DDL is short name of Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database.
DCL is short name of Data Control Language which includes commands such as GRANT, and mostly concerned with rights, permissions and other controls of the database system.
DML is short name of Data Manipulation Language which deals with data manipulation, and includes most common SQL statements such INSERT, UPDATE, DELETE etc, and it is used to store, modify, delete and update data in database.
DQL is short name of Data Query Language which used for performing queries on the data within schema objects. The purpose of the DQL Command is to get some schema relation based on the query passed to it. SELECT statement is used to retrieve data from the database.
| Data type | Description |
|---|---|
| CHAR(size) | Holds a fixed length string (can contain letters, numbers, and special characters). The fixed size is specified in parenthesis. Can store up to 255 characters |
| VARCHAR(size) | Holds a variable length string (can contain letters, numbers, and special characters). The maximum size is specified in parenthesis. Can store up to 255 characters. Note: If you put a greater value than 255 it will be converted to a TEXT type |
| TINYTEXT | Holds a string with a maximum length of 255 characters |
| TEXT | Holds a string with a maximum length of 65,535 characters |
| BLOB | For BLOBs (Binary Large OBjects). Holds up to 65,535 bytes of data |
| MEDIUMTEXT | Holds a string with a maximum length of 16,777,215 characters |
| MEDIUMBLOB | For BLOBs (Binary Large OBjects). Holds up to 16,777,215 bytes of data |
| LONGTEXT | Holds a string with a maximum length of 4,294,967,295 characters |
| LONGBLOB | For BLOBs (Binary Large OBjects). Holds up to 4,294,967,295 bytes of data |
| ENUM(x,y,z,etc.) | Let you enter a list of possible values. You can list up to 65535 values in an ENUM list. If a value is inserted that is not in the list, a blank value will be inserted.Note: The values are sorted in the order you enter them.You enter the possible values in this format: ENUM('X','Y','Z') |
| SET | Similar to ENUM except that SET may contain up to 64 list items and can store more than one choice |
| Data type | Description |
|---|---|
| TINYINT(size) | -128 to 127 normal. 0 to 255 UNSIGNED*. The maximum number of digits may be specified in parenthesis |
| SMALLINT(size) | -32768 to 32767 normal. 0 to 65535 UNSIGNED*. The maximum number of digits may be specified in parenthesis |
| MEDIUMINT(size) | -8388608 to 8388607 normal. 0 to 16777215 UNSIGNED*. The maximum number of digits may be specified in parenthesis |
| INT(size) | -2147483648 to 2147483647 normal. 0 to 4294967295 UNSIGNED*. The maximum number of digits may be specified in parenthesis |
| BIGINT(size) | -9223372036854775808 to 9223372036854775807 normal. 0 to 18446744073709551615 UNSIGNED*. The maximum number of digits may be specified in parenthesis |
| FLOAT(size,d) | A small number with a floating decimal point. The maximum number of digits may be specified in the size parameter. The maximum number of digits to the right of the decimal point is specified in the d parameter |
| DOUBLE(size,d) | A large number with a floating decimal point. The maximum number of digits may be specified in the size parameter. The maximum number of digits to the right of the decimal point is specified in the d parameter |
| DECIMAL(size,d) | A DOUBLE stored as a string , allowing for a fixed decimal point. The maximum number of digits may be specified in the size parameter. The maximum number of digits to the right of the decimal point is specified in the d parameter |
| Data type | Description |
|---|---|
| DATE() | A date. Format: YYYY-MM-DDNote: The supported range is from '1000-01-01' to '9999-12-31' |
| DATETIME() | *A date and time combination. Format: YYYY-MM-DD HH:MI:SSNote: The supported range is from '1000-01-01 00:00:00' to '9999-12-31 23:59:59' |
| TIMESTAMP() | *A timestamp. TIMESTAMP values are stored as the number of seconds since the Unix epoch ('1970-01-01 00:00:00' UTC). Format: YYYY-MM-DD HH:MI:SSNote: The supported range is from '1970-01-01 00:00:01' UTC to '2038-01-09 03:14:07' UTC |
| TIME() | A time. Format: HH:MI:SSNote: The supported range is from '-838:59:59' to '838:59:59' |
| YEAR() | A year in two-digit or four-digit format.Note: Values allowed in four-digit format: 1901 to 2155. Values allowed in two-digit format: 70 to 69, representing years from 1970 to 2069 |
| Operator | Description |
|---|---|
| + | Add |
| - | Subtract |
| * | Multiply |
| / | Divide |
| % | Modulo |
| Operator | Description |
|---|---|
| & | Bitwise AND |
| | | Bitwise OR |
| ^ | Bitwise exclusive OR |
| Operator | Description |
|---|---|
| = | Equal to |
| > | Greater than |
| < | Less than |
| = | Greater than or equal to |
| <= | Less than or equal to |
| <> | Not equal to |
| LIKE ‘%expression%’ | Contains ‘expression’ |
| IN (‘exp1’, ‘exp2’, ‘exp3’) | Contains any of ‘exp1’, ‘exp2’, or ‘exp3’ |
In SQL, Wildcards are special characters used with the LIKE and NOT LIKE keywords which allow us to search data with sophisticated patterns much more efficiently
| Name | Description |
|---|---|
| % | Equates to zero or more characters. Example 1: Find all users with surnames ending in ‘son’. SELECT * FROM users WHERE surname LIKE '%son'; Example 2: Find all users living in cities containing the pattern ‘che’ SELECT * FROM users WHERE city LIKE '%che%'; |
| _ | Equates to any single character. Example: Find all users living in cities beginning with any 3 characters, followed by ‘chester’. SELECT * FROM users WHERE city LIKE '___chester'; |
| [charlist] | Equates to any single character in the list. Example 1: Find all users with first names beginning with J, H or M. SELECT * FROM users WHERE first_name LIKE '[jhm]%'; Example 2: Find all users with first names beginning letters between A–L. SELECT * FROM users WHERE first_name LIKE '[a-l]%'; Example 3: Find all users with first names not ending with letters between n–s. SELECT * FROM users WHERE first_name LIKE '%[!n-s]'; |
| Relational Algebra | SQL |
|---|---|
| Π𝑠(R) | SELECT DISTINCT s FROM R; |
| 𝜎𝗉(R) | SELECT * FROM R WHERE p; |
| R×S | SELECT * FROM R,S; |
| R-S | SELECT column(s) FROM R WHERE NOT EXISTS (SELECT column(s) FROM S); We can also use EXCEPT to achieve set difference. |
| R∪S | SELECT column(s) FROM R UNION SELECT column(s) FROM S; |
CREATE DATABASE dbname;DROP DATABASE dbname;List Available Databases:
SHOW DATABASES;You can run this to select/switch the current database to testDB:
USE testDB;In the below example, data passed to the id column must be an int, whilst the first_name column has a VARCHAR data type with a maximum of 255 characters.
CREATE TABLE users (
id int,
first_name varchar(255)
);Check if not exist and create
IF object_id('tbl_customer', n'U') IS NOT NULL DROP TABLE tbl_customer;
GO
CREATE TABLE tbl_customer ( id_customer INT NOT NULL PRIMARY key, fi_moral_nr INT, name VARCHAR(25) NOT NULL, vorname VARCHAR NOT NULL, wohnort VARCHAR );
GOAdds, deletes or edits columns in a table. It can also be used to add and delete constraints in a table, as per the above. Example: Adds a new boolean column called ‘approved’ to a table named ‘deals’.
ALTER TABLE deals
ADD approved boolean;Example 2: Deletes the ‘approved’ column from the ‘deals’ table
ALTER TABLE deals
DROP COLUMN approved;Alter an existing table and set the primary key to the first_name column.
ALTER TABLE stud
ADD PRIMARY KEY (first_name);Changes the data type of a table’s column. Example: In the ‘users’ table, make the column ‘incept_date’ into a ‘datetime’ type.
ALTER TABLE users
ALTER COLUMN incept_date datetime;Deletes a column from a table. Example: Removes the first_name column from the users table.
ALTER TABLE users
DROP COLUMN first_nameA foreign key can be applied to one column or many and is used to link 2 tables together in a relational database. As seen in the diagram below, the table containing the foreign key is called the child key, whilst the table which contains the referenced key, or candidate key, is called the parent table. This essentially means that the column data is shared between 2 tables, as a foreign key also prevents invalid data from being inserted which isn’t also present in the parent table.
It is optional. It specifies what to do with the child data when the parent data is updated or deleted. You have the options of RESTRICT (default), NO ACTION, CASCADE, SET NULL, or SET DEFAULT.
It specifies that the child data is deleted when the parent data is deleted. This is dangerous but can be used to make automatic cleanups on secondary tables.
It is used in conjunction with ON DELETE or ON UPDATE. It means that no action is performed with the child data when the parent data is deleted or updated.
It is used in conjunction with ON DELETE or ON UPDATE. It means that the child data is set to NULL when the parent data is deleted or updated.
It is used in conjunction with ON DELETE or ON UPDATE. It means that the child data is set to their default values when the parent data is deleted or updated.
ALTER TABLE orders
ADD FOREIGN KEY (user_id) REFERENCES users(id)
ON UPDATE CASCADE
ON DELETE SET NULL;
Create a new table and turn any columns that reference IDs in other tables into foreign keys.
CREATE TABLE orders (
id int NOT NULL,
user_id int,
product_id int,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (product_id) REFERENCES products(id)
);Alter an existing table and create a foreign key.
ALTER TABLE orders
ADD FOREIGN KEY (user_id) REFERENCES users(id);It creates a new constraint on an existing table, which is used to specify rules for any data in the table. Example: Adds a new PRIMARY KEY constraint named ‘user’ on columns ID and SURNAME.
ALTER TABLE users
ADD CONSTRAINT user PRIMARY KEY (ID, SURNAME);This constraint ensures all values in a column are unique.
Adds a unique constraint to the id column when creating a new users table.
CREATE TABLE users (
id int NOT NULL, name varchar(255) NOT NULL, UNIQUE (id)
);Alters an existing column to add a UNIQUE constraint.
ADD UNIQUE (id);Registers a new data type for use in the current database. The user who defines a type becomes its owner.
CREATE TYPE owntype FROM numeric(9,0)DECLARE @modification SMALLINT = 180;
DECLARE @new_sum INT;change password
ALTER LOGIN Mary5 WITH PASSWORD = '<enterStrongPasswordHere>' OLD_PASSWORD = '<oldWeakPasswordHere>';create
CREATE USER romulus FROM LOGIN romulusdrop
DROP user romulusAvailable permissions: CREATE DEFAULT, CREATE FUNCTION, CREATE PROCEDURE, CREATE ROLE, CREATE TABLE, CREATE TYPE, CREATE VIEW, DELETE, EXECUTE, INSERT, SELECT, UPDATE
Grant rights
GRANT SELECT, INSERT, DELETE, REFERENCES, UPDATE
TO alexRevoke
REVOKE INSERT, DELETE, REFERENCES, UPDATE TO alexCreate
CREATE ROLE verkaufAdd member
exec sp_addrolemember 'verkauf', 'anna'Grant rights
GRANT SELECT, UPDATE, INSERT, DELETE ON tbl_customer TO verkaufTo create a view, you can do so like this:
CREATE VIEW priority_users AS
SELECT * FROM users
WHERE country = ‘United Kingdom’;Then in future, if you need to access the stored result set, you can do so like this:
SELECT * FROM [priority_users];With the CREATE OR REPLACE command, a view can be updated.
CREATE OR REPLACE VIEW [priority_users] AS
SELECT * FROM users
WHERE country = ‘United Kingdom’ OR country=’USA’;To delete a view, simply use the DROP VIEW command.
DROP VIEW priority_users;Add new rows to a table. Example: Adds a new vehicle.
INSERT INTO cars (make, model, mileage, year)
VALUES ('Audi', 'A3', 30000, 2016);Delete data from a table.
Removes all users.
DELETE FROM usersTRUNCATE TABLE usersRemoves a user with a user_id of 674.
DELETE FROM users WHERE user_id = 674;This two keywords used to update the existing data.
SET used alongside UPDATE to update existing data in a table.
Updates the mileage and serviceDue values for a vehicle with an id of 45 in the cars table.
UPDATE cars
SET mileage = 23500, serviceDue = 0
WHERE id = 45;Updates the value and quantity values for an order with an id of 642 in the orders table.
UPDATE orders
SET value = 19.49, quantity = 2
WHERE id = 642;Used to select data from a database, which is then returned in a results set.
Selects all columns from all users.
SELECT * FROM users;Selects the first_name and surname columns from all users.xx
SELECT first_name, surname FROM users;Selects the first_name and surname columns where id is 2 AND has address.
SELECT first_name, surname FROM users WHERE user_id = 2 AND address IS NOT NULL;Used to select data from a database, which is then returned in a results set.
Returns all countries from the users table, removing any duplicate values (which would be highly likely)
SELECT DISTINCT country from users;To limit the number of rows returned by a select statement, you use the LIMIT and OFFSET clauses.
Returns the first three records from the "Customers" table, both queries are the same:
SELECT * FROM Customers
WHERE Country='Germany'
LIMIT 0,3;SELECT * FROM Customers
WHERE Country='Germany'
LIMIT 3 OFFSET 0Used to sort the result data in ascending (default) or descending order through the use of ASC or DESC keywords. Example: Returns countries in alphabetical order.
SELECT * FROM countries
ORDER BY name DESC;Returns true if the operand value matches a pattern.
Returns true if the user’s first_name ends with ‘son’.
SELECT * FROM users
WHERE first_name LIKE '%son';Returns true if the user’s first_name with ‘son’.
SELECT * FROM users
WHERE first_name LIKE '%son%';Returns true if the user’s first_name starts with ‘A’ or ‘B’ or ‘C’ and length of 4.
SELECT * FROM users
WHERE first_name LIKE '[^A-C]___';Returns true if a record DOESN’T meet the condition.
Returns true if the user’s first_name doesn’t end with ‘son’.
SELECT * FROM users
WHERE first_name NOT LIKE '%son';Change query output depending on conditions.
Returns users and their subscriptions, along with a new column called activity_levels that makes a judgement based on the number of subscriptions.
SELECT first_name, surname, subscriptions
CASE WHEN subscriptions > 10 THEN 'Very active'
WHEN Quantity BETWEEN 3 AND 10 THEN 'Active'
ELSE 'Inactive'
END AS activity_levels
FROM users;Used to join separate conditions within a WHERE clause. Example: Returns events located in London, United Kingdom
SELECT * FROM events
WHERE host_country='United Kingdom' AND host_
city='London';Used alongside WHERE to include data when either condition is true.
Returns users that live in either Sheffield or Manchester.
SELECT * FROM users
WHERE city = 'Sheffield' OR 'Manchester';Renames a table or column with an alias value which only exists for the duration of the query. Example: Aliases north_east_user_subscriptions column:
SELECT north_east_user_subscriptions AS ne_subs
FROM users
WHERE ne_subs > 5;SELECT north_east_user_subscriptions ne_subs
FROM users
WHERE ne_subs > 5;Selects values within the given range.
Selects stock with a quantity between 100 and 150.
SELECT * FROM stock
WHERE quantity BETWEEN 100 AND 150;Selects stock with a quantity NOT between 100 and 150. Alternatively, using the NOT keyword here reverses the logic and selects values outside the given range.
SELECT * FROM stock
WHERE quantity NOT BETWEEN 100 AND 150;CYCLING
| id | name | country |
|---|---|---|
| 1 | YK | DE |
| 2 | ZG | DE |
| 3 | WT | PL |
| ... | ... | ... |
SKATING
| id | name | country |
|---|---|---|
| 1 | YK | DE |
| 2 | DF | DE |
| 3 | AK | PL |
| ... | ... | ... |
Combines the results from 2 or more SELECT statements and returns only distinct values.
This query displays German cyclists together with German skaters:
SELECT name FROM cycling WHERE country = 'DE'
UNION
SELECT name FROM skating WHERE country = 'DE';UNION ALL The same as UNION, but includes duplicate values.
INTERSECT returns only rows that appear in both result sets.
This query displays German cyclists who are also German skaters at the same time:
SELECT name FROM cycling WHERE country = 'DE'
INTERSECT
SELECT name FROM skating WHERE country = 'DE';INTERSECT ALL The same as INTERSECT, but includes duplicate values.
EXCEPT returns only the rows that appear in the first result set but do not appear in the second result set.
This query displays German cyclists unless they are also German skaters at the same time:
SELECT name FROM cycling WHERE country = 'DE'
EXCEPT
SELECT name FROM skating WHERE country = 'DE';MINUS is the same as EXCEPT.
EXCEPT ALL The same as EXCEPT, but includes duplicate values.
COUNTRY
| id | name | population | area |
|---|---|---|---|
| 1 | France | 66600000 | 640680 |
| 2 | Germany | 80700000 | 357000 |
| ... | ... | ... | ... |
CITY
| id | name | country_id | population | rating |
|---|---|---|---|---|
| 1 | Paris | 1 | 2243000 | 5 |
| 2 | Berlin | 2 | 3460000 | 3 |
| ... | ... | ... | ... | ... |
AVG() - Returns the average value.
SELECT city_id, AVG(rating)
FROM ratings
GROUP BY city_id;COUNT(*) - Returns the number of rows.
Find out the number of cities with non-null ratings:
SELECT COUNT(rating)
FROM city;MAX() - Returns the largest value.
MIN() - Returns the smallest value.
Find out the smallest and the greatest country populations:
SELECT MIN(population), MAX(population)
FROM country;SUM() - Returns the sum.
Find out the total population of cities in respective countries:
SELECT country_id, SUM(population)
FROM city
GROUP BY country_id;FIRST() - Returns the first value.
LAST() - Returns the last value.
Find out the name of first customer in Customers table:
SELECT FIRST(CustomerName) AS FirstCustomer
FROM Customers;A subquery is a query that is nested inside another query, or inside another subquery. There are different types of subqueries.
The simplest subquery returns exactly one column and exactly one row. It can be used with comparison operators =, <, <=, >, or >=. This query finds cities with the same rating as Paris:
SELECT name FROM city
WHERE rating = (
SELECT rating
FROM city
WHERE name = 'Paris'
);A subquery can also return multiple columns or multiple rows. Such subqueries can be used with operators IN, EXISTS, ALL, or ANY. This query finds cities in countries that have a population above 20M:
SELECT name
FROM city
WHERE country_id IN (
SELECT country_id
FROM country
WHERE population > 20000000
);Used alongside a WHERE clause as a shorthand for multiple OR conditions. So instead of:
SELECT * FROM users
WHERE country = 'USA' OR country = 'United Kingdom' OR
country = 'Russia' OR country = 'Australia';You can use:
SELECT * FROM users
WHERE country IN ('USA', 'United Kingdom', 'Russia',
'Australia');NOT IN works exactly the opposite of IN .
Returns true if any of the subquery values meet the given condition.
Example: Returns products from the products table which have received
orders – stored in the orders table – with a quantity of more than 5.
The main difference between the ANY and IN keywords in SQL is that ANY allows for more flexible comparison operators, whereas IN only checks for equality.
SELECT name
FROM products
WHERE productId = ANY (SELECT productId FROM orders WHERE
quantity > 5);SOME is the same as ANY.
Returns true if all of the subquery values meet the passed condition. Example: Returns the users with a higher number of tasks than the user with the highest number of tasks in the HR department (id 2)
SELECT first_name, surname, tasks_no
FROM users
WHERE tasks_no > ALL (SELECT tasks FROM user WHERE
department_id = 2);A correlated subquery refers to the tables introduced in the outer query. A correlated subquery depends on the outer query. It cannot be run independently from the outer query. This query finds cities with a population greater than the average population in the country:
SELECT *
FROM city main_city
WHERE population > (
SELECT AVG(population)
FROM city average_city
WHERE average_city.country_id = main_city.country_id
);This query finds countries that have at least one city:
SELECT name
FROM country
WHERE EXISTS (
SELECT *
FROM city
WHERE country_id = country.id
);Checks for the existence of any record within the subquery, returning true if one or more records are returned.
Lists any dealerships with a deal finance percentage less than 10.
SELECT dealership_name
FROM dealerships WHERE
EXISTS (SELECT deal_name FROM deals WHERE
dealership_id = deals.dealership_id AND finance_percentage < 10);NOT EXISTS works exactly the opposite of EXISTS.
This query finds supplier numbers who supplied a part with quantity of at least 50:
SELECT spone.s# FROM sp spone
WHERE NOT EXISTS (SELECT sptwo.s# FROM sp sptwo
WHERE spone.qty < 50);Used alongside aggregate functions (COUNT, MAX, MIN, SUM, AVG) to group the results.
Find out the total population of cities in respective countries:
SELECT country_id, SUM(population)
FROM city
GROUP BY country_id;It’s used in the place of WHERE with aggregate functions.
Find out the average rating for cities in respective countries if the average is above 3.0:
SELECT country_id, AVG(rating)
FROM city
GROUP BY country_id
HAVING AVG(rating) > 3.0;WITH clause allows you to give a sub-query block a name (a process also called sub-query refactoring), which can be referenced in several places within the main SQL query.
Find all the cities that rating is more than the average rating of all cities.
WITH temporaryTable(averageValue)
AS (SELECT AVG(rating) FROM city)
SELECT id,name, rating FROM city, temporaryTable
WHERE city.rating > temporaryTable.averageValue;There are a number of different joins available for you to use:
- Inner Join (Default): Returns any records which have matching values in both tables.
- Left Join: Returns all of the records from the first table, along with any matching records from the second table.
- Right Join: Returns all of the records from the second table, along with any matching records from the first.
- Full Join: Returns all records from both tables when there is a match. A common way of visualising how joins work is like this:

JOIN (or explicitly INNER JOIN) returns rows that have matching values in both tables.
SELECT city.name, country.name
FROM city
[INNER] JOIN country
ON city.country_id = country.id;FULL JOIN (or explicitly FULL OUTER JOIN) returns all rows from both tables – if there's no matching row in the second table, NULLs are returned.
SELECT city.name, country.name
FROM city
FULL [OUTER] JOIN country
ON city.country_id = country.id;LEFT JOIN returns all rows from the left table with corresponding rows from the right table. If there's no matching row, NULLs are returned as values from the second table.
SELECT city.name, country.name
FROM city
LEFT JOIN country
ON city.country_id = country.id;RIGHT JOIN returns all rows from the right table with corresponding rows from the left table. If there's no matching row, NULLs are returned as values from the left table.
SELECT city.name, country.name
FROM city
RIGHT JOIN country
ON city.country_id = country.id;CROSS JOIN returns all possible combinations of rows from both tables. There are two syntaxes available.
SELECT city.name, country.name
FROM city
CROSS JOIN country;SELECT city.name, country.name
FROM city, country;NATURAL JOIN will join tables by all columns with the same name.
SELECT city.name, country.name
FROM city
NATURAL JOIN country;NATURAL JOIN is very rarely used in practice.
Run a transaction
START TRANSACTION;
SELECT @A:=SUM(salary) FROM table1 WHERE type=1;
UPDATE table2 SET summary=@A WHERE type=1;
COMMIT;
-- or rollbackThe database scheme consists of three tables:
S (S#, sname, city) SP (S#, P#, qty) P (P#, pname, color)
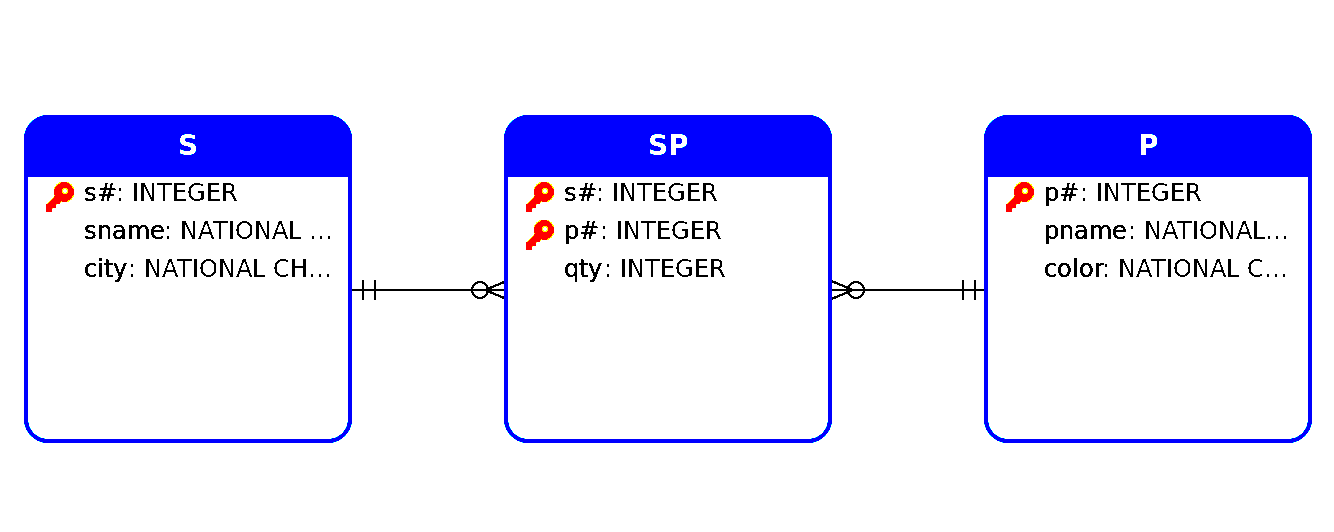
Let`s consider task:
Determine number of suppliers who have supplied all parts.
The keyword here is “all” which means that supplier numbers in SP table must have all part numbers (P#).
There is special operation for solving this type of tasks in the relational algebra. This operation is relational division (÷).
This operation makes solution of considering task very simple [1]:
SP[S#] ÷ P[S#]
The relational division operation is superfluous. It can be expressed by the complete set of the relational algebra. Perhaps, that`s the reason why it absents in the SQL.
This is division in relational algebra:
Let`s introduce three methods of implementation of relational division in SQL on considering example.
If suppose that there is only three types of part in table P, we may group data by supplier number and count quantity of their parts. Then we select only suppliers with quantity equal three. like this,
SELECT `s#`
FROM sp
GROUP BY `s#`
HAVING COUNT(`p#`) = (SELECT COUNT(`p#`) FROM p);SELECT DISTINCT `s#`
FROM s
WHERE NOT EXISTS (
SELECT `p#` FROM p
EXCEPT
SELECT `p#` FROM sp WHERE s.`s#` = sp.`s#`);This query may be rewritten in shorter form if we take into account fact that the ALL predicate returns TRUE if the subquery have no rows:
SELECT DISTINCT `s#`
FROM s
WHERE `s#` = ALL (
SELECT `p#` FROM p
EXCEPT
SELECT `p#` FROM sp WHERE s.`s#` = sp.`s#`);SELECT `s#`
FROM s
WHERE NOT EXISTS (SELECT `p#`
FROM p
WHERE NOT EXISTS (SELECT `p#`
FROM sp
WHERE s.`s#`= sp.`s#` AND p.`p#` = sp.`p#`));All solutions, except first one, are using correlation subquery.