gの呼び出し時典のRBP | |
| ローカル変数 a | |
| ローカル変数 b | |
| 関数fのリターンアドレス | |
| 関数fの呼び出し時典のRBP | ←RBP, RSP |
| ... | |
|---|---|
| 関数gのリターンアドレス | |
| 関数gの呼び出し時典のRBP | ←RBP |
| ローカル変数 a | |
| ローカル変数 b | |
| 関数fのリターンアドレス | ←RSP |
| ... | |
|---|---|
| 関数gのリターンアドレス | |
| 関数gの呼び出し時典のRBP | ←RBP |
| ローカル変数 a | |
| ローカル変数 b | ←RSP |
メモリとXMM0系レジスタ間で値を転送する命令では、メモリ上の値が16バイト境界に配置されていることを求める。 コンパイラは、関数呼び出し時のスタックポインタが16バイト整列されていることを前提に命令を発行するため、16バイト整列するように調整する責任がある。
| title | type | weight | lastmod | |
|---|---|---|---|---|
AWS |
docs |
1000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Cloud Formation |
docs |
showa |
|
1 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
DynamoDB |
docs |
showa |
|
1 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
IAM |
docs |
showa |
|
1 |
| title | type | weight | lastmod | |
|---|---|---|---|---|
Links |
docs |
100000 |
|
- Introduction - AWS Lambda - 2023/05/11
- Lambdaのベストプラクティスについて書かれている
- ECSサービスの設計ポイントをざっくりまとめてみる - NRIネットコムBlog - 2023/05/20
- Global AcceleratorとCloudFrontの違いが見えてきたら解るCloudFrontの活用方法 - NRIネットコムBlog - 2023/05/20
- 全AWSエンジニアに捧ぐ、CloudWatch 設計・運用 虎の巻 / CloudWatch design and operation bible - Speaker Deck - 2023/05/31
- 半年前に勉強会で話したAWS VPCルーティングについて改めて整理してみた - NRIネットコムBlog - 2023/05/31
- Let’s Architect! Designing architectures for multi-tenancy | AWS Architecture Blog - 2023/06/20
- AWS Shield AdvancedのTips - Qiita - 2023/06/28
- AWS Sketch - 2023/07/21
- 各サービスについてのスケッチ
- 【15分で確認】AWSでクラウド構築する時に覚えておきたい設計原則・アーキテクチャ3選 - Qiita - 2023/09/17
- AWSのネットワーク設計入門
- 個人的AWS ログ管理のベースライン - mazyu36の日記
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
S3 |
docs |
showa |
|
1 |
| title | type | weight | lastmod | |
|---|---|---|---|---|
Bash |
docs |
100600 |
|
- シェルスクリプトの ( ) と の違いを歴史的に解説 〜 言語設計者の気持ちになって理解しよう - Qiita
- シェルスクリプト(bash)のif文やwhile文で使う演算子について - Qiita
- 変数内の文字列置換
- shellの引数
- 値が配列に存在するかチェック
- find
- sed
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
C |
docs |
showa |
|
100100 |
buf1 と buf2 を先頭から n バイト分比較します。比較はunsigned char として行われます。memcmp() は buf1 と buf2 をメモリブロックとして扱うため、途中に空文字('\0')を含んでいても比較を続けます。
#include <string.h>
int memcmp(const void *buf1, const void*buf2,size_t n); int main(void){
int hoge = 1;
switch(hoge) {
case 1:
printf("1やで");
case 2:
printf("2やで");
default:
printf("君だれ?");
}
}関数は呼び出す前にコンパイラに情報を渡すために、プロトタイプ宣言する必要がある。
gccなどでは、プロトタイプ宣言がなくてもコンパイルできるが、基本はエラーとなる。
また、main関数は、プロトタイプ宣言する必要のない特別な関数。
int number(void); # プロトタイプ宣言
int main(void){
int i = 0;
for(;;) {
printf("%d回目\n",number());
if(i>5){
break;
}
i+=1;
}
}
int number(void){
return 5;
}char型を利用する。ただし、255種(8bit)しか扱えないため全角文字は扱えない。 文字の比較とかの標準ライブラリ:[ctype.h https://www.programiz.com/c-programming/library-function/ctype.h]
C言語では、文字列を配。または文字リテラルで表す。
文字列の最後(EOS)は\0で表す。
int main(void){
char str[6] = {'A', 'B', '\0'};
printf("%s\n", str);
// ""で囲めば宣言できるが、初期化の時にしかつかえない
char str[] = "hoge";
printf("%s\n", hoge);
char input[32];
scanf("%s", input);
printf("%s\n",input);
printf("%ld\n", strlen(input));
return 0;
}int main(void){
int i;
printf("%p\n", &i);
int arr[4];
printf("array %p\n", arr);
for(i = 0; i < 4; i++){
printf("%d %p\n", i, &arr[i]);
}
intp1;
// nilになる
printf("pointer %p\n", p1);
// 0を代入してもnullポインタになる
p1 = 0;
printf("pointer %p\n", p1);
intp2;
i = 3;
p2 = &i;
printf("p2: %p i: %p\n", p2, &i);
i = 4;
printf("p2: %d i: %d\n", *p2, i);
*p2 = 6;
printf("p2: %d i: %d\n", *p2, i);
return 0;
} #include <stdio.h>
void hoge(int a[]);
int main(void){
int input[5] = {1, 2, 3, 4, 5};
printf("before: %d\n", input[2]);
hoge(input);
printf("after: %d\n", input[2]);
return 0;
}
void hoge(int a[]){
a[2] = 100;
}[]はあくまでも配列の先頭のポインタからの演算子。 配列は、先頭から連続したアドレスで作られるので、[]の演算子で値がとれる。
多くの人が、配列とポインタを勘違いしてしまうようです。 配列とは、多数の変数を順番つけでまとめて扱う方法であり、 ポインタとは、変数のショートカットを作る方法です。
それなのに、似たような使い方が出来るのは配列の設計と関係あります。 C言語では、配列を実現する手段として、ポインタを利用しているからです。 従って、ポインタ変数では、配列と同等のことが出来てしまいます。
そのため、ポインタと配列は混同しやすいのですが、 配列はあくまでも多数の変数の先頭を示す固定された変数であり、 ポインタ変数は、好きな変数のアドレスを代入して、 好きなメモリ領域を使うことが出来る可変的な変数です。
// studentのことを「構造体タグ名」と呼ぶ
// 厳密には型名じゃない
struct student_tag {
int year; /学年 */
int clas; /クラス */
int number; /出席番号 */
char name[64]; /名前 */
double stature; /身長 */
double weight; /体重 */
};
// 構造体型
typedef struct student_tag student;
void student_print(student *data);
/*
一番簡潔な書き方
typedef struct {
int year;
int clas;
int number;
char name[64];
double stature;
double weight;
} student;
*/
int main(void){
// typedef 指定指定ない場合、structを頭につける必要がある
// struct student_tag data
student data;
data.year = 1;
student_print(&data);
strcpy(data.name,"MARIO");
retrun 0;
}
void student_print(student *data){
printf("%d\n", (*data).year);
// ポインタの構造体変数は、「->」でアクセス可能
printf("%d\n", data->year);
(*data).year = 100;
return;
}-
構造体の中の配列
構造体の中に配列が含まれている場合は、配列の中身もコピーされて渡されます。 従って、中身を変更しても、呼び出し元の変数には影響しません。 配列をコピーして渡したい時(例えば、リバーシのプログラムで盤面情報を渡したい等)には、 構造体にしてしまうのが一番簡単です。 従って、構造体の配列を渡すのはとても遅いので、場合によってはやめたほうがいいこともあります
#include <stdio.h>
#define EXCISETAX 0.03 /ここで定数を宣言 */
int main(void)
{
int price;
printf("本体価格:");
scanf("%d",&price);
price = (int)((1 EXCISETAX) price); /定数使用 */
printf("税込価格:%d\n",price);
return 0;
}constよりはdefineのが一般的に使われる。 関数内定数や、関数の引数の型として使われることが多い。
#include <stdio.h>
int main(void)
{
const double EXCISETAX = 0.05;
int price;
printf("本体価格:");
scanf("%d",&price);
price = (int)((1 EXCISETAX) price);
printf("税込価格:%d\n",price);
return 0;
} enum {
ENUM_0,
ENUM_1,
ENUM_5 = 5, // 整数値を直接指定できる
ENUM_6, // 6
ENUM_7,
ENUM_9 = 9,
};#define疑似命令による定数は、単なる置き換えによって実現されている。
#include <stdio.h>
// 関数の呼び出しを置き換えることができる
#define PRINT_TEMP printf("temp = %d\n",temp)
int main(void)
{
int temp = 100;
PRINT_TEMP;
return 0;
}この機能によってマクロという簡単な関数をつくることができる。多用は非推奨。
#include <stdio.h>
// ()を使うと引数のように置き換えられる
#define PRINTM(X) printf("%d\n",X)
int main(void)
{
int a1 = 100,a2 = 50;
PRINTM(a1);
PRINTM(a2);
return 0;
}必要なメモリサイズを指定するとそのサイズを確保する。 確保した後、先頭のvoid型のポインタを返す。
mallocで確保されたメモリの解放処理。 mallocで確保されたメモリはプログラム終了まで確保されるので、メモリリークにならないように必ず開放する。
拡張元の配列の要素数を拡大する。 reallocによって、新たにメモリの領域を確保し、そこに拡張元の配列のコピーを行う。
int main(void)
{
int *heap;
heap = (int *)malloc(sizeof(int) 10);
// これだと元のheapのアドレスで確保したメモリがメモリリークしてるので、
// 別変数に突っ込んで解放してあげる必要ある。
heap = (int *)realloc(heap,sizeof(int) 100);
free(heap);
return 0;
}- [メモリの動的な確保と解放 https://kaworu.jpn.org/c/%E3%83%A1%E3%83%A2%E3%83%AA%E3%81%AE%E5%8B%95%E7%9A%84%E3%81%AA%E7%A2%BA%E4%BF%9D%E3%81%A8%E8%A7%A3%E6%94%BE]
宣言だけを行い定義は行わない宣言方法。ヘッダーファイル内で利用する。 宣言を行った変数の定義をどこか1つのソースファイルの中で普通の宣言を行って実体を作成して利用する。 extern宣言を使うと、異なるソースファイルで変数を共有することが出来る。
extern int Number; #include "hoge.h"
int Number;
int sum(int x) {
Number += x;
return Number;
}(あんまりC言語関係ない)
キャリッジリターン(\r)を使用すると、行の先頭に移動する制御になる。
コンソールの出力は上書きになるため、1行の範囲なら出力内容の更新が可能。
.ccファイル中に、ファイル外から参照される必要がない定義を行うときは、それらを無名の名前空間内で宣言するか、staticに宣言します。 これらの宣言を.hにおいてはいけません。
- Kilo Github
- 1000行でできたC言語製のCUIテキストエディタ
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
ChatGPT |
docs |
showa |
|
100200 |
プロンプトエンジニアリングで可能な例やアプリケーションをさらに多く取り上げるにつれて、プロンプトを構成する特定の要素があることに気付くでしょう。プロンプトには、以下のコンポーネントが含まれます。
- 指示 - モデルに実行してほしい特定のタスクや指示
- 「書く」「分類する」「要約する」「翻訳する」「並べ替える」など、モデルに目的を達成させるよう指示するコマンドを使って、さまざまなシンプルなタスクに効果的なプロンプトを設計することができます。
- 指示と文脈を区切るために、「###」のような明確なセパレータを使用することもお勧めされています。
- プロンプトが詳細で説明的であればあるほど、結果は良くなります。
- プロンプトを設計する際には、具体的で直接的であることが重要です。
- やらないことを言うのではなく、代わりにやることを言う。
- 文脈 - 外部情報や追加の文脈を含めることで、モデルがより良い回答に導かれる
- 入力データ - 応答を見つけたい入力や質問
- 出力指標 - 出力のタイプや形式を示す。
より良い結果を得るためのプロンプトの改善させる概念
- Zero-Shot Prompting
- 大量に訓練され調整されたLLMは、命令だけ(ゼロショット)でタスクを実行できる
- Few-Shot Prompting
- より複雑なタスクではゼロショットでは不十分。プロンプトの中でデモンストレーション(例を示す)をおこなうことでモデルの性能を向上させることができる。数発のプロンプトで文脈を使って学習させることができる。
- デモンストレーションで示す入力と結果の分布はどちらも重要
- 一様な分布じゃなく、ランダムな分布でもない場合より有効
- 本当の分布に合わせた分布でデモンストレーションすることでさらなる学習の助けになる
- 推論問題に対してはfew-shotでは不十分。
- より複雑なタスクではゼロショットでは不十分。プロンプトの中でデモンストレーション(例を示す)をおこなうことでモデルの性能を向上させることができる。数発のプロンプトで文脈を使って学習させることができる。
- Chain-of-Thought Prompting(CoT)
dair-ai/Prompt-Engineering-Guide: Guides, papers, lecture, and resources for prompt engineeringの抜粋
- ChatGPTは馬鹿じゃない! 真の実力を解放するプロンプトエンジニアリングの最前線
- Prompt Engineering: The Ultimate Guide 2023 (GPT-3 & ChatGPT)
- LLMがなぜ大事なのか?経営者の視点で考える波の待ち受け方|福島良典 | LayerX
- 大規模言語モデル(LLM)の快進撃
- 自然言語処理AIとの接近 – りん研究室
- GPTの仕組みと限界についての考察(1) - conceptualization
- 深層学習界の大前提Transformerの論文解説! - Qiita
- 数式を使わないTransformerの解説(前編) - conceptualization
- Transformer モデルとは? | NVIDIA
- 【完全保存版】GPT を特定の目的に特化させて扱う (Fine-tuning, Prompt, Index, etc.) - Qiita
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
DB |
docs |
showa |
|
3000 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
CAP定理 |
docs |
showa |
|
1 |
ノード間のデータ複製において、同時に次の3つの保証を提供することはできない。
すべてのデータ読み込みにおいて、最新の書き込みデータもしくはエラーのどちらかを受け取る。
ノード障害により生存ノードの機能性は損なわれない。つまり、ダウンしていないノードが常に応答を返す。単一障害点が存在しないことが必要。
システムは任意の通信障害などによるメッセージ損失に対し、継続して動作を行う。通信可能なサーバーが複数のグループに分断されるケース(ネットワーク分断)を指し、1つのハブに全てのサーバーがつながっている場合は、これは発生しない。ただし、そのようなネットワーク設計は単一障害点をもつことになり、可用性が成立しない。RDBではそもそもデータベースを分割しないので、このような障害とは無縁である。
この定理によると、分散システムはこの3つの保証のうち、同時に2つの保証を満たすことはできるが、同時に全てを満たすことはできない。単一障害点があれば、ネットワーク分断が発生した際にシステムがバラバラに分裂しても、そこを基準に一貫した応答ができる(分断耐性+一貫性)が、可用性が成立しなくなる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
MySQL |
docs |
showa |
|
1 |
確認
SHOW COLUMNS FROM v_balance;レコード更新のたびに反映
updated[/ at timestamp NOT NULL DEFAULT CURRENT]TIMESTAMP ON UPDATE CURRENT_TIMESTAMPCreate
CREATE OR REPLACE VIEW
[ビュー名]
(
[カラム]
)
AS
SELECT
[カラム]
FROM
[テーブル];MySQL 5.7以前はFrom句にサブクエリを含めることができない
Create
CREATE TRIGGER [トリガー名] [BEFORE|AFTER] [INSERT|UPDATE|DELETE] ON [テーブル]
FOR EACH ROW
BEGIN
...
END;MySQL 5.7以前は2つ以上の処理を含めることができない
確認
SHOW TRIGGERS WHERE `Trigger`='[テーブル名]';Create
CREATE PROCEDURE [プロシージャ名]([引数:in/戻り値:out])
BEGIN
...
END;確認
SHOW PROCEDURE STATUS WHERE Name='[テーブル名]';DDLの動的実行
// sample
SET @ddl = 'ALTER TABLE hogehoge ADD COLUMN hogen int);';
PREPARE ddl_stmt FROM @ddl;
EXECUTE ddl_stmt;
DEALLOCATE PREPARE ddl_stmt;Alter
ALTER TABLE [テーブル名]
PARTITION BY RANGE ([カラム名])
(
PARTITION [パーティション名] VALUES LESS THAN 10000,
PARTITION pmax VALUES LESS THAN MAXVALUE
)確認
SELECT
TABLE_SCHEMA,
TABLE_NAME,
PARTITION_NAME,
PARTITION_METHOD,
PARTITION_EXPRESSION,
PARTITION_DESCRIPTION
FROM
INFORMATION_SCHEMA.PARTITIONS
WHERE
TABLE_NAME = '[テーブル名]';件数とスレッドIDの確認
mysql> SHOW ENGINE INNODB STATUS\Gプロセスの確認
mysql> show processlist;
mysql> KILL {数字};| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
分離性 |
docs |
showa |
|
1 |
同時に実行しても、それぞれのトランザクションを重なりなく順番に実行した場合と同じ結果になることを直列可能(serializable)であると呼びます。
分離性は、この直列可能性を保証するものです。
参考
| title | type | weight |
|---|---|---|
Docker |
docs |
100700 |
Linuxディストリビューションやカーネルのバージョンが違っても動作する理由はいくつかあります。まず、LSB(LinuxStandardBase)はソースコードをコンパイルした時点で、互換性のあるマシンコードを生成するよう、ISO規格として標準化されています。また、LinuxABI(ApplicationBinaryInterface)には、Linuxカーネルのバージョンが上がっても、ユーザー空間で動作するバイナリ(マシンコード)レベルの互換性を維持することが定められています
- ネームスペース(Namespace)
ネームスペースはLinuxのカーネル技術であり、コンテナが1つの独立したサーバーのように振る舞うために使用されます。 - コントロールグループ(cgroup)
cgroupはプロセスに対して、CPU時間やメモリ使用量など、資源の監視と制限を設定することができます
コンテナランタイムの標準仕様「RuntimeSpecificationv1.0」と、コンテナイメージフォーマットの標準仕様「FormatSpecificationv1.0」から成ります。このOCIの定めた標準仕様にしたがいDocker社が実装したのが、コンテナランタイムのrunCです。一方で、CoreOSのコンテナランタイムrktについても、ネイティブで標準に準拠するための作業が進んでいます。
高良真穂.15Stepで習得Dockerから入るKubernetes(Kindleの位置No.909).株式会社リックテレコム.Kindle版.
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Google Cloud |
docs |
showa |
|
4000 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Cloud Run |
docs |
showa |
|
1 |
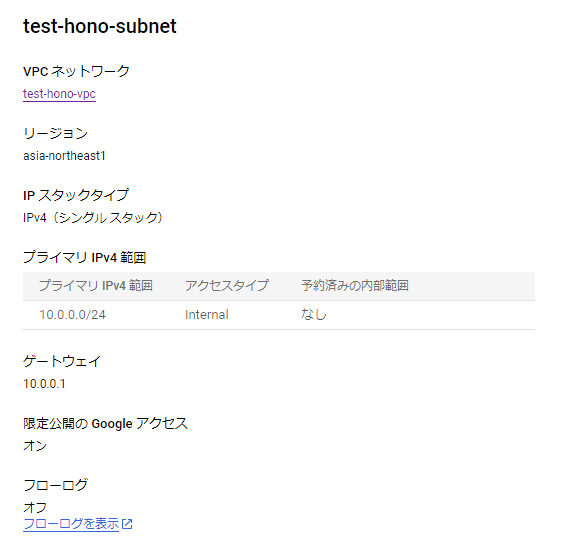
サーバーレス環境でサーバーレスVPCアクセスコネクタ経由で内部DNSと内部IPアドレスを使用してVPCネットワークにリクエストの送信とレスポンスの受信ができる。
反対に他の内部トラフィックをサーバーレス環境に送信する方法については、限定公開のGoogleアクセスを利用する必要がある。
コネクタの IP アドレス範囲を設定するには、次の 2 つの方法がある。
- サブネットを使用するリソースがない場合は、既存の /28 サブネットを指定できる
- 未使用の /28 CIDR 範囲を指定できる
サーバーレス VPC アクセス コネクタは、コネクタ インスタンスで構成されており、マシンタイプが大きいほどスループットが高くなる。
ダイレクトVPCを利用するとサーバーレスVPCアクセスコネクタを使用せずにCloud RunがVPCネットワークに直接トラフィックを送信できる。
また、インスタンスを使用しないためアクセス自体に必要な費用がネットワークの費用だけになる。
ダイレクトVPCで利用すると各インスタンスにサブネット内のIPアドレスが割り当てられるため、サブネット内には十分なIPアドレスが使用可能な状態である必要がある。また、トラフィックが急増したときに備えて事前にIPが割り振られるため、存在するインスタンス数よりも多くなることも留意する。
そのほか制限事項がいくつか存在するため、ドキュメントを参照。
ダイレクトVPCを有効にするとVPC内にCloud Runインスタンスが立ち上がるようになり、Cloud RunからVPC内部のサービスへのリクエストは許可される。一方でVPCのほかのサービスからのCloud Runのインスタンスへのアクセスはできない。
ダイレクトVPCを利用しても、通常通りCloud RunのエンドポイントへのリクエストはCloud Runにルーティングされる。(ここの制御は上り(内向き)の制御でする。)
- VPC ネットワークによるダイレクト VPC 下り(外向き) | Cloud Run のドキュメント | Google Cloud
- Cloud Run でダイレクト VPC 下り(外向き)の提供を開始: パフォーマンス向上と費用削減を実現 | Google Cloud 公式ブログ
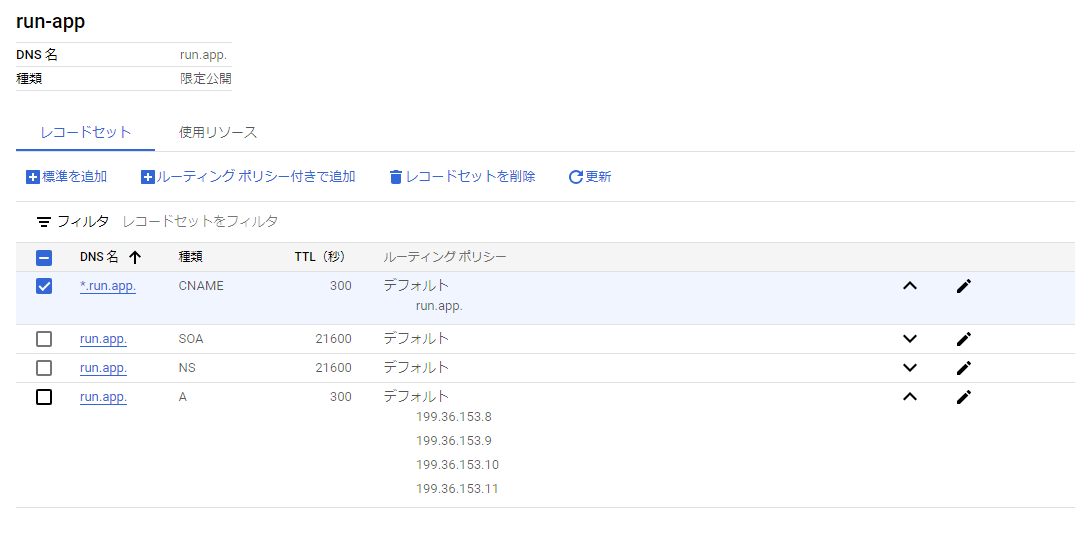
デフォルトの設定では、Cloud Runに設定されたドメイン(run.appまたはカスタムドメイン)にインターネット経由でアクセスができる。
上りの設定でこれらのアクセスの制限をかけることができる。
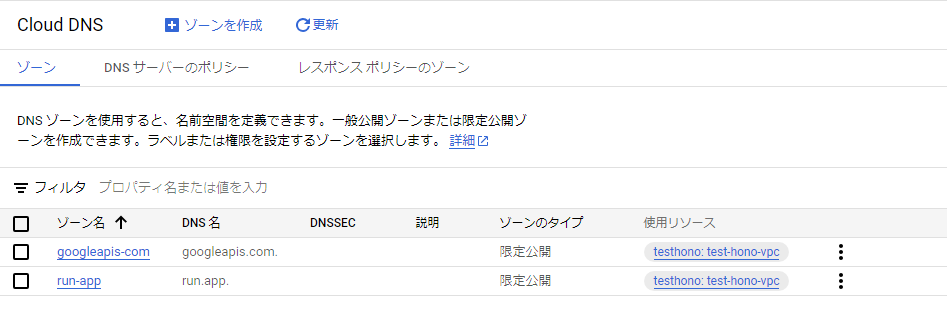
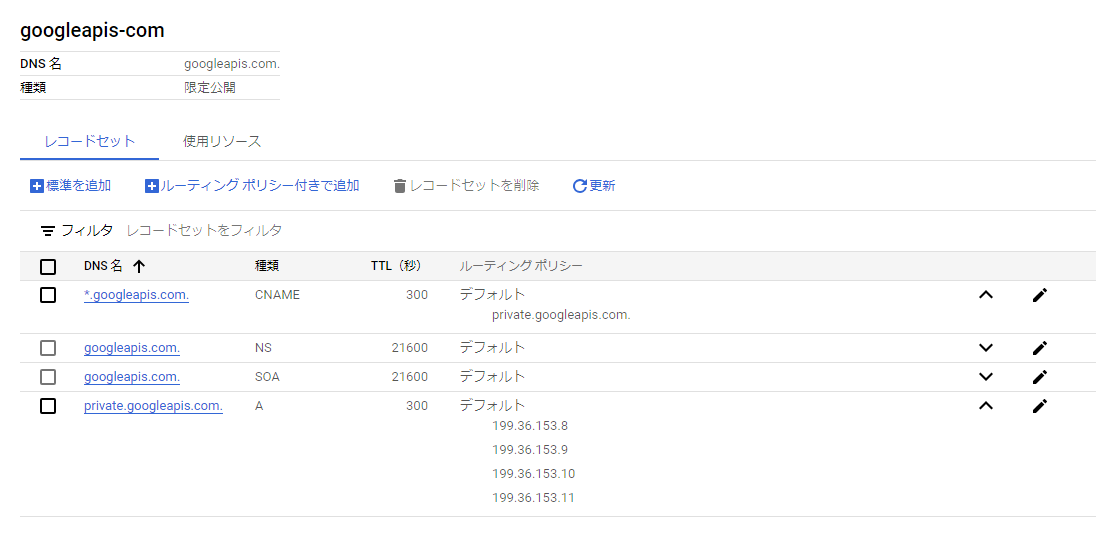
-
内部
以下のソースからのリクエストを許可する。ron.appにアクセスする場合でもGoogleのネットワーク内に閉じる。ほかのソースからのリクエストは到達できない。
Cloud Runなどのサーバレスサービスからのリクエストを内部リクエストとみなすためにはVPCネットワークを経由する必要がある。
→ 限定公開の Google アクセスを構成する | VPC | Google Cloud- 内部アプリケーション ロードバランサ
- VPC Service Controlsの境界内
- Cloud Runと同じプロジェクトまたはVPC Service Controlsの境界内にあるVPCネットワーク
- 共有VPC
- 特定のGoogle Cloudのプロダクト
-
すべて
インターネットから直接run.appへ送信されるリクエストを許可する
内部に設定されたCloud Runにアクセスするには、前述より内部のリクエストにする必要がある。
Cloud Run → Cloud Runにアクセスする場合について考える。
- 内部かつダイレクトVPCのCloud Runにリクエスト
- サーバーレスVPCアクセス経由
この場合、すべてのトラフィックをVPCにルーティングすると内部のリクエストとしてCloud Runに送信される。
一方でプライベートIPのみの場合、Cloud Runにインターネット経由でアクセスするためアクセスできない。 - ダイレクトVPC経由
サーバーレスVPCアクセスでは有効だったすべてのトラフィックを VPC にルーティングに設定してもアクセスができない。
これはダイレクトVPC内にCloud Runを配置するとVPCのほかのサービスからのCloud Runのインスタンスへのアクセスはできないという制約があるためだと考えられる。
そのためダイレクトVPCに設定する場合、必ず限定公開のGoogeleアクセスの設定が必要になる。設定するとちゃんとできる。
プライベート IP へのリクエストのみを VPC にルーティングするの設定のままルーティングさせたい場合は、ドキュメントに記載されたPVCまたは内部ロードバランサーを設定しDNSでそっちを見るようにするか、限定公開のGoogleアクセスを有効にしてDNSを設定するの2通りにのどちらかを選択する必要がある。
-
限定公開のGoogeleアクセスとCloud DNSを利用した方法
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Firebase Emulator on Docker |
docs |
showa |
|
1 |
Docker上でFirebase Emulatorを動かす。備忘録。 ほぼ他所様のブログのまんま。権限の解決だけ追加でやってる。
Firebase Emulatorを動かすDockerfileの内容は以下の通り。
cli-tableの不具合によって、firebase-toolsのv9.22.0で動作しなくなっていたため、暫定対処としてgithubからcloneして、cli-tableのバージョンをバグのないバージョンに固定している。が、11/18にマージされていて解決している。
Firebase Emulator throws npm cli-table error only when importing firestore data · Issue #3909 · firebase/firebase-tools
FROM node:16-alpine
RUN apk add --no-cache openjdk11-jre-headless \
&& apk add shadow
# && apk add shadow \
# && apk add git
RUN npm i -g firebase-tools
#11/18に不具合対応がマージされてv9.23.0で解決
#cli-tableにバグがあり、暫定対応のために
#firebase-toolsのcli-tableのバージョンを固定してbuildしている
#RUN mkdir tools && cd tools \
# && git clone https://github.com/firebase/firebase-tools.git -b v9.22.0 \
# && cd firebase-tools \
# && npm install -g npm \
# && npm config set save-exact true \
# && npm install cli-table@0.3.6 \
# && npm install \
# && npm run build \
# && npm link
RUN groupmod -g 1000 node && usermod -u 1000 -g 1000 node
USER node
以下Docker Composeのファイル。
ホスト側のfirebaseのキャッシュや設定を直接読み取って起動している。
ただ、ホスト側でemulatorを起動していると、権限が異なるためPermission deniedになる。
これを回避するために、ホスト側と同じグループのユーザーをDockerfileで設定している。
version: '3'
services:
firebase:
build:
context: .
dockerfile: firebase/Dockerfile
tty: true
restart: always
command: firebase emulators:start --only auth,firestore --export-on-exit ./firebase/.firebase --import ./firebase/.firebase
ports:
- "9000:9000"
- "8080:8080"
- "9099:9099"
volumes:
- .:/workspace
- ~/.cache/firebase:/root/.cache/firebase
- ~/.config/configstore:/root/.config/configstore
working_dir: /workspace
権限周りなんもわからん
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Link |
docs |
showa |
|
10000 |
| title | type | lastmod | waight | |
|---|---|---|---|---|
GitHub Actions |
docs |
|
1 |
continue-on-error
trueが設定されているステップでエラーになっても後続のステップの動作が継続される。
変更があるときだけコミット [GitHub Actions]
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Command |
docs |
showa |
|
1 |
go.modファイルにあるモジュールの依存関係を更新し、パッケージをビルドしてインストールする。 モジュールとバージョンが解決できたら、require命令を追加、変更、削除する。 go.modのrequireディレクティブの管理に重点を置いている。
go get
# a specific module
# 暗黙的に@upgrade queryが使われる
# go get -d golang.org/x/net@upgrade
go get -d golang.org/x/net
# all modules
go get -d -u ./...
go get -d -u all
# a specific version
go get -d golang.org/x/text@v0.3.2
# a specific branch name or revision
go get -d golang.org/x/text@master
# @none suffixでモジュールの削除ができる
go get golang.org/x/text@none-d- ビルドやインストールを行わないように指示する
-dなしでgo getを使うことは非推奨です。- Go1.18からデフォルトで有効になる
-u- パッケージからインポートされたパッケージを提供するモジュールをアップグレードするように指示する
-u=patch- 最新のパッチバージョンにアップグレードする
-t- 指定されたパッケージのテストを動作させるために必要なモジュールも含めるように指示する
-insecurehttpのような安全でないスキーマから取得することを許可する- 非推奨
パッケージをビルドしてインストールする。実行ファイルは$GOBINで指定されたディレクトリにインストールされる。$GOROOTにある実行可能ファイルは$GOBINではなく、$GOROOT/binまたは$GOTOOLDIRにインストールされる。
Go1.16以降、引数にバージョンのさフィクスがある場合、モジュールを考慮したモードでパッケージをビルドする。このとき、カレントディレクトリや親のディレクトリにgo.modがある場合、go.modを無視する。
go install
# go install [build flags] [packages]mフラグでモジュールをリストアップする。
go list -m
# go list -m [-u] [-retracted] [-versions] [list flags] [modules]
go list -m all
go list -m -versions example.com/m
go list -m -json example.com/m@latest-f- フラグでフォーマットテンプレートを適用する。
-u- 利用可の名アップグレードに関する情報を追加する
-versions- そのモジュールのすべての既知のバージョンをセマンティックバージョニングに従って順番にリストアップする
retractedフラグが指定されない場合、撤回されたバージョンは一覧から省かれます
指定されたモジュールをモジュールキャッシュにダウンロードします。
引数なしの場合、メインモジュールのすべての依存関係を適用される。
goコマンドは必要に応じて自動的にモジュールをダウンロードします。モジュールキャッシュの事前ロードやプロキシが提供されるデータのロードに有用。
go mod download
# go mod download [-json] [-x] [modules]
go mod download
go mod download golang.org/x/mod@v0.2.0-json
ダウンロードされた各モジュールについてのJSONオブジェクトを標準出力に出力する-x
ダウンロードが実行するコマンドを標準エラーに出力する
go.modファイルの編集や書式設定のためのインターフェース。
go mod edit
# go mod edit [editing flags] [-fmt|-print|-json] [go.mod]
go mod edit -replace example.com/a@v1.0.0=./a
go mod edit -json-
-modulego.modファイルのモジュールの行を変更する -
-go=version動作に期待するGoのバージョンをセット -
-require=path@version与えられたモジュールをrequireディレクティブに追加・削除- 記載の上書きを行うだけなので、必要な変更をおこなう
go getを利用すべき
- 記載の上書きを行うだけなので、必要な変更をおこなう
-
exclude=path@versionexcludeディレクティブに追加・削除をおこなう -
-replace=old=new与えられたペアのreplaceディレクティブに追加する -
-dropreplace=old与えられたモジュールパスのreplaceディレクティブをドロップする -
retract=versiondropretract=versionretractディレクティブに追加・削除をおこなう。ただしコメントは記載できない -
出力方法の操作
-fmt他の変更を加えずにgo.modファイルの再フォーマットをおこなう。ほかのフラグが指定されていない場合にだけ利用できる-printgo.modへの書き込みをする代わりに標準出力する-jsongo.modへの書き込みをする代わりにjson形式で標準出力する
replace適用後のrequireディレクティブのテキスト形式を表示する。
各行はモジュールのバージョンと依存関係をもつグラフのエッジを表現する。
go mod graph
# go mod raph [-go=version]カレントディレクトリに新しいgo.modファイルを初期化して書き込む。
vendoringツールの設定ファイルが存在する場合、その設定ファイルからモジュールディレクティブをインポートする。
go mod init
# go mod init [module-path]| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Generics |
docs |
showa |
|
1 |
関数のパラメータはgo1.17以前ではパラメータの型によって制限された値の集合の範囲にあった。go1.18でジェネリクスが導入され、関数や型は型パラメータをもつことができるようになった。型パラメータによって、関数のパラメータや型が満たすべき型の制約(性質)を定義できるようになった。
型パラメータはインターフェース型で型のセットを定義できる。ジェネリクスの導入によってインターフェース型はメソッドの集合という定義から型の集合を定義するように仕様が変更された。この変更によって以前はメソッドによって間接的に型を制限していたが、明示的に型の集合を定義できるようになった。
go1.18より前と異なり、インターフェース型を実装するというのはインターフェース型でない型Tの場合、満たすべきインターフェース型が定義する型集合の要素であることが必要である。型Tがインターフェース型である場合、満たすべきインターフェース型が定義する型集合の部分集合であれば実装している。
| 集合 | 型 | 説明 |
|---|---|---|
| 任意の型 | interface { AnyType } | 任意の型の集合 |
| 型の和集合 | interface { int | string } | 複数の型の和集合 型制約としてしか利用できない メソッドをもつインターフェース型では利用できない |
| 基底型 | interface { ~int64 | ~float64 } | 基底型を満たす型の集合 |
基本的な型制約はconstraintsパッケージで提供される。
型制約は型パラメータが許容する型を指定するものだけでなく、型パラメータが可能な操作を定義します。メソッドセットで定義された関数や+や*のような算術演算やビット演算なども型パラメータによって許可される。
演算とは異なり、等式など比較が可能かどうかの型制約はcomparableの型集合によって定義される。
ただし、comparableによる型集合と言語仕様の型の集合(spec-comparable)は同等ではない。anyなどのインターフェースで実際の値がcomparableでない場合、比較時にruntime panicが発生します。comparableには比較時にパニックをおこさないことを保証している型だけが含まれます。このような型をstrictly comparableと呼ぶ。
go1.20からstrictly comparableでなかったany型もcomparableとして扱えるようにcomparableはインターフェースの実装(implement comparable)と型引数を型パラメータにわたすときの制約充足(satisfy comparable)を区別するようになった。つまり、implement comparableがstrictly comparableを満たし、satisfy comparableがspec-comparableを満たすようになります。
以下の例を考える。
func f[T comparable](x, y T) {
if x == y { // (4)
fmt.Println("Same!!!")
}
}
func g[P any]() {
_ = f[int] // (1)
_ = f[P] // (2)
_ = f[any] // (3)
}3番目のケースではany型は空のインターフェースなのでcomparableを満たす(satisfy comparable)。ただし、any型はcomparableを実装しないので、comparableでない値を引数に渡した場合、(4)でruntime panicが発生します。これはimplement comparableと区別されたことで厳密な型安全性をもたなくなったためである。
2番めのケースではP型はany型で制約されたパラメータなので、すべてのパラメータがcomparableを満たさないので、comparableを満たさない。
型推論に成功したら、インスタンス化がおこなわれる。インスタンス化は型パラメータに実際に型推論された型パラメータを代入した型がインスタンス化される。そのため、型に定義されたメソッドは型のインスタンスが生成された時点で確定するため、個別のメソッドがジェネリクスによる型推論によるインスタンス化をおこなうことはできない。
以上が自分の理解。
[Go言語のジェネリクス入門(1) https://zenn.dev/nobishii/articles/type_param_intro] [Go言語のジェネリクス入門(2) インスタンス化と型推論 https://zenn.dev/nobishii/articles/type_param_intro_2] [Go言語のBasic Interfaceはcomparableを満たすようになる(でも実装するようにはならない) https://zenn.dev/nobishii/articles/basic-interface-is-comparable] [All your comparable types - The Go Programming Language https://go.dev/blog/comparable] [Core Types | The Go Programming Language Specification - The Go Programming Language https://go.dev/ref/spec#Core_types]
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Go Genericsで実装するYコンビネータ |
docs |
showa |
|
1 |
元はこれ
実装の自己理解のためのメモ
https://go.dev/play/p/15_CYMMp4Pk
| title | type | weight | lastmod | |
|---|---|---|---|---|
Links |
docs |
100000 |
|
- (26) Internals of Maps in Golang - YouTube
builtinのmapのデータ構造に関する説明
- Workiva/go-datastructures: A collection of useful, performant, and threadsafe Go datastructures.
Goでつくられたデータ構造のリポジトリ - Finding The Best Go Project Structure — Part 1 | by Aviv Carmi | May, 2023 | ITNEXT
- Goのパッケージ構成について
- Organizing a Go module - The Go Programming Language
- ついにディレクトリ構成の公式発表
- レイヤードアーキテクチャとかクリーンアーキテクチャとか
- Home · golang/go Wiki
- Effective Go - The Go Programming Language
- Go by Example
- avelino/awesome-go: A curated list of awesome Go frameworks, libraries and software
- pion/example-webrtc-applications: Examples of WebRTC applications that are large, or use 3rd party libraries
- SimonWaldherr/golang-examples: Go(lang) examples - (explain the basics of #golang)
- Common Anti-Patterns in Go Web Applications
- Implementing Go stream API. What is Stream Processing | by Kevin Wan | Dev Genius
- Behind the Scenes of Go Scheduler - DEV Community
- What is the zero value, and why is it useful? | Dave Cheney
- A complete guide to working with Cookies in Go – Alex Edwards
- 100 Go Mistakes
- start fast: booting go programs quickly with
inittraceandnonblocking[T]- 起動時間の高速化をはかる記事
- Handling network bursts with channels in Golang :: Yoshiyuki Kurauchi — A telecom / networking / security enthusiast.
- Concurrent HTTP Requests in Golang: Best Practices and Techniques | by Rafet Topcu | Insider Engineering | Jan, 2024 | Medium
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
lru |
docs |
showa |
|
1 |
かんたんにじっそうした。連結リストとハッシュマップの組み合わせ。追加で取得時に生存期間チェックして超過してたらキャッシュから消してる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Modules |
docs |
showa |
|
1 |
モジュールは、リリース、バージョン管理や配布されるパッケージの集合。
モジュールパスによって識別され、Moduleの依存関係の情報とともにgo.modで宣言される。
go.modファイルを含むディレクトリがモジュールのルートディレクトリとなります。
モジュール内の各パッケージは同じディレクトリにあるソースファイルをまとめてコンパイルしたもの
- パッケージのパスはモジュールのパスにパッケージを含むモジュールルートからの相対パス。
- リポジトリのルートパスは、バージョン管理リポジトリのルートディレクトリに対応する
- パス構成
- リポジトリのルートパス/ディレクトリ/メジャーバージョンサフィックス
- メジャーバージョンサフィックス
- メジャーバージョン2以上の場合つける
- 必ずしもサブディレクトリの名前の一部である必要はない
- メジャーバージョンサフィックス
- リポジトリのルートパス/ディレクトリ/メジャーバージョンサフィックス
セマンティックバージョンで管理 v{メジャー}.{マイナー}.{パッチ}
また、オプションで以下の2つをつけられる
- ハイフンで始まるプレリリース文字列
- プラスで始まるビルドメタタグ文字列
v1.2.3-pre
v1.2.3+meta
v1.2.3+imcompatible
バージョンアップについて
- メジャーバージョン
- 後方互換性がない変更がされた場合
- パケージ削除や、インターフェースの変更など
- 推移的依存関係により2つの異なるバージョンが必要とされる場合、より高いバージョンが利用される
- v2以降は、モジュールのパスに
/v2のようなサフィックスが必要- 1つのビルド内で複数のメジャーバージョンが利用される場合がある
- 常に最新を利用する場合、バージョン間に互換性がない場合、依存しているモジュールが動かない場合があるため。
- マイナーバージョン
- 後方互換性がある変更がされた場合
- 関数が追加されたなど
- パッチバージョン
- バグフィックスや最適化された場合などインターフェースに影響が与えない場合
- pre-releaseサフィックス
- あるバージョンをプレリリースであることを示す
- プレリリースバージョンはリリースバージョンの前になる
- ビルドメタデータ接尾辞
- バージョン比較では無視される
- go.modファイルでは保持
- imcompatible接尾辞
- モジュールバージョンのメジャーバージョンに移行する前にリリースされたバージョン
- メジャーバージョンが2以上のgo.modファイルのないリポジトリとの互換性のためのサフィックス
- 作成者が自分でつけるものではなく、goコマンドが判断して付与されるサフィックス
バージョン管理リポジトリの特定のリビジョンの特別な書式のプレリリースバージョン
バージョンタグが利用できないリビジョンの参照で利用される
vX0.0-{リビジョンが作られたUTC時間}-{コミットハッシュの12文字}
パッケージパスの接頭辞を持つモジュールをビルドリストからから検索する。
ビルドリストにある場合、ディレクトリにパッケージを含んでいるかチェックする。
ビルドリストの中で1つのモジュールがパッケージを提供していなかったり、2つ以上のモジュールが同じパッケージを提供しているとエラーになる。
go build -mod=modでコンパイルをおこなうと不足しているパッケージを提供するモジュールを探す。
go getとgo mod tidyはこれを行う。
パッケージパスのモジュールを探すときにGOPROXYを調べる。
GOPROXYリストの各エントリに対して、パッケージパスのプレフィックスの最新版を要求する。要求に成功したら、そのモジュールをダウンロードし必要なパッケージが含まれているか検証する。1つ以上のモジュールがパッケージを含んでいる場合、最も長いパスをもつモジュールを使用する。ただし、パッケージが見つからない場合はエラー。
解決されたモジュールはgo.modファイルに追加される。
メインモジュールで利用されていない場合、// indirect commentのコメントをもつ。
GOPROXY:カンマ区切りのプロキシURLのリスト、direct、off
ルートディレクトリに行志向で記述されるUTF-8でエンコードされたファイル。
-
go get:依存関係のアップグレード、ダウングレードが可能 -
go mod edit:より低レベルな編集が可能 -
golang.org/x/mod/modfile:プログラム的にmodファイルを変更できる -
moduleディレクティブ:メインモジュールのパスを定義する。modファイルに1つ必ず含める。
ModuleDirective = "module" ( ModulePath | "(" newline ModulePath newline ")" ) newline .- module fuga
-
Deprecated:moduleディレクティブの前か後で、コメントブロックの中で非推奨をマークできる。
// Depecated: comment- そのモジュールのすべてのマイナーバージョンで適用される。v2より高いメジャーバージョンは別モジュール扱いとなる。
- Go1.17以降、
go list -m -uはビルドリストにあるすべての非推奨モジュールをチェックする。go getはコマンドラインで指定されたパッケージをビルドするために必要な非推奨モジュールをチェックする。
-
goディレクティブ:モジュールが期待するGoのセマンティックバージョンを記載する。
- go.modファイルの中に、最大で1つ含めることができる
- 後方互換性のない変更をサポートするためのものだった
- 指定されたバージョンよりあとに導入された言語機能の使用ができないようにする
- goコマンドの動作が変更される
- go1.14以降
vendor/modules.txtファイルが存在すると、自動ベンダリングが有効になる
- go1.16以降
- mainモジュールでimportされたパッケージとテストでインポートされたものだけにマッチ する
- より低いgoのバージョンでは、メインモジュールのパッケージによってインポートされたパッケージも含んでいた
- go.modファイルがないパッケージを読み込んだ場合、間接的な依存関係が発生する
- go1.17以降
- go.modファイルに、モジュールのパッケージやテストでインポートされるパッケージで利用される間接的に必要なモジュールも明示的にrequireに含まれるようになる
- importしたモジュールとして必要なモジュールであったとしても、パッケージで利用されていない場合、読み込む必要がないため、刈り込みの対象になる。
- モジュールグラフの刈り込みやモジュールの遅延読み込みが可能になる
- ※1.16以下では間接的な依存関係は最小限のバージョンしか含まれなかった
- 間接的な依存関係(
//indirect)が存在する可能性があるため、go.modファイル内の別のブロックに記載される go mod vendorはgo.modとgo.sumを省略する- 依存しているモジュールそれぞれのgo.modファイルから
vendor/module.txtにgoのバージョンを記録する
- 依存しているモジュールそれぞれのgo.modファイルから
- go.modファイルに、モジュールのパッケージやテストでインポートされるパッケージで利用される間接的に必要なモジュールも明示的にrequireに含まれるようになる
- go1.14以降
-
requireディレクティブ
- 依存モジュールの中で最小の必須のバージョン(MVS)を選択し定義される
// indirectコメントがある場合、モジュールが直接依存していないモジュールを表す- go 1.16以下
- メインモジュールの依存で利用されているモジュールのバージョンより高いバージョンの場合、indirectとして追加する
go get -uによる明示的なアップグレードや、依存関係の削除、go.modを持たないパッケージをインポートする場合に発生する
- go 1.17以降
- メインモジュールのテストやパッケージなどによって(間接的にでも)importされたそれぞれのパッケージも間接的な要件として追加される。
- これによって、go.modの再帰読み込みが最小限になり、モジュールグラフの刈り込みやモジュールの遅延読み込みが可能になる
- go 1.16以下
-
excludeディレクティブ
- 指定のモジュールのあるバージョンがgoコマンドでロードされるのを防ぐ
- メインモジュールのgo.modファイルだけで適用される
- go 1.16以前
- requireディレクティブで参照されているバージョンがメインモジュールのexcludeディレクティブで除外されている場合、利用可能なバージョンをリストアップし(go list -m -versions)代わりに除外されていないより高いバージョンをロードする。
- 時間経過で変化する可能性があります。
- 高いバージョンがない場合、エラーを出力する
- go 1.16以降
- requireディレクティブで参照されているバージョンがメインモジュールのexcludeディレクティブで除外されている場合、requireは無視されます。
- go getやgo mod tidyなどでより高いバージョンをinderectでで追加する要因になる
exclude golang.org/x/net v1.2.3
exclude (
golang.org/x/crypto v1.4.5
golang.org/x/text v1.6.7
)- replaceディレクティブ
- あるモジュールの特定のバージョン、またはすべてのバージョンを他の内容に置き換える
- メインモジュールのgo.modファイルだけで適用される
- 別のモジュールのパス、またはプラットフォーム固有のファイルパスを指定する
- 矢印の左側にバージョンがある場合、そのバージョンだけ置換される
- 矢印の右側が絶対パスや相対パスの場合、ローカルのファイルパスとして解釈される
- 置換後のバージョンは省略する
- 矢印の右側がローカルパス出ない場合、モジュールパスでなければならない
- 置換後のバージョンは必須
replace golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
replace (
golang.org/x/net v1.2.3 => example.com/fork/net v1.4.5
golang.org/x/net => example.com/fork/net v1.4.5
golang.org/x/net v1.2.3 => ./fork/net
golang.org/x/net => ./fork/net
)- retractディレクティブ(Go 1.16以降)
- go.modで定義されたモジュールのバージョンや範囲が利用されるべきでないことを示す
- リリースが早かった場合や、深刻な不具合が見つかった場合に利用する
- retractされても依存されたモジュールのビルドが壊れないように利用可能なままにすべき
- retractの根拠を説明するコメントを持つべきだが、必須ではない
- 撤回するにはretractを含んだ最新のバージョンを公開する必要がある(@latestで解決できるようにする)
- retractで撤回されるとgo getやgo mod tidyで自動的にそのバージョンにアップグレードすることはなくなる
- go getやgo list -m -uで更新をチェックすると通知される
- go list -m -retractedでないとバージョンリストからは隠される
- go.modで定義されたモジュールのバージョンや範囲が利用されるべきでないことを示す
retract v1.0.0
retract [v1.0.0, v1.9.9]
retract (
v1.0.0 // Published accidentally.
[v1.0.0, v1.9.9]
)White Space:スペース、タブ、キャリッジリターン、ニューリターンComments://,/* */がコメントとして許容されているPunctuation:,や=>が句読点Keywords:module、go、require、replace、exclude、retractIdentifiers:モジュールパスやセマンティックバージョンなどの並びStrings:"",\``で囲まれた文字の並びを文字列とする
- パスは1つ以上のスラッシュで区切られている必要がある
- また、文頭と文末がスラッシュになってはいけない
- ASCII文字、ASCII数字、制限付きASCII句読点からなるからでない文字列であること
- パス要素はドットから始まったり終わったりしてはいけない
- 最初のドットまでの要素名はWindwsの予約語であってはならない
- 最初のドットまでの要素名はチルダに続く1桁以上の数字で終わってはいけない
モジュールパスがrequireに含まれていてreplaceされていない場合、またはモジュールパスがreplace命令の右側にある場合、そのパスでダウンロードする必要があり、次の要件を満たす必要がある。
- 最初のスラッシュまでの先頭のパス要素は慣習的にドメイン名であり、少なくとも1つ以上のドットを含む必要があり、ダッシュ(
-)から初めてはならない。 - パス要素の末尾が
/vN(Nは数字とドット)である場合、- Nの先頭文字が0であってはならない
/v1であってもならない- ドットを含んではならない
go.modに情報が欠けたり、実態と異なっているとエラーになる。
go get やgo mod tidy、または-mod=modフラグはこれらの問題を自動で修正する。
go1.15以下では-mod=modが有効になっておりgoコマンドで自動実行されていた。
go1.16以降では-mod=readonlyが設定されているように動作する。go.modへの変更が必要な場合、エラーを報告する。
GOPATHからの移行の保証のために、goコマンドでgo.modを追加することでモジュールに移行していないリポジトリもモジュールのリポジトリに移行が可能。
go.modファイルのないモジュールをダウンロードする場合、goコマンドはモジュールディレクティブ以外なにもないモジュールキャッシュにあるgo.modファイルを統合します。
統合されたgo.modファイルにはgo.modファイルのないモジュールの依存関係をあらわすrequireディレクティブをもたないので、それぞれの依存関係が同じバージョンでビルドできることを保証するために、追加のreuireディレクティブ(// require)を必要とします。
詳細はRus Cox著のresearch!rsc: Minimal Version Selection (Go & Versioning, Part 4)
GoはMVSというアルゴリズムを使用してパッケージを構築するモジュールのバージョンを選択する。
MVSはビルドで使用されるモジュールのバージョンのリストであるビルドリストを出力として生成する。各モジュールで必要なバージョンを追跡しながらグラフを横断する。グラフをすべて巡回した時点で最も要求の高いバージョンでリストが構築される。このリストがすべての要求を満たす最小のバージョン。
go list -m allで確認できる。ビルドリストは決定論的に決まっているので、新しいバージョンの依存関係がでても変更されない。
モジュールの内容は、メインモジュールのgo.modファイルにあるreplaceディレクティブを使用して置き換えられる。置換されたモジュールは、置換前と異なる依存関係を持つ可能性があるため、モジュールグラフが変化する。
モジュールの内容は、メインモジュールのgo.modファイルにあるexcludeディレクティブで特定のバージョンをモジュールから除外できる。除外されるとモジュールグラフから除外されるため、上位のバージョンの要求に置き換えられる。
go getコマンドでモジュールのアップグレードするために使用される場合、MVSを実行する前にモジュールグラフを変更して、アップグレードされたバージョンのエッジを追加する。
ダウングレードする場合、ダウングレードするバージョンより上のバージョンをモジュールグラフから削除することでモジュールグラフの変更を行います。削除されたバージョンに依存する他のモジュールのバージョンの情報も削除されます。
また、メインモジュールがダウングレードによって削除されたバージョンを要求している場合、削除されたバージョンより前のバージョンを要求するモジュールのバージョンに変更されます。
メインモジュールがgo1.17以上の場合、MVSで使われるモジュールグラフには、go1.16以下のモジュールの依存関係で要求されない限り、go.modファイルでgo1.17以上が指定されている各モジュールの依存関係の直接的な要件のみ含まれる。(推移的依存関係はグラフから切り捨てられる。)
go1.17のgo.modファイルからは、そのモジュールのパッケージやテストをビルドするために必要なすべての依存関係のためのrequireディレクティブを含む。(明示的に必要でない依存関係はモジュールグラフから刈り取られる)
あるモジュールにとって必要のないモジュールは動作に影響を与えることはできないので、モジュールグラフで刈り取られた依存関係が残っていると無関係なモジュール間の干渉を引き起こす。
go1.16以前はgo.modファイルに直接の依存関係しか含まれていなかったため、より大きなすべての間接的な依存関係がロードされないといけなかった。
go mod tidyによって記録されたgo.sumは、go.modのgoディレクティブより1つ下のバージョンで必要なチェックサムを含む。
go1.17では、go1.16でロードされた完全なモジュールグラフに必要なチェックサムをすべて含む。
go1.18では、go1.17で刈り取られたモジュールグラフで必要なチェックサムだけを含む。
メインモジュールがgo1.17以降の場合、モジュールグラフ全体の読み込みを必要になるまで遅延させられる。代わりにメインモジュールのgo.modファイルのみを読み込んで、その要件だけをつかってビルドするパッケージのロードを試みる。メインモジュール外のパッケージのテストの依存などで必要なパッケージが見つからない場合、残りのモジュールグラフを要求に応じてロードする。
モジュールグラフを読み込まずにgo.modファイルからインポートされたパッケージが全て見つかった場合、go.modファイルをロードする。ロードした結果、メインモジュールの要件と照合されてローカルで整合していることが確認される。
ワークスペースはMVSを実行するときに、ルートモジュールとして使用されるディスク上のモジュールの集合です。
ワークスペース各モジュールのディレクトリへの相対パスを指定したgo.workファイルで宣言できる。go.workが存在しない場合、ワークスペースはカレントディレクトリを含む単一のモジュールで構成される。
-workfileフラグを確認することで、ワークスペースのコンテキスト上にあるかを判断する。フラグは.workで終わる既存のファイルへのパスを指定した場合、有効化される。
ルートディレクトリに行志向で記述されるUTF-8でエンコードされたファイル。
go 1.18
use ./my/first/thing
use ./my/second/thing
use (
./my/first/thing
./my/second/thing
)
replace example.com/bad/thing v1.4.5 => example.com/good/thing v1.4.5
- goディレクティブ
- go.workファイルに必須
- 有効なリリースバージョンを記載
- useディレクティブ
- ディスク上のモジュールをワークスペースのメインモジュールの集合に追加する。
- go.modファイルがあるディレクトリの相対パス
- replaceディレクティブ
- go.modのreplaceディレクティブと同様にすべて、もしくは特定のバージョンのモジュールの内容を置き換える
- go.workのワイルドカードの置換は、go.modファイルのバージョン指定のreplaceをすべて置き換える
goコマンドはモジュール対応モードとGOPATHモードで実行できる。
- GO111MODULE=off
- go.modファイルがあってもGOPATHモードで実行される
- GO111MODULE=on
- go.modファイルの存在有無に関わらずモジュールモードで動作する
- go.modファイルを使って依存関係を探すようになります
- go1.16以降ではデフォルトで有効
- GO111MODULE=auto
- go1.15以前でデフォルトで有効
- go.modファイルがあるとモジュールモードが有効化される
go build, go fix, go generate, go get, go install, go list, go run, go test, go vet
モジュールコマンドに共通する以下のフラグを利用できる
-mod
go.modが自動的に更新されるか、vendorディレクトリが使われるかを制御するgo1.14 以上ではvendorディレクトリが存在する場合、-mod=vendorを指定されたように動作する。そうでない場合、mod=readonlyが指定されたように動作する。
-mod=mod- vendorディレクトリを無視してgo.modを更新するように指示する
-mod=readonly- vendorディレクトリを無視してgo.modを更新が必要な場合、エラーを報告する
-mod=vendor- vendorディレクトリを利用するように指示する
-moodcacherwモジュールキャッシュに作成するディレクトリを書き込みも可能なパーミッションを指定する。 パーミッションを変更せずにモジュールキャッシュを削除できる-modfile=file.modモジュールルートディレクトリのgo.modファイルの代わりのファイルを読み書きするように指定できる。拡張子は.modである必要がある。ただし、go.modファイルはモジュールルートディレクトリを決めるために必要だが、使用されることはない。-workfileワークスペースを定義するgo.workファイルを使用してワークスペースモードを使用するようにgoコマンドに指示する。
- vendorディレクトリを利用するように指示する
go mod vendorコマンドでメインモジュールのルートディレクトリにvendorディレクトリを作成。メインモジュールのパッケージのビルドやテストに必要なすべてのパッケージのコピーを格納する。メインモジュール以外のパッケージのテストでしか使われていないパッケージは含まれない。
また、vendor/modules.txtというファイルが作成される。vendoringが有効な場合、go list -mなどで出力されるバージョン情報のソースとして使用される。このとき、modules.txtはgo.modファイルと一致するかどうかチェックする。
go1.14以上でメインモジュールのルートディレクトリにvendorディレクトリがあれば自動で使用される。
vendorが使用される場合、ビルドコマンドはネットワークやモジュールキャッシュにアクセスせずにvendorディレクトリからパッケージをロードする。
| title | type | weight | lastmod | |
|---|---|---|---|---|
Release |
docs |
1 |
|
2023/8リリース
- このマイナーバージョンから
.0のパッチバージョンがつくようになった - buildin関数が増えるよ
- min/max
- clear
mapがデカくなっちゃったままにはならんのかな
- 型推論のパワーアップ
- ジェネリックな関数の引数としてジェネリックな関数を渡した場合、型引数をわたさなくても関数側の引数の型から型推論されるようになった。
go:wasmimportディレクティブでWebAssemblyからインポートした関数をGoのプログラムで利用できるようになった- ようわからん
- WASIの対応を実験的にはじめた
- 1.20ではいったPGOがbuildコマンドのpgoフラグがデフォルトで
-pgo=autoになった。 - 追加された関数
log/slogパッケージ正式リリース- slogハンドラーのテスト用に
testing/slogtestが追加
- slogハンドラーのテスト用に
- スライスやマップの共通の関数をまとめた
slices,mapsパッケージが追加- これがジェネリクスの賜物なんだな。
contextWithoutCancel:キャンセルされたコンテキストからキャンセル前のコンテキストのコピーを返す。WithValueとかしたやつもコピーされるのかな。WithDeadlineCause/WithTimeoutCause:タイマー切れのときに原因を設定できるようになる。Cause関数で取得できるAfterFunc:コンテキストがキャンセルされた後に実行する関数を登録できる- cleanup関数登録とかすんのかな
- カバレッジのプロファイルをコンパイル後のバイナリの実行で取得できるようになった
Coverage profiling support for integration tests - The Go Programming Language
go build -coverでカバレッジのプロファイルを出力するバイナリにビルドできる。-covevrpkgフラグでカバレッジに含めるパッケージを指定できる。プロフィルが環境変数COVERDIRで指定されたディレクトリに出力される。環境変数COVERDIRのプロファイルを操作するgo tool covdataが追加go tool covdata percent -i=somedataでカバレッジの割合が出力されるgo tool covdata textfmt -i=somedata -o profile.txtでgo testで生成されるプロファイルに変換go tool covdata merge -i=windows_datadir,macos_datadir -o mergedで複数のOSで実行したプロファイルのマージができる
- プロファイル誘導型最適化(PGO)
Profile-guided optimization - The Go Programming Language
CPU pprofファイルをコンパイラのフィードバックとして使用しコンパイラの最適化の決定(FDO)をおこないます。PGOを使用してビルドすると性能が2~4%程度の向上が期待できるコンパイル時のコードが取得したプロファイルのコードから変更されていた場合、変更箇所は最適化の影響をうけない。コンパイラはPGOビルドを繰り返しても最適化のばらつきを防ぐような保守的なつくりになっている。
go build -pgo=autoでビルドするとdefault.pgoファイルを自動で選択してコンパイルします。go1.20ではデフォルトでgo build -pgo=off
- slice型を配列のポインタにキャストできるようになった
型変換でパニックを起こす可能性がある。 - go.modに間接的に呼び出されるパッケージが含まれるようになった
go get時とかにサブパッケージのgo.modまで読み込む必要がなくなったのかな // +buildだったのが、他に合わせて//go:buildに変更されたgo runでバージョンサフィックス付きで呼び出せるようになった
go run example.com/hoge/cmd@v1.0.0
ファイルをインストールしたり、go.modに変更を及ぼさずに使える- tools.goいらない子。
- コンパイラが関数の引数にレジストリ使うようになって2%処理速度が向上
- testing.Tとtesting.BにSetenvが追加
テストに閉じた環境変数を設定できる
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| package main | |
| import ( | |
| "fmt" | |
| "sync" | |
| "sync/atomic" | |
| "time" | |
| ) | |
| const CacheLinePadSize = 64 | |
| type CacheLinePad struct { | |
| _ [CacheLinePadSize]byte | |
| } | |
| type RingBuffer[T any] struct { | |
| size uint64 | |
| buf []T | |
| _ CacheLinePad | |
| readIndex atomic.Uint64 | |
| cachedWriteIndex uint64 | |
| _ CacheLinePad | |
| writeIndex atomic.Uint64 | |
| cachedReadIndex uint64 | |
| } | |
| func NewRingBuffer[T any](n int) *RingBuffer[T] { | |
| size := uint64(2 << (n - 1)) | |
| return &RingBuffer[T]{ | |
| buf: make([]T, size), | |
| size: size, | |
| } | |
| } | |
| func (r *RingBuffer[T]) Dequeue() (item T, ok bool) { | |
| readIndex := r.readIndex.Load() | |
| if readIndex == r.cachedWriteIndex { | |
| r.cachedWriteIndex = r.writeIndex.Load() | |
| if readIndex == r.cachedWriteIndex { | |
| return | |
| } | |
| } | |
| item = r.buf[readIndex&(r.size-1)] | |
| r.readIndex.Store(readIndex + 1) | |
| return item, true | |
| } | |
| func (r *RingBuffer[T]) Enqueue(item T) bool { | |
| writeIndex := r.writeIndex.Load() | |
| if writeIndex-r.cachedReadIndex == r.size { | |
| r.cachedReadIndex = r.readIndex.Load() | |
| if writeIndex-r.cachedReadIndex == r.size { | |
| return false | |
| } | |
| } | |
| r.buf[writeIndex&(r.size-1)] = item | |
| r.writeIndex.Store(writeIndex + 1) | |
| return true | |
| } | |
| func main() { | |
| rb := NewRingBuffer[int](10) | |
| size := 2 << 9 | |
| var wg sync.WaitGroup | |
| start := time.Now() | |
| for i := 0; i < 1024; i++ { | |
| wg.Add(2) | |
| go func() { | |
| defer wg.Done() | |
| for i := 0; i < size; i++ { | |
| for { | |
| if ok := rb.Enqueue(i); ok { | |
| break | |
| } | |
| } | |
| } | |
| }() | |
| go func() { | |
| defer wg.Done() | |
| for i := 0; i < size; i++ { | |
| for { | |
| if _, ok := rb.Dequeue(); ok { | |
| break | |
| } | |
| } | |
| } | |
| }() | |
| wg.Wait() | |
| } | |
| elapsed := time.Now().Sub(start) | |
| times := 2 * 1024 * 1024 | |
| elapsedms := float64(elapsed.Nanoseconds()) / 1000 / 1000 | |
| fmt.Printf("finished benchmark. %d times, elapsed %f ms, %f op/ms\n", times, elapsedms, float64(times)/elapsedms) | |
| } |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
言語仕様 |
docs |
showa |
|
1 |
- Goの言語仕様における表現方法:EBNF - Wikipedia
- Template:General Category (Unicode) - Wikipedia
- identifiers
- keywords
- operators and punctuation
- literals
ホワイトスペース(スペース(U+0020)、水平タブ(U+0009)、キャリッジリターン(U+000D)、ニューライン(U+000A))は、トークンを分離する場合を除き、無視されます。
また、開業やファイルの終端があるとセミコロンが挿入されることがある。
生成物の終端にセミコロンを使用している。ただし、以下のルールでセミコロンを省略できる。
- 以下のトークンであれば、行の最後のトークンの直後に自動的にセミコロンが挿入される
- identifiers
- 整数、浮動小数点、虚数、ルーン、または文字列リテラル
- break、continue、fallthrough、returnのいずれかのキーワード
- 演算子および句読点の中の++、--、)、 ] 、 } のいずれか。
- 文を1行にまとめるために、)や}で閉じる前のセミコロンを省略できる
変数や型などのプログラムの実態をあらわす。
identifier = letter { letter | unicode_digit } .
予約済みのキーワード
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Goで文字列のポインタ参照でアロケート |
docs |
showa |
|
1 |
- 文字列の変数のスコープがポインタ参照によって関数より外に広がったことでheapに割り当てられる
- これは実際にポインタ参照されるところまでコードが到達しなくても関数を呼び出した時点で発生する
- (あたり前田のクラッカー)
- そのため、該当箇所まで到達しなくてもメモリアロケートが発生する
勉強不足。この修正でライブラリの性能ちょっとあがったので学び。
遭遇したのはこんな感じのreflectで文字列を操作したときにみつけた。 ※再現確認のために超簡単な内容にしている。
package main
import "reflect"
func main() {
stringToString("XXX")
}
func stringToString(s string) string {
if s != "" {
return s
}
return reflect.ValueOf(&s).Elem().String() // ← ここには到達しない
}到達しないが、Benchmarkとると1allocs走ってる
> go test -bench $ -benchmem -benchtime 5s string-test
goos: linux
goarch: amd64
pkg: string-test
cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
BenchmarkReflectString-8 217355878 27.66 s/op 16 B/op 1 allocs/opなんでだろ~。reflect.ValueOf~を別の関数にしてみる。
package main
import "reflect"
func main() {
stringToString("XXX")
}
func stringToString(s string) string {
if s != "" {
return s
}
return valueOfString(s).String()
}
func valueOfString(s string) reflect.Value {
return reflect.ValueOf(&s).Elem()
}Benchmarkをとるとallocsがゼロになった!
> go test -bench $ -benchmem -benchtime 5s string-test
goos: linux
goarch: amd64
pkg: string-test
cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
BenchmarkReflectString-8 1000000000 1.391 ns/op 0 B/op 0 allocs/op次にbuildでgcflagsフラグをつかってコンパイル時の最適化の内容をみてみる。
まず前者のメモリアロケートが発生するパターン。
stringToString関数で変数sがヒープに移動されている。つまり、stringToString関数が呼び出すと引数の変数sはスタックじゃなくてヒープにおかれる。
> go build -gcflags '-m' main.go
# command-line-arguments
./main.go:14:24: inlining call to reflect.ValueOf
./main.go:14:42: inlining call to reflect.Value.String
./main.go:14:24: inlining call to reflect.escapes
./main.go:14:24: inlining call to reflect.unpackEface
./main.go:14:24: inlining call to reflect.(*rtype).Kind
./main.go:14:24: inlining call to reflect.ifaceIndir
./main.go:14:42: inlining call to reflect.flag.kind
./main.go:5:6: can inline main
./main.go:9:21: moved to heap: s次に後者。
stringToString関数でleaking paramが起きている。これはぐぐるとGoのコンパイル時の最適化結果を確認する(インライン化の条件についても記載) - Qiitaより、関数が終わっても変数が残るというアラート。なので、関数呼び出し時点ではヒープに変数が置かれてはいない。
> go build -gcflags '-m' main.go
# command-line-arguments
./main.go:19:24: inlining call to reflect.ValueOf
./main.go:19:24: inlining call to reflect.escapes
./main.go:19:24: inlining call to reflect.unpackEface
./main.go:19:24: inlining call to reflect.(*rtype).Kind
./main.go:19:24: inlining call to reflect.ifaceIndir
./main.go:15:32: inlining call to reflect.Value.String
./main.go:15:32: inlining call to reflect.flag.kind
./main.go:5:6: can inline main
./main.go:18:20: moved to heap: s
./main.go:9:21: leaking param: s別に関数にしなくても別の変数に置き換えても問題なし。
func stringToString(s string) string {
if s != "" {
return s
}
t := s
return reflect.ValueOf(&t).Elem().String()
}
// > go test -bench $ -benchmem -benchtime 5s -memprofile mem.out string-test
// goos: linux
// goarch: amd64
// pkg: string-test
// cpu: Intel(R) Core(TM) i7-9700 CPU @ 3.00GHz
// BenchmarkReflectString-8 1000000000 1.476 ns/op 0 B/op 0 allocs/op| title | type | weight | lastmod | |
|---|---|---|---|---|
Test |
docs |
1 |
|
関数名の接頭辞にBenchmarkをつけて*testing.Bを受け取る関数をつくるとベンチマークをとれる。
-benchmemでベンチマーク中のメモリの情報がとれる。
-cpuprofile [ファイルパス]: ベンチマーク中のCPUのプロファイルを取得し出力します。-memprofile [ファイルパス]: ベンチマーク中のmemoryアロケーションのプロファイルを取得し出力します。-trace [ファイルパス]: ベンチマーク中のtraceを取得し出力します。-gcflags: gcコンパイラにわたすフラグを設定できる。-mを渡すと最適化の結果を確認できる。
go test -benchmem -cpuprofile pprof/cpu.out -memprofile pprof/mem.out -bench BenchmarkCtable github.com/showa-93/hashing/hashtable取得したprofileをwebで参照する。
go tool pprof -http ":8080" pprof/cpu.out| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Java |
docs |
showa |
|
100300 |
- Java7からJava16までの変遷。 - Qiita
- finalについて
- Javaのfinalを大解剖 finalの全てがここにある!!
- 完全に理解した
- Javaのfinalを大解剖 finalの全てがここにある!!
- JavaBeans
- 再利用可能なモジュール化されたプログラムを作成するための仕様
- (Java)新人向けにJavaBeansの直列化やフィールド・プロパティの謎をPOJOとの違いを交えて解説 - Qiita
- 非同期処理
Threadで非同期処理をおこなう別のスレッドを動かせる- 「
Threadの継承したクラス」または「Runnable を実装したクラス」を実行体として利用できる - Javaのスレッド(Thread)を使いこなすコツを、基礎からしっかり伝授
- Callbackや共通の変数で値の受け渡しをおこなう。
- 排他制御
synchronizedブロック- 識別子で指定したブロックそのものを排他制御させる。マルチスレッドで同時に実行されることを防げる
- ロック対象は同一のインスタンスのみ
synchronized識別子- メソッドそのものを排他制御させる。マルチスレッドで同時に実行されることを防げる
ReentrantLockクラス- 明示的にロック制御可能
- lock取得後try-catchで囲んで、finallyで必ずロックを開放する
atomicなんたら- 単一の変数などの加算代入などの原子性を担保して排他制御できる
- ラムダ式やメソッドの参照に利用するインターフェースたち
Stream- Collectionの操作を遅延評価で行う専用のオブジェクト
- 拡張性を考慮された結果、Listに直接生やすのではなく、一度stream()を挟む形になっているらしい、
- https://qiita.com/huge-book-storage/items/79fe8bd0de330e9ed1f7
- gradlew
- Gradle Wrapperのコマンド
- 共通の設定済みのGradleを配布できる形にしたもの
gradle wrappergradlew dependencies- 依存関係にあるライブラリをダウンロードする
gradle bootBuildImage
- build.gradle
-
groovyで記述できるビルド定義
-
dependencies
- ビルド時に必要なライブラリを定義している
- Gradleのdependenciesはどう書くべきか | Korean-Man in Tokyo
dependencies { implementation 'org.groovy:groovy:2.2.0@jar' implementation group: 'org.groovy', name: 'groovy', version: '2.2.0', ext: 'jar' }
-
実行可能なスタンドアロンのSpringベースのアプリケーションを作成できるフレームワーク。 デフォルトのロギングシステムはlogbackが利用されている→Spring Boot でロギングライブラリをLog4j2にする - Qiita https://spring.pleiades.io/spring-framework/docs/current/reference/html/
- SpringのDIコンテナーの読み込み
@ComponentScan(@SpringBootApplication)のアノテーションがついているクラスのパッケージとその配下のクラスに存在する@Component(またはそれが含まれるアノテーション)がついているクラスを走査し、BeanをDIコンテナに登録する。 https://github.com/kazuki43zoo/spring-study/tree/master/memos/ioc-container
- Bean
- Springコンテナで管理させたいBean(オブジェクト)を生成するメソッドにつける
@Configurationをつけたクラスで定義できる- Springコンテナによってインスタンス化され、
@Autowiredまたは@Injectを付与したフィールドにDIされる - Java Beansと異なり
Java.io.Serializableを実装する必要がない - サードパーティライブラリのクラスを利用する場合に利用することが多い
- 【Spring】Beanのライフサイクル〜生成から破棄まで〜 - Qiita
- Beanを生成、破棄するFactoryのインターフェース
- Component
- SpringのDIコンテナで管理させ、
@AutowireなどでDIできるようになる
- SpringのDIコンテナで管理させ、
- ComponentScan
- このクラスのパッケージ配下で@Component, @Service, @Repository, @Controller, @RestController, @Configuration,@NamedつきのクラスをDIコンテナに登録します。
- RestControllerAdvice
- 共通のエラーハンドリングのクラスを表す
- 各メソッドに
@ExceptionHandlerでハンドリングする例外を指定することで例外別のエラー処理を作成できる @ExceptionHandlerは通常のコントローラ内のメソッドでアノテーションを指定するとコントローラ別で例外処理できる
- 各メソッドに
- Spring-boot-exception-handling - Dev Guides
- アドバイスの作成3 - @ControllerAdvice · 独習Spring
- 共通のエラーハンドリングのクラスを表す
アノテーションをつけることでコンパイル時にコードを自動生成するライブラリ 同一のコードを記載することで発生する煩雑さをなくし、コードの可読性を向上させられる
使いたいロギングライブラリをプラグインできるようにするファサード。 SLF4J自体はロギングのインターフェースであり、このインターフェースに対応した実装のロギングシステムを設定で切り替えられる。 共通のインターフェースでロギングライブラリの詳細を知らずとも利用でき、インターフェースが共通なため他のライブラリに切り替えることも容易。
- ビルドツールの違いって何?
- ビルドツール make / ant / maven / gradle ざっくり理解メモ - Qiita
- Maven
- Gradle
- サーブレットコンテナってなに
- Java Servletの実行環境。Webコンテナとも呼ばれる
- Tomcat
- Jetty
- Webサーバー→サーブレットコンテナ→サーブレット
- ビジネスロジック以外の処理を提供してくれたりする
- Spring Bootの場合、TomCatかなんかがくみこまれてる
- Java Servletの実行環境。Webコンテナとも呼ばれる
- Spring Bootビルド後のコントローラってどうなってるの。というかルーターの生成かな。
- Spring boot側が管理してるけど、最初のロードのときにやってんのかな
- WebサーバーとSpring bootとかの関係性(通信経路)がぴんとこん
- spring bootは、tomcatが同梱された実行ファイルを生成するぜ
- なので、spring bootで開発したらそのまま動かせる
- さくっと理解するSpring bootの仕組み
- エラーハンドリングってどうしてるの
- 一番大本のエラーハンドリングするコントローラがつくれるからそこで任意の例外を補足するか、個別で補足するか
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Kubernates |
docs |
showa |
|
100800 |
# cluster 作成のコンフィグファイル
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
role: control-plane
role: worker
role: worker# clusterを作る --nameを指定しない場合、"kind"でつくられる
kind create cluster --config k8s.yamlKubernetesはAPIを通じて操作している。cuiのkubectlはマスターノードのkube-apiserverに対して、yaml形式やjson形式のマニフェストを送信してオブジェクト(ポッド、コントローラ、サービスetc...)を操作する。
ワークロードは、オブジェクトのカテゴリを表す用語として用いられ、コンテナとポッド、そして、コントローラのグループを指しています。これらは、アプリケーションやシステム機能を担うコンテナの実行を管理するために使用されます。
- フロントエンド処理
- バックエンド処理
- バッチ処理
- システム運用処理
コンテナの起動に設定できる項目は、引数や環境変数、永続ボリュームのマウント先のパス、CPU使用時間やメモリ容量の要求量や上限値、ヘルスチェック方法、コンテナ起動時の実行コマンド、イメージ名などがあります。
コンテナを実行するためのオブジェクトです。ポッドは1つまたは複数のコンテナを内包しており、その構造が、エンドウ豆の鞘(さや)が豆を内包する様子と似ています。このことから、このオブジェクトは鞘を意味する英単語のPodで表現されています。状態は保持しないので、起動と削除しかありません。IPはエフェメラルなため、Podへのアクセスはservice名を利用します。
- ポッド内部のコンテナを外部に公開できる
- ポッド内部のコンテナはlocalhostのIPアドレスとポート番号で互いに通信できる
- ポッド内部のコンテナは、ポッドのボリュームをコンテナからクロスマウントして、ポッド内でファイルシステムを共有できる
- ポッドは内部のコンテナの監視設定できる
- ポッドの起動後、初期化専用コンテナ(initContainers)をほかのコンテナ起動前に実行できる。
正常終了するとポッド内の他コンテナが起動される - 活性プローブ(livenessProbe)が問題を検知すると、コンテナを強制終了して再び起動することで回復を試みる
- 準備状態プローブ(readinessProbe)は真を返すまで、サービスオブジェクトはポッドへリクエストを転送しない
- 削除要求があった場合、終了要求シグナル(SIGTERM)が送信
猶予期間過ぎて終了されていない場合、SIGKILLされる
コンテナをブラックボックスとして扱い、再利用性の高い複数のコンテナを組み合わせて利用するパターン。
https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns/
「コントローラ」は、ポッドの実行を制御するオブジェクトであり、処理の種類に応じた複数のコントローラを使い分けなければなりません。たとえば、クライアントサーバーモデルに適した「デプロイメント」コントローラでは、サーバー役のポッドの数が、なんらかの原因で目標設定値より少なくなったら、目標値を維持するようにポッドを起動します。また、バッチ処理用の「ジョブ」コントローラでは、バッチ処理が正常終了するまで再実行を繰り返し、正常終了したらログが参照できるようにポッドの削除を保留します。
- Deployment-ポッドの起動と停止を迅速に実行するよう振る舞い、稼働中ポッドの順次置き換え、オートスケーラーとの連動、さらに、高可用性構成が可能という特徴があり、オールラウンドに適用できます。
- StatefulSet-ポッドと永続ボリュームの組み合わせで制御を行い、永続ボリュームの保護を優先します。
- Job-バッチ処理のコンテナが正常終了するまで再試行を繰り返すコントローラです。ポッドの実行回数、同時実行数、試行回数の上限を設定して実行、削除されるまでログを保持する
- CronJob-時刻指定で定期的に前述の「ジョブ」を生成します。UNIXに実装されるcronと同じ形式で、ジョブの生成時刻を設定できます。
- DaemonSet-K8sクラスタの全ノードで、同じポッドを実行するためにあります。システム運用の自動化に適しています。
- ReplicaSet-デプロイメントコントローラと連動して、ポッドのレプリカ数の管理を担当します。
-
Scale
Replicaの値を変更してpodの数を増減させる機能。CPU使用率と比例して自動でスケールさせるオートスケール機能がある。 podを増やす過程でk8sの計算資源が不足するとノードが増設されるまでpodの増設は保留される。- 水平ポッドオートスケーラ (Horizontal Pod Autoscaler: HPA)
-
CPU稼働時間を監視して指定されたCPU使用率以下になるようにポッドのレプリカ数が調整される
-
CPU稼働時間→例えば、200ms/sだと 1秒あたり200ミリ秒のCPU時間に相当
-
nodeに1core割り当てられていたら、1000ms/s使えるので、5つのポッドが使える。
- クラスタオートスケーラ(Cluster Autoscaler: CA)
-
RollOut
アプリケーションコンテナの更新。通常の適用と同様にkubectl apply -fで適用可能。進行中はリクエストの処理負荷に対処できるポッド数を残して停止できるポッド数(停止許容数)だけ古いポッドを停止する。停止許容数に加えた数だけreplicasの数を上限としてポッドを起動して新しいコンテナへの更新を行う。
RollingUpdateStrategyがロールアウトの設定。kubectl describe deployment web-deployで核にできる。- RollBack
- ロールアウト前の古いコンテナの状態に戻すためにポッドを入れ替えていく。
kubectl rollout undo deployment {resource name}
-
自己回復機能
ポッドが内包するすべてのコンテナが正常終了するまで再試行する。再試行回数の上限が達するとジョブが中断される。ノード障害でポッドが失われた場合、別のノードで再スタートする。ポッドはジョブが削除されるまで保持される。
CronJobの場合、指定時刻のたびにポッドを生成して実行します。決められた保存世代数を超えるとガベージコレクションというコントローラを使って終了済みのポッドを削除する。
ポッドと永続ボリュームの対応関係を厳密に管理し、永続ボリュームのデータ保護を優先するようにふるまう。
ステートフルセット管理下のポッドは、レプリカセットと連携したハッシュ文字ではなく、連番を付与して命名される。
ボリューム名もポッドとの対応付けが明確になるように末尾に連番を付与する。
ヘッドレスサービスで設定すること。IPは固定できないので、内部DNSで解決するようにする。
すべてのノードでポッドを実行するためのコントローラ。管理下にあるpodをk8sクラスタの全ノードで稼働するように制御する。ノードが削除されると、その管理下のポッドがそのノードから削除される。ノードセレクタで一部のノードに限定できる。
メッセージブローカーと合わせて利用する。ジョブを初期化するdocker containerを用意して、値をメッセージブローカーに登録する。
そして、kubeAPIを利用して動的にmanifestを作って、JobControllerでメッセージを受け取って処理させる。

高良真穂. 15Stepで習得 Dockerから入るKubernetes (Kindle の位置No.3738-3739). 株式会社リックテレコム. Kindle 版.
コンテナ内のアプリケーションの設定やパスワードなどの情報は、デプロイされた「名前空間」から取得することが推奨されています。それを促進するためのオブジェクトとして、設定を保存する「コンフィグマップ(ConfigMap)」と、パスワードなど秘匿情報を保存する「シークレット(Secret)」があります。
Kubernetesの「サービス」は、ポッドとサービス名とを具体的に紐付ける役割を負います。つまり、「処理のサービス」を提供するサーバー役のポッドが、クライアントのリクエストを受け取れるようにするために、「サービス」は代表IPアドレスを取得して内部DNSへ登録するなどを担当します。さらに、代表IPアドレスへのリクエストトラフィックを該当のポット群へ転送する負荷分散の設定も担当します。
-
ロードバランサーの役割を持ち、ポッドを代表するIPアドレスを獲得して、クライアントのリクエストを受ける。
-
オブジェクト生成時にサービス名と代表IPアドレスを内部DNSへ登録する。これによりクライアントは、サービスの名前からその代表IPアドレスを取得できる。
-
サービスがリクエストを転送するべきポッドを選別するために、サービスのセレクターにセットされたラベルと一致するポッドを選び出し、そのIPアドレスへリクエストを転送する
-
サービスのオブジェクト存在時に起動されるポッドのコンテナには、サービスへアクセスするための環境変数が自動的に設定されるようになる。
-
サービスには4種のサービスタイプがあり、クライアントの範囲をK8sクラスタの内部に留めるか、外部まで対象とするか、また反対に、K8sクラスタ外部のIPアドレスへ転送するかを設定する。
| Service Type | Access Range and Method |
|---|---|
| Cluster IP | デフォルト。ポッドネットワーク上のポッドから内部DNSに登録された名前でアクセスできる |
| NodePort | CusterIP のアクセス可能範囲に加えて、K8sクラスタ外のクライアントもIPとPortを指定してアクセスできる。ノード横断でリクエストの分配が可能 |
| LoadBalancer | NodePortのアクセス可能範囲に加えて、K8sクラスタ外のクライアントも代表IPアドレスとプロトコルのデフォルトポート番号でアクセスできる |
| ExternalName | K8sクラスタ内のポッドネットワーク上のクライアントから外部のIPアドレスを名前でアクセスできる |
- セッションアフィニティ 代表IPアドレスで受けたリクエストを常にポッドに送信するキー項目。 ClientIPをセットするとクライアントのIPアドレスで転送先を固定できる
ストレージシステムの違いを隠蔽して、コンテナが共通したAPIによって「永続ボリューム(Persistent Volume)」をアクセスできるようにしています。これを実現するためにストレージを階層的に抽象化するオブジェクト群が用意されています。 PVのプロビジョニングは、PVC(永続ボリューム要求)の作成に伴って自動的に行われる。
storage
| 種類 | 範囲 | col3 |
|---|---|---|
| emptyDir | 同一ポッド内ファイル共有 | ポッドから一時的に利用する仕組み。 |
| ポッド終了とともに削除される。 | ||
| hostPath | 同一ノード内ファイル共有 | ポッドとともに削除されない。 外部ストレージを利用できない場合の代替手段。 |
| local | 同一ノード内ファイル共有 | ノードのディスクをコンテナからマウントして利用 |
| 外部 | ストレージシステムの方式による | NFSのようなプロトコルだとノード間で 永続ボリュームを共有できる |
Roll-Based Access Control(RBAC) 。クラスタ内で役割の権限を定義できるアクセスコントロールのこと。サービスアカウントが対応しており、サービスアカウントはユーザ個人でなく、コンテナに対して特権を付与する。namespace内で一意である。
TODO:よくわからん。podに与える権限をコントロールしてる感じ? https://kubernetes.io/ja/docs/reference/access-authn-authz/authentication/
リバースプロキシ。 k8sクラスタの外部からのリクエストをK8sクラスタ内部のアプリケーションへつなぐためのAPIオブジェクト。 SSL/TLS暗号化やセッションアフィニティなどの機能を備えている。
- 公開用URLとアプリケーションの対応付け
- パス部分に複数のアプリケーションを紐づけることができる!
- ingress→Serviceに転送される
- 「仮想ホスト」機能で、1つのパブリックIPアドレスを共有して、ドメイン名によって転送先を設定できる
metadataのannotation
- kubernetes.io/ingress.class:'nginx': 複数のingressが動いている場合の送り先設定
- nginx.ingress.kubernetes.io/rewrite-target:/ : URLパスの書き換え要求
論理的にクラスタを区分することができる。名前空間を利用して論理的にコマンドの有効範囲を制限できる。
名前空間は、1つの物理的なk8sをカオス化して、複数の占有環境としての利用を設定できる。
-
スコープ設定
-
リソースの割り当て
-
アクセス制御(Calico)
-
default: デフォルトの名前空間
-
kube-public: すべてのユーザーが読める空間
-
kube-system: システムやアドオンによって利用される名前空間
- パスワード、トークンまたはキーなどの機密情報を保持できる
- Base64エンコーディングする必要がある
- 名前空間やサービスアカウントを作成した際のトークンを保存したシークレットが名前空間に自動生成される
- ポッドの環境変数やボリューム、ファイルとして利用できる
- tls証明書の設定とかもできるよ
- 暗号化機能を有効にできる
- ポッドを起動する前にシークレットを生成する必要がある
- Base64エンコードする必要がない
- シークレットと異なり定期的に更新チェックされており自動更新されて反映される
-
ヘルスチェック
KubernetesのチェックするAPIに対応するコマンドやHTTPのアクセスパスを実装することでヘルスチェック苦悩を活かせる。 -
コンテナの終了
SGTERMをアプリケーションが受け取るとコンテナを停止するための終了処理を開始するように実装する必要がある。 -
稼働ログ
DockerやKubernetesは集中型ロギング死すt無へ接続できる。そのため、アプリケーションのログは一貫して標準出力や標準エラー出力へ書き出すように実装する。 -
終了ステータス
プロセス「PID=1」のExitコードがコンテナの終了コードとしてセットされる。 終了コード=0で終了すると、正常終了。0以外で終了すると失敗終了として扱う。
アプリケーションはこの終了コードを実装する必要がある。
kubernatesを用いた継続的な開発体験を実現するデプロイツール
Kubernetesのアプリケーション開発で楽をしたい。そうだ、Skaffoldを使ってみよう! | Skyarch Broadcasting
| title | type | weight | lastmod | |
|---|---|---|---|---|
Logging |
docs |
100900 |
|
| title | type | weight | lastmod | |
|---|---|---|---|---|
開発手法 |
docs |
7000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
BDD |
docs |
showa |
|
1 |
-
- CucumberっていうBDDの支援ツール的なさむしんぐ
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
DNS |
docs |
showa |
|
1 |
Domain Name System(ドメイン・ネーム・システム)
インターネット上のドメイン名とIPアドレスの対応付けを階層化と委任におる分散管理しているシステム。
ドメイン名に対応する形で管理範囲を階層化する。サブドメインのゾーンを委任することで親子関係をつくる。
委任は、親のネームサーバーで委任先の子のネームサーバーの委任情報を登録することでおこなう。
ルートのネームサーバーから順にたどることで、ドメイン名のIPアドレスを取得できる仕組み。
DNSの通信にはTCPとUDPをサポートする必要がある。
ドメイン名の登録管理する組織。以下のような機能をもつ。
- レジストリデータベースの運用管理
- ポリシーに基づいた登録規則の策定
- 登録申請の受付
- Whoisサービスの提供
- ネームサーバーの運用
ドメイン名の登録者からの申請の取り次ぎ。レジストリとことなり、複数のレジストラが存在する。
登録者とレジストラを取り次ぐ「リセラ」という事業者も存在する。
TLDによってレジストラの役割も異なるが、おおよそ下記。
- 登録者からの登録申請の受付
- レジストリデータベースの登録依頼
- Whoisサービスの提供
- 登録者情報の管理
別称:DNSクライアント
利用端末で動作(OSに組み込まれている)、フルリゾルバに名前解決を依頼するDNSのクライアント。
リゾルバ自前実装してるnetパッケージ
別称:キャッシュDNSサーバー、参照サーバー、DNSサーバー
名前解決要求をスタブリゾルバーから受け付け、問い合わせを受けたドメイン名がキャッシュされている場合、スタブリゾルバにその結果を応答する。
存在しない場合、権威サーバーへ問い合わせを行う。問い合わせ結果である委任情報やIPアドレスをキャッシュする。
- ヒントファイル
ルートの権威サーバーの問い合わせ先はフルリゾルバー自身でもっている
初回の名前解決の前に読み込まれる。 - プライミング
最新のルートサーバーの一覧を得る仕組み
初回の名前解決時にヒントファイルを元にルートサーバーに問い合わせる
スタブリゾルバーとフルリゾルバーの間に配置され、問い合わせと応答を中継する。
利用メリット
- フルリゾルバー相当の機能を簡易的に実装できる
- ネットワーク内の利用者が使うフルリゾルバーのDNS設定を各端末で変更する必要がなくなる
- フォワーダーで一括で対応する
別称:権威DNSサーバー、ゾーンサーバー、DNSサーバー
委任を受けたゾーンの情報と委任しているゾーンの委任情報を保持するネームサーバー。
フルリゾルバーからの問い合わせを受けて、自分の保持する情報を応答する。
権威サーバーはゾーンの設定内容を「リソースレコード」という形式で保存している。
複数台の権威サーバーでフルリゾルバーからのアクセスを分散させる。
メインの権威サーバーを「プライマリサーバー」、ゾーン転送によりコピーされた権威サーバーを「セカンダリサーバー」と呼ぶ。
- DNS NOTIFY:プライマリサーバーでゾーンデータが更新された場合、セカンダリサーバーに通知する。
- ゾーン転送方法
- AXFR(Authoritative Transfer):ゾーンのすべての情報を送る
- IXFR(Incremental Transfer):特定のバージョンからの差分のみを送る

