The Keylime integrity verification system currently operates on a pull, or server-initiated, basis whereby a verifier directs a number of enrolled nodes to attest their state to the server on a periodic basis. This model is not appropriate for enterprise environments, as each attested node thereby acts as an HTTP server. The requirement to open additional ports for each node and the associated increase in attack surface is unacceptable from a compliance and risk management perspective.
This document aims to outline the challenges that need to be overcome in order to support an alternate push model in which the nodes themselves are responsible for driving the attestation cycle. These include changes to the registration, enrolment and attestation protocols. We hope to elicit feedback from the Keylime community on these topics to arrive at a robust, forward-thinking solution which considers the latest developments in verification.
Thore Sommer (@THS-on) has previously put together a draft proposal on how some aspects of this could work. We make reference to this where relevant.
To begin, we first provide an overview of the current state of Keylime as it relates to this topic. We will then move onto a discussion of our security requirements and operational concerns. And finally, we will will give our specific recommendations for satisfying these.
- 2023-09-18: (Current) Minor clarifications
- 2023-09-04: Simplified presentation of proposed changes
- 2023-08-10: Introduced a new comprehensive approach to agent authentication
- 2023-08-02: Initial version
Keylime's stated purpose, as given on the official website, is to "bootstrap and maintain trust". The original design was presented in a 2016 ACSAC paper which explains the meaning of this statement: the goal is to (1) provision identities for nodes on a network and (2) monitor these nodes to detect integrity deviations.
Keylime consists of three main components: a registrar, which acts as a simple store of identities associated with each node, a verifier, which analyses node state and detects changes, and an agent, which is installed on each node and reports information to the registrar and verifier.
The ACSAC paper also leaves a number of responsibilities to the "tenant", that is, the customer of a cloud platform. These tasks have been extracted into a management CLI, referred to by the same name. In the rest of this document, when we mention the tenant, we are referring to the command-line tool.
The Keylime registrar, verifier and tenant are all fully trusted to perform their respective responsibilities faithfully. Nodes, including their installed agents and any running workloads, are not trusted until the registrar, verifier and tenant collaborate to obtain and validate a set of trusted measurements of node state. From that point, a node is deemed trusted, at least until that trust is revoked (either by an automatic mechanism or through manual intervention by an administrator).
The authenticity of measurements are assured by the TPM of each node (the TPMs are thereby also considered to be trusted).
In the default configuration, the registrar and verifier share a single TLS certificate and corresponding private key for server authentication and secure channel establishment. The verifier and tenant share a TLS certificate and private key for client authentication. Both server and client certificate are produced by a common Keylime CA, the certificate for which is preloaded and trusted by all components (verifier, registrar, tenant and agent).
The agent has its own TLS certificate this document calls the NKcert (mtls_cert in the REST APIs and source code) which it generates on first startup using a pair of public and private transport keys (collectively, the NK) chosen at random. The NKcert is registered with the registrar on agent startup and automatically trusted.
The agent also uses the TPM to create an attestation key (AK), referred to as an "attestation identity key" (AIK) in older TCG specs (and in places in the Keylime source code), associated with the TPM's endorsement hierarchy. The public portion of attestation key (AKpub) is reported to the registrar and verifier during registration/enrolment of the agent. Additionally, the registrar receives the TPM's public endorsement key (EKpub) and endorsement certificate (EKcert).
In the current architecture, the Keylime server components are entrusted with these specific responsibilities:
| Registrar | Verifier | Tenant |
|---|---|---|
|
|
|
Keylime performs its functions via a handful of protocols between the various Keylime components. The relevant ones are as follows:
- Registration protocol: Enables the agent on first start to register its EKpub, EKcert and AKpub with the registrar and prove that the AK and EK are linked.
- Enrolment protocol: Four-way protocol between the tenant, registrar, verifier and agent to enrol the agent for periodic verification by the verifier and provision nodes with credentials.
- Attestation protocol: The verifier uses this to request TPM quotes from the agent according to a configured interval.
A high-level overview of these protocols is given in the diagram below:
Enabling agent-driven attestation in Keylime is not a simple matter of reversing the directionality of the protocols. There are a number of adjacent concerns which need to be considered. For one, given the stringent security requirements of enterprise users, the trust assumptions inherent in the existing pull protocols should be re-evaluated before adopting them wholesale for the push model. Further, it is worth enumerating the operational constraints which could reasonably be foreseeable in different enterprise deployment contexts.
Push support presents the perfect opportunity to revisit these fundamental concerns, as backwards compatibility with old agents does not need be considered (updates to both the agents and the server components would be required to use the push feature regardless).
The primary driver behind the need for the push model is a desire to limit the attack surface of the agent. The user needs to place significant trust in the agent software, so it should be compact, inspectable and should not unnecessarily affect system state. The user should not be expected to make significant changes to their system/network configuration or deploy additional controls in order to secure a Keylime installation (within reason).
Beyond these high-level concerns, special attention must be afforded to our protocols. See Appendix A for the threat model we are considering in our protocol designs.
The environments in which users may deploy Keylime are diverse:
- Users may or may not have an existing public key infrastructure (PKI).
- Users may or may not have a record of their nodes in an inventory management system.
- TPMs may or may not make an EKcert available (physical TPMs usually do, but public cloud vTPMs often do not).
- Attested nodes may be issued with IDevID and IAK certificates1 out of the factory, or may not.
- Users may deploy Keylime on a private network, expose it to the internet, or make it available on a semi-public network (e.g., that of a university campus).
A comprehensive solution should provide the user with options for deploying Keylime in all these situations.
While we ultimately need to make changes to the registration, enrolment and attestation protocols, these depend on authentication and trust mechanisms as shown in the below figure:
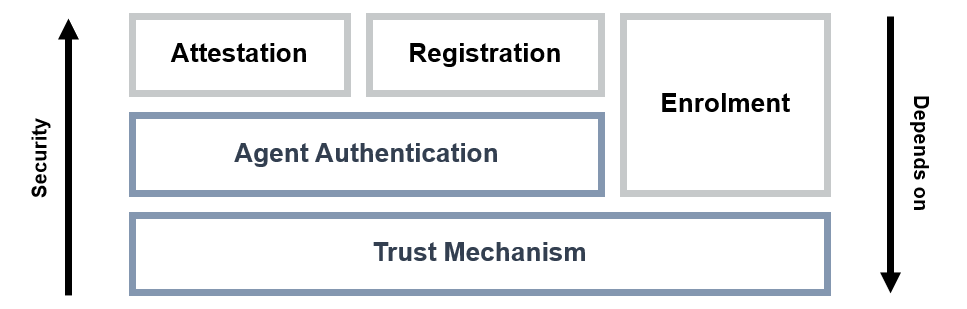
As different authentication and trust mechanisms are more or less appropriate depending on the deployment context, we do not fix these and instead provide the user with a couple options for each. This makes it possible to support many different environments without overwhelming the user with choices.
The agent authentication and trust mechanisms which the user may choose from are discussed in the subsequent sections after which we will introduce the higher-level protocols that build on these. Miscellaneous changes to support the new and revised protocols are given in Appendix B.
Attestations are of course authenticated by virtue of being signed by a TPM. But agents do not simply report attestations: they also need to access certain data stored by the verifier. An additional authentication mechanism is therefore needed to secure these API endpoints.
We propose that the user may choose between two agent authentication mechanisms:
- mutually authenticated TLS (mTLS) with pre-provisioned client certificates for the agents; or
- a challenge–response protocol secured by the TPM and the unilateral authentication provided by regular TLS.
In the current pull model, mTLS is used to authenticate agents using a certificate and private key which each agent generates on first start and is trusted automatically by the registrar (refer back to Long-Term Keys). In the past, concerns have been expressed that this is not compliant with the certificate management policies in many organisations as they often require a central certificate authority (CA).
However, we do not wish to remove mTLS as an option for users who manage their own PKI. In such cases, the user would provision agents each with a certificate which is pre-trusted with the registrar and the verifier.
When this authentication option is chosen, the agent should bind the corresponding private key to the TPM's identity at registration time by way of TPM2_Certify,2 as suggested by the earlier draft proposal. Additionally, all endpoints which accept authentication via mTLS should check that the expected node identifier is contained within either Subject or Subject Alternative Name fields of the presented certificate to ensure that there is a binding to the identifier. The topic of identity binding is discussed in greater detail later in the Proposed Trust Mechanisms section.
When mTLS is not enabled, the verifier can use an alternate mechanism to authenticate agents (also shown in the sequence diagram to the right):
- The agent will request a new nonce from a verifier endpoint which does not require authentication. The verifier will randomly generate a new nonce and store it alongside the node identifier provided by the agent (multiple nonces can be associated with a single node).
- The agent will use TPM2_Certify (TPM 2.0 Part 3, §18.2) to produce a proof of possession of the AK, based on the nonce. The AK will be the object certified and also the key used to produce the signature.
- The agent will send the result to the verifier which will verify the signature using its record of the AKpub for the node and check that the signed data contains a valid nonce.
- If verification of the AK possession proof is successful, the verifier will respond with a session token, which it will persist and deem valid for a configured time period.
- The agent will use this token to authenticate subsequent requests to the verifier. If the token is still valid, the action will proceed. Otherwise, it will reply with a 401 status and the agent will repeat the challenge–response protocol to obtain a new session token.
Whenever the agent submits a valid attestation, the quote itself acts as a proof of possession of the AK. Therefore, on successful verification of a quote, the verifier may extend the validity of the session token, minimising the need to repeat the challenge–response protocol.
This mechanism is very similar to DPoP which allows authentication of OAuth 2.0 clients by way of cryptographic proof. As such, it should be possible to evolve it into a standard OAuth-based solution for API authentication down the line, if desirable.
Entity authentication is only useful when the entities are authenticated against a trusted identity. Here, we must be careful not to conflate the identity of the TPM with the identity of the agent or the identity of the attested node itself. This is because the Keylime protocols are effectively three way protocols between the TPM, agent and Keylime server (whether the registrar or the verifier). Per the stated adversarial model (Appendix A), communications between the TPM and agent can be tampered with.
Reliably identifying the agent is likely impossible in our adversarial model. Any private key used by an agent to sign messages is also obtainable by an attacker resident on the attested node.
But even if we treat the agent as a simple intermediary between a TPM and the server without an identity of its own (like a network switch or router), this is insufficient. The root identity of the TPM, the EK, does not contain any information about which device the TPM is installed in (it does not contain a device-specific identifier). So, you cannot use the EK to identify the TPM as belonging to a particular device. From TPM 2.0 Part 1, §9.4.3:
The TPM reports on the state of the platform by quoting the PCR values. For assurance that these PCR values accurately reflect that state, it is necessary to establish the binding between the RTR and the platform.
As such, we have two different trust concerns:
-
The need to identify a TPM as having been produced by a trusted manufacturer. In order to have confidence in measurements of system state, it is necessary that the TPM behaves according to spec, e.g., that it correctly performs PCR extend operations and protects the contents of its registers (including keys) from access by outside entities except via the well-defined mechanisms.
-
The need to have a trusted binding between the TPM's (RTR) identity and the node's (platform) identity. Otherwise, there is no assurance that a verification outcome is the result of applying the right verification policy to measurements of the right node.
In summary, when an agent sends an attestation or otherwise accesses a Keylime API, the trust that is placed in the agent's request needs to derive from some root identity (e.g., EK), bound to a particular logical node identifier, which the user has specified as trusted (the user must trust the identity itself as well as the binding). The node may have certain subordinate identities (e.g., AK) which are transitively trusted by their binding to one of the node's root identities. This is illustrated by the below figure:
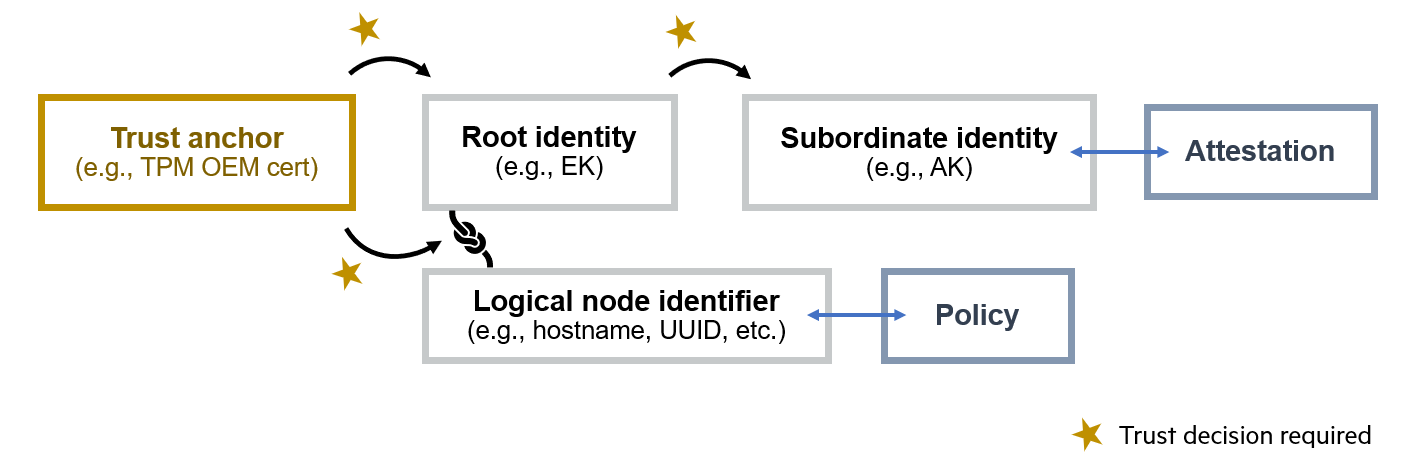
If the outcome of all the trust decisions shown on the diagram is favourable, we can trust that the right policy (associated with a node's logical identifier) is applied to the right attestation (produced by a subordinate cryptographic identity) by following both chains all the way to a trusted root identity.
Once again, we propose two different mechanism for making these trust decisions, which users can use independently or together at their discretion:
- a standard trust store mechanism for use when certificates are available to establish trust; and/or
- a webhook mechanism for when certificates are not an option or when custom trust logic is desirable.
Keylime already uses certificate checking in a number of places, e.g., to verify an EKcert against trusted TPM manufacturer certificates and to authenticate TLS connections. However, the implementations are specific to each individual circumstance.
Instead, we propose that a single genericised mechanism is used across all situations in which certification verification is required. This should operate in similar fashion to the trust stores implemented by browsers and operating systems. Given (1) a certificate to check, (2) a list of intermediate certificates with indeterminate trust status and (3) a list of trusted certificates, the mechanism should deem (1) as trusted whenever a binding exists from (1) to a certificate in (3), possibly via one or more certificates in (2).
The generic nature of this mechanism allows it to be used to trust EKcerts, pre-provisioned agent TLS certificates (when using mTLS for agent authentication), IDevIDs/IAKs1, or any future X.509 certificate-based identity. The user has the option of providing CA certificates, in which case leaf certificates will be trusted transitively, or individual leaf certificates, effectively whitelisting them.
However, it is important to note that this mechanism, as described above, does not necessarily provide a binding to the node's logical identifier. In the following cases, the binding can be established automatically:
- when the root identity being checked is an EKcert and the node identifier is a hash of the EK (this is already a configuration option in Keylime);
- when the root identity being checked is a pre-provisioned certificate issued to the agent and either its
SubjectorSubject Alternative Namefield matches the node identifier; or - when the root identity being checked is an IDevID/IAK containing a device serial number and the node identifier is set to the same serial number.
Outside of these situations, the binding of the node's root identity to its logical identifier will need be established via the webhook mechanism.
Currently, if no EKcert is available (for example, if the agent is running on a VM deployed in the cloud), then the tenant allows the user to specify a script to use to verify the EK using custom logic.
We propose adopting a new mechanism which serves as an evolution of, and replacement for, this script-based approach. Instead, the user will have the option of configuring a webhook which the registrar can query for a trust decision.
The webhook will not only be called in situations where an EKcert is unavailable, but rather whenever a favourable trust decision cannot be reached by the registrar. For example:
- when an EK has been provided by the agent but this is not accompanied by an EKcert;
- when an EKcert has been provided but verification against the trust store fails; or
- when an EKcert has been provided and verifies against the trust store, but the node identifier does not match the hash of the EKpub.
When the registrar issues its request to the webhook URI, it would provide all information it has about the agent: its keys and certificates and the outcomes of the checks which the registrar has already performed. For example, it may supply a JSON object similar to the following in its request:
{
"node_id": "...",
"root_identities": ["ek"],
"subordinate_identities": ["ak"],
"ek": {
"trust_status": "NOT_TRUSTED",
"trust_details": ["EK_CERT_RECEIVED", "EK_CERT_NOT_TRUSTED", "EK_NOT_BOUND_TO_ID"],
"ekcert": "..."
},
"ak": {
"trust_status": "BOUND_TO_UNTRUSTED_ROOT",
"trust_details": ["AK_BOUND_TO_EK"],
"bound_root_identities": ["ek"]
}
}The webhook endpoint may reply with a list of decisions it wishes to override based on its own custom logic, e.g.:
{
"node_id": "...",
"decisions": ["EK_CERT_TRUSTED", "EK_BOUND_TO_ID"]
}It may also elect not to override any decisions, or override only a subset of decisions, and instead provide additional information to enable the registrar to reach its own new decisions. For example, consider the case in which an agent is deployed in a VM on a cloud provider and, as a result, the EKcert is unavailable and thus the EK is not trusted nor bound to the node's logical identifier, set to the hostname of the node. The web service serving the webhook endpoint could use the node identifier to retrieve the EKcert from an API provided by the cloud provider and respond to the registrar with the following:
{
"node_id": "<hostname>",
"decisions": ["EK_BOUND_TO_ID"],
"ek": {
"ek_cert": "<ek_cert_from_cloud_provider>",
"intermediate_certs": ["<cloud_provider_intermediate_cert>"]
}
}Given that the cloud provider's root CA certificate is present in the registrar's trust store, the registrar will re-evaluate its EK decision, and mark the EK as trusted.
This proposed webhook functionality can be added to the existing registration protocol while remaining backwards compatible with previous versions and is illustrated by the sequence diagram:
(The current protocol messages are in black while green indicates the new items proposed by this document. Items not relevant to the push model are struck out in red.)
Note that the outgoing request to the webhook URI is performed in a non-blocking way, so the registrar can reply to an agent's registration request without waiting for a response from the outside web service. If no well-formed response is received from the web service, it should reattempt the request using an exponential backoff, similar to what the verifier currently does when a request for attestation data from an agent fails.
To obtain an integrity quote in the current pull architecture, the verifier issues a request to the agent, supplying the following details:
- A nonce for the TPM to include in the quote
- A mask indicating which PCRs should be included in the quote
- An offset value indicating which IMA log entries should be sent by the agent
The agent then replies with:
- The UEFI measured boot log (kept in
/sys/kernel/security/tpm0/binary_bios_measurements) - A list of IMA entries from the given offset
- A quote of the relevant PCRs generated and signed by the TPM using the nonce
In a push version of the protocol where the UEFI logs, IMA entries and quote are delivered to the verifier as an HTTP request issued by the agent, the agent needs a mechanism to first obtain the nonce, PCR mask and IMA offset from the verifier. We suggest simply adding a new HTTP endpoint to the verifier to make this information available to an agent correctly authenticated with the expected certificate via mTLS.
As such, the push attestation protocol would operate in this manner:
-
When it is time to report the next scheduled attestation, the agent will request the attestation details from the verifier.
-
If the request is well formed, the verifier will reply with a new randomly-generated nonce and the PCR mask and IMA offset obtained from its database. Additionally, the verifier will persist the nonce to the database.
-
The agent will gather the information required by the verifier (UEFI log, IMA entries and quote) and report these in a new HTTP request along with other information relevant to the quote (such as algorithms used).
-
The verifier will reply with the number of seconds the agent should wait before performing the next attestation and an indication of whether the request from agent appeared well formed according to basic validation checks. Actual processing and verification of the measurements against policy can happen asynchronously after the response is returned.
This protocol is contrasted against the current pull protocol in the sequence diagrams which follow:
| Pull attestation protocol | Push attestation protocol |
|---|---|
(The current protocol messages are in black while green indicates the new items proposed by this document.)
One drawback of this approach is that the number of messages a verifier needs to process is doubled. However, this is unlikely to significantly impact performance as the most intensive operations performed by the verifier remain those related to verification of the received quotes. Any such impact should be offset by the increased opportunity for horizontal scaling presented by the push model (as it makes it easy to load balance multiple verifiers). Further optimisations of the protocol can be explored once work on the simple version presented above has been completed.
Currently, registration serves mostly as a way for agents to report their root and subordinate identities to the registrar when they are run for the first time. Only limited checking of these identities is performed: the registrar will check that the reported AK and EK are linked by way of TPM2_ActivateCredential. All other identity verification is performed by the tenant at enrolment.
We propose that, when operating in push mode, the registrar perform these checks at registration time instead. As discussed in previous sections, this would be done using the new trust mechanisms: either the certificate trust store, the webhook mechanism, or both together. The registrar can make this determination on the fly depending on what identity information is received from the agent (e.g., when an EKcert is presented, the registrar will check it against the trust store and fall back on the webhook, if configured).
Additionally, the registration protocol should always be secured with TLS whenever Keylime is configured to operate in push mode (registration currently happens over simple HTTP).
Enrolment currently is a fairly complicated protocol involving all parties (the agent, registrar, verifier and tenant) with most of the processing being performed by the tenant. We propose instead that enrolment is simplified significantly for the push model.
Verification of the agent's identities will be performed during registration, as stated in the last section, and the registrar will make the outcome of these decisions available through its REST API. As such, we propose that this function is not performed by the tenant for agents running in push mode.
As part of the current enrolment process, the user specifies a payload which is delivered to the agent and placed in a directory to be consumed by other software. The reason for this is to support the provisioning of identities to workloads running on the node (e.g., TLS certificates or long-lived shared secrets). The payload may optionally contain a script file, which is executed by the agent.
Considering the current landscape of the identity and access management space, a more modern approach to solving this problem would likely be to have Keylime report verification results to a SPIRE attestor plugin which could then handle provisioning of workload identities. This offloads issues related to revocation and suitability for cloud-native workloads.
The arbitrary nature of the payloads mechanism also raises concerns as to the attack surface of the agent and the whole Keylime system. Not only can Keylime server components query a node to report on its state but they also have the power to modify a node's state and execute arbitrary code. Enterprise users would consider this unacceptable.
As a result, we recommend that the payload feature is not implemented in the push model. This gives users the choice to opt into a more secure design which considers a stronger threat model without taking features away from existing users. And for users which do require identity provisioning alongside push support, they have the option of using SPIFFE/SPIRE.
With identity checks moved into the registration protocol and the payload feature removed entirely from the push model, enrolment now becomes, simply, a way for users to specify a verification policy for a node. The process is as follows:
-
The user identifies the relevant node by whatever logical identifier has been configured (e.g., UUID, hostname, EK hash, etc.) and provides a verification policy to the tenant.
-
The tenant contacts the registrar and retrieves information about the node, including the outcomes of the registrar's trust decisions.
The tenant exits and displays an error to the user whenever:
- the registrar replies with a 404 status indicating the node has not yet been registered; or
- the registrar indicates that the AK could not be bound to a root identity which has been deemed trusted.
In all other cases, the tenant proceeds with enrolment.
-
The tenant creates a new record for the node at the verifier, providing the node identifier and verification policy plus select information obtained from the registrar: the AK for the node and the agent's client certificate (if the agent is configured to use mTLS). If the verifier replies with a 200 status, the tenant exits and displays a success message to the user. Otherwise, the tenant exits with an error message.
Once the enrolment process has been completed successfully, the verifier will accept the next attestation received from the agent and verify it against the supplied policy.
As the role of the tenant in enrolment has effectively been reduced to contacting a couple simple REST endpoints, it should be easy to re-implement this if the tenant is replaced with something else (either by the Keylime project or by the end user).
Putting all the above recommendations together, the lifecycle of an agent operating in push mode can be described according to the following steps (also shown in the flowchart to the right):
-
The agent starts for the first time. If the agent has not been pre-configured with a specific identifier, the agent will use the configured mechanism to obtain the identifier for the node (i.e., DMI UUID, hostname, EK hash, or IDevID serial number).
-
The agent will, as is currently the case, register itself at the registrar, providing its identifier and all available root and subordinate identities of the node (e.g., an AK and an EK, with an EKcert if available).
Not shown: the registrar will process the provided keys and certificates and reach a trust decision asynchronously, either on its own, or by invoking the configured webhook.
If the agent is configured to use mTLS for authentication, it will proceed directly to step 5. Otherwise, it continues to step 3.
-
The agent will attempt to authenticate itself to the verifier, providing its node identifier and obtaining, in response, a nonce. Then, it will use the TPM to construct a proof of possession of its AK, based on the nonce, and try to exchange it for a session token.
If the verifier replies with a session token, the agent proceeds to step 5. Otherwise, it continues to step 4.
-
At this point, it is likely the user has not yet enrolled the agent with the verifier and provided a verification policy for the node. As such, the verifier will reply will an error and the agent will attempt authentication again from step 3 repeatedly, employing an exponential backoff.
Not shown: the user may subsequently use the tenant to enrol the node for verification. The user supplies the identifier of the node and desired verification policy and the tenant will obtain the keys for the node from the registrar. If the registrar indicates that all identity checks for the node have passed (the AK is associated with a trusted root identity that is bound to the node identifier), then the tenant sends the node identifier, AK and verification policy to the verifier. The next authentication attempt performed by the agent should succeed such that the agent obtains a valid session token.
-
The agent retrieves, from the verifier, the information needed to produce an attestation for the node (authenticating via mTLS, if configured, or using a token obtained in the previous steps). It prepares the quote, gathers logs and sends it to the verifier. The verifier will process the quote received and arrive at a decision asynchronously.
The verifier may reject an attestation sent by an agent for one of two reasons:
- (a) The token is no longer valid. The agent will reattempt authentication from step 3.
- (b) The previous attestation failed verification (and the verification policy has not since changed). In such case, the agent will continue to send attestations, employing an exponential backoff.
-
The agent will continue to send periodic attestations to the verifier from step 5.
Note that full separation between the registrar and verifier is maintained and no communication takes place between them.
Many thanks to Thore Sommer (@THS-on) for sharing his ideas, both face to face and in his previous draft proposal, to Marcus Heese (@mheese) for many helpful discussions around threat model and operational concerns and to everyone else who has commented on the various iterations of this proposal. We also greatly appreciate the feedback and guidance received from the maintainers and community members in the June, July and August community meetings.
In the design of security protocols, it is prudent to define a threat model in terms of the capabilities of an idealised attacker. This has a number of advantages, not limited to the following:
- users are clear on the security properties they can expect from the system;
- developers have agreement on which attacks are in scope and which are out of scope; and
- the protocols naturally lend themselves to analysis by outside parties.
In lieu of a full formal model, we give a plain English description, translatable to formal definitions, in the subsections below.
We give the main security property for Keylime by stating what a successful adversary must achieve:
A valid attack against Keylime is one in which an adversary can cause a mismatch between a verification outcome reported by a verifier and the correct, expected verification outcome for the verified node.
This includes attacks in which:
- verification of a node is reported as having passed when the policy for the node should have resulted in a verification failure; or
- verification of a node is reported as having failed when the policy for the node should have resulted in a successful verification.
The latter is important to consider because, depending on how Keylime is used (e.g., if Keylime results are consumed by SPIRE or otherwise used for authentication of non-person entities), this could be exploited to trigger cascading failures throughout the network.
For our adversary, we consider a typical network-based (Dolev-Yao) attacker3 which exercises full control over the network and can intercept, block and modify all messages but cannot break cryptographic primitives (all cryptography is assumed perfect). Because we need to consider attacks in which the adversary is resident on a node to be verified, we extend the "network" to include the channel between the agent and the TPM. It is assumed the adversary has full access to the filesystem and memory of the node. The adversary cannot corrupt (i.e., take control of, or impersonate) the TPM, boot firmware, verifier, registrar or tenant.
Attacks which exploit poorly-defined verification policies or deficiencies in the information which can be obtained from IMA and UEFI logs (and other measures of system state) are necessarily out of scope. Additionally, we exclude attacks which are made possible by incorrect configuration by the user. Attacks which rely on UEFI bootkits or otherwise require the adversary to modify the measured boot process are also excluded.
The following minor changes are required to support the protocol-level changes proposed above:
Enterprise users often route HTTP traffic through proxies. Support needs to be added to the Keylime agent to proxy requests to a given HTTP proxy URI.
The following changes should be made to the agent's configuration options (usually set in /etc/keylime/agent.conf):
- Add an
operation_modeoption which accepts eitherpushorpull. - Add
verifier_ipandverifier_portoptions to specify how the agent should contact the verifier when operating in push mode. - Add an
https_proxyoption to allow users to specify an HTTP proxy by which the agent should contact the registrar and verifier. - Update comments to indicate which values won't have an effect when push mode is turned on (e.g., those related to payloads).
It is suggested that operation_mode should not be configurable via environment variable and that the agent checks the ownership of the config file on startup, outputting a warning if it can be written to by any user other than root.
These changes should be made to the verifier's configuration options:
- Add an
operation_modeoption which accepts eitherpushorpull.
Finally, these changes should be made to the registrar's configuration options:
- Add a
trusted_certsoption to set the directory where the registrar should look for trusted certificates when verifying root identities such as agent mTLS certificates, EKs, IDevIDs/IAKs1, etc. - Add a
intermediate_certsoption to set the directory where the registrar should look for intermediate certificates when verifying root identities such as agent mTLS certificates, EKs, IDevIDs/IAKs, etc. - Add a
trust_decision_webhookoption to set the URI the registrar should invoke when it cannot reach a favourable trust decision.
Footnotes
Footnotes
-
IDevIDs/IAKs are a type of cryptographic identity issued by a device manufacturer and tied to the TPM of the device. For further discussion of device identity as it relates to Keylime agent-driven attestation, we have produced a supplement to this document, entitled 802.1AR Secure Device Identity and the Push Model. ↩ ↩2 ↩3
-
TPM2_Certify, described in TPM 2.0 Part 3, §18.2, does not, on its own, prevent all attacks on the binding between the EK and the agent's client certificate used for mTLS. An attacker who obtains the secret key associated with the certificate (possible in our adversarial model) could block the legitimate node's registration messages from reaching the registrar. Then, the attacker could register their own node instead, causing the certificate to be associated with a TPM under the attacker's control. Because of this, the CA should perform its own binding during certificate issuance and include the EK hash in the certificate. ↩
-
This type of rule-based adversary is first described by Danny Dolev and Andrew Yao in their 1983 paper, "On the security of public key protocols". ↩
Once you are in an exponential backoff it may then take a while until the attestation actually starts. There should probably be a limit set to a few seconds on how far to back off until the first attestation with the policy starts. Like maybe 10s ?
If nothing happens before a policy is set we could require that a policy be set first using the tenant tool. This ordering of requiring a policy first could be used to open access for a particular agent to the verifier while preventing it to connect to the verifier first and keeping it busy for no reason...
Should the UUID of the agent be written into the client side certificate and make the client side certificate unique? This would at least make it a bit more difficult to just register an agent that then claims a UUID from a configuration file and prevent re-use of possibly stolen cert. On the other hand it requires issuing a certificate per agent, which may be an operational pain.