これまでの章で取り上げたデータ構造はロックやCAS等の同期プリミティブを使っている:
- 現在の種類
- これらを使って効率的なデータ構造を実装することは可能
- ただし欠点も多い
本章では既存の手法の問題点の検討と、新たに出てきた魅力的な代替案の検討を行う。
ロックは経験の浅いプログラマが嵌りがちなたくさんの欠点を備えている:
- 優先順位の逆転: 優先度低のスレッドが先にロックを取得してしまった場合に発生
- 護送: ロック保持スレッドがdescheduleされた場合(e.g. ページフォルト)に長い順番待ちが発生
- デッドロック: 複数のスレッドが共通のロック群を異なる順番で取得しようとした場合に発生
昔は専用のエキスパートプログラマをアサインすることで問題を回避していた:
- 今は高スケーラブルなアプリケーションがありふれているので、この方法では非効率過ぎる
問題の核心は、ロックに依存した巨大なシステムをどうやって組織するかを、誰も本当には知らないこと:
- ロックとデータの関係は、慣習によって確立されている
- プログラマの頭の中 or コメントドキュメント
- 図18.1. Linuxのヘッダファイルでのコメント例
- => メンテ大変
CASのようなアトミック操作を使えば(上述の)ロックの問題を回避できるが、こちらにも問題がある:
- 単一ワードに対してしかアトミックなread/writeが行えないのが問題の根幹
- アルゴリズムが、複雑/不自然/高オーバヘッド、になってしまうことがある
図18.2はロックフリーキューの例 (10章の実装の再掲):
- enqメソッド内で、
last.nextとtailの更新を別々のCASで行っているのが複雑- 片方だけ更新に成功した、という状態が生じえるため
- 両方一緒にアトミックに更新できたら楽なのに...
- 複数ワード対応版CASがあれば解決? (図18.3の
multiCompareAndSetメソッド)- 図18.4は上のメソッドを使ってenqメソッドを書き直したもの
- 関連する二つのフィールドの更新がアトミックに行えてだいぶシンプル!
- 残念ながら
multiCompareAndSetを現在主流のアーキテクチャで実現する自明な方法はない
- また仮に複数ワード対応CASがあったとしても、次に取り上げる問題の解決策にはならない
ロックやCASには「合成が容易に行えない」という主要な欠点がある:
- 例1: モニターを使ったロックキュー間の要素移動
- キュー0からキュー1に__アトミック__に要素を移したい(q0.deq -> q1.enq)
- 対象要素が一時的に消失したり、両方のキューに存在するのはダメ
- ロックはそれぞれのキューの内部に隠蔽されているので、両者を結合してアトミック転送を達成するのは不可能
- キュー0からキュー1に__アトミック__に要素を移したい(q0.deq -> q1.enq)
- 例2: 複数のロックキューを対象としたdequeue
- 二つキューがあるとして、両方が空の場合にだけdequeueメソッドを呼び出しをブロックさせたい
- いずれかが要素を保持しているなら、それを取り出す
- 条件変数はそれぞれのキュー内に隠蔽されているので、...以下同...
- 二つキューがあるとして、両方が空の場合にだけdequeueメソッドを呼び出しをブロックさせたい
- たいていはアドホックな解決策を見つけることは可能ではある:
- 例1なら、全体を大きなロックで囲ってしまえば良い。ただし、
- 並列ボトルネックになり得る (粗粒度ロックの典型)
- 二つのキューが一緒に使われることを事前に知っている必要がある (ロック漏れ防止は困難)
- キューな内部状態を公開して、利用者側でロックを管理するということも出来なくはないが、
- モジュラリティを破壊するし、インタフェースが複雑になる
- 利用者が複雑な慣習に従ってくれることに依存する
- ノンブロッキングキューだとそもそも実現不可能
- 例1なら、全体を大きなロックで囲ってしまえば良い。ただし、
従来の同期プリミティブの問題点の要約:
- ロックは効率的に管理するのが難しい。特に大規模システムでは。
- CASのようなアトミックプリミティブは、一度に一つのワード対して適用できずアルゴリズムが複雑になる
- 複数オブジェクトに対する複数呼び出しを、アトミックなものとして合成するのは困難
次節ではトランザクショナルメモリという新しいモデルを導入して、これらの問題に対する解決策を提案する。
用語:
- トランザクション:
- 一つのスレッドで実行されるステップ列
- 直列化可能でなければいけない
- ステップ列は一度に一つずつ、シーケンシャルに実行されているように見える
- 直列化可能性(serializability):
- 線形化可能性(linearizability)の粗い版
- 線形化可能性は単一のオブジェクト(のメソッド呼び出し)のアトミック性について定義
- 直列化可能性はトランザクション全体のアトミック性を定義する
- トランザクションの開始から終端のどこか一つに直列化点を有する
- トランザクション内では通常、複数のオブジェクトに対するメソッド呼び出しが行われる
Javaがトランザクショナルモデルの同期機構を備えているものとして話を進める:
- __atomic__キーワード:
- 囲んだブロックがトランザクショナルに実行される
- ネストしたatomicブロックは許容される (デッドロックしない)
- 図18.5. キューのenqメソッドの実装
- atomicキーワードがあれば、上で紹介した
multiCompareAndSet(複数ワード対応版CAS)は不要になる
- atomicキーワードがあれば、上で紹介した
トランザクションの特徴:
- 投機的に実行される:
-
- オブジェクト群に対して仮の変更群を適用
- 2-a. 最後まで他と衝突しなければ、変更がコミットされる (変更内容が正式に反映)
- 2-b. 他と衝突しているのであれば、変更はアボートされる (仮の変更群は破棄される)
-
- ネスト可能:
- モジュラリティのためにはネスト可能でなければならない
method() { atomic { b.method(); /* この中でatomicが使われているかどうかを気にする必要はない! */ } }- 親のトランザクションに影響を与えずにアボートできる場合に、ネストトランザクションは特に有用
- この特性は、後で条件付き同期について議論する際に重要
- __synchronized__と違ってネストしてもデッドロックする危険性はない
キュー要素のアトミック転送の例:
- 内部でモニターロックを使う実装では不可能 (前掲)
- トランザクションを使えば簡単! (図18.7)
条件付き同期の例:
- 図18.6: 上限付きキューのenqメソッド
- キューが満杯の場合は、以下の効果を持つ
retryキーワードを呼び出す- 「トランザクションをロールバック」=>「一時停止」=>「キューの状態が変わったら再試行」
- 条件付き同期は、親に影響を与えずにロールバックできると便利な例の一つ
- 条件変数を明示的に使う場合に比べて
lost wake-upバグが混入しにくいのが良い
複数の条件に待機する例:
- 条件変数群を内部で使用するモニターの実装では不可能
retryならそういった合成も簡単- 図18.8. 複数キューのdequeue待機の例
q0.deq()がretryを呼び出したら、orElseブロックが実行されるq1.deq()もretryを返したら、ステートが変わるまで待機して、変わったらリトライ- どちらかが成功するまで繰り返す
- ! ネストしたトランザクションは親トランザクションに影響を与えないといった話はどうなったのか?
- 以下のようなコードだったら納得できた
- or deq内ではatomicを使わずに、トランザクション内でdeqを実行するのは呼び出し元の責任にする?
- 以下のようなコードだったら納得できた
atomic {