- リソースレコードセット(RRset)
- 同じドメイン名、タイプ、クラスでデータが異なる集合
- ゾーンファイル
- 権威サーバーが読み込むファイル。リソースレコードをまとめたもの
- code: ゾーンファイル
- example.jp. IN SOA (
- ns1.example.jp. ; MNAME
- postmaster.example.jp. ; RNAME
- 2021013001 ; SERIAL
- 3600 ; REFRESH
- 900 ; RETRY
- 604800 ; EXPIRE
- 3600 ; MINIMUM )
- example.jp. IN NS ns1.example.jp
- example.jp. IN NS ns2.example.jp
- ns1.example.jp IN A 192.0.2.11
- ns2.example.jp IN A 192.0.2.12
- example.jp. IN SOA (
リソースレコード
| 項目 | 説明 |
|---|---|
| ドメイン名 | 問い合わせで指定されたドメイン名。同じドメイン名の場合、2行目以降は省略可。 |
| TTL | Time to Live。リソースレコードのキャッシュ時間。 |
| クラス | ネットワークの種類。「IN」 |
| タイプ | 情報の種類。 |
| データ | リソースレコードのデータ |
| リソースレコードタイプ |
| タイプ | 内容 | 備考 |
|---|---|---|
| A | リソースのデータがIPv4アドレス | 委任情報としてネームサーバーのアドレス情報の登録(グルーコード) |
| AAAA | リソースのデータがIPv6アドレス | 上同 |
| NS | ゾーンの権威サーバーのホスト名 | ゾーン頂点に設定する場合とサブドメインの委任情報 |
| MX | ドメイン名宛の電子メールの配送先と優先度 | |
| SOA | ゾーンの管理に関する基本的な情報 | Start of Authority |
| CNAME | ドメイン名に対する正式名 | 例えばcdnのドメイン名を指定すると、名前解決をフルリゾルバがおこなう |
| TXT | 任意の文字列 | Sender Policy Frameworkなどなりすまし対策で設定したり |
| PTR | IPアドレスに対するドメイン名 | 逆引き用 |
| DNSKEY | 署名者が署名に使ったそのゾーンの公開鍵 | |
| RRSIG | 各RRSetに付加される電子署名 | |
| DS | 公開鍵のハッシュ値 | 親ゾーンに登録 |
| NSEC | 不在証明(存在するリソースレコードの一覧) | NSEC3/NSEC3PARAM |
| ドメイン名 |
| 絶対ドメイン名 | absolute domain name | TLDまで省略なく表記 |
|---|---|---|
| 相対ドメイン名 | relative domain name | ドメイン名を省略した表記 |
| 完全修飾ドメイン名 | FQDN | TLDまで含むドメイン名。ルートを含まない。 |
DNSメッセージは、DNSの問い合わせと応答に同じ構造が使われる。
フォーマット
Headerセクション
各種制御情報を含むヘッダ部
規定されたビット長で順番に並ぶ- Questionセクション
- 問い合わせるドメイン名や情報のタイプ
- Answerセクション
- 問い合わせしたドメインのリソースレコード
- Authorityセクション
- ゾーンの委任情報がある
- Additionalセクション
- 子の権威情報やDNSクッキーがはいってくる
-
dig/drill
- DNSの通信でやりとりされるDNSメッセージがセクションごとに出力される
- 名前解決要求のオプション
- フルリゾルバーに対しては名前解決要求が必要(再帰問い合わせ)
dig domain名
- 権威サーバーに対しては名前解決要求を無効にする(非再帰問い合わせ)
dig +norec domain名
- フルリゾルバーに対しては名前解決要求が必要(再帰問い合わせ)
- タイプを指定して問い合わせる
dig domain名 -t AAAA
-
- 共通のサービスIPアドレスを複数のホストで共有する仕組み
- RFC1546
- BGP - JPNIC
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
DNS関連攻撃 |
docs |
showa |
|
1 |
| 対象 | 帯域や容量 | プロトコルの脆弱性 | 運用側の問題 |
|---|---|---|---|
| DNSそのもの | ランダムサブドメイン攻撃 | ランダムサブドメイン攻撃 | BINDの脆弱性をついたDoS攻撃 |
| DNS利用者 | DNSリフレクター攻撃 | キャッシュポイズニング | ドメイン名ハイジャック |
DoS攻撃の一つ。
送信元IPアドレスを偽って問い合わせをフルリゾルバーや権威サーバーに送ることで、DNSが偽装された送信元IPに応答を返して対象のサービス不能に陥らせる。
- 通信にUDPをサポートしており、送信元IPを偽装した攻撃が成立しやすい
- 問い合わせ内容が応答にコピーされ応答サイズが大きくなるため、攻撃に使われやすい
- フルリゾルバーへのアクセスコントロールの実施
- 権威サーバーにRPL(Response Rate Limiting)を導入
権威サーバーやフルリゾルバーに対するDDoS攻撃のひとつ。
問い合わせのドメイン名にランダムなサブドメインを付与するkとdフルリゾルバーのキャッシュ機能を有効にさせずに、攻撃対象の権威サーバーに問い合わせを集中させ、サービス不能に陥らせる。
- 通常の利用と区別がつかないため、根本対策が難しい
- 適切なアクセス制限がされていないオープンリゾルバをなくす
- 利用者側が悪用されないようにIP53Bを実施する
- 利用者側で動作しているオープンリゾルバーを踏み台にした攻撃を防ぐ
- UDPの53番ポートをブロックすることでオープンリゾルバーへのアクセスをISP側で防ぐ
偽のDNS応答をフルリゾルバーにキャッシュさせることで、攻撃者の用意したサーバーに誘導する攻撃手法。
- カミンスキー型攻撃手法
- ソースポートランダマイゼーション
- スタブリゾルバーやフルリゾルバーに実装
- UDPの通信における問い合わせパケットのソースポート番号をランダムに変化させる
- 攻撃者が偽の応答を注入しづらくなる
- [DNSクッキー]
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
DNSSEC |
docs |
showa |
|
1 |
電子署名で応答の検証(正しいDNSからの返答か)ができる仕組み。
RRSetが署名対象のデータになる。署名者は署名済みのゾーンデータと、署名に使用した鍵ペアの公開鍵をゾーンデータとして権威サーバーで公開。
リゾルバーがバリデーターとなって署名の検証をおこなう。
DSリソースレコードの更新頻度をさげるために、DNSKEYリソースレコードを署名する鍵とRRSetを署名する鍵をわけて管理する。
- Key Signing Key(KSK: 鍵署名鍵)
- DNSKEYを署名するための鍵
- DSリソースレコードとして親ゾーンに登録する
- Zone Signing Key(ZSK: ゾーン署名鍵)
- 自分のゾーンの署名をする鍵
- ZSKのDNSKEYはKSKで署名する
そのゾーンで公開している公開鍵が信頼できることを親ゾーンの秘密鍵で署名し、公開すること(DSリソースレコード)で公開鍵の信頼性を担保する。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
EDNS0 |
docs |
showa |
|
1 |
UDPの限界である512バイトを超える大きなメッセージを扱うことができる拡張方式。 DNSのフラグや応答コードの拡張もできる。ESN0の情報は疑似リソースレコードとして、Additionalセクションに格納される。
サイズの大きなIPパケットをより小さな最大転送単位(MTU)を持つネットワークを通る場合、MTUを超えるIPパケットはそれ以下に断片化されて転送される。 ファイアウォールの種類や設定によっては断片化されたパケットを通さないことがある。 IPv6における最小MTUの1280からヘッダーを除いた1232バイトや、DNSSECでサポートする最小値の1220バイトで設定することが多い。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
QNAME minimisation |
docs |
showa |
|
1 |
(RFC 7816)
問い合わせ情報の最小化。
スタブリゾルバーから受け取った問い合わせをフルリゾルバーがそのままTLDの権威サーバーに問い合わせていた。
よって、TLDがクライアントの問い合わせ内容をしることができる。
QNAME minimisationは、プライバシーの保護の観点から、レベルドメインごとの権威サーバーにNSを問い合わせ、スタブリゾルバーが問い合わせたドメイン名とタイプは該当の権威サーバーにのみ問い合わせるように名前解決アルゴリズムを変更する。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Network |
docs |
showa |
|
8000 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
イーサネット |
docs |
showa |
|
1 |
主に室内や建物内でコンピュータや電子機器をケーブルで繋いで通信する有線LANの標準の一つ。
ハブやネットワークスイッチを中心として接続を集約するスター型を採用している。
初期のEthernetで用いられた半二重通信でアクセス制御方式。衝突を検出したら、ランダムな時間を待ってからフレームの再送を行う。
伝送できるパケットサイズの最小:46バイト、最大(MTU):1500バイト
- CSMA(搬送波感知多重アクセス):他の機器の通信を監視し、ある機器が送信を行っている最中は別の機器は送信を開始しない。フレームの送信が完了した後、次のフレームを送信を始めるには時間間隔を開ける必要がある。(フレーム感覚時間:IFG)
- CD(衝突検出):通信状況(電気信号の状況)を確認し、衝突発生を電気的に検出できるメカニズム。

イーサネット上でやりとりされるデータ。[OSI 7階層参照モデル]のデータリンク層に位置する。
- プリアンブル:フレームが始まることを表す制御用信号。同期信号のため、物理層に位置する。
- アドレス:宛先アドレスと送信元アドレスのビット列。送信元アドレスは、ネットワークインターフェースに割り当てられるMACアドレス。宛先アドレスは、宛先のネットワークインターフェースのMACアドレス。
- タイプ/長さ:1500以下の場合、データ長。1500より大きい場合、データのタイプを表す。
- データ部:「タイプ/長さ」にタイプが指定されている場合、伝送データがなくなったらフレームの末尾まで受信されたことを識別できる。
- LLC部:長さが指定された場合、データ部の先頭に管理情報がおかれる。
- エラーチェック:プリアンブルより後のデータ部までの情報から算術的に導出されたエラーチェック情報(CRC)。
1台ないし複数台のスイッチに接続されている多数の機器をグループに分け、複数のネットワークに分離する機能。
イーサネットフレームにVLAN IDを収めたタグを付加する。この情報に基づいてLANを仮想的に分割する方法。
VLANタグを含むイーサネットフレームの最大長は1522バイト。
VLANタグの構造
| タグ | バイト | 値 |
|---|---|---|
| TPIP(タグプロトコル識別子) | 2バイト | VLANタグであることを示す0x8100というタイプ情報。 |
| TCI(タグ制御情報) | ||
| 優先度 | 3ビット | 0~7 |
| CFI(正規フォーマット識別子) | 1ビット | 0 |
| VLAN ID | 12ビット | 0~4095 |
スイッチ内部にグループを設定し、MACアドレスを登録することでグループに登録された機器間でのみフレームの中継を行う。
スイッチのポート単位でグループを分けてネットワークを分離する。
ポートにID(VLAN ID)を割り当てて、同一のVLAN IDをもつポートのグループ内でのみ中継を行われる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
ICMP |
docs |
showa |
|
1 |
インターネットワークの管理や通知のためのメッセージを伝送するプロトコル。
ICMPで伝送するメッセージはIPデータグラムのデータ部に置かれる。
ICMPのエラー通知のICMPメッセージでエラーが起きた場合、ICMPメッセージを生成しない。

