K-means is one of the most popular unsupervised learning techniques due to its simplicity and efficiency. It is an iterative and unsupervised clustering algorithm used in machine learning.
A cluster is a group of data points that are grouped together due to similarities in their features.The k-means clustering algorithm assigns data points to categories, or clusters, by finding the mean distance between data points. It then iterates through this technique in order to perform more accurate classifications over time.
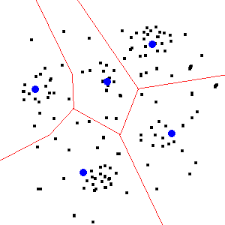
To put it simply, K-Means clustering intends to partition n objects into k clusters in which each object belongs to the cluster with the nearest mean.
The objective of K-Means clustering is to minimize total intra-cluster variance.
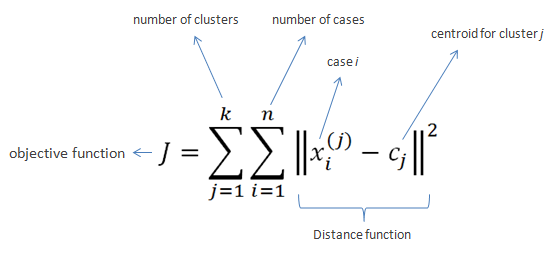
- Specify the number of clusters needed to be identified from the data. This value is represented by k .
- Select k points at random as initial cluster centers.
- Assign all the objects/points to their closest cluster center by calculating the Euclidean distance between them (the point and centers ).
- Calculate the centroid or mean of all objects in each cluster.
- Repeat steps 2, 3 and 4 until the same points are assigned to each cluster in consecutive rounds.
Note : The final result of the cluster is hugely dominated by the points which were choosen as initial cluster centers.
So , its really recommended to run this algorithm mutliple times and keep track of the different clusters it forms with different randonmly choosen initial cluster centers or you can simply call them starting points.
The algorithm explained above finds clusters for the number k that we chose. So, here the big question is how do we decide on that number?
The most traditional and straightforward method is to try with different values of k starting with 1 ( the worst case scenario ) which will form only a single cluster. Each time we add a new cluster, the total variance within each cluster reduces and when there is only one point in the cluster , the variance gets 0.
When the reduction in variance for the increasing value of k is plotted as a 2D graph , it takes the shape of an elbow and that is why this method of finding k is known as elbow method.

Now there will a point after which the varience dosen't go down quickly and its called the elbow point which represents the best value of k with satisfactory outcomes of clustering.
Other methods :
- Average silhouette method
- Gap statistic method
K-means clustering is a fast and efficient algorithm to classify data points into categories when you have little available information about your data. It is the simplest algorithm that can be used . However there are many famous algorithms available for unsupervised learning such as:
- Apriori algorithm
- K-NN (k nearest neighbors)
- Principal Component Analysis
It is recommended that you first understand your data before deciding which technique or algorithm to use for solving your problem.