When I have multiple server instances deployed from the same repo, I prefer to keep track of them with local branches, especially when using multiple clouds services like heroku and openshift. This makes it really easy to merge features branches into a particular instance's deploy without ever bringing it into master, but still allow the inclusion of those commits into other instances after it folds into master.
So, I have master, which stays as the primary place to put new commits. I then split features branches off of master and then merged in when they are accepted.
% git checkout -b wicked-sweet-login-page
% vim static/teh_loginz.html
# coding happens… <tappa tappa tappa>
% git add $_
% git commit -m 'made the login page look BALLER'
% git checkout master
% git merge wicked-sweet-login-page
Here's a visual of this kind of branching from Pro Git (which is free to read online, by the way). If you haven't read it, it's certainly worth your time.
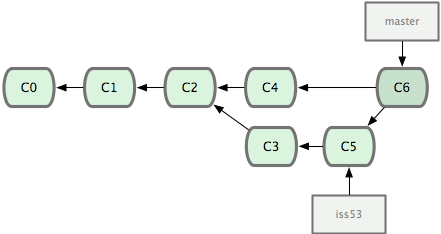
However, in non-trivial projects, not every feature should go to every instance immediately, and it might entirely skip the master branch and go directly to the development environment until it's accepted and merged to the staging server. For example a feature might get pulled directly into a dev branch to be deployed to myserver-dev.herokuapp.com, without ever touching myserver-stg.herokuapp.com or ever origin/master
% git checkout develpment-server-branch
% git merge my-test-feature
I can then push this particular branch to our development instance as the master branch on that instance by doing the following.
% git remote add development-remote git@heroku.com/myserver-dev.get
% git push development-remote development-server-branch:master
This way, each of the instances maintains a state that directly relates to local copies. Without dealing with the instance of the server in question, I can easily check where a server is at, and even run diffs against the remote if a feature was merged into the remote instance without actually being put into the appropriate branch first.
# wait… are we sure that's how it is in the live version?
% git diff origin/remote-feature-branch dev
# this won't work if your user doesn't have permission to access dev server repo
% git diff origin/remote-feature-branch dev/master
Admittedly, this is entirely unnecessary: it is completely possible to manage a whole slew of remote instances entirely on SHA hashes and intuition. I even have a pretty clever team most of the time, who are very good about keeping up with what features should be in what branches and what features should be on a given server. However, teams change over time, and projects get handed around. Keeping a record of where in a codebase's history each remote is at with a branch (aside from whatever other record-keeping the team is doing) gives an immediate reference point of where each server should be at, at the cost of a mere 40 bytes and a few extra extra shell commands. Centralized branches for deployments communicate to the whole team a clear boundary between what is deployed where.
Lastly, if you are using only heroku, they have a quick-start tutorial in their dev center on how to manage multiple server instances using their own tooling.