x = q0.deq(); // これ自体はノンブロッキングで、キューが空ならnullを返す
if (x == null) retry;
} orElse {
x = q1.dep();
if (x == nulL) retry;
}章の残りの部分では、以下のトランザクショナルメモリの実装方法を探る:
- ハードウェアトランザクショナルメモリ(HTM)
- ソフトウェアトランザクショナルメモリ(STM)
まずはSTMから。
この節で扱うSTM:
TinyTMという名前のライブラリを実装する- 前節で取り上げたトランザクショナルメモリの機能を提供する
- 簡潔性のために以下の(重要な)機能はサポートしない
- ネストしたトランザクション、retry、orElse
STMには以下の二つの構成要素がある:
- トランザクションを実行する__スレッド__
- スレッド同士は、共有アトミックオブジェクトを通して通信を行う
- スレッドがアクセスする__オブジェクト__
- オブジェクトは以下の機能を提供する
- 同期: トランザクションは、別のトランザクションの未コミットな影響を見ることができない
- 復帰: アボートしたトランザクションの影響を巻き戻す
- オブジェクト(のフィールド)には常にgetter/setterメソッドを通してアクセスする
- トランザクショナルな同期や復帰処理を差し込めるようにするため
- オブジェクトは以下の機能を提供する
スキップリスト(14章)の実装を題材としてコンセプトを説明する。
図18.9はスキップリスト用のノードのインタフェース定義(SkipNodeクラス):
- 後で逐次版とトランザクショナル版の実装クラスを定義する(18.3.3以降)
- getter/setterを使っているのと配列が
AtomicArrayクラスになっていること以外には特筆すべきことはないAtomicArrayは通常の配列と機能的には等しいが、TinyTMが処理を挟めるように専用クラスにしている
図18.10と18.11は、STMを使ったスキップリストの実装:
- getter/setterが煩わしいのを除けば、逐次版の実装とほぼ同様
図18.12はトランザクションを実行するスレッドクラス(TTrhead)の実装:
- doItメソッドが
Callable<T>として表現されたトランザクションを受け取り実装するTはトランザクションの実行結果の型- 処理内容はコードの通り (トランザクション作成 => 実行 => validate => commit or abort)
図18.13はTThreadとSkipListSetを使って、スキップリストに要素を追加していく例:
- コードが煩雑だけど、要は「トランザクション内でスキップリストに要素を追加」しているだけ
以降ではTinyTMの実装の詳細を見ていく。
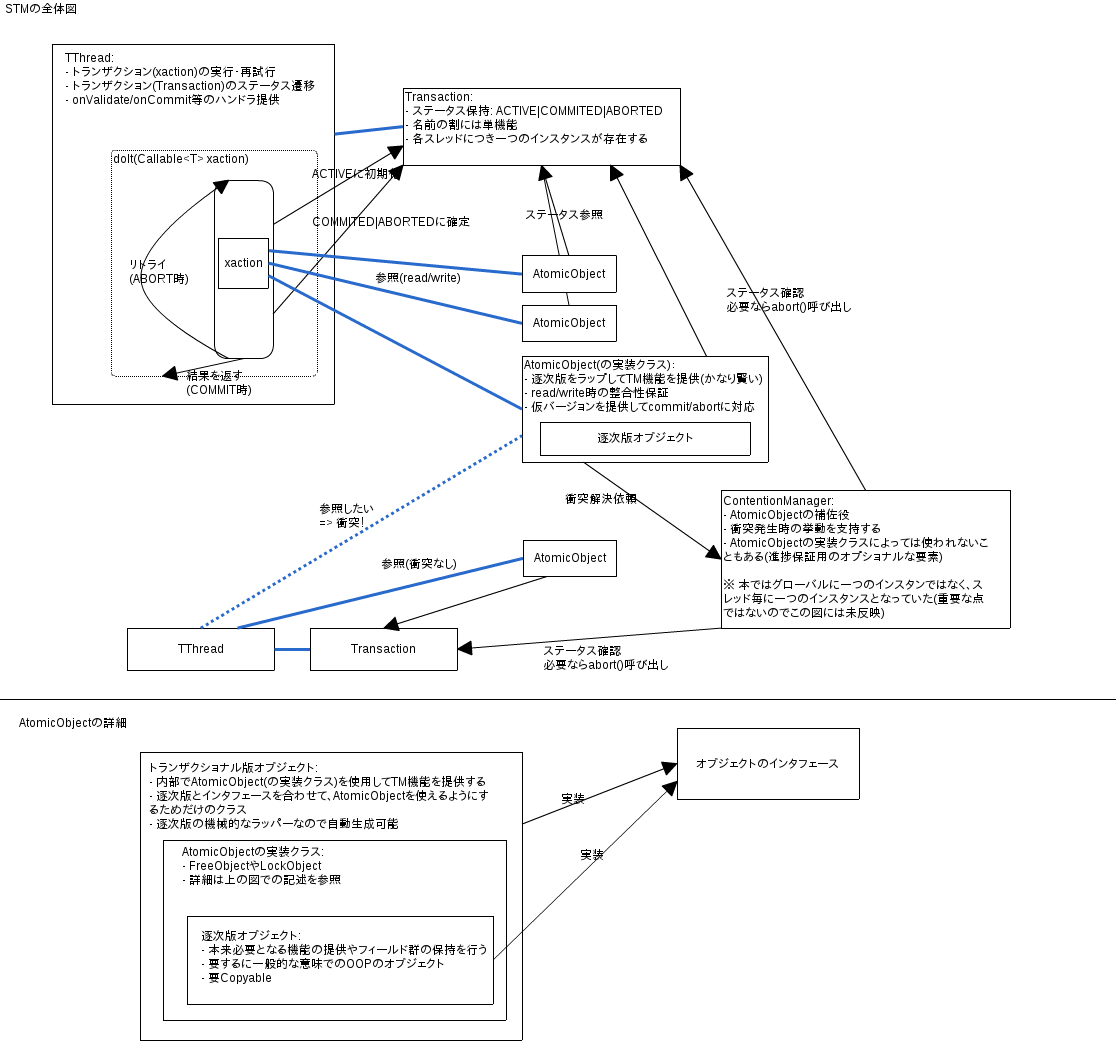
トランザクションのステータスはTransactionオブジェクトに隠蔽されている(図18.14):
- 三つのステータス: ACTIVE(初期値), COMMITED, ABORTED
- スレッドローカルなTransactionインスタンスを
localに保持しているlocalという名前だが、実質的にはスレッドスコープのグローバル変数
- ステータスに変更を加える時にはCASを使う (commit or abort メソッド)
- ACTIVE => COMMITED|ABORTEDへの変更は一方通行
トランザクショナルスレッドに関しては図18.12を参照 (! 既出なので省略)
ゾンビ:
- コミットが失敗することが確定した後も実行を継続しているトランザクションのこと
- 衝突発生時に、常に即座に、そのトランザクションの実行を中断できるとは限らないためゾンビは生まれ得る
- 重要なデザイン上の課題: ゾンビトランザクションが不整合な状態を見るのを避けるにはどうすれば良いか?
どうせコミットは最終的に却下されるので、不整合状態を問題としなければ良いのでは?
- 状況: 二つのトランザクションが
xとyという二つのオブジェクトにアクセスする - 逐次不変項:
y = x*2が常に成り立つ - 不変項が維持されないなら、以下のような許容できないケースが発生し得る:
- 致命的なエラー:
1/(x-y) - 無限ループ:
for (int i=x+1; i++ != y;) {}
- 致命的なエラー:
- 一般に、不変項が任意の地点で崩れる可能性があるなら、正しいプログラムを書くのは不可能
TinyTMはゾンビトランザクションでも、常に整合性のある状態を見ることを保証する
並列トランザクション群は共有のアトミックオブジェクトを通して通信する:
- 図18.15は、そのインタフェース(abstract class)
- 各メソッドの詳細は 18.3.6 で
- AtomicObjectを実装するには、オブジェクトの「逐次実装」と「トランザクショナル実装」の両方が必要
- コンパイラで自動生成もできるけど、今回は手で実装する
- 逐次実装に対する要求:
- getter/setterによるフィールドアクセス
- トランザクショナル版と逐次版を透過的に扱えるように
- より正確には両者が共通のインタフェースを実装する (e.g. SkipNode,SSkipNode,TSkipNode)
- 引数なしコンストラクタの提供、および、Copyableインタフェース (図18.16)の実装
- 各トランザクション内で機械的に、オブジェクトのローカルコピーを作成可能なように
- getter/setterによるフィールドアクセス
- 上の要求を除けば、逐次版の実装はSTMを考慮しない場合のクラス実装と同様
- 用語:
- バージョン: オブジェクトの(ある特定の)逐次版インスタンスのこと
図18.17はSkipNodeインタフェースの逐次版実装:
- 上の要求が反映された素直な実装
STMを実装する時には、どの進捗条件を採用するかを決定しなければいけない:
- 独立進捗(e.g. lock-free,wait-free)なSTMを作ることも不可能ではないが、現実的な効率を達成する方法は知られていない
- より保証が弱いけど効率的な、依存進捗での実装に焦点を当てる:
- ノンブロッキングSTMの場合は__妨害フリー__な実装
- 一つのスレッドだけが実行(スケジュール)されている状態での進捗が保証される
- 待機中の他のスレッドの影響(妨害)は受けないが、複数スレッドが並列に実行されている場合の進捗保証はなされない
- e.g. 二つのスレッドが延々と
abort => retryを繰り返すかも
- ロックベースSTMの場合は__デッドロックフリー__な実装
- クリティカルセクション内でスレットが停止した場合の進捗保証はない
- 細粒度ロックを活用すれば、その可能性は最小化される
- 妨害フリーと同様に複数の競合するスレッドが並列に実行された場合の進捗保証もない
- ノンブロッキングSTMの場合は__妨害フリー__な実装
弱い進捗保証だと(競合度が高い場合に)延々とリトライが繰り返されてしまうことはないか?
- トランザクションが競合した場合の進捗は__競合マネージャ__が保証する
- 競合解決メカニズムを提供し、(競合スレッド群内の)あるスレッドは確実に進捗するようにする
競合マネージャ:
- 同期衝突の発生を検出したトランザクション(要求者)は、競合マネージャに解決を求める
- 競合マネージャは、以下のいずれかを指示する:
- 他のトランザクションを即座にアボートさせる
- 他のトランザクションが完了できるように(要求者を)待機させる
- 要求者もいつかは進捗するように注意は必要 (e.g. タイムアウトを付ける)
図18.18は競合マネージャのインタフェース(ベースクラス):
- 競合を解決するためのresolveメソッドを提供する (abort or wait)
- スレッド毎に一つの競合マネージャが存在する
- ! TLS(グローバル変数もどき)を使い過ぎな感がある
衝突解決ポリシー(= ContentionManagerの実装クラス)にはいろいろなものがあり得る:
- 前提: トランザクションAが、トランザクションBと競合する直前にあるものとする
- バックオフ(Backoff):
- 待機時間を倍々しつつAをウェイトさせる。上限に達したらBをアボートする
- 優先順位(Priority):
- トランザクションの開始タイムスタンプの若い順に優先順位を付ける
- AがBよりも優先順位が高いならBをアボート、そうではないならAを待機
- リトライ時にはタイムスタンプが更新されないように気をつける (延々待機を防ぐため)
- 貪欲(Greedy): Bが待機中なら常にアボートする以外は
Priorityと同様 (待機チェインを防ぐ) - カルマ(Karma): 各トランザクションが達成した仕事量を記録し、それが多いものほど高優先にする
図18.19はバックオフポリシーを採用した競合マネージャの実装例。
直列化可能性(≒ 複数のメソッド呼び出しのアトミック実行)をどう保証するか:
- 各オブジェクトのトランザクショナル版は、図18.15の
AtomicObjectを内部で(適切に)使用するようにする - AbstractObject:
- トランザクショナルな同期や復帰を実現するための抽象クラス
- openReadメソッド: 読み込みに適したオブジェクトのバージョンを返す (i.e. getterのみ利用可)
- openWriteメソッド: 書き込みが行われるかもしれないバージョンを返す (i.e. getter/setter両方が利用可)
- validateメソッド: バージョンに整合性があるかを検証する (後述の
TSkipNodeでの使用例を参照)
AtomicObjectの実装クラスには、いろいろなものがあり得る- 今回は、妨害フリー版の
FreeObjectとロックベース版のLockObject、を見ていく
- 今回は、妨害フリー版の
図18.20はSkipNodeのトランザクショナル版実装(TSkipNode):
- AtomicObjectの実装クラスとしては
LockObjectを使っている - 内容としては
SSkipNodeの単純なラッパー - getNextメソッドの実装に注目(トランザクショナルなgetterの典型例):
-
- openReadを使って、バージョンを取得
-
- バージョンから取得した値(getNext())をローカル変数に保存
-
- validate()を呼び出して、2で保存した値の整合性が保たれていることを確認
- 以下を保証するために、呼び出し元に値を返す前には、常に呼び出される必要がある:
- 1と2の間にオブジェクトが変化していない
- 2で取得した値とトランザクション内の他の値の整合性が取れている
openRead.getHoge => save local => validate => returnは今後も頻出するパターン- ! 勝手に
open-read-save-validateパターンと呼ぶ
-
- setterも対称的な方法で実装される (! と書いてあるがこちらにはvalidate呼び出しはない)
残りでアトミックオブジェクトの実装を見ていく(簡潔性を重視、そこまで最適化はされていない)。
※ 並列読み込みを許可する方法に関しては読者の課題となっている
オブジェクトは三つの論理フィールドを持っている:
- owner: そのオブジェクトにアクセスした最後のトランザクション
- oldVersion: トランザクションが到着する前のオブジェクトの状態
- newVersion: トランザクションによる更新群が反映された(る)オブジェクトの状態
トランザクションAがアトミックオブジェクトにアクセスする際の処理:
- 定義: トランザクションBは、オブジェクトの一つ前のownerだとする
- オブジェクトにアクセスする場合、最初に以下のオープン処理を行う:
- owner/oldVersion/newVersionの値を、トランザクションのステータスに応じてセットする
-
- B=COMMITEDの場合:
- 前のトランザクションが完了(成功)しているので、
newVersionの値を採用する owner = A, oldVersion = newVersion, newVersion = copy(newVersion)- ※ openRead()の場合は、最後のコピーは不要
-
- B=ABORTEDの場合:
- 前のトランザクションがアボート(失敗)しているので、
oldVersionの値を採用する owner = A, oldVersion = oldVersion, newVersion = copy(oldVersion)- ※ openRead()の場合は、最後のコピーは不要
-
- B=ACTIVEの場合:
- AとBが衝突した
- 競合マネージャに解決を依頼する (Bのアボート or Aのウェイト)
- 結果に応じて1か2のどちらかを行う
- オープン後のオブジェクトへのアクセス方法は、前述の通り:
- open-read-save-validateパターン
- トランザクションの終了(COMMIT or ABORT)時に、オブジェクトのownerのステータスも確定する
図18.21は実行例(省略)
全てのトランザクションで整合性が保たれる理由:
- オブジェクトのownerは一人だけ、かつ、衝突により途中でownerが変わっても安全
- 読み込み時: open-read-save-validateにより担保 (不整合に繋がるowner変更を検出可能)
- 書き込み時: 常に(オープン時に)コピーされた新しいバージョンに対して行われるので、同じバージョンに対する書き込み競合は発生しない
トランザクションが直列化可能である理由:
- トランザクションAが(ACTIVEから)COMMITEDになったとする:
- これはAがトランザクション内でアクセスした全てのオブジェクトのownerであり続けていることを示す
- 別のトランザクションが所有権を奪うには、まずAのステータスをABORTEDにする必要がある
- つまり、A以外に(Aが参照した)オブジェクト群にアクセスしたトランザクションは存在しないことを示す
- Aはオブジェクト群をアトミックに参照/更新出来ている (ので直列化可能)
- これはAがトランザクション内でアクセスした全てのオブジェクトのownerであり続けていることを示す
オブジェクトオープン時にはowner/oldVersion/newVersionの三つをアトミックに更新する必要がある:
Locatorクラスにフィールド群をまとめる(図18.22)- LocatorインスタンスにCASを適用することでアトミック更新を実現 (間接参照は増える)
図18.23はFreeObject.openWrite()の実装:
- 現在のトランザクションのステータスに応じて処理を分岐:
- COMMITEDの場合: トランザクション内ではないので、逐次版のオブジェクトを返す
- ABORTEDの場合: トランザクションがアボートしているので、即座に例外送出(AbortedException)
- ACTIVEの場合: トランザクション内なので、「概観」で説明されているオープン処理を実行する
- openReadメソッド: openWriteとほぼ同様 (newVersion準備時のコピーがなくなるくらい)
- validateメソッド: 現在のスレッドのトランザクションのステータスがACTIVEかどうかをチェックするだけ
妨害フリー版はやや非効率に見える:
- 書き込みの度にLocatorとバージョンのコピーが必要
- 読み込みの度に二つの間接参照(indirection)が必要となる
これらの問題を解決するために、この節ではロックベースの実装を紹介する:
- 短いクリティカルセクションを有する
- 多くのアプリケーションのread/write比は8/2程度なので、read時にはロックを不要にして最適化
基本方針:
- オブジェクトの読み込みを楽観的に行い、後で衝突をチェックする
- 衝突検出にはグローバルバージョンクロックを用いる (!長いので勝手にgv-clockと呼称)
- 全てのトランザクションで共有されるカウンタ
- 何らかのトランザクションがコミットされる度にインクリメントされる
- トランザクションもオブジェクトも、gv-clockから取得したタイムスタンプを保持している
- 衝突検出の流れ:
-
- トランザクション開始時にgvclockから、タイムスタンプを取得し、読み込みスタンプ(! t-rstamp)に保存
-
- オブジェクトに(読み込み)アクセスする時には、オブジェクトのタイムスタンプ(! o-stamp)をチェックする
o-stamp =< t-rstampが成り立つなら、そのオブジェクトは整合している- トランザクション開始後の別のトランザクションによって更新されていない
-
- トランザクションの終了時に、gv-clockをインクリメントする
- その値で、トランザクションの書き込みスタンプ(! t-wstamp)と更新行ったオブジェクトのo-stampを更新する
-
オブジェクトは以下のフィールドを持つ:
- stamp: そのオブジェクトへの書き込みを最後に行ったトランザクションのt-rstamp
- version: 逐次版オブジェクトのインスタンス
- lock: ロック
オブジェクトの実装の詳細:
- トランザクションはオブジェクト群へのアクセス(read/write)を__仮想的__に実行する
- どのオブジェクトも実際には更新されない
- 代わりにトランザクションは以下を保持する:
- スレッドローカルなreadセット: 読み込みが行われたオブジェクト群を記録する
- スレッドローカルなwriteセット: 書き込みを行う予定であるオブジェクト群を記録する
- 仮想的な書き込みが反映された仮の新バージョン群
- openRead()呼び出し時の動作:
-
- 対象オブジェクトがwriteセットに存在するかを確認し、存在するなら、その仮の新バージョンを返す
-
- 存在しないなら、オブジェクトがロックされているかどうかを確認する
-
- ロックされているなら同期衝突が発生しているので、トランザクションをアボートする
-
- ロックされていないなら、オブジェクトをreadセットに追加して、そのバージョンを返す
-
- openWrite()もほぼ同様:
-
- 対象オブジェクトがwriteセットに存在するかを確認
-
- 存在しないなら新しい仮のバージョンを作成して、writeセットに追加する
-
- writeセット内のバージョンを返す
-
- validate():
-
- オブジェクトの
stampがトランザクションのread stamp以下であるかを確認する
- オブジェクトの
-
- オブジェクトのタイムスタンプの方が大きいのであれば、衝突があるのでトランザクションをアボートする
-
- LockObjectのvalidate()メソッドは、値の整合性のみを保証するということを理解するのは重要:
- 呼び出し元がゾンビトランザクションではないことは保証しない
- 代わりに、トランザクションのコミット時には以下のステップを確実に踏まなければならない:
-
- writeセット内の全オブジェクトをロックする
- ロック順は任意だが、デッドロックを避けるためにタイムアウトを使用する
-
- CASを使ってグローバルバージョンクロックをインクリメントする (t-wstampにも保存)
- トランザクションがコミットされるなら、ここが直列化ポイントとなる (まだ失敗する可能性あり)
-
- トランザクションはreadセット内の各オブジェクトが他スレッドによってロックされていないことを確認する
- また、各オブジェクトの
stampがトランザクションのread stamp未満であることも確認する - このチェックをパスしたらトランザクションをコミットする
- 特殊ケースとしてトランザクションで
writeStamp = readStamp + 1が成り立つなら上のチェックは飛ばせる - 競合するトランザクションが存在しないことが確実なため
- 特殊ケースとしてトランザクションで
-
- トランザクションはwriteセット内の各オブジェクトの
stampを更新する (! write-stampの値で?要確認)
- ! ここで仮を正式にする?(実装を要確認)
- 更新が完了したらロックを解放
- トランザクションはwriteセット内の各オブジェクトの
- テストのいずれかが失敗した場合はトランザクションはアボートする(read/writeセットの破棄、ロックの解放)
-
図18.24は実行例 (口頭で軽く触れるかも)
トランザクション群はグローバルバージョンクロックをインクリメントした順で直列化可能
整合性が保たれてる理由(= トランザクション開始後のオブジェクトの更新を検出可能な理由):
- トランザクションAのt-rstampはトランザクションの開始時にgv-clockの値に更新される
- 読み込み対象のオブジェクトのo-stampの値がt-rstamp以下なら、トランザクション開始後に更新がなく、超えているなら更新あり
- 前者の場合には処理を続け、後者の場合にはアボートするので整合性は崩れない (open-read-save-validateパターン)
- 危ういのは、他のトランザクションのコミット処理(ロック有)と、オブジェクトの読み込み処理(ロック無)が重なった場合:
- validate()で
o-stamp =< t-rstampが成り立つけど、実はopenRead()後にオブジェクトが更新されていた、というケースがあり得る Bコミット中(t-wstamp更新) => C,D,Eがコミット => A開始 => Aがx.openRead() => Bコミット完了(update x.o-stamp) => Aがx.validate()B.t-wstamp = x.o-stamp < A.t-rstampが成り立つので、タイムスタンプの比較だけでは隠れた更新が検出できない
- validate()で
- 上のケースはopenRead()内等で、ロックが獲得されているかを判定することで、チェック可能なので整合性は崩れない
- ! それとは別に今の実装を見ると「versionは更新されたけど、stampはまだ古いまま(なので更新に気づけない)」という状態(不整合)が発生し得るように思える
直列化可能な理由:
- 主張: Aがxを読んで、後にコミットしたとするなら、xはAに読まれてからAがgv-clockをインクリメントするまでの間で変化していないはずである
- Aが、時間
tにxがunlockedであると観察したとしたら、その後のいずれの修正も、xにA.t-rstampよりも大きなタイムスタンプを与えるはずである - もし(Aが参照するオブジェクトを更新する)BがAの前にコミットしたなら、Aのバリデーションハンドラは次のいずれかを観察し、アボートするはずである
- xはBによりロックされている
- xのタイムスタンプは、A.t-rstampより大きい
- Aが、時間
図18.25. WriteSetクラスの実装:
- 本質的には単なるマップ
- オブジェクト => トランザクション内で使用される仮バージョン
- スレッド毎に異なるインスタンスを有する
- ! この章は無駄にスレッドローカルストレージを使い過ぎているような気がする (コードの可読性が...)
- マップに登録させている全オブジェクトのロックの獲得/解放も行える
ReadSetは単なるオブジェクトの集合なので詳細は割愛
図18.26. VersionClockクラスの実装:
- グローバルカウンタ(
global)とスレッドローカルなカウンタ(local)を保持する - readスタンプとwriteスタンプは同じカウンタ(
local)を共有しており、set時の動作だけが異なる- setReadStamp: globalの値をセット
- setWriteStamp: globalの値をインクリメントし、その結果をセット
図18.27. LockObjectクラスのフィールド定義:
- lock, stamp, version (節の冒頭で出てきた通り)
- メソッド群:
- 図18.28. LockObject.openRead()
- 図18.29. LockObject.openWrite()
- 図18.30. LockObject.validate()
- これまでの説明以上のことは特になし
図18.31と図18.32:
- TinyTMはハンドラをカスタマイズ可能になっている (図18.12)
- 図18.31. onValidateハンドラの実装
- 図18.32. onCommitハンドラの実装
- ここもこれまでの説明以上のことは特になし
ここまでで学んだことは?
- 一つのトランザクショナルメモリフレームワークで、二つの全く異なる種類の同期機構をサポート可能なことを見てきた
- 一つは妨害フリー、もう一つは短時間のロックを使ったもの
- このそれぞれは弱い進捗保証を提供する
- 競合マネージャに進捗保証を委ねている
- !
LockObjectでは競合マネージャを使っていないのではないか? - ! 特定のトランザクションが延々とリトライを繰り返すことはありそう (飢餓)
! STMの欠点が書かれていない
- すぐに思いつくこと(今回の実装に関して云えば)
- オーバヘッドが大きい(read/writeセット and indirection)
- 実装で工夫?
- 機械的な競合判定のために無駄が多いことがある (影響範囲が無駄に広く、長いトランザクションほどアボートしやすい)
- 本当に必要のないケースでもabortが走ることがある
- e.g. スキップリストなら、もう操作済みのノードが更新されても別に気にしない、とか(直前・直後のみが重要)
- リトライも先頭から
- トランザクションの粒度を気を付ける or 多段トランザクションを活用する?
- 本当に必要のないケースでもabortが走ることがある
- オーバヘッドが大きい(read/writeセット and indirection)
ここでは標準的なハードウェアアーキテクチャが「短命かつ小さなトランザクション」をダイレクトにサポート可能なことを示す:
- 高レベルかつ単純化されているけど、HTMデザインの主要な点は抑えている
- キャッシュ一貫性(cache-coherence)プロトコルに馴染みのない読者は付録Bを見ると良い
HTMの基本的な考え方:
- 現代的なキャッシュ一貫性プロトコルは、既にトランザクションを実装するのに必要な大半のことをしてくれている
- 同期衝突の検出及び解決 (between writers, and between readers and writers)
- メモリを直接更新する代わりに、仮の変更をバッファする
- よっていくつかの細部を変更するだけで良い
大半の現代的なマルチプロセッサは、各プロセッサに__キャッシュ__を備えている:
- 小さく高速なメモリで、大きく低速なメインメモリとの通信を避けるために使用される
- 各キャッシュエントリは__ライン__と呼ばれる隣接ワード群のグループを保持している
- アドレスをラインにマッピングする仕組みも備えている
シンプルなアーキテクチャを考える:
- 各プロセッサとメモリは__バス__と呼ばれるブロードキャスト媒体を通して通信する
- 各キャッシュラインは__タグ__を持っている
- タグはMESIプロトコルに準拠したステート情報を保持する
- MESIプロトコルはキャッシュ一貫性プロトコルの一つ
MESIプロトコル:
- 各キャッシュライン(のタグ)は以下のいずれかの状態にマークされている
- Modified: ラインが修正された。メモリに書き戻す必要あり。他のプロセッサとの共有なし。
- Exclusive: ラインは修正されていない。他のプロセッサとの共有なし。
- Shared: ラインは修正されていない。他のプロセッサもラインをキャッシュ(共有)しているかもしれない。
- Invalid: ラインが有意なデータを含んでいない
- 個々のload/store時の同期衝突を検出し、異なるプロセッサ同士が同じ共有メモリの状態に合意することを保証する
- プロセッサが
aというメモリアドレスをload/storeする場合: (! aは不要?)- そのリクエストをバスにブロードキャストする
- 他のプロセッサやメモリはそれを聴取する
- プロセッサが
- キャッシュ一貫性プロトコルの完全な説明は複雑なので、ここで関係する主要な遷移のみを書く:
- プロセッサがラインのloadをExclusiveモードで要求した場合:
- 他のプロセッサは、そのラインのコピーを全て破棄する
- もしラインの修正されたコピーを保持するプロセッサがいるなら、load前にメモリに書き戻されなければならない
- プロセッサがラインのloadをSharedモードで要求した場合:
- ラインのexclusiveコピーを保持する他のプロセッサはステートをsharedに変更しなければいけない
- ラインのmodifiedコピーを保持する他のプロセッサはload前にメモリに書き戻さなければならない
- キャッシュが満杯になったら、ラインを立ち退かせる必要がある
- ラインがsharedあるいはexclusiveなら、単に破棄する
- modifiedなら、メモリに書き戻される必要がある
- プロセッサがラインのloadをExclusiveモードで要求した場合:
次は、このプロトコルをトランザクションをサポートするように調整する。
! 要点書く: 要はトランザクションの途中状態をメモリに書き戻されたくないだけ
MESIプロトコロに対する変更点:
- 基本は同じ
- タグにトランザクショナルビットを追加する:
- 通常はセットされない
- 値がトランザクションの途中で、キャシュラインに乗った場合にだけセットされる
- このエントリは__トランザクショナル__という
- 以下を確実にするのが必要:
- 修正されたトランザクショナルラインはメモリに書き戻されない
- トランザクションがアボートしたら、トランザクショナルラインを無効化する
ルールの詳細:
- MESIプロトコルがトランザクショナルエントリを無効化したなら、トランザクションはアボートする
- このような無効化は同期衝突を表す (between two stores, or a load and a store)
- 修正されたトランザクショナルラインが無効化あるいは追い出された場合は、その値は(メモリに書き戻されずに)破棄される
- トランザクショナルな値は仮なものなので、云々、途中結果は破棄される
- キャッシュがトランザクショナルラインを追い出したなら、そのトランザクションはアボートする
- ラインはもうキャッシュ上に載っていないため、これ以上のプロトコルによる同期衝突検出が不可能になるため
トランザクションが完了したら、トランザクショナルラインは無効化ないし追い出しされることはない:
- コミット => ビットクリア
無効化や追い出しが発生したらトランザクションはアボートして、そのラインは無効化される。
このルールは、コミットとアボートがプロセッサローカルなステップであることを確実にする。
このスキーマはハードウェア上でのトランザクショナルメモリを正しく実装するが、明白な欠点や制限も多い:
- (ほぼ全てのHTM提言に共通だが)トランザクションのサイズがキャッシュサイズによって制限される
- 多くのOSは、スレッドをdescheduleする際にキャッシュをクリアする
- トランザクションの尺はプラットフォームのスケジュールquantumによって制限されてしまうかもしれない
- これらによりHTMは短く小さなトランザクションに一番適している
- 長いトランザクションが必要なアプリケーションはSTM(or HTMとSTMのコンビネーション)を使うべき
- HTMLはトランザクションがアボートした場合に、理由を返すのが重要:
- 同期衝突による場合には、リトライすべき
- リソース枯渇による場合には、リトライを諦めるべき
- ! ここまでは他のHTMにも共通しがちなこと
この特有のデザインは、いくつかの追加の欠点を持っている:
- 多くのキャッシュは__direct-mapped__:
- 一つのアドレスは、正確に一つのキャッシュラインにマッピングされる
- 同じキャッシュラインにマップされる二つのアドレスを使用するトランザクションは失敗することが運命づけられている
- いくつかのキャシュは__set-associative__:
- アドレスをK個のライン群にマッピングする
- 同じセットにマップされるK+1個のアドレスを使用するトランザクションは...
- (まれにある)__full-associative__なら大丈夫 (! ライン数の上限を超えなければ)
キャッシュ分割によって、この問題を緩和するいくつかの方法がある:
-
- 大きなdirect-mappedメインキャッシュと小さなfully-associatedな犠牲者キャッシュに分割する
- 後者はメインキャッシュからあふれたエントリ群を格納するために使用される
-
- 大きなset-assciatedなnon-transactionalなキャッシュと小さなfully-associativeなトランザクショナルなキャッシュに分割する
- いずれの方法の場合でも、キャッシュ一貫性プロトコルは、分割キャッシュ群の間での一貫性を扱えるように調整されなければならない
他の欠点は競合マネージャの欠如:
- トランザクションは相互に飢餓状態になり得る
- 同じキャッシュラインを使用するトランザクションAとBのload/store=>retryのループ
- ハードウェアレベル(一貫性プロトコルレベル)でもソフトウェアレベルでも対処は可能:
- ハードウェアレベル:
- プロセッサに無効リクエストの拒否や遅延を許可する
- ソフトウェアレベル:
- リトライにバックオフを導入する
- ハードウェアレベル:
HTMについてもっと知りたい人は章末注を見てね
省略