- 到達不可
- 到達不可メッセージが送信元に対して送られる。
- リダイレクト
- ホストが誤ったルーターにデータグラムを送信した場合、適切な中継先を送信元ホストに通知する。
- 時間超過
- IPヘッダのTTLが0になり、データグラムが破棄された場合に送信ももとに通知する
- エコー要求と応答
- pingで使われている応答要求
- 任意のデータとして大きなデータグラムを送ることでネットワークの負荷試験にも利用できる
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
IP |
docs |
showa |
|
1 |
イーサネットや無線LANなどの物理的なネットワークを相互に接続した通信を実現するためのプロトコル。
ネットワークインターフェース層に位置するMACアドレスは小規模なローカルエリアネットワークで通信を行うためのものであるため、複数のネットワークを前提とした通信を実現する。
IPを使うネットワークでデータをIPデータグラムというデータ構造に収めて伝送する。データの宛先と送信元を示すIPアドレスと管理情報が含まれる。
イーサネットフレームのデータとして収められてネットワークで伝送される。(タイプ:0800)

アドレス解決プロトコル(ARP)を使って、IPアドレスに対応するMACアドレスを取得する。問い合わせのイーサネットフレームをブロードキャストすることで、該当のホストが受信した場合は、MACアドレスを含めた応答を返却する。
ホスト上にIPアドレスとMACアドレスの対応表(ARPテーブル)で記録する。
IPデータグラムは最大で65535バイトになる。
イーサネット上のMTUより大きなサイズになるため、MTU以下のサイズに分割するフラグメントをおこなう。
分割した場合、各フレームがすべて到達しているかを検出したり、正しい順序で復元する必要がある。分割されたフレームには、分割もとのIPヘッダと分割に関する情報のヘッダが付与される。受信側はこの情報を使ってもとのデータグラムを再構築する。
また、ヘッダ中に識別子フィールドとしてごく短期間の間でのみ一意な値が付番される。この付番によって、送られてきたフラグメントされたIPデータグラムを識別する。

