Given a "book" and a string to search for, return an array of the character indices for every word in the book that begins with that string.
The book will contain two things: a book id and a string of English text. The search should be case insensitive.
Follow-up: consider the possibility of repeated searches through the same book.
const book = {
id: 1,
text: `Once upon a time, there was a book with words.
The book had not been catalogued, but would catch the
eyes of onlookers nonetheless.`
};
findWordsStartingWith(book, 'the'); // should return [ 18, 47, 97 ]
findWordsStartingWith(book, 'cat'); // should return [ 69, 91 ]A naive solution involves simply looping through the text. This solution is O(n * m), where n is the length of the text and m is the length of the prefix.
Interviewees may instinctively move to use includes, substring, indexOf, or to check the prefix against a slice of the text. This is fine in practice, but in an interview setting only serves to show that you happen to have read the docs, not that you understand how these methods work under the hood. Steer them away from this approach and towards something like the solution below.
function findWordsStartingWith (book, prefix) {
const text = book.text.toLowerCase();
prefix = prefix.toLowerCase();
const finds = [];
for (let i = 0; i < text.length - prefix.length; i++) {
if (i !== 0 && text[i - 1] !== ' ') continue;
for (let j = 0; j < prefix.length; j++) {
if (prefix[j] !== text[i + j]) break;
if (j + 1 === prefix.length) {
finds.push(i);
}
}
}
return finds;
}function findWordsStartingWith(book, prefix) {
const text = book.text.toLowerCase()
prefix = prefix.toLowerCase()
const finds = []
for (let i = 0; i < text.length - prefix.length; i++) {
if (i !== 0 && text[i - 1] !== ' ') continue
if (text.slice(i).startsWith(prefix)) finds.push(i)
}
return finds
}For repeated executions, pre-computing a trie would be extremely helpful.
A trie is a tree-like structure that stores successive prefixes of a word. They are also referred to as digital trees, radix trees, or prefix trees.


While expensive at setup, this solution yields dividends in repeated look-ups. Searching an existing trie is at most O(n), with n being the length of the prefix.
- Generally pronounced "trees"
- Used for re(trie)val
- Essentially a tree for storing strings
- Root associated with an empty string
- Each node is a character that points to the next
- All node descendants have a common prefix of the string associated with that node

- You could use sets or hash tables to search
- Tries shine when you're searching for words that have a single character difference or a prefix in common
- Tries can also be used to find a missing character
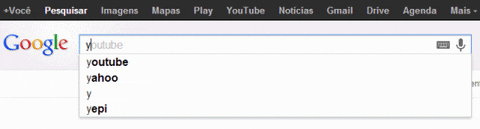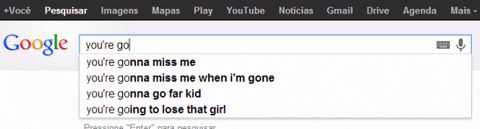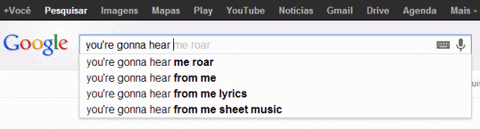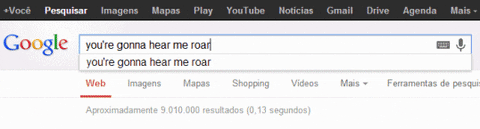
- Use case: Google search!
const tries = {};
function buildTrie (text) {
text = text.toLowerCase();
const trie = {}
for (let i = 0; i < text.length; i++) {
let node = trie;
const startsAt = i;
while (text[i] && text[i] !== ' ' && text[i] !== ',' && text[i] !== '.') {
const char = text[i];
node[char] = node[char] || {indexes: []};
node[char].indexes.push(startsAt);
node = node[char];
i++;
}
}
return trie;
}function findOrCreateTrie (book) {
if (!tries.hasOwnProperty(book.id)) {
tries[book.id] = buildTrie(book.text);
}
return tries[book.id];
}
function findWordsStartingWith (book, prefix) {
prefix = prefix.toLowerCase();
const trie = findOrCreateTrie(book);
let node = trie;
for (let i = 0; i < prefix.length; i++) {
const char = prefix[i];
node = node[char];
if (!node) return [];
}
return node.indexes;
}- Naive coding at first is fine!
- You can let them know the
idinbookis not really important for the naive approach if they seem confused about why it exists - Work on teaching them the concepts of tries and the build method
- Encourage drawing out the data structure
For more on tries: