This document is part-3 of the series of articles on scaling Bitcoin, I recommend reading part-2 on block propagation before continuing with this paper.
This paper takes a simple yet practical approach to building scalable software; puts to use the Fundamental Theorem of Software Engineering i.e. "We can solve any problem by introducing an extra level of indirection" & other often used software design paradigms. It is an attempt to derive a robust & scalable distributed system architecture which devolves crucial responsibilities to appropriate components. Although the new distributed node architecture is a departure from the legacy monolithic one, it ensures there is no impact to any of the consensus rules of the original Bitcoin protocol (Bitcoin SV).
The design that follows attempts to solve a number of issues; Parallel Transaction Verification & mempool acceptance, Parallel Block processing, UTxO set sharding, Parallel Merkle root validation among many other crucial items. In part-2 a novel high-compression low-latency block propagation protocol was introduced and it forms an essential component to the below architecture. Besides this paper introduces a couple of new concepts (perspectives) as well.
Performing well at scale typically involves multiple aspects i.e. horizontally scalable system, high availability, load balancers, caching, clustering, sharding, fault tolerance & recovery and high performance. But will be omitting high availability , clustering & fault tolerance for brevity.
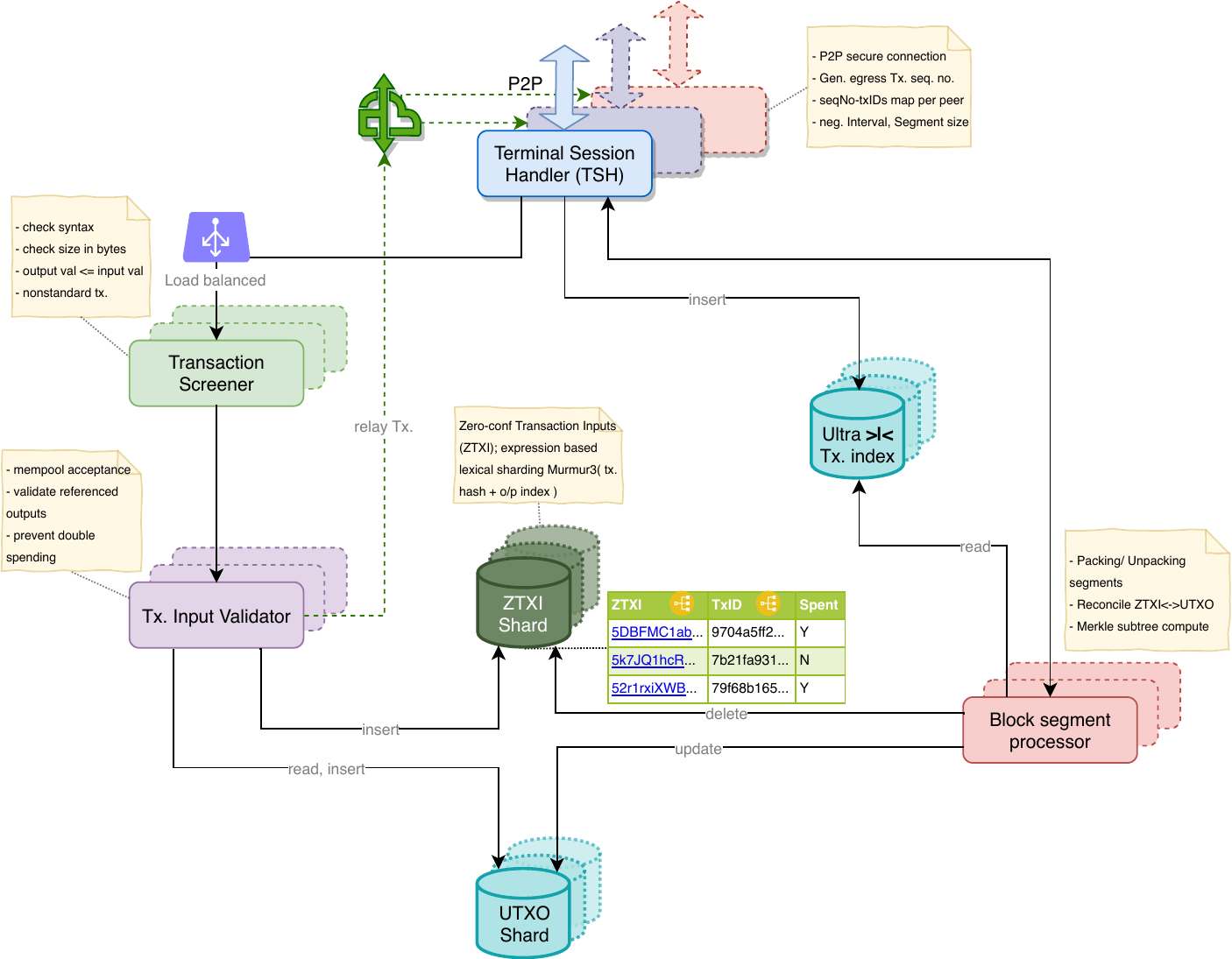
The block propagation problem is addressed with Ultra compression, and the next important problem to solve is 'Mempool acceptance', it is currently a serious bottleneck and we need a solution to allow accepting billions of transactions into the Mempool efficiently. A transaction is a set of multiple inputs and outputs, potentially belonging to different addresses(pub-keys), also a transaction is meant to be atomic, i.e. all of nothing must be committed, also transactions are independent. Transactions need to be validated before accepting into Mempool. To relieve the bottleneck, we need to concurrently validate transactions & the concept of mempool sharding seems to hold promise, it has been discussed previously, but the solution approach is important. Primary concern with sharding is the cross shard communication overhead involved, the obvious goal is to remove this if possible or have it extremely low. Naive Mempool sharding approaches do not succeed at this objective and inter shard messages grow exponentially, or else some transaction ordering (namely CTOR) approaches have to be incorporated breaking the consensus protocol.
Instead of sharding Mempool (unconfirmed transactions), the proposal shards Inputs or outpoints to be more specific, (outpoints are outputs referenced by the inputs of given transaction), now the different outpoints of a single transaction could be stored on different shards. Lexically sharded Mempools, based on TxId vs, do not work very well in our context. We adopt a slightly different approach. A new datastructure is introduced, to hold Zero-conf Transaction Inputs (ZTXI) it holds decomposed transactions i.e. inputs (Outpoints) as a primary key (also indexed on TxID). Both ZTXI & UTXO are horizontally sharded as below. Expression based Lexical sharding of the Murmur3 hash of transaction input's Outpoint (sha256 hash of ref. parent Tx + output index); Murmur3 is recommended because of its speed, low space & CPU utilization, and random uniform distribution. But since murmur (or Siphash) is not a cryptographic hash, an attacker could induce hash collisions or overload a single shard. This can be prevented by including a 'salt' component to the hashing input which can be any arbitrary string private to the node, so the sharding basis is not revealed outside.
The Tx. Input Validator cover the second level of transaction validation, it does this by combination of UTXO & ZTXI shard lookups and writes, as explained below:
For every Input:
- Verify the scriptPubKey accepts, if not reject
- If outpoint exists in the ZTXI shard
- If outpoint is not spent, mark spent and insert new outpoint into ZTXI shard.
- If outpoint is already marked spent, its a validation error, delete outpoints corresponding to this TxID on other shards (previously inserted) in order to keep the entire transaction atomic, effectively this transaction is rejected.
- If outpoint does not exist in ZTXI shard, but exists the corresponding UTXO shard, then insert outpoint into ZTXI and mark unspent.
- If outpoint does not exist either in ZTXI or UTXO shards, then insert into ZTXI and flag it for exponential back-off retries on corresponding UTXO shard. @@
- After processing all Inputs, insert corresponding Tx. Outputs into UTXO shard with a special flag indicating its transient status.
@@ If a parent Tx. appears out of order i.e. after child Tx. they will likely settle on different ZTXI shards. Now for the parent is to be marked spent, and the child to be admitted & marked unspent, it would need significant cross shard communication, mainly because its unknown which ZTXI shard to query for the parent output. Besides the model is vulnerable, as an attacker (Sybil) could churn out transactions with invalid inputs, and the node will not be able to recover itself from the avalanche of inter shard messages that would ensue. To solve this, transient/unconfirmed unspent output records are inserted into the UTXO shard with a flag indicating so. These can be easily reconciled once a block is found, the unconfirmed UTXOs are updated appropriately and the corresponding ZTXI shard contents will be pruned appropriately. If a block is received, it involves carefully updating relevant records for the transactions contained in the block.
The ZTXI shard is almost emptied every time a block is mined. The UTXO database stays relatively stable in size, with only a small % of transient records. The ZTXI shards holds unconfirmed Inputs, and the UTXO shards holds unspent Outputs. The validated transactions are in effect are topologically sorted before being accepted into the mempool, they can now be rolled into a block directly without needing any additional sorting.
As described in part-2, the ordered transaction set of a block can be segmented into chunks and the chunks can be packed and transmitted to the peer independently. It is advantageous to segment the block (transaction set) and handle packing/unpacking with high parallelization, while the actual segmenting process can be accomplished locally, there is an advantage in doing this at remote end (peer). It is not desirable for a large message/payload on one logical channel/API/RPC to monopolize the output channel, so splitting the message into smaller fragments allows better sharing of the output channel. If a supersized block (a 1TB block post Ultra compression could still be ~1GB) is being transmitted by the peer then the channel is monopolized by this large message, and other messages with equal or higher priority/urgency could be held up, this is clearly inefficient. Without chunking/multiplexing the potential for parallelism is diminished.
Since Bitcoin's P2P layer (unlike Ethereum's RLPx) does not support chunking/multiplexing, it makes sense to achieve the block segmenting at the application protocol layer, and with mutual co-ordination b/w peers.
As shown before, segments can be made to fit Merkle sub-trees by having <= 2^n segments which can be independently/parallelly computed and efficiently combined to validate the ultimate Merkle root contained in the block header. The desired number of segments can be pre-negotiated between the peers(p2p layer), and while packing the sender would try to split block into as many (or slightly fewer) segments. Obviously each segment (except the last one) needs to have strictly 2^n leaf nodes (Txns.) so that Merkle sub-tree recomputation can be avoided. The sender can additionally include the Merkle subtree root into the segment at no additional cost (since it had to be done anyway), and this can help the receiver quickly gain confidence in the validity of the segments and hence the block by validating the ultimate Merkle root
The distributed system architecture depicts only logical components and the deployment topology could vary, some components could be sharing h/w resources. The actual technology stack, messaging technologies are omitted, but there are plenty of off the shelf frameworks/tools (opensource) to choose from, databases/caches could be easily in-memory ones which offer low latency, and the horizontal scaling feature allows currently available affordable CPU/ RAM/ Bandwidth to be leveraged to realize a Terabyte block processing system. The design is not contingent to future hardware improvements (Moore's law expectations). 10Gbps bandwidth per peer & dozens of medium grade hardware with 32/64GB RAM will be within reach to many if not most miners, and a thriving miner ecosystem can be a reality. Yes miners will try out-compete each other, and possibly engineer proprietary closed source logical components (roughly) shown above, but I doubt it will be tilted towards a primarily h/w race.