イーサネットのブリッジでは、イーサネットフレームワークの宛先MACアドレスで中継処理を行っていた。IPでは、インターネット層のプロトコルも認識してその情報をもとに中継処理を行う。
ネットワークインターフェース層の、送信元と宛先は中継するにつれて変化するが、インターネット層の送信元IPと宛先IPは変化しない。
- 同じネットワーク内の場合
- 送信元のARPテーブルから宛先IPアドレスに対応するMACアドレスをイーサーネットフレームの宛先にする
- 異なるネットワークの場合
- 送信元
- ARPテーブルからルーターへのMACアドレスをイーサーネットフレームの宛先にする
- ルーター
- 受信したIPデータグラムを確認し、自身宛でない場合、中継処理をおこなう。
- 処理にかかった時間をIPヘッダ中のTTLから減少させて、0になった場合破棄する。
- 中継処理:宛先IPアドレスを調べる。ルーターのもっているネットワークインターフェースのネットワークアドレスと比較して、一致する場合、フレームをルーター自身が持っているARPテーブルから宛先MACアドレスを所得する。そして、送信元MACアドレスがルーターのイーサネットフレームを送信する。
- 送信元

ルーターが1台しかないネットワークでは、自信宛か、それ以外のネットワーク宛かの判定だけできればよい。これを満たすようにルーティングテーブルを簡略化するための考え方。
自身宛でなければ、どの宛先のネットワークでも特定のルーターにおくるようにデフォルトゲートウェイを設定する。
OSI 7階層参照モデルのセッション層からアプリケーション層に相当します。プログラム間でどのような形式や手順でデータをやり取りするか定める。Webや電子メール等のアプリケーションプロトコルもこの層に属する。
OSI 7階層参照モデルのトランスポート層に相当する。通信を行うプログラムの間でデータ伝送を実現する。必要に応じて、エラーの検出と快復や双方向の通信路の確立なども行います。UDP, TCPはこの層のプロトコル。
OSI 7階層参照モデルのインターネット層に相当する。複数のネットワークを相互に接続した環境での、機器間のデータ伝送を実現します。IPはこの層のプロトコル。
OSI 7階層参照モデルのデータリンク層、物理層に相当する。ネットワークハードウェアが通信を実現するための層。各種イーサネット、無線LANなどがこの層に属します。
- リピーター
- スイッチ
- ブリッジ
| title | type | weight | lastmod | |
|---|---|---|---|---|
Links |
docs |
100000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
OSI 7階層参照モデル |
docs |
showa |
|
1 |
アプリケーションごとのデータの形式や処理の手順などを規定します。Web、電子 メール、ファイル 転送 などのプロトコル は、この層で規定されます。
データの表現形式、例えば文字コードの種類や暗号化などを扱います。双方の機器の間で文字コードが違う場合の変換、通信の暗号化と復号といった 処理はこの層で行われます。
クライアントとサーバーなど、プログラム間の接続手順を規定します。この層により、2つのプログラムの間でデータ交換を行う論理的な通信チャネルが用意されます。
実際にデータのやり取りを行うプログラムの間でのデータ伝送を実現します。エラーの訂正、データのブロックサイズの違いの吸収(大きなデータを小さなパケットに分割するなど)などはこの層で行います。
ネットワーク上の2 台のコンピュータの接続を確立します。
下位のデータリンク層と同じように見えますが、データリンク層が同じ方式を使った1つのネットワーク上の接続を確立するのに対して、ネットワーク層は相互に接続された複数のネットワークの間、つまりインターネットワークを定める。これらの複数のネットワークはそれぞれの形式は問わない。
イーサネット、無線LANなど、ネットワークの方式に基づいたメディアアクセス制御や実際のデータ伝送について規定します。それぞれのネットワーク式がどのように通信メディアを使ってデータを伝送すrの可を定めている。
実際のネットワーク媒体の上を流れる電気信号の形式やコネクタなど、個々のネットワーク方式ごとに規定する。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
QUIC |
docs |
showa |
|
1 |
キーワードだけ
-
Head of Lineブロッキング
-
0-RTT
-
Quic Indicator:chrome拡張でquicが利用されているか確認できる
-
QUICパケット
- QUICフレーム、ロングヘッダパケット、ショートヘッダパケット
- 終点コネクションID
-
ハンドシェイク
- CRYPTフレームに格納
- ハンドシェイクの最初にClientHello(鍵交換)とSYNを同時におこなう
- 2回目以降は事前共有鍵(PSK: Pre-Shared Key)を使うことで0RTTを実現する
-
ストリーム
- コネクション内で順番を守って配送されるバイト列
- 1つの要求と応答は1つのストリームとして扱われる
- 1つのコネクションでストリームは複数扱える
- コネクション内で順番を守って配送されるバイト列
-
コネクションの終了
- 一般的な終了
- CONNECTION_CLOSEフレームを送信
- 送信側はコネクションのほとんどの状態を消去し、受信側もパケットの送信をやめる
- 送信側が一定時間待つことで正常に受信されたと判断する
- 新しいパケットが送信された場合、暗号化されたパケットを再送する
- エラーで終了する場合
- QUIC起因ならCONNECTION_CLOSEフレームにコードと理由を含める
- アプリケーション起因ならフレーム型のフィールドがないCONNECTION_CLOSEフレームが利用される
- タイムアウト
- 一定時間パケットを受信しない場合、コネクションを終了できる
- ハンドシェイクの交渉で決定する
- リセット
- サーバーの再起動でコネクションを継続しようとした場合、タイムアウトまで待つ必要がある
- 任意のパケットから生成するステートレス・リセット・トークンを使ってNEW_CONNECTION_ID フレームを使ってコネクションをリセットする
- 一般的な終了
-
フロー制御
- ストリームのフロー制御
- 受信者は、ストリームの受信可能累積バイト数をMAX_STREAM_DATAフレームに入れて送信者に伝えます
- コネクションのフロー制御
- ネクションの受信可能累積バイト数をMAX_DATAフレームに入れて送信者に伝えます
- ストリーム数の制御
- 1つのコネクションに対して作成してよい累積ストリーム数をMAX_STREAMSフレームに入れて送信者に伝えます
- ストリームのフロー制御
-
コネクションのマイグレーション
- TCPと異なり、IP、portが変更されてもコネクションIDを利用することで、コネクションを維持することができる
- コネクションを維持する機能のことをコネクションのマイグレーションと呼ぶ
- 制約
- マイグレーションできるのはハンドシェイクのあと
- マイグレーションできるのはクライアントだけ
- クライアントがIPの変化を検知して、乱数を含むPATH_CHALLENGEフレームを送信し、パス検証を開始
- サーバはパス検証に応答して乱数を含むPATH_RESPONSEフレームをクライアントに返す
- クライアントからPATH_RESPONSEフレームがサーバに返却された時点でパス検証を完了する
-
NATリバインディング
- クライアントとサーバの間にNATが存在する環境で一定期間パケットのやり取りがない場合、その通信の外向きのポートを削除する。その後に再度パケットのやり取りが発生した場合、NATが新たにポート番号を割り当てる。これをQUICではNATリバインディングと呼ぶ
- この場合、サーバ側がポートの変更を検知して、PATH_CHALLENGEフレームを送信してパス検証をおこなう
-
コネクションID
- コネクションを識別するための名前で、長さが8から20のバイト列
- あるコネクションに対するコネクションIDは、クライアントとサーバの両者がそれぞれ独立に名付ける
- 終点のコネクションIDには、相手が名付けたコネクションIDを指定
- 始点のコネクションIDには、自分が名付けたコネクションIDを指定
- あるコネクションに対して、ハンドシェイク時点では一対のコネクションIDが存在するだけですが、その後コネクションIDを増やせる。自分が新たに作成したコネクションIDは、NEW_CONNECTION_IDフレームによって、通信相手に伝えることができる。
-
パス検証
- クライアントのIPアドレスが正当だと判断できるまでのアドレス確認を「コネクション確立時のアドレス検証」と呼ぶ
- クライアントのIPまたはポートが変わったときのアドレス検証を「パス検証」と呼ぶ
- パス検証には、PATH_CHALLENGEフレームとPATH_RESPONSEフレームを使います。両者には、8バイトの乱数が格納されます。PATH_CHALLENGEフレームに収められた乱数と同じバイト列がPATH_RESPONSEフレームに格納されて戻って来れば、パス検証が成功です。
-
プライバシー
- TCPではIPやポートがかわったとき、通信を続ける場合、新しくコネクションを作り直していたため、新旧のコネクションが同じ通信だとはわからない
- QUICでは同じコネクションIDを使い続けた場合、同じ通信であることが明白になるため、変わったことを検知したら別のコネクションIDを使い始める
-
ヘッダ保護
- QUICではTCPのヘッダにあった情報をペイロードにいれて暗号化することで中間装置がパケットを解析できないようにしている
- QUICのヘッダ保護は、パケット番号に関連したフィールドをパケットごとにかわるマスクでXORをとることで結果の値を置き換えている
- マスクの生成
- クライアントからのInitialパケットにある終点コネクションIDからヘッダ保護用の鍵を生成する
- あるパケットに対して暗号化されたペイロードの一部を切り出してヘッダ保護用の鍵とともにマスクを生成する
-
増幅攻撃
- quicではハンドシェイクの際に証明書など大きなデータをやりとりするため、攻撃の標的になりうる
- 攻撃を緩和する規則として
- クライアントが送るUDPペイロードの大きさは1200バイト以上
- 0RTTの場合、PADDINGフレームで1200バイトになるように埋める
- リトライ機構があり、リトライトークンが渡された場合、IPが詐称されていない証拠になるので、パケットのサイズに制限はない
- クライアントが正当だと判断できるまでは、サーバの遅れるパケットのサイズは受け取ったバイト数の3倍まで
- クライアントが送るUDPペイロードの大きさは1200バイト以上
-
- TCPでも0-RTTでできる仕組みがある
- 2回目以降だと最初のSYNにデータも載せられる
- しかし、ネットワークの中間装置にパケットの中身をみて落とすような仕組みがあると使えない
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
TCP |
docs |
showa |
|
1 |
Transmission Controll Protocol
データが正しく伝送されることはIPデータグラムでは保証されていない。信頼性のある通信を実現するためのトランスポート層のプロトコル。
- 伝送中のエラーによるパケットの欠落時の再送処理
- 送信したパケットの順番保証
- 双方向通信のサポート
- ストリームでの通信
- UDPではデータグラム単位のため、送信データの組み立てや、受信後のデータの組み立てなど検討する必要がある。
- TCPでは、任意の長さのバイト列として受信できる
- パケットの分割や受信後の組み立てはTCPが実装されたネットワークソフトで管理されるため煩雑な手順が不要
- フロー制御
- 相手の処理能力に合わせて通信量が過大にならないように調整するフロー制御をもっている
- 3 way hand shakeは1往復分のレイテンシが発生
- スロースタートはすべての新規接続で発生
- スループットは現在の輻輳ウインドウサイズで制限される
- サーバーのカーネルのバージョンアップ
- cwndサイズを10に設定(RFC6928で推奨)
- アイドル後のスロースタートの無効化
- ウインドウスケーリングの有効化
- 不要なデータ送信を削除
- 送信データを圧縮
- 物理的にサーバーをユーザーの近くにし、ラウンドトリップを削減
- 既存のTCP接続の再利用
TCPのデータ伝送は、IPデータグラムにおさめておこなわれる。この個々のパケットのことをTCPセグメントと呼び、TCPヘッダとデータ部で構成される。
フラグメントされずに送信できるセグメントの最大サイズのことをMSSと呼ぶ。(イーサネットでは1460バイト)

- フラグ
- 通信を制御する情報。各ビットごとにフラグがきまっており、TCPの状態が設定されている
- SYN, ACK,FINなど...
- フラグは複数同時に建てることができるヨ
- 通信を制御する情報。各ビットごとにフラグがきまっており、TCPの状態が設定されている
- シーケンス番号
- 受信側がデータの連続性や欠落の有無の確認する情報
- コネクション確立時に初期値が決まり、送信データのサイズ分(バイト単位)増えていく
- 確認応答などでも加算される
- 確認応答番号
- ACKフラグがセットされたセグメントの確認応答番号には、次に受信すべきシーケンス番号が設定されている。
- 現在のシーケンス番号は初期値からわかってるので、受信したデータサイズから計算して次のシーケンス番号がわかる
- これは確認応答番号より前のデータは受信できたことを送信側に通知する番号
- コネクションが確立した後は、すべてのセグメントでACKがセットされているので、常に確認応答番号が設定されている
- 最大値(32bit)を超えた場合、0に戻る
- 「受信ウインドウサイズ」というパラメータで確認応答なしに一度に受け取れるデータ量を定められる
- ACKフラグがセットされたセグメントの確認応答番号には、次に受信すべきシーケンス番号が設定されている。
- ウインドウサイズ(rwnd)
- 受信できるバッファの空きサイズ
- データの送信側がACK時のこの空きサイズをみてバッファを溢れさせないように送信量を判断する
- 16bitしかないので、「ウインドウスケール」オプションで2のべき乗倍のサイズにスケールできる
- コネクションの確立
- コネクションのクローズ
- 片方のホストが突然ダウンなどで接続が切れた場合、クローズ処理がおこなわれない
- この場合、生きているホスト側のコネクションが残り続ける
- キープアライブを有効にするとデータの送受信がなくなったコネクションで、空のTCPセグメントが送信される
- 複数回ACKが返ってこない状態が続いたら、コネクションを強制的にクローズする
- コネクションの状態



データ受信側の容量を超過しないために調整させる仕組みの1つ。
ACKを受け取るごとにサーバー側がcwndのセグメント(=MSS)を指数関数的に増加させることで必要なウインドウサイズに調整していく。
- 輻輳ウインドウサイズ(cwnd)
- データ送信側がACKを受け取る前に続けて送信できるデータ量
- rwndとcwndの小さい方が適用される
- 初期設定は控えめな設定値(linuxはinitcwnd)
- 最大は輻輳しきい値を超えるか、パケロスが発生し輻輳回避アルゴリズムが制御する
- スロースタートリスタート(SSR)
- TCPの接続が一定時間アイドル状態だった場合、ネットワークの状態に変化がある可能性を考えて輻輳ウインドウサイズは初期化される
- HTTPキープアライブのような長期間アイドルが発生するような接続の場合、パフォーマンス影響が大きい場合、サーバー側のSSRを無効にすることが推奨されている
パケロスが発生するということは、ネットワークのどこかでパケットを捨てる必要があるほど混雑している。
これ以上のパケロスが発生しないようにウインドウサイズを調整することでパケロスを抑える。輻輳ウインドウサイズがリセットされると輻輳回避アルゴリズムはパケロスを最小化するためのウインドウサイズ拡大アルゴリズムを指定する。
リンク容量とエンドツーエンドの遅延の積。任意の時点における送信中未応答のデータの最大量。
送信か受信のどちらかが頻繁に停止して、送信したパケットに対するACKを待つ必要がある場合、接続の最大スループットが制限される。遅延なく送信するためには、データの送受信を継続できるほどウインドウサイズを十分に大きくする必要があるため、ウインドウサイズはパケットの往復時間に依存している。
- 送信データの欠落
- 送信したセグメントがロストした場合、送信側は一定時間内にACKされなかったら再送する
- 途中のデータが欠落
- 複数のセグメントを送信したのに、ACKに含まれる確認応答番号が増えていない場合
- 3回同じ確認応答番号のACKが返却された場合、確認応答番号以降のデータを再送する
- 3回待つのは、受信した順序が入れ替わった場合も一時的に同じ状態になるため
- 重送
- 受信済みのデータを再送されて再び受信した場合
- 欠落したセグメントの再送や、ACKが欠落した場合に発生する可能性がある
- 受信側はデータは破棄するが、ACKは送信する
TCPがデータを送信するとき、まずプログラムからTCPの管理している送信バッファに書き込まれる。書き込まれたデータはOS側が非同期的にネットワークに送信していく。
受信側は反対にネットワークから受信したデータをOSがTCPが管理する受信バッファに書き込んでいく。
受信バッファに書き込まれたデータを読み出して受信プログラムに渡している。

TCPの再送処理などをするために複雑なバッファ管理が必要になる。このバッファ管理方法として伝送する一連のバイト列データの一部をスライドする窓でのぞくような形でバッファリングする手法。
⇛概要説明:TCP - 通信効率の向上 ( ウィンドウ制御 )
アプリケーションがバッファからデータを読み込むには必要なデータが揃うまで待機する必要がある。また、アプリケーションがソケットのバッファからデータを読み込むとき、TCPは単に伝送遅延と認識し、これをHoLブロッキングと呼ぶ。
Webサーバーなどは1つのウェルノウンポートで複数のコネクションを実現している。これは、クライアント側のソケットアドレスと組み合わせることで一意に識別している。
最初のSYNパケットでアプリケーションのデータ送信を開始できる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
UDP |
docs |
showa |
|
1 |
IPネットワークで接続されたホストコンピュータ上のプラグラムのプロセス間で、データの伝送を実現するトランスポート層のプロトコル。
コネクションレス型の通信で、伝送順序の保証やデータの欠損への対応を行わずに一方的にデータを伝送する。その分データの伝送コストを低減、遅延が少なくすむ。
コネクションレスなのでデータのサイズが1回の送信に収まるようにする必要がある。
プログラムのプロセス間の通信をおこなうため、プロセスを識別するポート番号を伝送されるIPデータに付加する。


| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Other |
docs |
showa |
|
100000 |
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Chrome Extension |
docs |
showa |
|
1 |
拡張機能は下記コンポーネントで構成されている
- background scripts
- content scripts
- options page
- UI elements
Manifest Fileとはその拡張機能に関する情報を書くものであり、json形式で書きます。 具体的にはその拡張機能の名前と説明、使用するスクリプトなどのパス、chrome.APIを用いる為のパーミッションの設定などを書きます。 拡張機能のルートフォルダにmanifest.jsonという名前で配置します。 マニフェストにスクリプトを登録すると、拡張機能に動作が通知される。
manifest.json
{
"manifest_version": 2,
"name": "Input Helper",
"version": "1.0",
"description": "Build an Extension!",
"permissions": ["activeTab", "declarativeContent", "storage"],
"background": {
"scripts": ["background.js"],
"persistent": false
},
"page_action": {
"default_popup": "popup.html",
"default_icon": {
"16": "images/user_group.png"
}
},
"options_page": "options.html",
"icons": {
"16": "images/alert.png"
}
}マニフェストのバージョン 3が今後主流になるけど、しばらく2だよ
- scripts: [読み込むファイル]
- persistent:
- true
- バックグラウンドで永続的に動作し続ける
- false
- 必要に応じて読み込むイベントページ
ツールバーの拡張のボタンを押下したときに表示するポップアップを設定できる。
- default_popup: *.html
- default_icon: {iconのpngを指定する(16, 32, 48,128)}
- ツールバー固有のアイコン
利用を許可するAPIを指定できる。
拡張機能のオプションページを設定できる。
オプションページのfaviconなどに設定される
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Cloud FunctionsでGraphQLを動かす |
docs |
showa |
|
1 |
gqlgenでイニシャライズする
go get github.com/99designs/gqlgen
go run github.com/99designs/gqlgen init直接ServeHttpを叩いて動かすようにしてみる
var srv *handler.Server
var play http.HandlerFunc
func init() {
srv = handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: &graph.Resolver{}}))
// /GraphQLHandlerを含めないとplaygroundのアクセス先がおかしくなる
play = playground.Handler("GraphQL playground", "/GraphQLHandler/query")
}
func GraphQLHandler(w http.ResponseWriter, r *http.Request) {
switch r.RequestURI {
case "/query":
srv.ServeHTTP(w, r)
case "/":
play.ServeHTTP(w, r)
}
}
Cloud BuildのAPIを有効化して、cloud functions APIを許可する
gcloud functions deploy graphql --runtime go116 --trigger-httpDeploy後のURLにアクセスしたらちゃんとPlayGroundが表示される

| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
faviconにカメラの映像をだす |
docs |
showa |
|
1 |
丸パクリ。Web でカメラを使おう – WebRTC (getUserMedia) on WebView 芳和システムデザイン
Denoでやることを諦めた。intervalが50ms以下だと書き込み不安定になるから動画ががたがたになる。
https://houwa-js.co.jp/exe/2019/06/20190604/
<html lang="ja">
<head>
<link id="favicon" rel="icon" href="">
</head>
<body>
<video id="player" hidden="hidden" autoplay></video>
<canvas id="snapshot" hidden="hidden" width="640" height="640"></canvas>
<script>
let player = document.getElementById('player')
let snapshotCanvas = document.getElementById('snapshot')
let width = snapshotCanvas.width
let height = snapshotCanvas.height
const elm = document.getElementById('favicon')
let startScan = function() {
let intervalHandler = setInterval(() => {
snapshotCanvas.getContext("2d").drawImage(player, 0, 0, width, height)
const imageDataBlob = snapshotCanvas.toBlob(function(blob){
const url = URL.createObjectURL(blob)
elm.setAttribute('href', url)
});
}, 50)
};
let handleSuccess = function(stream) {
player.srcObject = stream;
startScan()
};
navigator.mediaDevices.getUserMedia({
video: {facingMode: "environment", width: width, height: height},
audio: false
}).then(handleSuccess)
.catch(err => {
console.log(JSON.stringify(err));
});
</script>
</body>
</html>| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
画像処理 |
docs |
showa |
|
1 |
Microsoft Windows Bitmap Image
マイクロソフトとIBMがWindowsとOS/2にわかれる前のOSを共同で開発していた頃に作られた画像ファイル形式。圧縮の方法についても定義されているが、Windowsが標準では無圧縮のファイルを生成するため、他のアプリケーションにおいても無指定時は、圧縮はされていない場合が多い。
Graphics Interchange Format
ジフ。
Graphics Interchange Format(グラフィックス・インターチェンジ・フォーマット、略称GIF、ジフ)とはCompuServeのPICSフォーラムで提唱された画像ファイルフォーマットの一つ。LZW特許を使用した画像圧縮が可能。
GIFは256色以下の画像を扱うことができる可逆圧縮形式のファイルフォーマットである。圧縮形式の特性上、同一色が連続する画像の圧縮率が高くなるため、イラストやボタン画像など、使用色数の少ない画像への使用に適している。
Graphics Interchange Format - Wikipedia
Portable Network Graphics
ビットマップ画像を扱うファイルフォーマットである。圧縮アルゴリズムとしてDeflateを採用している、圧縮による画質の劣化のない可逆圧縮の画像ファイルフォーマットである。
画像の色モデルとして、最大16ビットのグレースケール、24ビットと 48ビットのRGB、または8ビットまでのインデックスカラーモード を利用することができる。透過についてはクロマキーによる透過指定、および8ビットから16ビットのアルファチャンネルをサポートする。また、画像に付属するテキストなどのメタデータやガンマ値なども画像ごとに記録できる。
Portable Network Graphics - Wikipedia
Joint Photographic Experts Group
一般的に非可逆圧縮の画像フォーマットとして知られている。可逆圧縮形式もサポートしているが、可逆圧縮は特許などの関係でほとんど利用されていない。
標準では、特定の種類の画像の正式なフォーマットがなく、JFIF形式(マジックナンバー上は、6バイト目から始まる形式部分にJFIFと記されているもの)が事実上の標準ファイルフォーマットとなっている。
Tagged Image File Format
ビットマップ画像の符号化形式の一種である。タグと呼ばれる識別子を使うことによって、様々な形式のビットマップ画像を柔軟に表現できる。
画像データを、解像度や色数、符号化方式が異なるものでも様々な形式で一つのファイルにまとめて格納できるため、アプリケーションソフトに依存することがあまり無いフォーマットであると言える。
Tagged Image File Format - Wikipedia
Scalable Vector Graphics
XMLベースの、2次元ベクターイメージ用の画像形式の1つである。アニメーションやユーザインタラクションもサポートしている。SVGの仕様はW3Cによって開発され、オープン標準として勧告されている。
SVG は、拡張の自由度が高い XMLで記述されており、XML ならではの各種機能を定義した要素を持つ。SVG ではそれ自身に回転・拡大・移動などの表現を定義しているため、単体で多様な表現をすることが可能である。
Scalable Vector Graphics - Wikipedia
合成元の画像に合成したい画像を特定の座標に転送すること。
特定の色を転送しない手法をカラーキー転送とよぶ。
線をひいてピクセル化したときにみためがジャギーになることをエイリアスと呼ぶ。
半透明色などでジャギーを改善する手法をアンチエイリアスという。
- スーパーサンプリング
アンチエイリアスとは?厳選6手法をご紹介します - SeleQt【セレキュト】|SeleQt【セレキュト】
画像の拡大率に合わせて元の画像からサンプリングすることで画像の拡大・縮小をおこなう。
このサンプリング方法によって、画像の品質や処理性能などがきまる。
- ミップマップ
- 予め解像度を落とした画像を用意しておくことで縮小時の計算処理量を削減する
- 縮小後の画像の品質がオリジナルからの縮小より低くなる
- 縦横比の異なるリップマップを用意することで画像の品質低下を抑えることもできる
- 二アレストネイバー
- 一番近いピクセルを選択するサンプリング手法
- バイリニア補間
- 最近傍の4pxを参照してピクセル色を計算するサンプリング手法
- バイキュービック補間
- 周囲16近傍のピクセルを参照したサンプリング手法
- 重み付けをしてピクセル色を計算する
RGBのヒストグラムの偏りを補正する処理。
ヒストグラムが偏りのない分布になるようにマッピングする。
中間色を中心に全体的に明るく(暗く)補正するフィルタ。
ガンマ補正に用いるパラメータをガンマ値と呼ぶ。
特定の範囲ごとに平均色をもとめてその範囲を平均色のピクセルにすることでモザイクをかけることができる。
透明度付きの画像の場合、透明度を考慮しないと暗く滲んだようになるため注意。
モザイクフィルタとことなり、すべてのピクセルに平均処理が必要だが。縦方向と横方向それぞれ計算することで計算負荷を下げられる。
- ガウスぼかし
- ガウス分布を使ったぼかし処理で、中心を最大とした重み付けをしてぼかしの計算をおこなう。自然なぼかしになる。
dpi = 1 inch あたりのピクセル数。1 inch = 2.54cm
物理的なサイズを考える場合、DPIが必須。
パレットを参照するピクセル形式の総称。パレットの値をインデックスで指定するため。
写真では一番明るい場所を(255,255,255)としているため、明るさのレンジが広いものを表現しようとすると暗い部分が段階的に表現できなくなる。(逆光など)
精度の低下が起こらないように255以上の情報を含ませることができるフォーマット。
データ上でしか扱えないため、画面上に表示するためにトーンマッピングをすることで通常のRGBに収まるように圧縮する。
RGBのかわりに光の周波数をいくつかのバンドにわけて表現する方法。
MPEGなど動画データで使われる形式。Y=輝度、Cb=青色差、Cr=赤色差で表現する。
人間が色差について鈍感であることを利用するとCbCrを間引くことができ、データを圧縮することができる。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
nvmでなんかエラーでる |
docs |
showa |
|
1 |
nvm is not compatible with the npm config "prefix" option: currently set to "/home/shoma/.nodenv/versions/14.9.0"
Run `npm config delete prefix` or `nvm use --delete-prefix v14.16.0 --silent` to unset it.
shoma:~/dev/study/deno/practice$ npm config delete prefixbash起動時にエラーがでてくる悲しみ。
https://docs.npmjs.com/resolving-eacces-permissions-errors-when-installing-packages-globally
https://tutorialmore.com/questions-1118117.htm
この辺のことをやればできた。
npm confi set prefixでnpmのバージョンを指定する
npm config set prefix $NVM_DIR/versions/node/v14.16.0
理由としてはこれらしいけどよくわからん。
https://www.webprofessional.jp/beginners-guide-node-package-manager/
npmでグローバルなところにファイルを置く場合、root権限を保つ必要がある。 なので、いちいちsudoしてあげないといけないけど、それは問題あるべ。
グローバルなパッケージをインストールする場合のパーミッションの問題を回避するために、デフォルトのディレクトリを自分の権限があるディレクトリに変えてあげることでroot権限が不要になる。なので、これを変更してあげるためにprefixの変更をおこなって解決する。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
達人プログラマー |
docs |
showa |
|
1 |
ネガティブは伝染する。問題を無視することでチーム全体がその考え方に流され、問題が蓄積し破滅に向かう。 「割れた窓=悪い設計、誤った意思決定、品質の低いコード」を放置スべからず。
みずらからの利益を守る側ではなく、石のスープで要求を引き出すための変化する触媒になる。
ゆるやかな変化(機能の追加やパッチによる変更)に気づかずにゆであがってしまうカエルにならないために、本来の構想を忘れず俯瞰すること。
「Easier To Change」。良い設計は悪い設計より変更がしやすい。 いまつくってるものは本当にETCか問い続けよう!!
「Don't Repeat Yourself」。「知識」や「意図」の繰り返しをしない。 類似のコードのことを繰り返しと読んでいるわけではない。コードが表現している知識が異なれば同じ内容でも異なるコード。 ドキュメントとコード間の2重化も繰り返し。開発者間、開発組織全体に対しても同様に言える。
関係しないもの同士の影響を排除する。単機能で目的に合わせて独立した凝集度の高いコンポーネントを設計する。 自分でコントロールできない属性に依存しないように設計を心がける。
今まで作ったことのない目標に対して、小さなコンポーネント単位で動くものを少しづつ作り、成果物のフィードバックをもとに目標を修正して、機能追加や修正を繰り返す。 プロトタイプはシステムのゴールを見定めるための使い捨てのコードを作成するが、曳光弾型の開発では動作する最小限のシステムを構築する。プロトタイプは曳光弾を発射する前の諜報活動みたいなものである。
今までつくったものがないものやリスクを測定する必要のあるものに適用できる。 プロトタイプの核心は構築のために得られた学習の経験にある。 適用できるケースは以下のパターン
- アーキテクチャ
- 新機能の追加
- 外部データの構造や内容
- サードパーティのツールやコンポーネント
- パフォーマンス
- ユーザーインターフェースの設計
見積もりを正確にする一番の方法はプロジェクトを実際に経験することである。 要求から要件を洗い出し、リスクの分析、設計と実装、テストをおこない、ユーザーと検証をおこなう。 決まりをもとに見積もりと振り返りを繰り返して精度を高めていく。 象を1頭食べるには1くちずつ食べるしかないのだ。
作業内容やアイデア、学んだこと、落書きを記録する。
- 記憶より記録は確実
- アイデアを思いついたとき忘れないようにでき、今の作業に集中できる
- 書き留めることで新たな見識に気づける
完璧なソフトウェアはつくることはできない。自らの過ちに対しても防衛的であるべきだ。
Design by Concept。Effielという言語でモジュールの権利と責務を文書化する技法を提唱した。 処理を受け付ける条件は厳格に、終了後に確約する内容は少なくする。
- 事前条件:機能を呼び出すために満たすべき条件。呼び出し側の責務を定義
- 事後条件:機能が終了したときに機能が保証する内容
- 不変表明:処理終了後にクラスのメンバが不変であることを保証する
あり得ないなんてありえない。常に防衛的なプログラミングを心がける。 そして、エラーをにぎるのではなくエラーによって早めにクラッシュさせるべきである。
起こるはずがないなら、それをチェックしよう。 ただし、エラー検出のために追加したコードで振る舞いを変えてしまわないように気をつけよう。(ハイゼンバグ) Go言語ではassertのような機能はないので、コードコメントによって表明している。
ヘッドライトの視認距離より車の停止距離が長いときヘッドライトを追い越してしまう=見えないところに突っ込んでしまう。 ソフトウェア開発においても遠い未来に闇雲に前進せず、常にフィードバックを受けて軌道修正を加えながら見える範囲ですこしづつ進めるべし。 不確かな未来の予言に労力をかけるより、コードを交換可能なものにしておくことで柔軟に対処できるようにする。
Tell, Don't Ask. 別の関数でオブジェクトの内部状態を直接参照して更新すべきではない。オブジェクトの責務を考え、公開すべきメソッドを検討する。ドメイン知識の流出やカプセル化を守ることにつながる。
メソッドの呼び出しを連鎖させないこと。1ドットで完結させるべし。任意のオブジェクトが持っているプロパティやメソッドに対する仮定を最小にすること。ドットで繋いで参照すると結合度があがって変更影響が大きくなる可能性があるため、 ただし、言語がメソッドチェーンで処理を提供している場合は除く。
外部設定でアプリをパラメーターで変更可能にする。 YAMLやJSONで静的なものとして管理することもできるが、APIとして設定の詳細を隠蔽するほうがよりよい。(CaaS:Configuration as a Service)
- 複数のアプリケーションで設定の共有ができる
- 設定の変更の適用
- 専用のUIとして管理できる
- 動的に変更できる
共有メモリの同期をすることなく並行処理を実現する方法。個別の処理を定義されたアクターが処理を実行する。メッセージを受け取ったアクターが個別の処理を実行する。アクター間でメッセージを連携することで非同期に処理を実現する。
アクターモデルとアプリケーションアーキテクチャの関係 - nkty blog
本能に耳を傾けうまくいかなくなったら足をとめてみる。ゴムのアヒルに話しかけてみる。行動してみる。
Martin Fowlerのリファクタリングのヒント
- リファクタリングと機能追加を同時にしない
- リファクタリングより前にテストを十分に用意する。そして頻繁にテストを行う
- 局所的な箇所から変更とテストを行うことでデバッグの単位を減らす
テストができるコードを書く必要があるため、自然と疎結合を意識する必要がある。
契約(入力の条件)と不変性(処理によって変わらないこと)を使ってテストを自動化する。 プロパティベースのランダムなテストにより誤った仮定を検出する。 GoだとFuzzingを使えばできる。
- 攻撃界面を最小化
- 最小権限の原則を厳守
- デフォルトをセキュアなものにする
- 機密データの暗号化
- セキュリティアップデートをおこなう
本当の要求は相談者も把握していないため、分厚い仕様書をつくろうとしない。要求文書は計画のためにある。簡潔に記すことで相談者と開発者のフィードバックプロセスをまわしやすくする。
プロジェクトによって用語の意図が変わるため、1つの箇所でプロジェクトで使用する用語を定義する必要がある。整合性をもたせるためにすべてのスタッフがドキュメントにアクセスできる必要がある。
Agileはスタイルであって、決まったプロセスがあるわけではない。アジャイルソフトウェア宣言で明記された価値は、よりよい開発手法をみつけるための継続的な活動の中にある。アジャイルな方法で開発をするには、自分の立ち位置をきめて、目的に向けて最小の意味のある一歩をすすめ、評価する、フィードバックプロセスを回すことで継続的に改善をすることでアジャイルなチームになれる。
いつかやるは決して訪れない。チームの改善のための施策は必ずスケジュールを組む。
- システムのメンテナンス
- プロセスの振り返り
- 新しいテクノロジーの実験
- チームの学習とスキルの向上
方法論は背景にあるコンテキストがベースになっているため、方法に固執するのは無意味にである。自分たちにとって最適なものを取捨選択していく必要がある。
カーゴ・カルトに陥らないこと。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
VPNサーバーを立てる |
docs |
showa |
|
1 |
rasberry pi 3bにVPNサーバーを構築するぞい
https://www.raspberrypi.org/software/
なるよしなにイメージ作ってくれる便利ツールがrasberrypi公式から提供されているので、こいつを使ってSDカードにインストール!!!
あとはrasberrypi で読み終わるのをまつ
とりあえずローカルIP固定にしてリモートでいじれるようにしたい
ネットワークの設定でゲートウェイのIPみすってたのではまった
https://qiita.com/zen3/items/757f96cbe522a9ad397d#ip%E3%82%A2%E3%83%89%E3%83%AC%E3%82%B9%E3%81%AE%E7%A2%BA%E8%AA%8D
https://www.komee.org/entry/2018/06/12/181400
https://qiita.com/quailDegu/items/63114ba1e14416df8040#ssh%E3%81%AE%E8%A8%AD%E5%AE%9A
だいたいこの辺にかいているやつをやる
# ユーザー追加
sudo adduser shoma
sudo adduser shoma sudo
# ユーザーlock
sudo passwd -d ubuntu # passwordの削除
sudo passwd -l ubuntu
sudo passwd -l root# 鍵設定
ssh-keygen -t rsa -f hoge_rsa
ssh-copy-id -i ~/.ssh/id[/ rsa.pub ras]vpc # はじめてしった。便利。# 日本語にしまっせ
sudo apt install language-pack-ja-base language-pack-ja ibus-mozc
sudo update-locale LANG=ja_JP.UTF-8
echo $LANG
datehttps://my.noip.com/#!/account
no-ipにアカウントを作ってhostを取得する
現在のIPを設定するDdclientをインストールする
sudo apt install ddclient -y
https://deviceplus.jp/hobby/how-to-use-raspberry-pi-as-vpn-server/
PiVPNっていう簡単インストールツール君を使ってWireguardをインストールする
つなげられるようにするのにかなりじかんがかかった
原因は、アパートのルーターを使ってプライベートIPをふられているから、外にでようがなかった
とりあえず、グローバルIPサービスってのに課金してIPをもらってみる(1000円/月)
→グローバルIPもらって設定したらできた。
mackerelっていうモニタリングサービスを導入してみた。hatena がやってるらしい。日本製なのでよい。
サーバーにtoolいれてAPI key設定するだけでアプリケーションの登録ができちゃう
wget -q -O https://mackerel.io/file/script/setup-all-apt-v2.sh | MACKEREL_APIKEY='[API KEY]' sh

外形適当にcpuとメモリだけみてSlack通知するようにした。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
WSLでwhisper_micを動かす |
docs |
showa |
|
1 |
whisperをつかってリアルタイムの音声の書き起こしをするやつを動かす。
これ↓
マイクに話しかけた言葉を,リアルタイムにAIが認識(whisper, whisper_mic, Python を使用)(Windows 上)
sudo apt install -y portaudio19-dev python3-pyaudio
sudo apt install -y ffmpeg
gh repo clone mallorbc/whisper_mic
cd whisper_mic
# python --version
# 3.10.10
pip install -r requirements.txt
python -m pip install click
python -m pip install pyaudio# Windows側でpulseaudio起動する
.\pulseaudio.exe# うちのGPUではsmallが限界。
python mic.py --model small※WSL2でマイク入力をさせる
- Enabling sound in WSL | Memorandum!
- PulseAudioをコマンドラインで操作したときのメモ - Qiita
- WSL2で libcuda.so: cannot open shared object fileになる - Qiita
WSLでマイク入力させるのがたいへんだった。pulseaudioさえ設定すればwsl2側はwslgが有効なら適当に設定で問題なかった。(PULSESERVERのIP設定いらん。)
あとは音声入力をlistenするときにphrase_time_limitを設定してあげないと永遠に待ちに入ってしまうのはよくわからん。ローカルで動かす分にはぼちぼち読み取ってくれるけど、実用できるかというと微妙。largeとか動かせるGPUがあれば精度いいのかな。
あと、何も言ってないと「ご視聴ありがとうございました。」が無限にでてくるのこわい。次回はおいしい食べ物紹介される…。

| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
PHP |
docs |
showa |
|
9000 |
PHP は、ほとんど全てが式であるという意味で、式指向の言語です。
sudo apt-get install software-properties-common
# PPAを有効化
sudo add-apt-repository ppa:ondrej/php
# PHP8以降が検索できるようになってる
sudo apt search php8.0-*https://getcomposer.org/download/
PHP の PSR-0 と PSR-4 で autoloader の違いと名前空間の基礎
宣言以降のブロックの挙動を指定できる。ticks,encoding, strict_typesが利用できる。
ticksだと、宣言した実行単位で、低レイヤーでイベントが発生するようになる。(式単位かな)そのイベントの間隔で任意の処理を挟むことができる。
static $i = 1;
$hoge = function () use (&$i) {
$i++;
};
register_tick_function($hoge);
declare (ticks=2) {
echo $i;
echo $i;// この後に$hogeが動作する
echo $i;
echo $i;
echo $i;
echo $i;
}
unregister_tick_function($hoge);ファイル読み込みの失敗時の挙動が異なる。
- require
- 致命的なエラーとなる
- include
- 警告となるが、処理は継続される
- 戻り値に読み込みの成否、もしくはreturnされた値が設定される
オートローダを登録することで明示的にクラスやインターフェースをincludeしていなくても、動的にクラスをロードする。
class ClassLoader
{
protected $dirs;
/**
* 登録したディレクトリをもとにオートローダにロードする関数を登録する
*/
public function register()
{
spl_autoload_register(function (string $class) {
foreach ($this->dirs as $dir) {
$file = $dir. '/' . strtolower($class) . '.php';
if (is_readable($file)) {
include $file;
return;
}
}
});
}
/**
* クラスファイルが格納されているディレクトリを登録
* @param string $dir ディレクトリ
*/
public function registerDir(string $dir)
{
$this->dirs[] = $dir;
}
}オブジェクトでない型をオブジェクトに変換したときに変換されるメンバやメソッドを持たない標準クラス。
PHP: オブジェクト - Manual
Q. yield fromっていつ使うの
Q. エラーハンドリング
php.iniでエラーの挙動の設定ができる
- error_reporting
- エラー出力レベルを設定します。
- display_errors
- エラーをHTML出力の一部として画面に出力するかどうかを定義します。
- デフォルト:stdout
- log_errors
- エラーメッセージを、サーバーのエラーログまたはerror_logに記録するかどうかを指定 します。
- error_log で定義した場所 (ファイルや syslog など) に書き出されます。
Q. thisの挙動
Objectになると自身のクラスのオブジェクトがバインドされる。
staticの場合、バインドされないので、staticじゃない関数とか呼ぶとthisにバインドされてなくてエラーになる。
Q. UnitTestのベストプラクティス
PHPUnitをつかうらしい
composer導入してLaravelと一緒でいいかな。
Q. file_get_contentsvs`cURL
APIなどにfile_get_contents()を使うのはオススメしない理由と代替案 - Qiita`
file_get_contents() はヘッダ情報の保持ルールやタイムアウト処理に癖があるため 返却されるステータスコードや、タイムアウト時に再リクエストなどを行うような 対APIの処理では、それらを知らないと想定していない事態に陥る。
Q. cURLについて
まんまPHPでcURLをたたける。ただのcURLなので、ヘッダーをパースしてくれたりとかは何もしてくれない。Do it yourself!!な感じ。
これを使ったライブラリをcomposerで取得して使う感じかな。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Composer |
docs |
showa |
|
1 |
aptやnpmのようなphp向けのパッケージ管理システム。ライブラリやプロジェクトの依存関係を管理する。
composer.jsonというファイルでプロジェクトの依存関係を記載し、composer.lockで依存するパッケージのバージョンを固定している。
Packagist.orgは、Composerのリポジトリ。Composerはなにも指定されていない場合、ここから入手可能なパッケージを自動的に検索し取得する。
sudo apt install php-curl
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');"
php -r "if (hash_file('sha384', 'composer-setup.php') === '756890a4488ce9024fc62c56153228907f1545c228516cbf63f885e036d37e9a59d27d63f46af1d4d07ee0f76181c7d3') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;"
php composer-setup.php
php -r "unlink('composer-setup.php');"
mv composer.phar /usr/local/bin/composerCommand-line interface / Commands
- init
- プロジェクトの初期設定としてcomposer.jsonを作成する
- self-update
- Composer自身を最新のバージョンのアップデートする
- install
composer.jsonをもとに依存関係を解決しながらvendorフォルダにパッケージをインストールするcomposer.lockが存在する場合、記載されたバージョンでインストールするreinstallってのをつかうと指定したパッケージをクリーンインストールできる
- remove
- 指定したパッケージを
composer.jsonから削除する
- 指定したパッケージを
- update
composer.lockに含まれるパッケージのバージョンを最新にする- packageを指定した場合、そのパッケージのバージョンをアップグレードする
- require
composer.jsonのrequireフィールドに追加してインストールする--devオプションを付けた場合、require-devフィールドに追加される- code:bash
- $composer require [package name]
- show
- 利用できるパッケージのリストを表示する
- パッケージを指定すると詳細を確認できる
--platformオプションを指定することでcomposerでインストールできないphpやphpの拡張機能を参照できる
- depends
- あるパッケージの他のパッケージの依存関係を確認できる
composer installやcomposer updateされた場合にインストールするバージョンをcomposer.jsonで指定する方法について
x.y.z- 固定のバージョン指定
x.y.**を指定した任意のバージョンの最新のバージョンを取得する- パッチバージョンで指定した場合、マイナーバージョン内で最新のパッチバージョンのパッケージを取得
- マイナーバージョンで指定した場合、メジャーバージョン内で最新のマイナーバージョンのパッケージを取得
^x.y.z- 指定したバージョンより最新のパッチバージョンのパッケージを取得
~x.y.x- 指定したバージョンより最新のマイナーバージョンのパッケージを取得
- require
- composer.jsonが配置されたプロジェクトが依存しているパッケージとそのバージョンを記載する
- autoload / autoload-dev
-
composerは
vendor/autoload.phpを生成し、ライブラリが提供するクラスなどをかんたんに利用できるようにしている -
自分のソースコードをオートローダーに追加したい場合、このautoloadフィールドに追加することで可能になる
-
exclude-from-classmapを設定することで特定のフォルダやファイルをクラスマップから除外できる"autoload": { "psr-4": { "Shoma\\Laratest\\": "src/" } },
-
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Laravel |
docs |
showa |
|
1 |
Symphonyベースのフルスタックなフレームワーク。
sudo apt install php-mbstring php-xml
composer global require laravel/installer
# $HOME/.composer/vendor/binにパスを通しておくと使えるyo
laravel new example-appバージョンアップ間隔
| 間隔 | Bug fix | Security fix | メモ | |
|---|---|---|---|---|
| メジャーリリース | 6ヶ月 | 7ヶ月 | 1年 | Laravel 9以前 |
| 1年 | 1年半 | 2年 | Laravel 9以降 | |
| LTS | 2年 | 2年 | 3年 | Laravel 6 2021/7/29時点 |
public/index.phpを起点にリクエストをパスルーティングして処理している。
サービスコンテナの実体 Illuminate\Foundation\Application
アプリケーションでよく使われる共通の機能の生成やインスタンスのキャッシュなどのインスタンスの管理をする役割を担う。サービスコンテナが生成やDIへの責任を持つため、利用側は設定や初期化などを気にする必要がなくなる。

{kind=link}
- バインド
- サービスコンテナに対してインスタンスの生成方法を登録する処理
- bind/bindf/singleton/instanceメソッドなどで登録する
- Providers/AppServiceProviderクラス内などProvidersにバインドを定義する
- 解決
- makeメソッドやapp関数を利用することで名前から解決したインスタンスを取得する
- Class名ならbindされてなくてもインスタンス生成は可能
- ただのリフレクションやん
- when/need/giveを利用すると注入先クラスによってサービスコンテナで解決するクラスを変更できる
- adminだったらこのクラス、userだったらこのクラスみたいに。
クラスメソッド形式でフレームワークの機能をかんたんに利用できる。
サービスコンテナをベースに実現されているらしい。
マジックメソッド__callStaticを使ってサービスコンテナで解決したインスタンスのメソッドを呼び、あたかもクラスメソッド形式で読んでいるようにみせている。密ですね。
ビジネスロジックの実行前にサービスプロバイダーが呼び出される
- サービスコンテナへのバインド
- イベントリスナーやミドルウェア、ルーティングの登録
- 外部コンポーネントの読み込み
registerメソッド⇛(任意)bootメソッドの順に実行して処理をおこなうよ
DeferrableProviderを実装するとサービスプロバイダーで呼び出されるまで読み込みを遅延させることができる。
Laravelのコアコンポーネントで利用されている関数をインターフェースで定義したもの。このコントラクトを実装したクラスでコアコンポーネントの差し替え(Providerで再バインド)が可能。
- HTTPクライアント
- guzzlehttp/guzzleをラップしたクライアント
- Laravel 7.x以降から導入された
- グローバルミドルウェア
- ルーターに登録されたコントローラの動作前に実行
- ルート情報を取り扱うような処理はおこなえない
- ルートミドルウェア
- ミドルウェアを特定のルートに指定したい場合に利用する
- Routeのmiddlewareメソッドで指定することができる
- ミドルウェアグループという形で一括でmiddlewareを指定できる形にもできる
LaravelのデフォルトのDocker開発環境を操作するためのCLI。Laravelのアプリケーションを構築するための出発地点を提供するよ。
> composer require --dev laravel/sail
# docker-composeを生成するよ
> php artisan sail:install
Which services would you like to install? [mysql]:
[0] mysql
[1] pgsql
[2] mariadb
[3] redis
[4] memcached
[5] meilisearch
[6] minio
[7] mailhog
[8] selenium
> ./vendor/bin/sail up -d
> alias sail="./vendor/bin/sail"
# コンテナのmysqlに直接アクセスできるコマンドも用意しているよ
> sail mysql| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
SAPI |
docs |
showa |
|
1 |
Webサーバーの違いを吸収してPHPの実行環境を利用可能する
Common Gateway Interface Webサーバー上でユーザープログラムを動作させる仕組み。 Webサーバーのプログラムから別のプログラムを呼び出し(プロセスの生成)、その処理結果をリクエストしたクライアントに送信する連携方法を取り決めた方式。
初回リクエスト時に起動したプロセスをメモリに保持し、次回リクエストで再利用することで、動作速度の向上とサーバー負荷の低減をおこなう。
Webサーバーのプロセス内でPHPを実行する。 サーバーを動かすユーザーで動作するため、セキュリティ面での問題。
FastCGI Process Manager 高度なプロセス管理
- 異なる uid/gid/chroot/environment でのワーカーの開始、 異なるポートでのリスン、異なる php.ini の使用 (safe_mode の代替)
- 標準出力および標準エラー出力へのログ出力
- opcode キャッシュが壊れた場合の緊急再起動
- 高速なアップロードのサポート
- "slowlog" - 実行時間が非常に長いスクリプトの記録 (スクリプト名だけでなく、PHP バックトレースも記録します。バックトレースを取得するために、 ptrace やそれと同等の仕組みを使ってリモートプロセスの execute_data を読みます)
- fastcgi_finish_request() - 何か時間のかかる処理 (動画の変換や統計情報の処理など) を継続しながら リクエストを終了させてすべてのデータを出力させるための特殊な関数
- 動的/静的 な子プロセスの起動
- 基本的な SAPI の動作状況 (Apache の mod_status と同等)
- php.ini ベースの設定ファイル
| title | type | weight | lastmod | |
|---|---|---|---|---|
Security |
docs |
10000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
GPG |
docs |
showa |
|
1 |
- 1. 公開鍵暗号とGPGの基本
- 第675回 apt-keyはなぜ廃止予定となったのか | gihyo.jp
- Dockerfile: 非推奨化されたapt-keyを置き換える|TechRacho by BPS株式会社
apt-keyの代替
curl -sSL キー取得元URL | gpg --dearmor -o /usr/share/keyrings/パッケージ名.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=キー取得元URL] debパッケージ取得元URL" オプション | tee /etc/apt/sources.list.d/パッケージ名.list > /dev/null| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
TLS |
docs |
showa |
|
1 |
Transport Layer Security Version: TLS1.0(RFC2246)、TLS1.1(RFC4346)、TLS1.2(RFC5246)、TLS1.3(RFC8446)
トランスポート層の通信のためのセキュリティ。
メッセージの転送 別のレイヤからわたされるデータのバッファを転送する。レコードは最大16364バイトのチャンクに分割される。 暗号化および完全性の検証 最初の接続のメッセージはネゴシエーションのために保護されない。ハンドシェイク後はレコード層による暗号化および完全性の検証がはじまる。 圧縮 2012年にCRIME攻撃に利用された。TLSの圧縮機能は利用されていない。 拡張性 Recordプロトコルが担うのはデータ転送と暗号処理のみで、サブプロトコルで機能の追加ができる。 HandShakeプロトコル、Change Cipher Specプロトコル、Application Dataプロトコル、Alertプロトコル
TLSで使うパラメータのネゴシエーションと認証をおこなう。(6~10のメッセージをやりとりする) Handshakeプロトコルのメッセージのヘッダにメッセージの種類とメッセージの長さをあらわします。 フルハンドシェイク クライアントとサーバーが一度もセッションを確立したことながない場合、TLSセッションを確立するために実行されるプロトコル。ハンドシェイクが完了したFinishedメッセージの送信から暗号化される。そのため、それまでの通信では平文でやりとりされる。 クライアント認証 サーバーから許容できるクライアント証明書が提示された場合、クライアントからCertificateメッセージを送ることでクライアント認証をおこないます。サーバー認証のあとにおこなわれます。 セッションリザンプション フルハンドシェイクによるメッセージの往復や証明書の検証など負荷の高い処理によるオーバーヘッドを回避する仕組み。 Session IDという識別子によってセッションを再開を可能にする仕組み。クライアントは以前のセッションを再開させるためにClient HelloメッセージにSession IDを含めて送信することで共有したマスターシークレットから新しい暗号鍵に移行してからFinishedメッセージを送り、暗号通信に移行します。これにより通信が1往復に省略される。 反対にクライアント側が状態をすべて保持するセッションチケット(RFC 5077)を利用する方法もある。 再ネゴシエーション
)をおこなう場合、鍵交換のパラメータの証明を一緒に送ることでクライアントはサーバーの検証を同時におこなえる。
よく利用される鍵交換アルゴリズム RSA (TLS1.3で鍵交換のアルゴリズムから廃止)クライアントがプリマスターシークレットを生成。サーバーの公開鍵で暗号化して転送して鍵交換をおこなう。ただし、秘密鍵が漏洩すると過去にわたってすべての暗号データが復号化されてしまう。
DHE_RSA(Ephemeral Diffie-Hellman) [PFS(Perfect Forward Security) https://kaworu.jpn.org/security/Perfect_Forward_Secrecy#:~:text=Perfect%20Forward%20Secrecy%20(PFS)と,鍵交換の概念です%E3%80%82]があり、クライアントとサーバー双方で共通鍵を決定する。RSAによる認証を合わせて利用する。処理速度が遅い問題がある。DH鍵交換には6つのDHパラメータを利用する。次回接続時にパラメータは再利用されないため、共有鍵が漏洩しても安全。このパラメータは乱数と一緒にサーバー側の秘密鍵で署名され、クライアントは検証された証明書の公開鍵でサーバーからきたものだと判別してから利用します。 証明書にパラメータを埋め込む方法もあるが、この場合生成される共有鍵が常におなじになるため、PFSがなくなる。
セキュリティの問題点
- 受動攻撃には安全だが、通信路で相手のフリをする能動的攻撃は受けてしまう。認証により守る必要がある。
- (TLS1.2)DHパラメータのネゴシエーションで生成するDHパラメータの強度を選択できないため、うまく受け入れてもらうことを期待するしかない(TLS1.2)
- (TLS1.2)重要性が無視され強度が不足したDHパラメータが利用されてきた。
ECDHE_RSA(Ephemeral elliptic curve Diffie-Hellman) or ECDHE_ECCDSA 楕円曲線暗号に基づく鍵交換アルゴリズム。処理が高速かつPFSがある。TLS1.2ではRSAかECDSAによる認証を併せて利用する。
TLS1.2ではストリーム暗号化方式、ブロック暗号化方式、AEAD(認証付き暗号)を利用できる。TLS1.3ではAEADだけ利用可能になった。暗号化アルゴリズムによって完全性(=改ざんされてないよね?)を検証する。 [暗号スイートとTLS拡張の関係を再整理 - Qiita https://qiita.com/kj1/items/ad98c124cb4fbc9b2cc7]
AEAD 暗号化および認証とデータの完全性の検証を提供する暗号方式。データの気密性だけでなくデータの改ざんを検知し、完全性を保証する。AES-GCMやChaCha20-Poly1305は現在主流となっているAEADアルゴリズム。 AEADアルゴリズムは、次の入力を受け取る。
- 鍵:共有された秘密鍵。
- プレーンテキスト:暗号化されるべきデータ。
- 関連データ:暗号化されないが、認証に使用されるデータ。例えば、ヘッダー情報など。
- ノンスまたは初期化ベクター:各暗号化操作に対して一意であるべき乱数。同じ鍵で複数回使用されることはない。 AEADアルゴリズムの出力は、暗号文と認証タグです。暗号文は暗号化されたデータであり、認証タグは送信者の正当性とデータの完全性を確認するために受信者が使用するバリューです。
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Web関連 |
docs |
showa |
|
1 |
セキュリティ関連のメモ
オンラインサービスを利用するユーザーがログイン状態を保持したまま悪意のある第三者の作成したURLなどをクリックした場合などに、本人が意図しない形で情報・リクエストを送信されてしまうことを意味します。 サービス提供者が考えるべき対策の一つに、どこから送られたリクエストなのか。このリクエストはユーザーが送ったものなのかを照合するシステムや、送信元のURLに対する照合、リクエストを送る時のパラメータに対する照合など、必要に合わせて適用し、脆弱性を排除しておくことが求められます。
ブラウザがオリジン(HTMLを読み込んだサーバのこと)以外のサーバからデータを取得する仕組みです。各社のブラウザには、クロスドメイン通信を拒否する仕組みが実装されています。れは、クロスサイトスクリプティングを防止するためです。
JSON Web Token(JWT)はHTTP認証ヘッダやURIクエリパラメータなどスペースに制約のある環境を意図したコンパクトな表現形式である。JWTの推奨される発音は, 英単語の"jot"と同じである.
- JWT draft
- Yahooにおける活用事例
- [JSON Web Tokenを理解する](https://scrapbox.io/fendo181/JWT(JSON[/ Web]Token)%E3%82%92%E7%90%86%E8%A7%A3%E3%81%99%E3%82%8B%E3%80%82)
- JWTについて簡単にまとめてみた
JWTでは、有効期限を短く設定することをお勧めします。WebSocketを使用している場合は、(たとえば)10分の有効期限でJWTを発行し、ユーザーがまだ接続してログインしている場合は8分ごとに自動的に新しいものを再発行することもできます。その後、ユーザーがログアウトするか切断されたとき。最後に発行されたJWTはわずか10分で無効になります(この時点で攻撃者にとってはまったく役に立たなくなります)。
共通鍵暗号アルゴリズムである。128ビット、192ビット、256ビットの鍵長が使える。
- [Wiki](https://ja.wikipedia.org/wiki/Advanced[/ Encryption]Standard)
Webサーバの HTTP Trace 機能と XSS を組み合わせて、クライアントの情報を盗む。
HTTP TRACEメソッドはHTTPヘッダも含めてすべての情報をクライアントに表示するデバッグの機能。この機能とXSSを組み合わせて、cookie情報やBASIC認証のパスワードなどを盗む。
タブナビング(Tabnabbing)とは、Webブラウザーのタブ表示機能を利用した[フィッシング http://it-words.jp/w/E38395E382A3E38383E382B7E383B3E382B0.html]の一種で、ブラウザーのアクティブでないタブの中身をユーザーが気づかないうちにSNSや銀行などの偽ログインページに書き変えてしまうという攻撃手法。
| title | type | weight | lastmod | |
|---|---|---|---|---|
Terraform |
docs |
101000 |
|
| title | type | weight | lastmod | |
|---|---|---|---|---|
Test |
docs |
11000 |
|
| title | type | weight | lastmod | |
|---|---|---|---|---|
Links |
docs |
100000 |
|
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
TypeScript |
docs |
showa |
|
100400 |
数値列挙、文字列列挙が可能 静的関数をもたせられる
enum Group {
Admin,
Member,
Guest
}
namespace Group {
export function idAdmin(group: Group): boolean {
switch (group) {
case Group.Admin:
return true
default:
return false
}
}
}TypeScriptに含まれるJavaScriptランタイムとDOMに存在するさまざまな一般的なJavaScriptを構成する機能のアンビエント宣言が含まれている。
- このファイルは、TypeScriptプロジェクトのコンパイルコンテキストに自動的に含まれます
- このファイルの目的は、JavaScriptやTypeScriptのプロジェクトで、すぐに型のサポートを得られるようにすることです
- 参考
typeof(組み込み型)やinstanceof(classのオブジェクト)で型の判定in演算子でオブジェクトのプロパティをチェックすることで型ガードできる- プロパティにあるリテラル型をチェックすることで型のチェックができる
- nullとundefinedのチェックは、
==null/!=nullでできる - コールバック関数内まで外側の型ガードの情報が有効にならない
- 変更されないことを保証する必要がある
type Foo = {
kind: 'foo', // Literal type
foo: number
}
type Bar = {
kind: 'bar', // Literal type
bar: number
}
function doStuff(arg?: Foo | Bar | null) {
if (arg == null) {
console.log("null or undefined")
return
}
if ('foo' in arg) {
console.log(arg.foo)
}
if (arg.kind === 'foo') {
console.log(arg.foo); // OK
} else { // MUST BE Bar!
console.log(arg.bar); // OK
}
}- ユーザー定義の場合、型ガード関数をユーザーで定義する
interface Foo {
foo: number;
common: string;
}
// trueの場合、`arg is Foo`で引数の型のヒントをあたえられる
function isFoo(arg: any): arg is Foo {
return arg.foo !== undefined;
}オブジェクト型のプロパティからUnion型を抽出する
type hoge = {
Neko: string
Inu: string
}
type animal = keyof hoge
let hoge: animal // type is Inu | Neko
hoge = 'Inu'型に[xx in yy]でプロパティ名にユニオン型を展開できる。
type animal = 'Cat' | 'Dog'
type names = {[a in animal]: string}
let n: names = {
Cat: 'Tama',
Dog: 'Pochi'
}実装がコンパイラの内部実装として隠蔽されていることを意味するキーワード。 構文を追加しないようにする工夫的なサムシングらしい。 TypeScript 4.1で密かに追加されたintrinsicキーワードとstring mapped types
| title | type | author | lastmod | waight | |
|---|---|---|---|---|---|
Zig |
docs |
showa |
|
1 |
version="0.11.0"
wget https://ziglang.org/download/0.11.0/zig-linux-x86_64-${version}.tar.xz && sudo rm -rf /usr/local/zig && sudo mkdir /usr/local/zig && sudo tar -C /usr/local/zig -xvf zig-linux-x86_64-${version}.tar.xz --strip-components 1 && rm -r zig-linux-x86_64-${version}.tar.xz
wget https://github.com/zigtools/zls/releases/download/${version}/zls-x86_64-linux.tar.gz && sudo rm -rf /usr/local/zls && sudo mkdir /usr/local/zls && sudo tar -C /usr/local/zls -xzf zls-x86_64-linux.tar.gz --strip-components 1 && chmod +x /usr/local/zls/bin/zls && rm -r zls-x86_64-linux.tar.gzZigのPeer Type Resolutionは、コンパイラが複数の値の型を比較して適切な共通型を導き出すためのメカニズムです。このプロセスにより、特にcomptime制約がある場合や型推論が必要な場面で、異なる型の値が一緒に使用される際に互換性を持たせることができます。
以下のように動作します:
- 異なる式が同じコンテキスト(例えば、条件演算子の両側のブランチや配列リテラルの要素)で使用されるとき、これらの式の戻り値の型は「peer」と見なされます。
- コンパイラはそれらの「peer」の間で互換性のある型を解決しようと試みます。例えば、整数リテラルが含まれている場合、これらは最も広い範囲を持つ符号付きまたは符号なしの整数の型に昇格することがあります。
- プログラマが型注釈を提供していない場合でも、Zigコンパイラは可能な限り最適な型を選択します。
- 解決が不可能な場合は、コンパイラはエラーを返し、プログラマに修正を求めます。
例として、次のような条件演算子があると考えましょう:
const a = if (condition) 10 else 20;ここで、10と20は整数リテラルです。Zigコンパイラはこれらのリテラルの型を解決するためにPeer Type Resolutionを使用し、aの型をi32として解決する可能性が高いです(i32はデフォルトの整数型です)。
Peer Type Resolutionの挙動はアップデートやZig言語のバージョンによって変更されることがあるので、具体的な挙動を知るためにはZigのドキュメントを参照したり、実際にコードを試したりすることが重要です。
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment